 开发者全社区
开发者全社区











不敢想象你们把这只AI塞进手机里的样子。





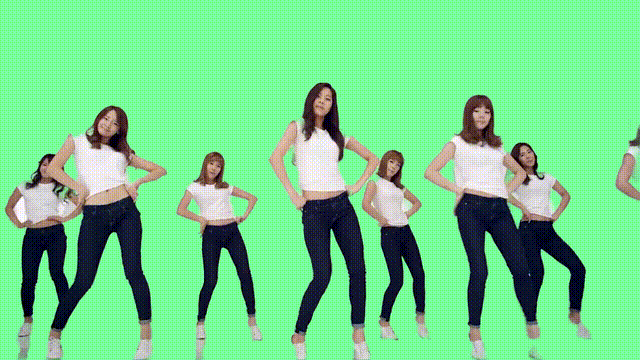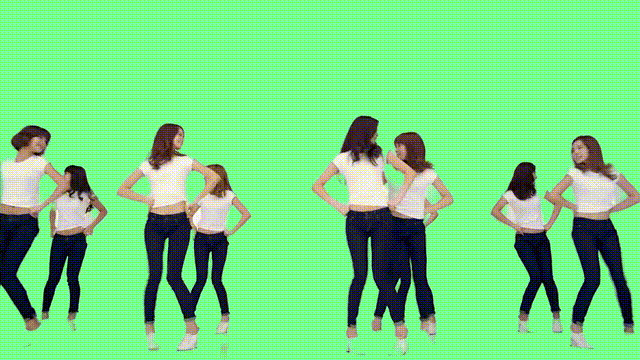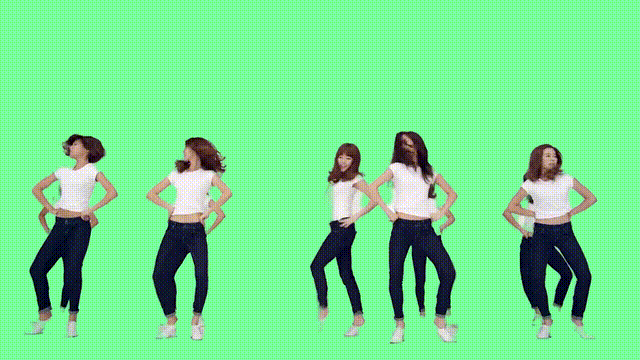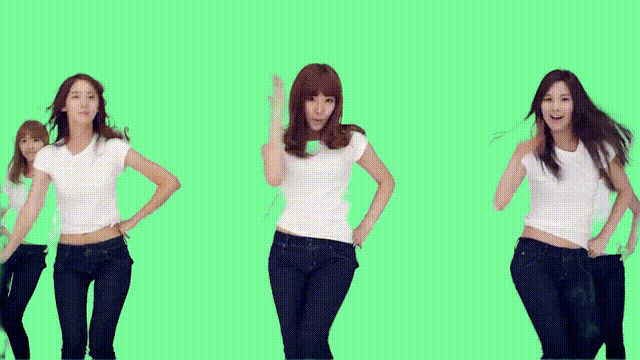
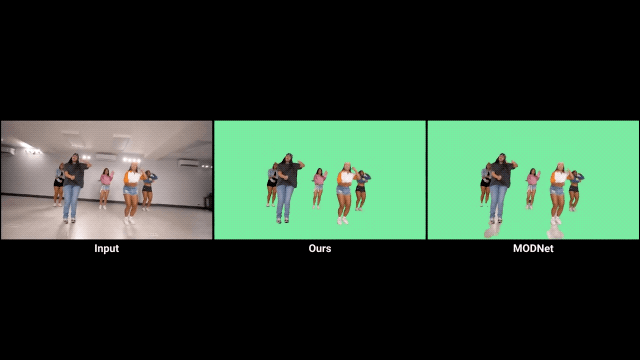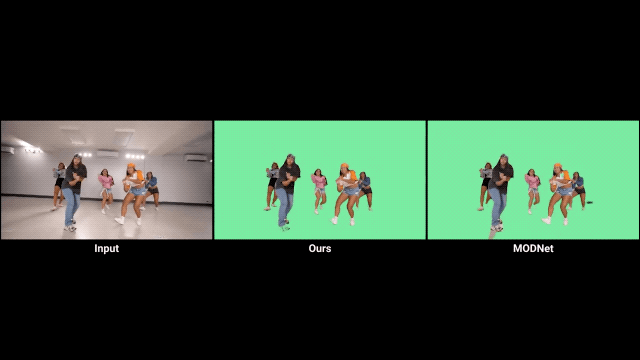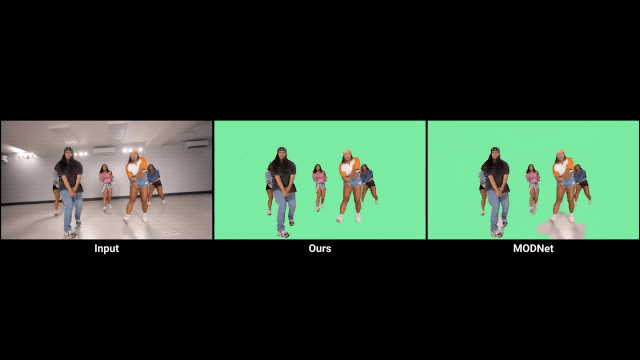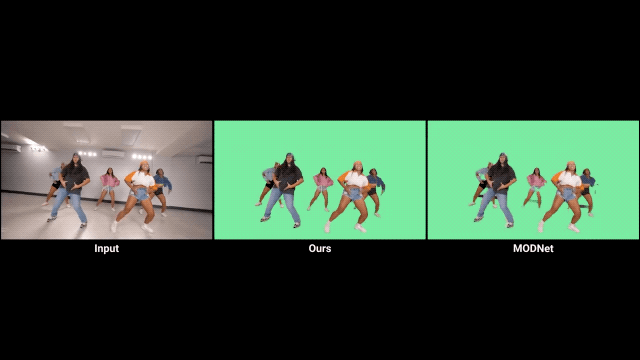


