 机器学习AI算法工程
机器学习AI算法工程





向AI转型的程序员都关注了这个号👇👇👇
机器学习AI算法工程 公众号:datayx
1、介绍tensorRT,和本课程、以及涉及的框架
2、介绍tensorRT驾驭的几种方案,以及推荐框架
3、正确导出onnx并在c++中使用
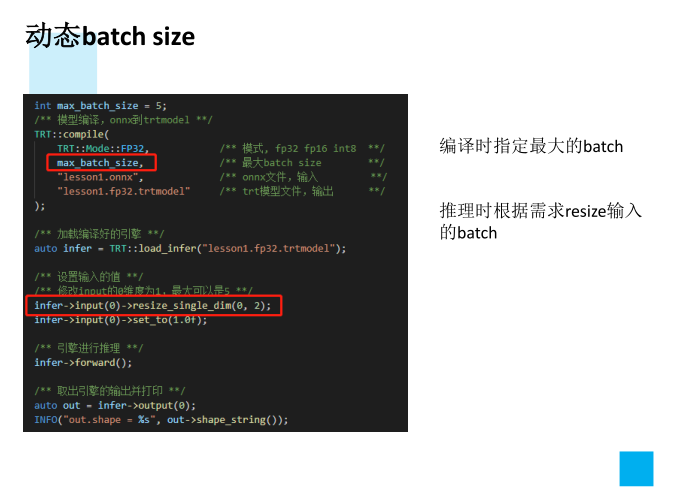
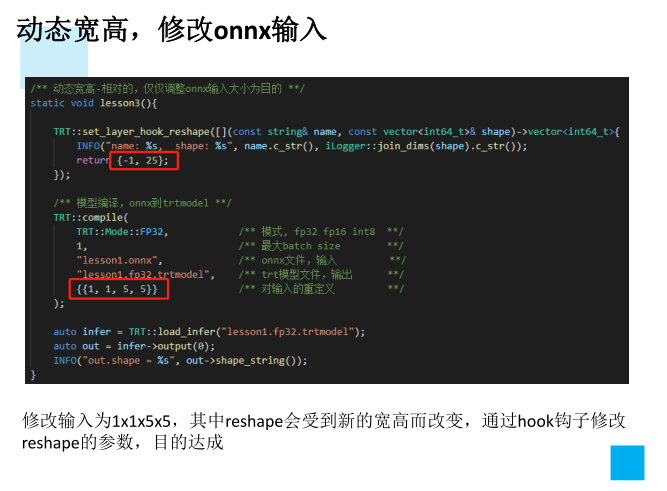
4、动态batch和动态宽高的实现方案
5、实现一个插件
6、关于封装
7、yolov5案例
8、retinaface案例
9、高性能低耦合
10、便捷性
tensorRT,nvidia发布的dnn推理引擎,是针对nvidia系列硬件进行优化加速,实现最大程度的利用GPU资源,提升推理性能
tensorRT是业内nvidia系列产品部署落地时的最佳选择
这个课程主要围绕着https://github.com/shouxieai/tensorRT_cpp提供的方案开展讨论,使得能够使用、部署起来
该教程,讲驾驭tensorRT,实现从模型导出,到c++/python推理加速,再到高性能、低耦合、有效、便捷的工程落地方案
以最终可用、好用为出发点
需要的知识点:
1、对深度学习的认识,CV相关知识,PyTorch
2、ONNX的认识,Netron工具的简单使用
3、C++和python能力
4、一定程度的cuda能力,了解tensorRT
课程内容:
1、如何正确的导出onnx
2、如何在c++中使用起来
