大数据文摘
大数据文摘





Excel 的“自动更错”
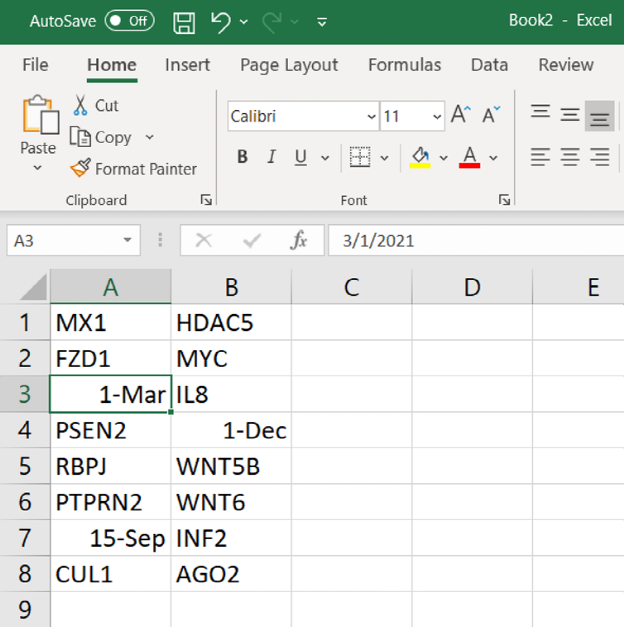
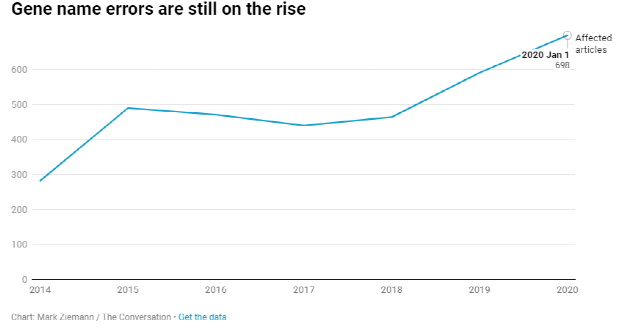
令人头疼的问题仍在持续
是时候换掉 Excel 了?
https://journals.plos.org/ploscompbiol/article?id=10.1371/journal.pcbi.1008984
https://www.nature.com/articles/d41586-021-02211-4
https://theconversation.com/excel-autocorrect-errors-still-plague-genetic-research-raising-concerns-over-scientific-rigour-166554