
JDK 17 G1/Parallel GC 改进【译】
共 3360字,需浏览 7分钟
· 2021-09-28
一、前言
前几天 JDK 17 GA 正式发布。出于这个原因,是时候写一篇文章来总结该版本中 Hotspot G1 和 Parallel GC垃圾收集器的最重要变化。
在详细了解 G1 和 Parallel GC 中的变化之前,先简要概述一下整个 GC 子组件的统计信息:垃圾收集区域中没有 JEP。
整个 Hotspot GC 子组件的完整更改列表在这里,总共有 312 个更改。这与最近的版本一致。
在谈论停止世界收集器之前,简要介绍一下ZGC:此版本通过动态调整并发 GC 线程以匹配应用程序,一方面优化吞吐量,另一方面避免分配停滞(JDK-8268372),从而提高了可用性)。另一个显着变化,JDK-8260267 显着减少了标记堆栈内存使用。Per 可能很快会在他的博客中分享更多细节。
二、一般改进
自 JDK-8256155 以来,VM 现在可以为不同的内存预留使用不同的大页面大小:即代码缓存可以使用与 Java 堆和其他大预留不同大小的大页面。这允许更好地使用系统中配置的大页面。为什么和如何使用大页面请查看之前的译文 JAVA 应用提速之 Large pages【译】。
三、并行GC
通过使暂停中以前的串行阶段比以前更多地并行执行,并行 GC 暂停有所加快。这包括
JDK-8204686 实现了像 G1 那样的动态并行引用处理 已经有一段时间了。最近几个版本中的先前工作允许轻松实现此功能。它的工作原理就像 G1 实现: 根据在 java.lang.ref.Reference给定垃圾收集期间需要对给定类型(软、弱、最终和幻影)进行引用处理的实例数量,并行 GC 现在为引用处理的特定阶段启动不同数量的线程。粗略地说,该实现j.l.ref.References将给定阶段的观察数量除以ReferencesPerThread(default1000)的值,以确定 Parallel GC 将用于该特定阶段的线程数量。该选项 ParallelRefProcEnabled现在默认启用,启用此机制。自从在 JDK 11 的G1中引入了这个特性,我们没有听到抱怨,所以这似乎是合适的。
另请查看发行说明。
同样,所有内部弱引用的处理已更改为自动利用JDK-8268443 中的并行性。 最后,出于同样的原因,JDK-8248314 减少了几毫秒的 Full GC 停顿。
我们还注意到,与 JDK 16 相比,某些应用程序的吞吐量有微小的个位数百分比改进,但与 GC 相比,这更可能与 JDK 17 中的编译器改进有关。也就是说,除非上述更改完全解决了您的应用程序问题。
四、G1 GC
G1 现在使用 JDK-8257774 计划预防性垃圾收集。Microsoft 的这一贡献引入了一种特殊的年轻集合,目的是避免因 疏散失败 而导致的典型长时间停顿。这种情况,没有足够的空间来复制对象,经常发生,因为短期巨大的对象分配率很高——它们可能会在 G1 通常安排垃圾收集之前填满堆。因此,与其等待这种情况发生,G1 会启动计划外垃圾收集,同时它仍然可以确信有足够的空间将幸存的对象复制到其中,假设急切回收将释放大量堆空间和常规操作可以继续。预防性收集将被标记为 G1 Preventive Collection在日志中,即相应的日志条目可能如下所示:默认情况下启用预防性垃圾回收。G1UsePreventiveGC如果它们导致回归,可以使用诊断标志禁用它们。
[...]
[2.574s][info][gc] GC(121) Pause Young (Normal) (G1 Evacuation Pause) 86M->83M(90M) 5.781ms
[2.582s][info][gc] GC(122) Pause Young (Normal) (G1 Evacuation Pause) 86M->83M(90M) 4.936ms
[2.596s][info][gc] GC(123) Pause Young (Normal) (G1 Preventive Collection) 86M->84M(90M) 9.997ms
[...]