3、动态batch,和动态宽高的处理方式
4、实现一个自定义插件
5、c++中推理实现高性能低耦合的方法
项目代码,视频讲解,PPT 获取方式:
关注微信公众号 datayx 然后回复 trt 即可获取。
驾驭TensorRT的方案介绍
TensorRT提供基于C++接口的构建模型方案
TensorRT-8.0.1.6/samples/sampleMNISTAPI/sampleMNISTAPI.cpp
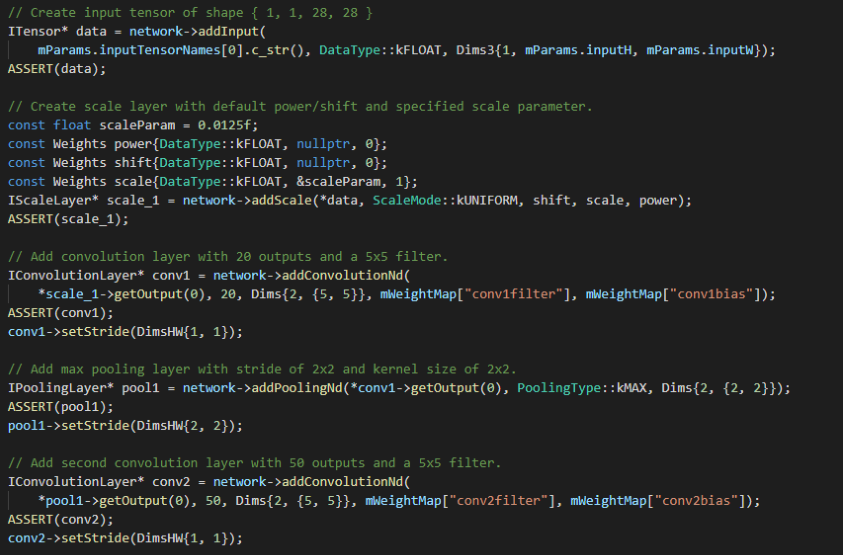
以C++接口为主,进而提供了python的接口
TensorRT-8.0.1.6/samples/python/engine_refit_mnist/sample.py

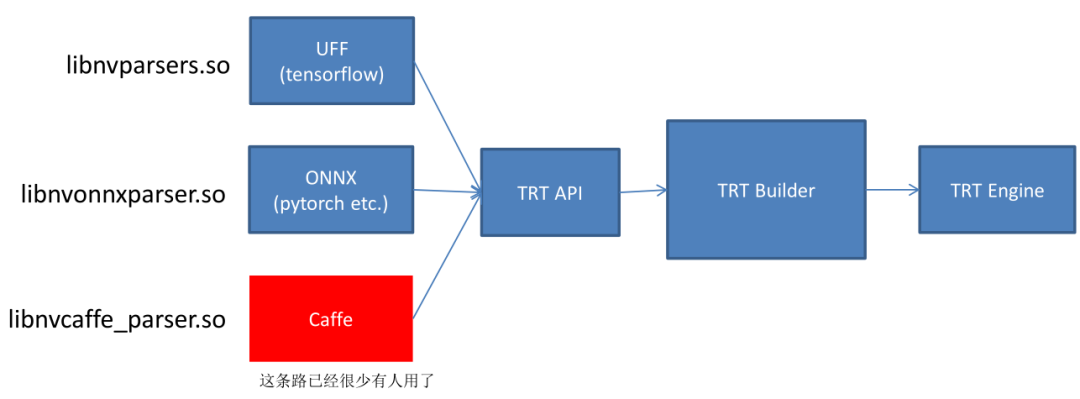
基于tensorRT的发布,又有人在之上做了工作
repo1,https://github.com/wang-xinyu/tensorrtx
为每个模型写硬代码


repo2,https://github.com/NVIDIA-AI-IOT/torch2trt
为每个算子写Converter,反射Module.forward捕获输入输出和图结构

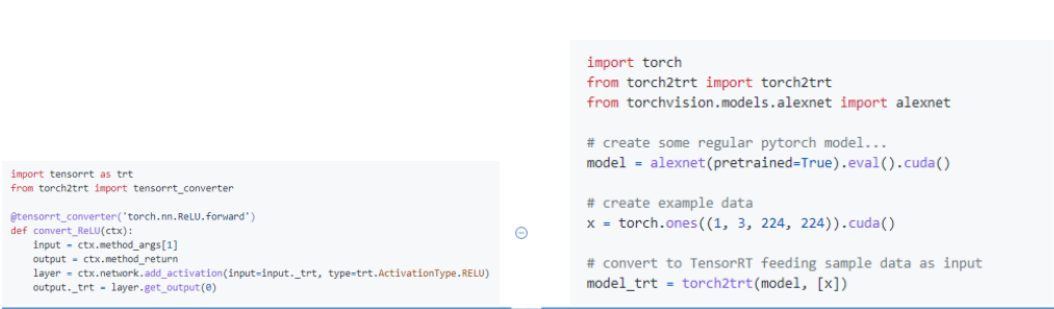

repo3(推荐方案),https://github.com/shouxieai/tensorRT_cpp
基于ONNX路线,提供C++、Python接口,深度定制ONNXParser,低耦合封装,实现常用模型YoloX、YoloV5、RetinaFace、Arcface、SCRFD、DeepSORT
