
(十)RASA CORE Policy
作者简介
作者:孟繁中(北京邮电大学 计算机科学与技术硕士)
原文:https://zhuanlan.zhihu.com/p/333947395
转载者:杨夕
面筋地址:https://github.com/km1994/NLP-Interview-Notes
个人笔记:https://github.com/km1994/nlp_paper_study

RASA NLU模块提供了用户消息中意图、槽位等信息,RASA DST模块提供了对话跟踪功能,记录了用户的历史消息,Policy要根据这些信息预测出,下一步机器人应该给出的动作是什么?可以是一个简单的回复,也可能是fallback等。默认情况下,RASA可以为每个用户消息预测10个后续操作。要更新此值,可以将环境变量MAX_NUMBER_OF_PREDICTIONS设置为所需的最大预测数。
RASA提供了多个Policy供选择,而且可以同时选择多个策略,由RASA Agent模块统一调度。在每一轮对话中,每个Policy都会给出自己预测的下一个Action,并给出置信度,然后Agent会选出最高置信度对应的action。当多个置信度相同的时候,RASA有自己的优先级:
6 -
RulePolicy3 -
MemoizationPolicyorAugmentedMemoizationPolicy1 -
TEDPolicy
但是不推荐同个优先级的policy配置2个以上,比如MemoizationPolicy和AugmentedMemoizationPolicy同时使用,因为这样如果2个预测的置信度相同的时候,会导致结果是随机的。
如果是自定义的策略,请使用这些策略配置项里的priority参数指定策略优先级。如果您的策略是一个机器学习策略,那么它很可能具有优先级1,与TEDPolicy相同。
TED Policy
该策略采用预定义架构,包括以下步骤:
将每轮用户输入(用户意图和实体),系统返回的动作,槽和活动都通过级联,变形等方式嵌入到输入向量中。
将输入向量输入到transformer。
在transformer的输出上应用全连接层,以获取每轮的对话嵌入。
应用全连接层为每轮的action创建嵌入特征。
计算对话特征和系统动作特征的相似度
TED的使用,同其他配置项一样,包括配置策略名称,和对应的参数,如
policies:
- name: TEDPolicy
max_history: 8其中对应的配置参数如下:
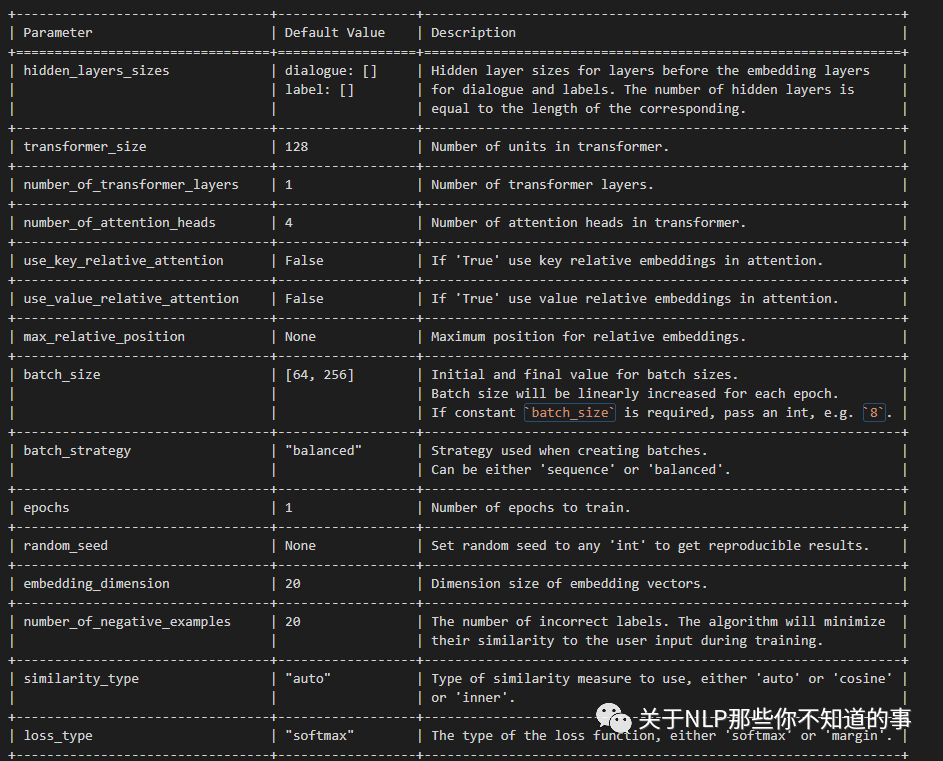
