 人工智能与算法学习
人工智能与算法学习




来源:知乎
文章仅作学术分享,著作权归属原作者,侵删
https://www.zhihu.com/question/498364155
电光幻影炼金术(香港中文大学 CS PhD在读)回答:
现在是2021年11月12日中午,恺明刚放出来几个小时,就预定了CVPR2022 best paper候选!
Arxiv地址:https://arxiv.org/pdf/2111.06377.pdf
恺明总能做出很新很有效的让人震惊的文章,这篇又是一个力作。要知道凯明最近已经很少发一作的文章了。
这篇文章推翻了之前自监督领域的统领范式,开天辟地地提出了简单本质有效的自监督方法:基于mask和autoencoder的恢复方法。
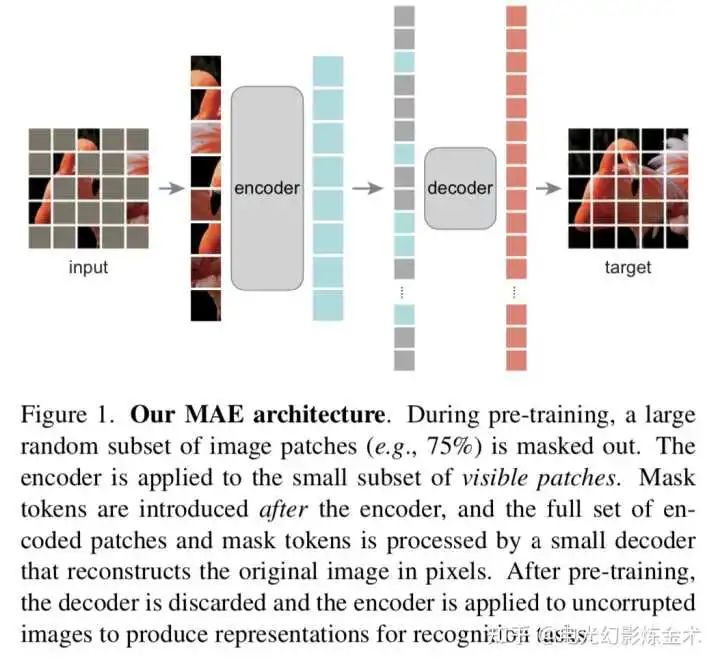
下面一起来赏析一下恺明的历史性工作。模型非常简单,上图一目了然。就是把图片中一部分像素遮盖掉,然后用autoencoder来恢复。这样无监督学习到的表征可以用于多个下游任务中。
这篇文章的效果也非常惊艳,下图可以看到,在验证集上仅仅通过很少的像素点就可以恢复出有意义的图像。

特别是95%遮挡的情况,简直让人拍案叫绝!

匿名用户回答:
虽然我很尊重kaiming的工程能力和讲故事的能力,但是这个东西就是bert里面那一套拿过来用吧,cv里面也已经有了beit。就像18年的non local一样,到现在几千个citation,是多少人梦寐以求都达不到的高度,但是和不带mlp的self attention有什么区别吗。包括moco在内的这几篇文章,我觉得kaiming的高明之处在于能把别人想到了但是调不出来的东西调出一个很impressive的结果,给大伙指明下一步能做的方向,但是idea的原创性上真的没有必要捧的那么高。
p.s. 不是喷kaiming,是喷那个“预定了CVPR2022 best paper候选”的标题党回答。
kai.han(北大 智能科学)回答:
大致看了一遍,在iGPT和BEiT的基础上,化繁为简,找出了最关键的点,能够让BERT式预训练在CV上也能训到很好!能比肩GPT3的CV大模型不远矣。
战斗性牧师回答:
东西看完之后我感觉非常amazing,不得不佩服kaiming He大佬的强大。
说一说我对于这篇文章的观点吧
1、我觉得这绝对是一篇标杆性的工作,这是毋容置疑。至于大家说的这不是原本有nlp相关的工作做过这类事情吗?novelty其实就很弱了,其实我要在这里说一句,大家对于novelty和best的理解的格局不够大。
首先我觉得真正的novelty是基于work的前提的,只有work才能说具有novelty,不然就是一个joke。在我的认知范畴里面,工程(后续的影响力)是要大于所谓的novelty。不work,就是天方夜谭,谈何novelty。
其次我觉得一个点子在从一个领域搬运到另一个领域,要work,其实中间的实现过程本身就是一个novelty的过程。那现在我说一句我觉得“我送你们上火星”,但是我做不work,那我非常具有创新性,你们服吗?只有把你们送上了火星的那位,才是novelty,掌握了真正的创新技术。其实总在说我们的模型过拟合了,现在的我们何尝不是对novelty的理解overfitting了。
2、best paper 我觉得我不敢说,但是这至少是我心中的一篇best work。至于是不是best paper,就要看其他的文章怎么样了,现在不做对于cvpr reviewer的判断造成影响的事情。
3、我想我接下来有时间会更加细致的了解他这项工作,已经之前一些大神们对于这类型工作的思考,然后再和大家讨论,一句话:不喜勿喷!
4、最后要说一句:kaiMing He yyds