算子由官方维护,模型直接导出



C++接口,YoloX三行代码

Python接口

如何正确的导出onnx
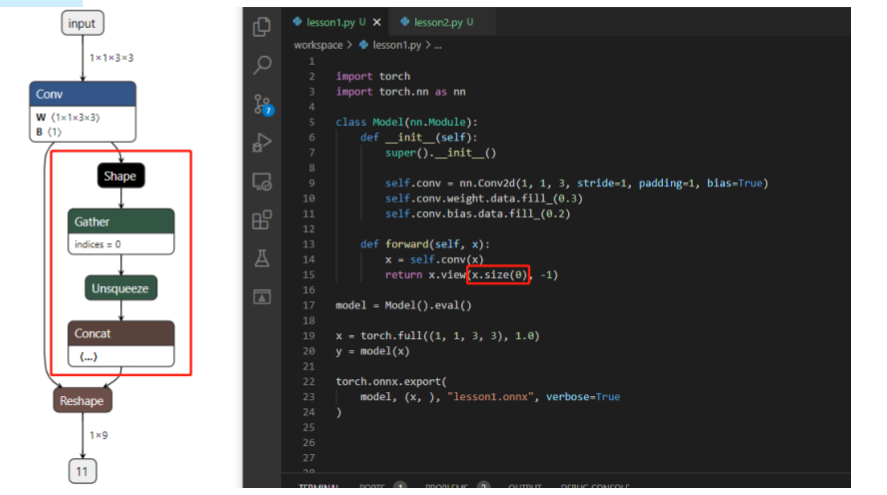
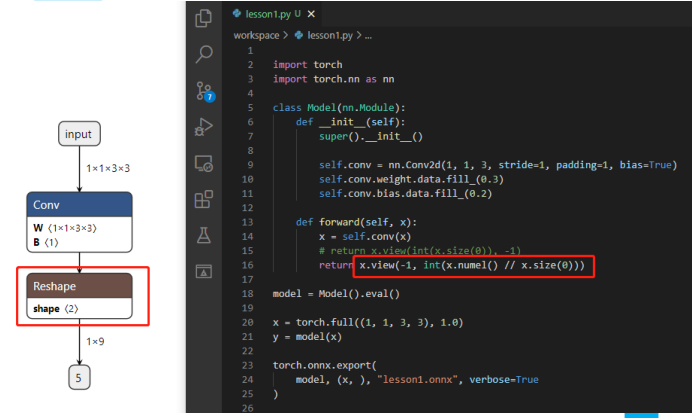
1.对于任何用到shape、size返回值的参数时,例如:tensor.view(tensor.size(0),-1)这类操作,避免直接使用tensor.size的返回值,而是加上int转换,tensor.view(int(tensor.size(0)), -1)
2.对于nn.Upsample或nn.functional.interpolate函数,使用scale_factor指定倍率,而不是使用size参数指定大小
3.对于reshape、view操作时,-1的指定请放到batch维度。其他维度可以计算出来即可。batch维度禁止指定为大于-1的明确数字
4.torch.onnx.export指定dynamic_axes参数,并且只指定batch维度。我们只需要动态batch,相对动态的宽高有其他方案
5.使用opset_version=11,不要低于11
6.避免使用inplace操作,例如y[…,0:2] = y[…, 0:2] * 2 - 0.5
7.掌握了这些,就可以保证后面各种情况的顺利了●
这些做法的必要性体现在,简化过程的复杂度,去掉gather、shape类的节点,很多时候,部分不这么改看似也是可以但是需求复杂后,依旧存在各类问题。按照说的这么修改,基本总能成。


