 极市平台
极市平台





极市导读
本文用李沁和孙怡的例子简单解释了对比学习的概念,并详细介绍了CPC工作的公式推理。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
Contrastive Learning (对比学习) 是这两年深度学习非常热的话题,可以说是刷新了很多人对无监督学习对认知。最初谷歌写的Representation Learning with Contrastive Predictive Coding (CPC) 公式十分抽象,不好理解。我在做完了一个CPC的项目以后,决定做一张超直观的图帮助大家摆脱公式理解。
在讲CPC之前,我会先在第一部分用脸盲的例子,让大家先理解什么是Contrastive Learning,它为什么有用?它到底是如何学习的。(笔者始终相信,科研创新都是先有直觉(intuition),再有严密的公式推理。如果不明白intuition,是很难真正理解公式的)
第二部分我会用一张自己做的图来解释CPC。
整篇文章我会围绕着理解contrastive learning的关键思想来讲:
构造positive pairs (正样本对) 和 negative pairs (负样本对)
在对比 positive pairs 和 negative pairs 的过程里提高辨识能力
一、发现自己脸盲时,你会怎么做?
很多人都有脸盲的体验,对我而言,脸盲是一大难题。不仅看外国电影会脸盲,连内地明星我也会。比如,假如你在不同的电视剧里分别看到李沁和孙怡两个人,深感困惑到底谁是谁的时候,你会怎么做?如果是我的话,我会去搜一下孙怡长什么样,李沁长什么样
⬇⬇⬇ 孙怡

⬇⬇⬇李沁

我们下意识地,在对比着她俩在不同情景下的图片,通过不断的对比,提升自己【提取特征】的能力。这里样本量可能不够大,这两位明星各三张图片,我仍然难以辨认她们。而对于天天见她们的导演,在日积月累的对比下,想必能抓取到更多特征。而阅人无数的导演,大概是不会像我们这么容易脸盲的。
在这个例子里,我想强调的是,我们在日常生活里,下意识地就会去构建正样本对(孙怡的不同照片,李沁的不同照片),和负样本对(一张孙怡的照片 v.s. 一张李沁的照片)。
对于分辨能力比较弱,没见过多少妆容精致的女明星的我,正样本对和负样本对看起来可能差不多,我可能无法判断正样本对和负样本对,也就是说,从上面六张图里,你挑两张给我,我都不知道是不是同一个人。
而对于不脸盲的人来说,你挑两张图,他可能就知道是不是同一个人。
而我们改善自己脸盲问题的方式,就是不断的去学习,哪对图片是同一个人,哪对是不同人,从而提高分辨能力。
这就是对比学习 (Contrastive Learning)
二、来讲CPC
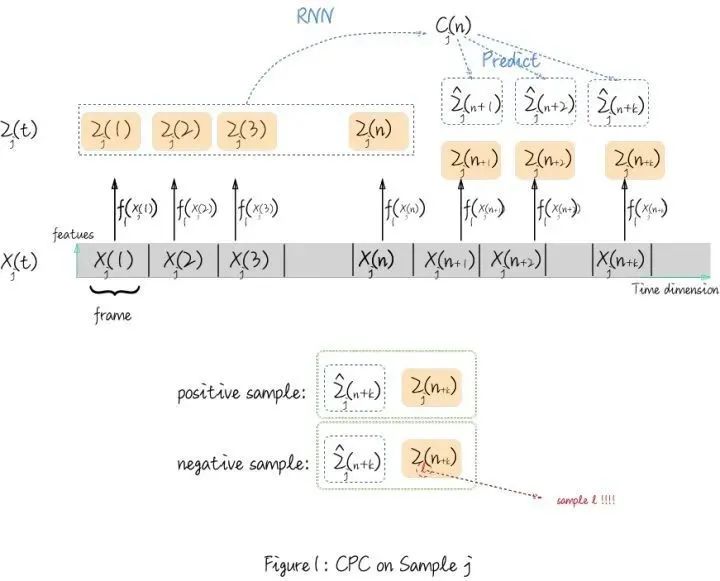
说好无公式,咱真的就不谈公式。
这个图的主要部分是对一个个体的CPC的特征提取过程。请注意脚标 j 代表这是个体 j 。
灰色的长矩阵 代表个体j的时间序列, 对于每一个frame, 我们对它做特征提取 (encode) , 也就是图中的箭头 , 然后每个frame会 得到对应的黄色矩阵
接下来,CPC原文里提到, 它希望学得一些global information,也称 context information。什么是context information呢?举例来说, 你 在看电视剧的时候, 看到了前面几十集 (对应图里的原时间序列 , 作为一个看片 (不对, 看剧) 无数的人,你从前几十集觉察到了他们的感情逐渐有了罏隙(你作为encoder提取了 ,然后,你可能就开始【预言了】: 和 肯定会感情越来越糟糕( 。(context information)。但你其实是无法准确预测后来到底会具体发生什么事情,即
跳出电视剧来说,CPC会在样本里随机选一个时间点 ,把 前面提取到的所有的 用一个回归模型来总结前面所有信息(比如用 RNN得到图里的 ) ,然后用线性变换去预测出 。
【重点来了】
那么怎么对比学习呢?
理想来说, 你是一个阅剧无数的人,那么从这个电视剧后面的真实剧情 的感情走向 和你预测 的感情走向 应该是极为相似的。
如果此时有人谈到另一个电视剧 (你看的电视剧叫 ) 的感情走向 ,那你一定能判断出他在谈的不是你在看的电视剧 可是如果你是一个小孩(初始化的神经网络,你可能就无法分辨不同剧的感情走向是不是对应的)
就像很多人模仿某作家的文风会被专业人士看出,却能欺骗过大众。
所以,正样本对和负样本对的定义是这样的:

(这里的k可以取1, 2, ..., K), K是你认为最多能预测的timestep
那么网络到底是怎么进行学习的呢??
对不起,下面不得不有个公式:
定义对于单独一个样本j的NCE Loss:
这里f是一个相似度衡量函数,可以直接用exp(内积( ))。(之所以不用MSE是因为CPC并不想要element wise的一致,而希望更全局的slowly changed 信息一致,希望mutual information一致)
这里分母的m=1,....,N 是采样的不是j的个体的embedding,通常取一个batch里的所有样本(包括样本j)。这样做比较方便写代码和计算。(不过Kaiming He最近有paper提出从batch之外采样效果更好)
现在我们来看,对于牛逼的神经网络,分子的相似度应该很高,值会很大。
而分母的每一项,除了m=j 的时候,其他项都应该非常小,甚至接近于0。
那么整个Ioss就会 而对于什么都不会的神经网络, 假如是random guess, 那么 (瞎猜情况) (理想情况)
所以,我们的只要minimize这个L,就是在优化这个神经网络, 让它越来越能辨识正负样本对。
三、总结
这就是CPC的整个学习过程,通过这个正负样本对的loss来更新网络的所有参数。你可以理解为,逼着它更新特征提取器来学会辨识正负样本对。
更广一点contrastive learning的工作的思想也是这样的,只是正负样本对的构建方式不一样。
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“CVPR21检测”获取CVPR2021目标检测论文下载~


# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~


