 Python之王
Python之王




Pandas的应用
Pandas是Wes McKinney在2008年开发的一个强大的「分析结构化数据」的工具集。Pandas以NumPy为基础(数据表示和运算),提供了用于数据处理的函数和方法,对数据分析和数据挖掘提供了很好的支持;同时Pandas还可以跟数据可视化工具Matplotlib很好的整合在一起,非常轻松愉快的实现数据的可视化展示。
Pandas核心的数据类型是Series(数据系列)、DataFrame(数据表/数据框),分别用于处理一维和二维的数据,除此之外还有一个名为Index的类型及其子类型,它为Series和DataFrame提供了索引功能。日常工作中以DataFrame使用最为广泛,因为二维的数据本质就是一个有行有列的表格(想一想Excel电子表格和关系型数据库中的二维表)。上述这些类型都提供了大量的处理数据的方法,数据分析师可以以此为基础实现对数据的各种常规处理。
Series的应用
Pandas库中的Series对象可以用来表示一维数据结构,跟数组非常类似,但是多了一些额外的功能。Series的内部结构包含了两个数组,其中一个用来保存数据,另一个用来保存数据的索引。
创建Series对象
「提示」:在执行下面的代码之前,请先导入
pandas以及相关的库文件,具体的做法可以参考上一章。
方法1:通过列表或数组创建Series对象。
代码:
# data参数表示数据,index参数表示数据的索引(标签)
# 如果没有指定index属性,默认使用数字索引
ser1 = pd.Series(data=[320, 180, 300, 405], index=['一季度', '二季度', '三季度', '四季度'])
ser1输出:
一季度 320
二季度 180
三季度 300
四季度 405
dtype: int64方法2:通过字典创建Series对象。
代码:
# 字典中的键就是数据的索引(标签),字典中的值就是数据
ser2 = pd.Series({'一季度': 320, '二季度': 180, '三季度': 300, '四季度': 405})
ser2输出:
一季度 320
二季度 180
三季度 300
四季度 405
dtype: int64
索引和切片
跟数组一样,Series对象也可以进行索引和切片操作,不同的是Series对象因为内部维护了一个保存索引的数组,所以除了可以使用整数索引通过位置检索数据外,还可以通过自己设置的索引标签获取对应的数据。
使用整数索引
代码:
print(ser2[0], ser[1], ser[2], ser[3])
ser2[0], ser2[3] = 350, 360
print(ser2)输出:
320 180 300 405
一季度 350
二季度 180
三季度 300
四季度 360
dtype: int64「提示」:如果要使用负向索引,必须在创建
Series对象时通过index属性指定非数值类型的标签。使用自定义的标签索引
代码:
print(ser2['一季度'], ser2['三季度'])
ser2['一季度'] = 380
print(ser2)输出:
350 300
一季度 380
二季度 180
三季度 300
四季度 360
dtype: int64切片操作
代码:
print(ser2[1:3])
print(ser2['二季度':'四季度'])输出:
二季度 180
三季度 300
dtype: int64
二季度 500
三季度 500
四季度 520
dtype: int64代码:
ser2[1:3] = 400, 500
ser2输出:
一季度 380
二季度 400
三季度 500
四季度 360
dtype: int64花式索引
代码:
print(ser2[['二季度', '四季度']])
ser2[['二季度', '四季度']] = 500, 520
print(ser2)输出:
二季度 400
四季度 360
dtype: int64
一季度 380
二季度 500
三季度 500
四季度 520
dtype: int64布尔索引
代码:
ser2[ser2 >= 500]输出:
二季度 500
三季度 500
四季度 520
dtype: int64
####属性和方法
Series对象的常用属性如下表所示。
| 属性 | 说明 |
|---|---|
dtype / dtypes | 返回Series对象的数据类型 |
hasnans | 判断Series对象中有没有空值 |
at / iat | 通过索引访问Series对象中的单个值 |
loc / iloc | 通过一组索引访问Series对象中的一组值 |
index | 返回Series对象的索引 |
is_monotonic | 判断Series对象中的数据是否单调 |
is_monotonic_increasing | 判断Series对象中的数据是否单调递增 |
is_monotonic_decreasing | 判断Series对象中的数据是否单调递减 |
is_unique | 判断Series对象中的数据是否独一无二 |
size | 返回Series对象中元素的个数 |
values | 以ndarray的方式返回Series对象中的值 |
Series对象的方法很多,我们通过下面的代码为大家介绍一些常用的方法。