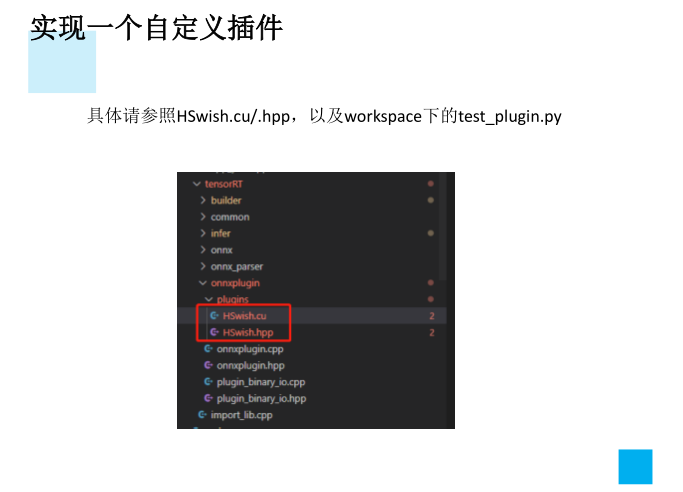
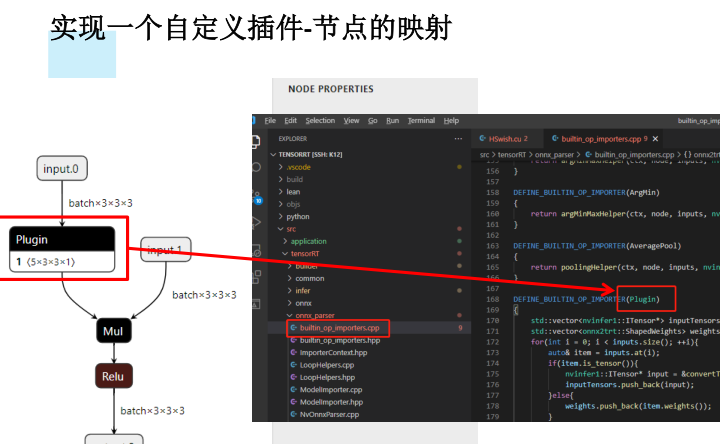
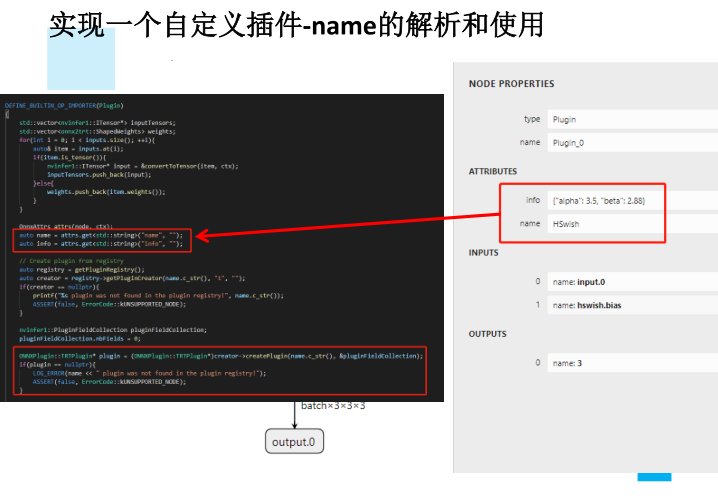
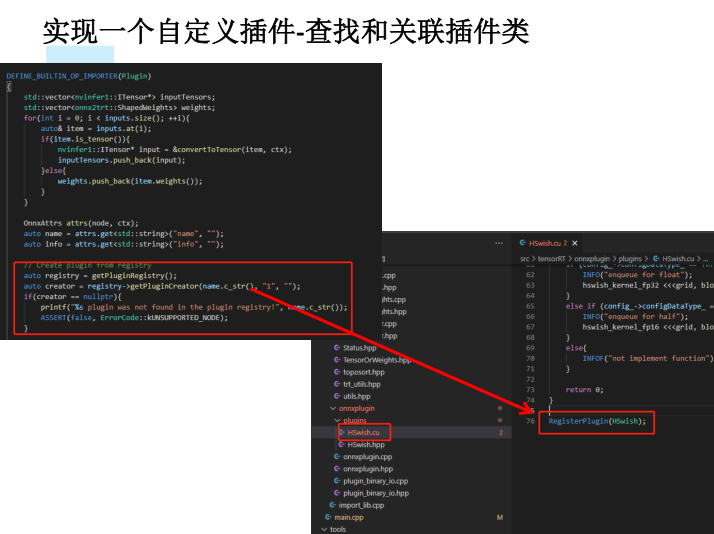
实现一个自定义插件
流程简介:
导出环节:
1.对需要插件的layer,写一个类A,继承自torch.autograd.Function2.对这个类A增加symbolic的静态方法,其中返回g.op(),名称给Plugin,name_s为插件名称,info可以带上string类型信息3.对这个类A增加forward的静态方法,使得其可以被pytorch正常推理,此时的forward内的任何操作不会被跟踪并记录到onnx中。通常直接返回个对等大小和数量的tensor即可,不一定要完全实现功能4.实现一个OP的类,继承自nn.Module,在OP.forward中调用A.apply5.正常使用OP集成到模型中即可●
编译/推理环节:
1.在src/tensorRT/onnxplugin/plugins中写cu和hpp文件,参照Hswish2.实现类继承自TRTPlugin,
a. new_config用于返回自定义config类并进行配置
b. getOutputDimensions返回layer处理后的tensor大小
c. enqueue实现具体推理工作