在 Windows 上处理大页面的一个重大错误已得到修复:JDK-8266489使 G1 能够在区域大小大于 2 MB 时使用大页面,在某些情况下,在较大的 Java 堆上显着提高性能。 随着JDK-8262068 Hamlin Li添加MarkSweepDeadRatio的支持,除了串行和并行GC在G1完全GC选项。此选项控制在计划进行压缩的区域中可以容忍多少浪费。实时占用率高于此比率(默认为 95%)的区域不会被压缩,因为压缩它们不会返回可观的内存量,并且只需要很长时间来压缩。在某些情况下,这可能是不可取的。如果出于某种原因需要最大堆压缩,请手动设置此标志的值以100禁用该功能(与其他收集器一样)。通过尽早修剪集合集(JDK-8262185)可以显着的节省内存:通过这种变化,G1 尝试只为它几乎肯定会撤离的一系列老年代区域保留记住的集合,而不是所有可能的有用候选区域。我的博客上有一篇文章强调了这个问题,并展示了潜在的收益。
部分 GC 阶段的一些额外并行化(例如JDK-8214237)可能会导致整体性能的提高,例如《java17有多快》中的报告。
五、其他值得注意的变化
此外,还有一些 JDK 17 更改很重要,但对最终用户来说却很少或根本不需要关注。
我们开始积极重构 G1 收集器代码。特别是我们正在将代码从包罗万象的类中移出 G1CollectedHeap,试图分离关注点并将其分割成更易于理解的组件。这已经提高了可维护性,并有望加快进一步的工作。
六、下一步是什么
当然,GC 团队和其他贡献者已经在积极致力于 JDK 18。以下是当前正在开发中的有趣更改的简短列表,您可能需要注意。在没有保证的情况下,像往常一样,它们将在完成后集成 ;-)
首先,实际已经集成的变更 JDK-8017163免费 大量减少了G1内存消耗。从 JDK 17 到 JDK 18,这种 记忆集 数据存储的重写将其占用空间减少了约 75%。下图显示了 NMT 报告的某些类似数据库应用程序的 GC 组件的内存消耗,作为各种最新 JDK 的预告片。 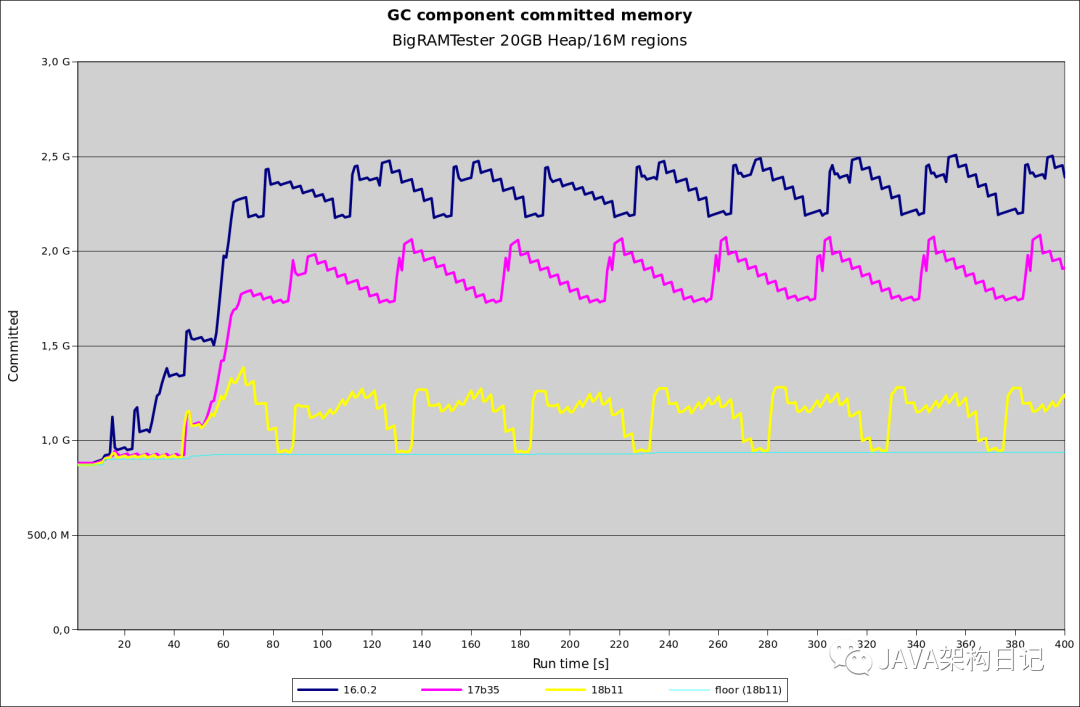 特别注意黄线显示当前 (18b11) 总内存使用量与 17b35(粉红色)和 16.0.2(蓝色)相比。您可以通过从给定曲线中减去由“地板”(青色)表示的其他 GC 组件内存使用量来计算记住的集合大小。将有一个更加全面的评估的变化,并解释在这个博客的未来。至少记住设置大小调整应该在很大程度上成为过去。计划在此更改的基础上进行更多更改以提高性能并进一步减少记住的设置内存大小。
特别注意黄线显示当前 (18b11) 总内存使用量与 17b35(粉红色)和 16.0.2(蓝色)相比。您可以通过从给定曲线中减去由“地板”(青色)表示的其他 GC 组件内存使用量来计算记住的集合大小。将有一个更加全面的评估的变化,并解释在这个博客的未来。至少记住设置大小调整应该在很大程度上成为过去。计划在此更改的基础上进行更多更改以提高性能并进一步减少记住的设置内存大小。串行 GC、并行 GC 和 ZGC 支持字符串重复数据删除, 如 JDK 18 中的 G1 和 Shenandoah。JEP 192 提供了有关此技术的详细信息,现在适用于所有 Hotspot 收集器。 JDK-8273508 中正在开发对 Serial GC 的归档堆对象的支持。 Hamlin Li 目前在改进疏散故障处理方面做了大量工作,其明显目标是在未来实现 G1中的区域锁定;早些时候,我写了一篇关于问题和可能的方案的短文。
八、译者说
我们已经陆续发了多篇 Java17 相关文章,还有一批文章正在酝酿。
关注 JAVA架构日记 学习技术不迷路!