统计相关的方法
Series对象支持各种获取描述性统计信息的方法。代码:
# 求和
print(ser2.sum())
# 求均值
print(ser2.mean())
# 求最大
print(ser2.max())
# 求最小
print(ser2.min())
# 计数
print(ser2.count())
# 求标准差
print(ser2.std())
# 求方差
print(ser2.var())
# 求中位数
print(ser2.median())输出:
1900
475.0
520
380
4
64.03124237432849
4100.0
500.0Series对象还有一个名为describe()的方法,可以获得上述所有的描述性统计信息,如下所示。代码:
ser2.describe()输出:
count 4.000000
mean 475.000000
std 64.031242
min 380.000000
25% 470.000000
50% 500.000000
75% 505.000000
max 520.000000
dtype: float64「提示」:因为
describe()返回的也是一个Series对象,所以也可以用ser2.describe()['mean']来获取平均值。如果
Series对象有重复的值,我们可以使用unique()方法获得去重之后的Series对象;可以使用nunique()方法统计不重复值的数量;如果想要统计每个值重复的次数,可以使用value_counts()方法,这个方法会返回一个Series对象,它的索引就是原来的Series对象中的值,而每个值出现的次数就是返回的Series对象中的数据,在默认情况下会按照出现次数做降序排列。代码:
ser3 = pd.Series(data=['apple', 'banana', 'apple', 'pitaya', 'apple', 'pitaya', 'durian'])
ser3.value_counts()输出:
apple 3
pitaya 2
durian 1
banana 1
dtype: int64代码:
ser3.nunique()输出:
4数据处理的方法
Series对象的isnull()和notnull()方法可以用于空值的判断,代码如下所示。代码:
ser4 = pd.Series(data=[10, 20, np.NaN, 30, np.NaN])
ser4.isnull()输出:
0 False
1 False
2 True
3 False
4 True
dtype: bool代码:
ser4.notnull()输出:
0 True
1 True
2 False
3 True
4 False
dtype: boolSeries对象的dropna()和fillna()方法分别用来删除空值和填充空值,具体的用法如下所示。代码:
ser4.dropna()输出:
0 10.0
1 20.0
3 30.0
dtype: float64代码:
# 将空值填充为40
ser4.fillna(value=40)输出:
0 10.0
1 20.0
2 40.0
3 30.0
4 40.0
dtype: float64代码:
# backfill或bfill表示用后一个元素的值填充空值
# ffill或pad表示用前一个元素的值填充空值
ser4.fillna(method='ffill')输出:
0 10.0
1 20.0
2 20.0
3 30.0
4 30.0
dtype: float64需要提醒大家注意的是,
dropna()和fillna()方法都有一个名为inplace的参数,它的默认值是False,表示删除空值或填充空值不会修改原来的Series对象,而是返回一个新的Series对象来表示删除或填充空值后的数据系列,如果将inplace参数的值修改为True,那么删除或填充空值会就地操作,直接修改原来的Series对象,那么方法的返回值是None。后面我们会接触到的很多方法,包括DataFrame对象的很多方法都会有这个参数,它们的意义跟这里是一样的。Series对象的mask()和where()方法可以将满足或不满足条件的值进行替换,如下所示。代码:
ser5 = pd.Series(range(5))
ser5.where(ser5 > 0)输出:
0 NaN
1 1.0
2 2.0
3 3.0
4 4.0
dtype: float64代码:
ser5.where(ser5 > 1, 10)输出:
0 10
1 10
2 2
3 3
4 4
dtype: int64代码:
ser5.mask(ser5 > 1, 10)输出:
0 0
1 1
2 10
3 10
4 10
dtype: int64Series对象的duplicated()方法可以帮助我们找出重复的数据,而drop_duplicates()方法可以帮我们删除重复数据。代码:
ser3.duplicated()输出:
0 False
1 False
2 True
3 False
4 True
5 True
6 False
dtype: bool代码:
ser3.drop_duplicates()输出:
0 apple
1 banana
3 pitaya
6 durian