关于封装
Tenosr封装
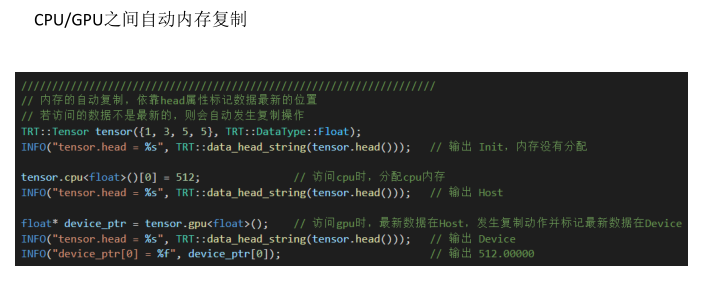
CPU/GPU内存自动分配释放,内存复用
CPU/GPU之间自动内存复制
计算维度的偏移量


Builder封装
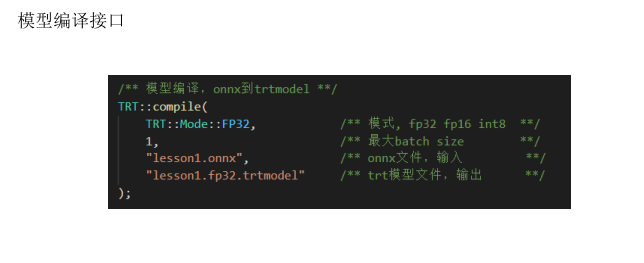
模型编译接口
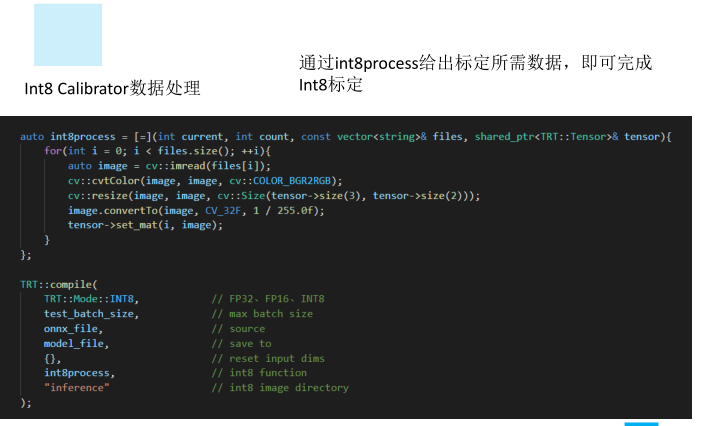
Int8 Calibrator数据处理
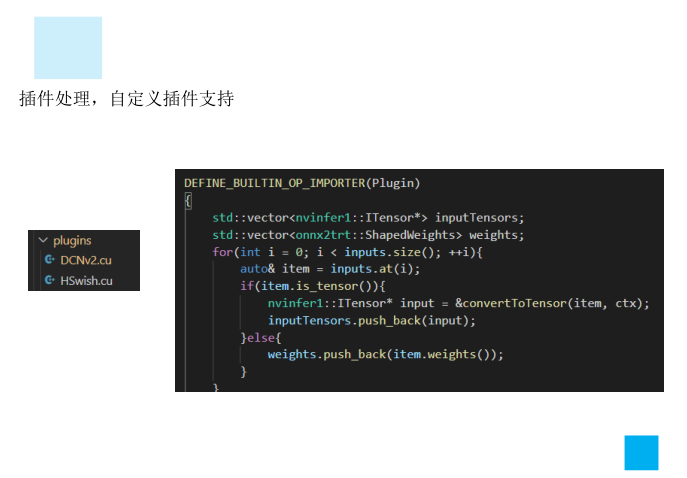
插件处理,自定义插件支持
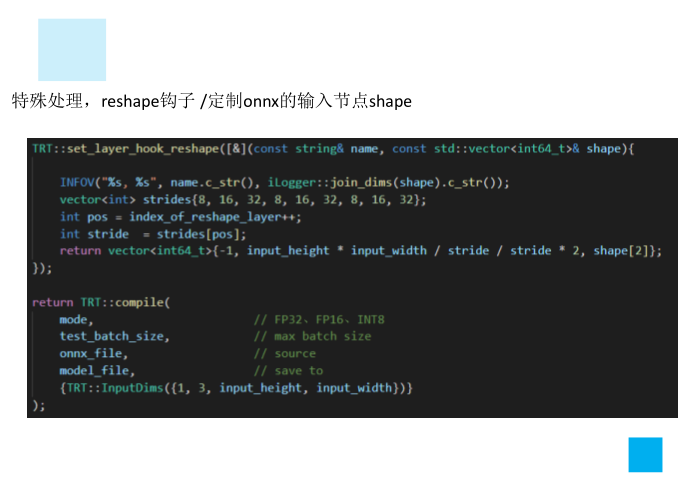
特殊处理,reshape钩子
定制onnx的输入节点shape
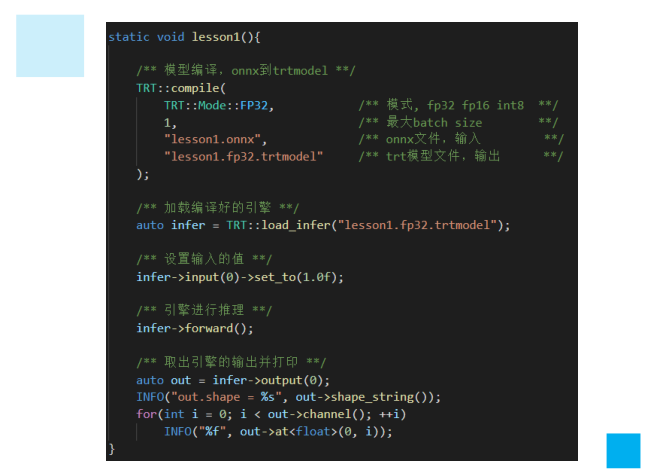
Infer封装
1.抽象input和output关系,避免手动去操作binding
降低tensorRT使用门槛、和集成难度,避免重复代码,关注业务逻辑,而非复杂的细节。因此做了封装
1、Tensor类,实现张量的内存管理、维度管理、偏移量计算、cpu/gpu相互自动拷贝。避免手动管理内存、计算偏移量
2、Infer类,实现tensorRT引擎的推理管理,自动关联引擎的输入、输出,或者名称映射,管理上下文,插件
3、Builder,实现onnx到引擎转换的封装,int8封装,少数几行代码实现需求
4、plugin,封装插件的细节、序列化、反序列化、creator、tensor和weight等,只需要关注具体推理部分,避免面临大量复杂情况