利用时间信息
那么这样的“魔法”,具体又是如何实现的?
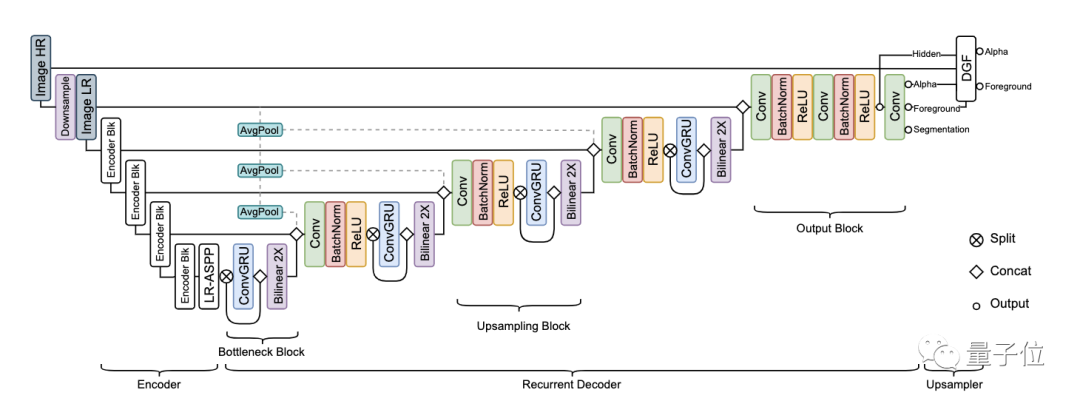

首先,人像抠图与人像分割任务密切相关,AI必须学会从语义上理解场景,才能在定位人物主体方面具备鲁棒性。 其次,现有的大部分抠图数据集只提供真实的alpha通道和前景信息,所以必须对背景图像进行合成。但前景和背景的光照往往不同,这就影响了合成的效果。语义分割数据集的引入可以有效防止过拟合。 最后,语义分割数据集拥有更为丰富的训练数据。

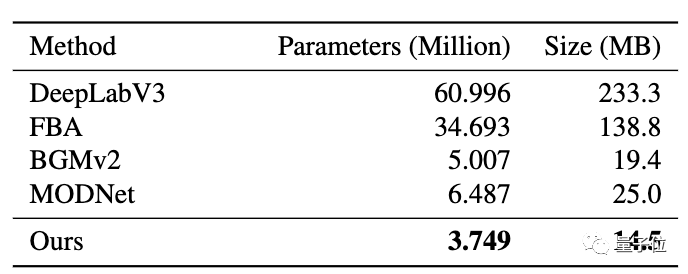
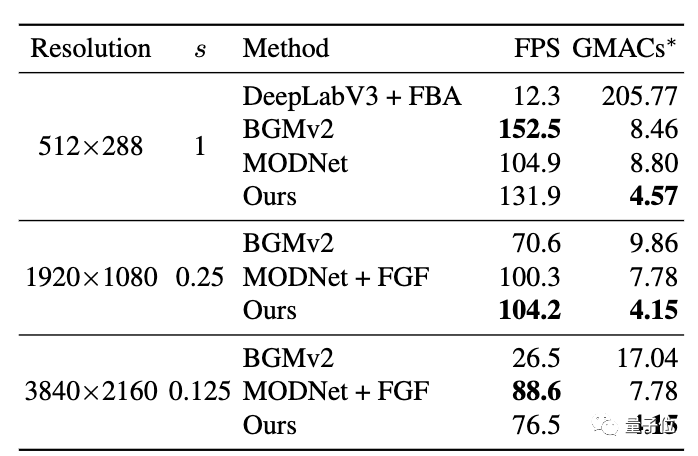
一作字节跳动实习生





地址:
https://peterl1n.github.io/RobustVideoMatting/#/demo
GitHub地址:
https://github.com/PeterL1n/RobustVideoMatting
论文地址:
https://arxiv.org/abs/2108.11515
参考链接:
https://www.reddit.com/r/MachineLearning/comments/pdbpmg/r_robust_highresolution_video_matting_with