dtype: objectSeries对象的apply()和map()方法非常重要,它们可以用于数据处理,把数据映射或转换成我们期望的样子,这个操作在数据分析的数据准备阶段非常重要。代码:
ser6 = pd.Series(['cat', 'dog', np.nan, 'rabbit'])
ser6输出:
0 cat
1 dog
2 NaN
3 rabbit
dtype: object代码:
ser6.map({'cat': 'kitten', 'dog': 'puppy'})输出:
0 kitten
1 puppy
2 NaN
3 NaN
dtype: object代码:
ser6.map('I am a {}'.format, na_action='ignore')输出:
0 I am a cat
1 I am a dog
2 NaN
3 I am a rabbit
dtype: object代码:
ser7 = pd.Series([20, 21, 12], index=['London', 'New York', 'Helsinki'])
ser7输出:
London 20
New York 21
Helsinki 12
dtype: int64代码:
ser7.apply(np.square)输出:
London 400
New York 441
Helsinki 144
dtype: int64代码:
ser7.apply(lambda x, value: x - value, args=(5, ))输出:
London 15
New York 16
Helsinki 7
dtype: int64排序和取头部值的方法
Series对象的sort_index()和sort_values()方法可以用于对索引和数据的排序,排序方法有一个名为ascending的布尔类型参数,该参数用于控制排序的结果是升序还是降序;而名为kind的参数则用来控制排序使用的算法,默认使用了quicksort,也可以选择mergesort或heapsort;如果存在空值,那么可以用na_position参数空值放在最前还是最后,默认是last,代码如下所示。代码:
ser8 = pd.Series(
data=[35, 96, 12, 57, 25, 89],
index=['grape', 'banana', 'pitaya', 'apple', 'peach', 'orange']
)
# 按值从小到大排序
ser8.sort_values()输出:
pitaya 12
peach 25
grape 35
apple 57
orange 89
banana 96
dtype: int64代码:
# 按索引从大到小排序
ser8.sort_index(ascending=False)输出:
pitaya 12
peach 25
orange 89
grape 35
banana 96
apple 57
dtype: int64如果要从
Series对象中找出元素中最大或最小的“Top-N”,实际上是不需要对所有的值进行排序的,可以使用nlargest()和nsmallest()方法来完成,如下所示。代码:
# 值最大的3个
ser8.nlargest(3)输出:
banana 96
orange 89
apple 57
dtype: int64代码:
# 值最小的2个
ser8.nsmallest(2)输出:
pitaya 12
peach 25
dtype: int64
绘制图表
Series对象有一个名为plot的方法可以用来生成图表,如果选择生成折线图、饼图、柱状图等,默认会使用Series对象的索引作为横坐标,使用Series对象的数据作为纵坐标。
首先导入matplotlib中pyplot模块并进行必要的配置。
import matplotlib.pyplot as plt
# 配置支持中文的非衬线字体(默认的字体无法显示中文)
plt.rcParams['font.sans-serif'] = ['SimHei', ]
# 使用指定的中文字体时需要下面的配置来避免负号无法显示
plt.rcParams['axes.unicode_minus'] = False
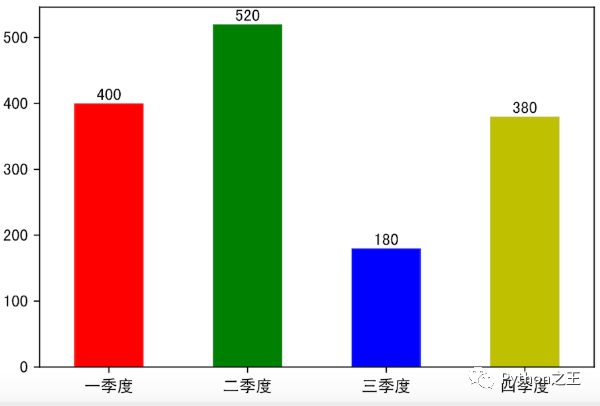
创建Series对象并绘制对应的柱状图。
ser9 = pd.Series({'一季度': 400, '二季度': 520, '三季度': 180, '四季度': 380})
# 通过Series对象的plot方法绘图(kind='bar'表示绘制柱状图)
ser9.plot(kind='bar', color=['r', 'g', 'b', 'y'])
# x轴的坐标旋转到0度(中文水平显示)
plt.xticks(rotation=0)
# 在柱状图的柱子上绘制数字
for i in range(4):
plt.text(i, ser9[i] + 5, ser9[i], ha='center')
# 显示图像
plt.show()
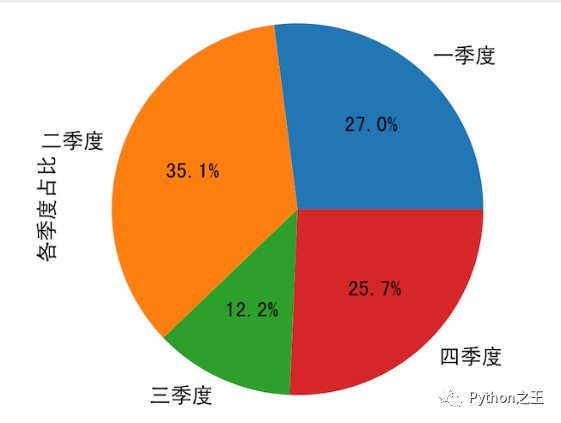
绘制反映每个季度占比的饼图。
# autopct参数可以配置在饼图上显示每块饼的占比
ser9.plot(kind='pie', autopct='%.1f%%')
# 设置y轴的标签(显示在饼图左侧的文字)
plt.ylabel('各季度占比')
plt.show()
DataFrame的应用
创建DataFrame对象
通过二维数组创建
DataFrame对象。代码:
scores = np.random.randint(60, 101, (5, 3))
courses = ['语文', '数学', '英语']
ids = [1001, 1002, 1003, 1004, 1005]
df1 = pd.DataFrame(data=scores, columns=courses, index=ids)
df1输出:
语文 数学 英语
1001 69 80 79
1002 71 60 100
1003 94 81 93
1004 88 88 67
1005 82 66 60通过字典创建
DataFrame对象。代码:
scores = {
'语文': [62, 72, 93, 88, 93],
'数学': [95, 65, 86, 66, 87],
'英语': [66, 75, 82, 69, 82],
}
ids = [1001, 1002, 1003, 1004, 1005]
df2 = pd.DataFrame(data=scores, index=ids)
df2输出:
语文 数学 英语
1001 69 80 79
1002 71 60 100
1003 94 81 93
1004 88 88 67
1005 82 66 60读取CSV文件创建
DataFrame对象。可以通过
pandas模块的read_csv函数来读取CSV文件,read_csv函数的参数非常多,下面接受几个比较重要的参数。代码:
df3 = pd.read_csv('2018年北京积分落户数据.csv', index_col='id')
df3输出:
name birthday company score
id
1 杨x 1972-12 北京利德xxxx 122.59
2 纪x 1974-12 北京航天xxxx 121.25
3 王x 1974-05 品牌联盟xxxx 118.96
4 杨x 1975-07 中科专利xxxx 118.21
5 张x 1974-11 北京阿里xxxx 117.79
... ... ... ... ...
6015 孙x 1978-08 华为海洋xxxx 90.75
6016 刘x 1976-11 福斯流体xxxx 90.75
6017 周x 1977-10 赢创德固xxxx 90.75
6018 赵x 1979-07 澳科利耳xxxx 90.75
6019 贺x 1981-06 北京宝洁xxxx 90.75
6019 rows × 4 columns「说明」:如果需要上面例子中的CSV文件,可以通过下面的百度云盘地址进行获取,数据在《从零开始学数据分析》目录中。链接:https://pan.baidu.com/s/1rQujl5RQn9R7PadB2Z5g_g,提取码:e7b4。
sep/delimiter:分隔符,默认是,。header:表头(列索引)的位置,默认值是infer,用第一行的内容作为表头(列索引)。index_col:用作行索引(标签)的列。usecols:需要加载的列,可以使用序号或者列名。true_values/false_values:哪些值被视为布尔值True/False。skiprows:通过行号、索引或函数指定需要跳过的行。skipfooter:要跳过的末尾行数。nrows:需要读取的行数。na_values:哪些值被视为空值。读取Excel文件创建
DataFrame对象。可以通过
pandas模块的read_excel函数来读取Excel文件,该函数与上面的read_csv非常相近,多了一个sheet_name参数来指定数据表的名称,但是不同于CSV文件,没有sep或delimiter这样的参数。下面的代码中,read_excel函数的skiprows参数是一个Lambda函数,通过该Lambda函数指定只读取Excel文件的表头和其中10%的数据,跳过其他的数据。代码:
import random
df4 = pd.read_excel(
io='小宝剑大药房2018年销售数据.xlsx',
usecols=['购药时间', '社保卡号', '商品名称', '销售数量', '应收金额', '实收金额'],
skiprows=lambda x: x > 0 and random.random() > 0.1
)
df4「说明」:如果需要上面例子中的Excel文件,可以通过下面的百度云盘地址进行获取,数据在《从零开始学数据分析》目录中。链接:https://pan.baidu.com/s/1rQujl5RQn9R7PadB2Z5g_g,提取码:e7b4。
输出:
购药时间 社保卡号 商品名称 销售数量 应收金额 实收金额
0 2018-03-23 星期三 10012157328 强力xx片 1 13.8 13.80
1 2018-07-12 星期二 108207828 强力xx片 1 13.8 13.80
2 2018-01-17 星期日 13358228 清热xx液 1 28.0 28.00
3 2018-07-11 星期一 10031402228 三九xx灵 5 149.0 130.00
4 2018-01-20 星期三 10013340328 三九xx灵 3 84.0 73.92
... ... ... ... ... ... ...
618 2018-03-05 星期六 10066059228 开博xx通 2 56.0 49.28
619 2018-03-22 星期二 10035514928 开博xx通 1 28.0 25.00
620 2018-04-15 星期五 1006668328 开博xx通 2 56.0 50.00
621 2018-04-24 星期日 10073294128 高特xx灵 1 5.6 5.60
622 2018-04-24 星期日 10073294128 高特xx灵 10 56.0 56.0
623 rows × 6 columns通过SQL从数据库读取数据创建
DataFrame对象。代码:
import pymysql
# 创建一个MySQL数据库的连接对象
conn = pymysql.connect(
host='47.104.31.138', port=3306, user='guest',
password='Guest.618', database='hrs', charset='utf8mb4'
)
# 通过SQL从数据库读取数据创建DataFrame
df5 = pd.read_sql('select * from tb_emp', conn, index_col='eno')
df5「提示」:执行上面的代码需要先安装
pymysql库,如果尚未安装,可以先在Notebook的单元格中先执行!pip install pymysql,然后再运行上面的代码。上面的代码连接的是我部署在阿里云上的MySQL数据库,公网IP地址:47.104.31.138,用户名:guest,密码:Guest.618,数据库:hrs,表名:tb_emp,字符集:utf8mb4。输出:
ename job mgr sal comm dno
eno
1359 胡一刀 销售员 3344 1800 200 30
2056 乔峰 分析师 7800 5000 1500 20
3088 李莫愁 设计师 2056 3500 800 20
3211 张无忌 程序员 2056 3200 NaN 20
3233 丘处机 程序员 2056 3400 NaN 20
3244 欧阳锋 程序员 3088 3200 NaN 20
3251 张翠山 程序员 2056 4000 NaN 20
3344 黄蓉 销售主管 7800 3000 800 30
3577 杨过 会计 5566 2200 NaN 10
3588 朱九真 会计 5566 2500 NaN 10
4466 苗人凤 销售员 3344 2500 NaN 30
5234 郭靖 出纳 5566 2000 NaN 10
5566 宋远桥 会计师 7800 4000 1000 10
7800 张三丰 总裁 NaN 9000 1200 20
基本属性和方法
DataFrame对象的属性如下表所示。
| 属性名 | 说明 |
|---|---|
at / iat | 通过标签获取DataFrame中的单个值。 |
columns | DataFrame对象列的索引 |
dtypes | DataFrame对象每一列的数据类型 |
empty | DataFrame对象是否为空 |
loc / iloc | 通过标签获取DataFrame中的一组值。 |
ndim | DataFrame对象的维度 |
shape | DataFrame对象的形状(行数和列数) |
size | DataFrame对象中元素的个数 |
values | DataFrame对象的数据对应的二维数组 |
关于DataFrame的方法,首先需要了解的是info()方法,它可以帮助我们了解DataFrame的相关信息,如下所示。
代码:
df5.info()
输出:
<class 'pandas.core.frame.DataFrame'>
Int64Index: 14 entries, 1359 to 7800
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 ename 14 non-null object
1 job 14 non-null object
2 mgr 13 non-null float64
3 sal 14 non-null int64
4 comm 6 non-null float64
5 dno 14 non-null int64
dtypes: float64(2), int64(2), object(2)
memory usage: 1.3+ KB
如果需要查看DataFrame的头部或尾部的数据,可以使用head()或tail()方法,这两个方法的默认参数是5,表示获取DataFrame最前面5行或最后面5行的数据。如果需要获取数据的描述性统计信息,可以使用describe()方法,该方法跟Series对象的describe()方法类似,只是默认会作用到DataFrame所有数值型的列上。
获取数据
索引和切片 数据筛选
重塑数据
concat函数merge函数
数据处理
数据清洗 缺失值处理 重复值处理 异常值处理 数据转换 apply和applymap方法字符串向量 时间日期向量
数据分析
描述性统计信息 分组聚合操作 groupby方法透视表和交叉表 数据分箱
数据可视化
用 plot方法出图其他方法
其他方法
独热编码
数据表中的字符串字段通常需要做预处理,因为字符串字段没有办法计算相关性,也没有办法进行检验、检验等操作。处理字符串通常有以下几种方式:
可以使用
get_dummies()函数来生成哑变量(虚拟变量)矩阵,将哑变量引入回归模型,虽然使模型变得较为复杂,但可以更直观地反映出该自变量的不同属性对于因变量的影响。有序变量(Ordinal Variable):字符串表示的数据有大小关系,那么可以对字符串进行序号化处理。 分类变量(Categorical Variable)/ 名义变量(Nominal Variable):字符串表示的数据没有大小关系和等级之分,那么就可以使用独热编码处理成哑变量(虚拟变量)矩阵。 定距变量(Scale Variable):数据有大小高低之分,可以进行加减运算。 窗口计算
相关性
协方差(covariance):用于衡量两个随机变量的联合变化程度。如果变量的较大值主要与另一个变量的较大值相对应,而两者较小值也相对应,那么两个变量倾向于表现出相似的行为,协方差为正。如果一个变量的较大值主要对应于另一个变量的较小值,则两个变量倾向于表现出相反的行为,协方差为负。简单的说,协方差的正负号显示着两个变量的相关性。方差是协方差的一种特殊情况,即变量与自身的协方差。
如果和是统计独立的,那么二者的协方差为0,这是因为在和独立的情况下:
协方差的数值大小取决于变量的大小,通常是不容易解释的,但是正态形式的协方差大小可以显示两变量线性关系的强弱。在统计学中,皮尔逊积矩相关系数用于度量两个变量和之间的相关程度(线性相关),它的值介于-1到1之间。
估算样本的协方差和标准差,可以得到样本皮尔逊系数,通常用英文小写字母表示。
等价的表达式为:
皮尔逊相关系数适用于:
斯皮尔曼相关系数对数据条件的要求没有皮尔逊相关系数严格,只要两个变量的观测值是成对的等级评定资料,或者是由连续变量观测资料转化得到的等级资料,不论两个变量的总体分布形态、样本容量的大小如何,都可以用斯皮尔曼等级相关系数来进行研究。
两个变量之间是线性关系,都是连续数据。 两个变量的总体是正态分布,或接近正态的单峰分布。 两个变量的观测值是成对的,每对观测值之间相互独立。
Index的应用
范围索引(RangeIndex)
代码:
sales_data = np.random.randint(400, 1000, 12)
month_index = pd.RangeIndex(1, 13, name='月份')
ser = pd.Series(data=sales_data, index=month_index)
ser
输出:
月份
1 703
2 705
3 557
4 943
5 961
6 615
7 788
8 985
9 921
10 951
11 874
12 609
dtype: int64
分类索引(CategoricalIndex)
代码:
cate_index = pd.CategoricalIndex(
['苹果', '香蕉', '苹果', '苹果', '桃子', '香蕉'],
ordered=True,
categories=['苹果', '香蕉', '桃子']
)
ser = pd.Series(data=amount, index=cate_index)
ser
输出:
苹果 6
香蕉 6
苹果 7
苹果 6
桃子 8
香蕉 6
dtype: int64
代码:
ser.groupby(level=0).sum()
输出:
苹果 19
香蕉 12
桃子 8
dtype: int64
多级索引(MultiIndex)
代码:
ids = np.arange(1001, 1006)
sms = ['期中', '期末']
index = pd.MultiIndex.from_product((ids, sms), names=['学号', '学期'])
courses = ['语文', '数学', '英语']
scores = np.random.randint(60, 101, (10, 3))
df = pd.DataFrame(data=scores, columns=courses, index=index)
df
输出:
语文 数学 英语
学号 学期
1001 期中 93 77 60
期末 93 98 84
1002 期中 64 78 71
期末 70 71 97
1003 期中 72 88 97
期末 99 100 63
1004 期中 80 71 61
期末 91 62 72
1005 期中 82 95 67
期末 84 78 86
代码:
# 计算每个学生的成绩,期中占25%,期末站75%
df.groupby(level=0).agg(lambda x: x.values[0] * 0.25 + x.values[1] * 0.75)
输出:
语文 数学 英语
学号
1001 93.00 92.75 78.00
1002 68.50 72.75 90.50
1003 92.25 97.00 71.50
1004 88.25 64.25 69.25
1005 83.50 82.25 81.25
时间索引(DatetimeIndex)
date_range()函数to_datetime()函数DateOffset类型相关方法 shift()方法asfreq()方法resample()方法时区转换 tz_localize()方法tz_convert()方法