YoloV5案例
https://github.com/ultralytics/YOLOv5
Retinaface案例
https://github.com/biubug6/Pytorch_Retinaface
高性能的注意点:
单模型推理时的性能问题:
1、尽量使得GPU高密集度运行,避免出现CPU、GPU相互交换运行
2、尽可能使tensorRT运行多个batch 数据。与第一点相合
3、预处理尽量cuda化,例如图像需要做normalize、reisze、warpaffine、bgr2rgb等,在这里,采用cuda核实现warpaffine+normalize等操作,集中在一起性能好
4、后处理尽量cuda化,例如decode、nms等。在这里用cuda核实现了decode和nms
5、善于使用cudaStream,将操作加入流中,采用异步操作避免等待
6、内存复用
系统级别的性能问题:
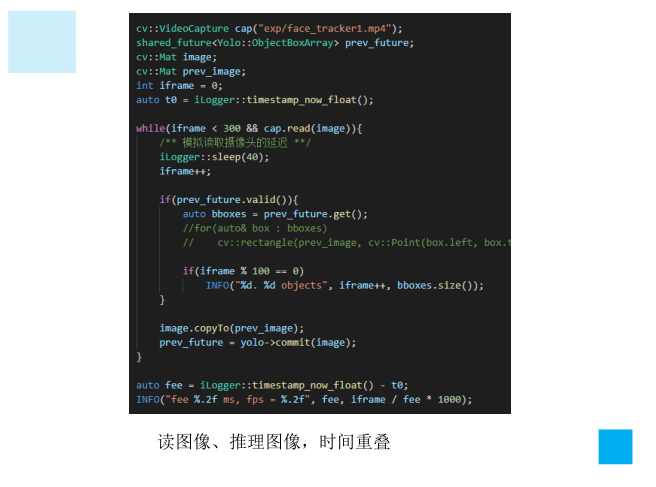
1、如何实现尽可能让单模型使用多batch,此时future、promise就是很好的工具
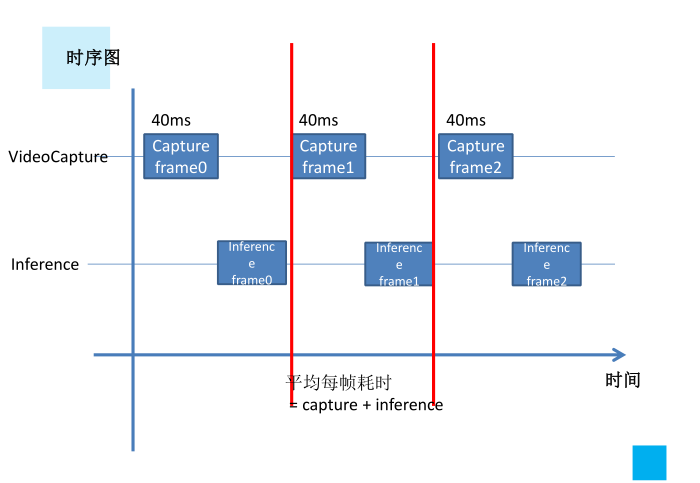
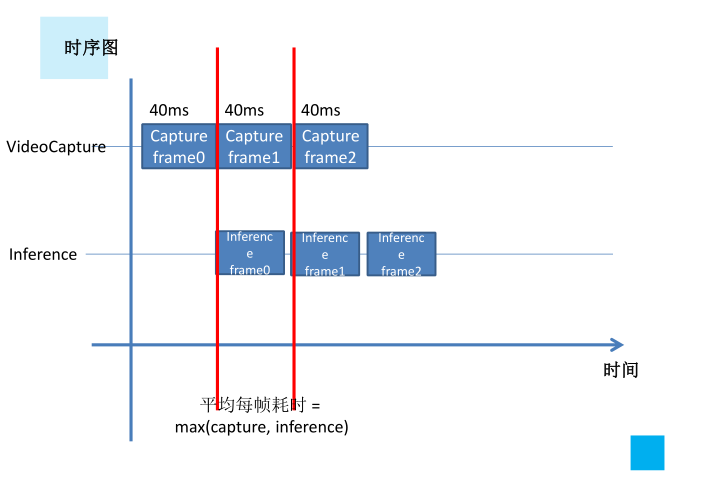
2、时序图要尽可能优化,分析并绘制出来,不必的等待应该消除,同样是promise、future带来的好处
3、尤其是图像读取和模型推理最常用的场景下,可以分析时序图,缓存一帧的结果,即可实现帧率的大幅提升

传统的队列方式,收集结果困难
例如:
1、image需要先给到yolo检测框得到box
2、image和box交给pose抠图识别关键点keys
3、keys、box绘制到image,并显示出来
如果串行时序图,效率低。如果队列,收集结果困难
推荐使用promise和future,未来给到结果
参照tensorRT/src/application/app_yolo/yolo.cpp的commit部分
低耦合:
隔离业务逻辑和tensorRT推理过程,分开调试,逻辑调试逻辑,推理调试推理,不应该耦合起来。对于高性能的处理,也应该在推理中实现,对使用者透明。最好的解决方案,即封装
参照tensorRT/src/application/app_yolo/yolo.cpp的commit部分
便捷性上讲,例如anchor base的模型,通常会需要计算anchor,需要储存xxx.onnx和xxx.anchor.txt,一起做编译推理。这样做常需要两个文件同时存在。其次,解码为框过程还比较繁琐
推荐的做法,例如yolov5做的,在导出onnx时,将输出与anchor做完操作后合并为一个(torch.cat)。此时模型与anchor信息融为一体,并且输出的结果就已经是计算好的box,只需要做nms即可完成解码。操作方便简单
机器学习算法AI大数据技术
搜索公众号添加: datanlp

长按图片,识别二维码
阅读过本文的人还看了以下文章:
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx