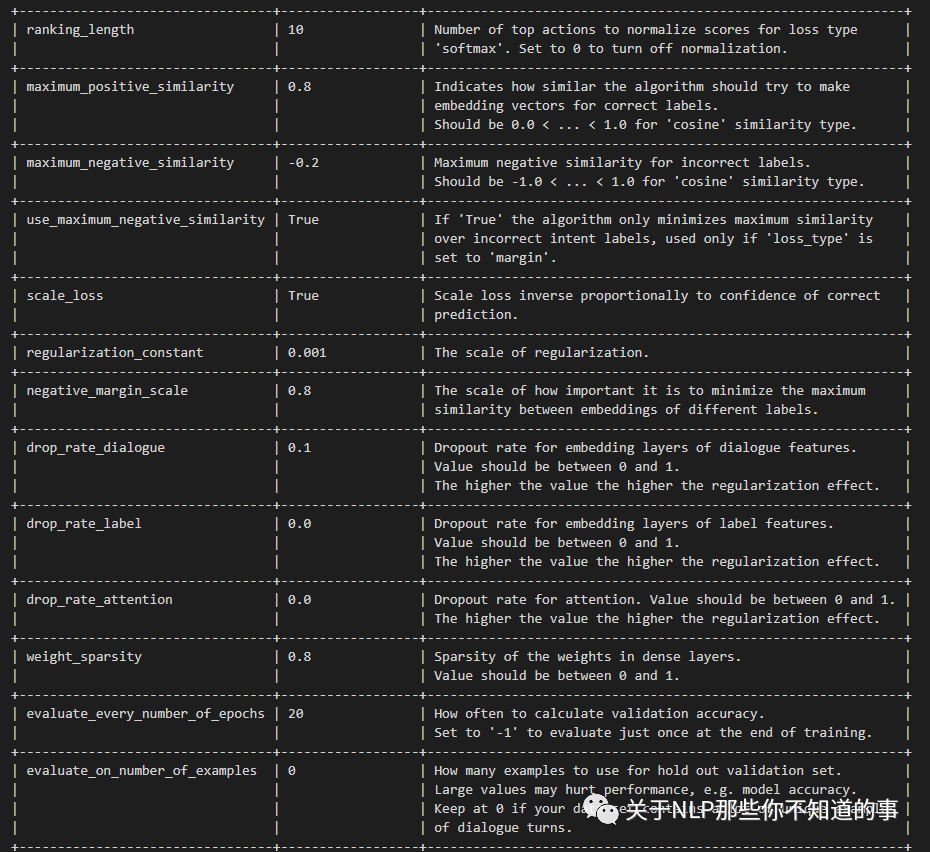
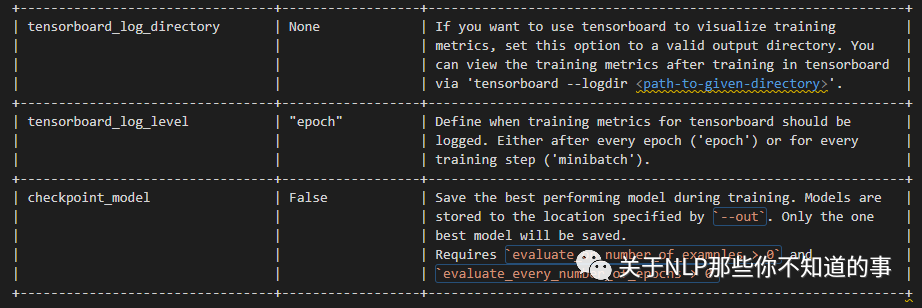
+---------------------------------+------------------+--------------------------------------------------------------+| Parameter | Default Value | Description |+=================================+==================+==============================================================+| hidden_layers_sizes | dialogue: [] | Hidden layer sizes for layers before the embedding layers || | label: [] | for dialogue and labels. The number of hidden layers is || | | equal to the length of the corresponding. |+---------------------------------+------------------+--------------------------------------------------------------+| transformer_size | 128 | Number of units in transformer. |+---------------------------------+------------------+--------------------------------------------------------------+| number_of_transformer_layers | 1 | Number of transformer layers. |+---------------------------------+------------------+--------------------------------------------------------------+| number_of_attention_heads | 4 | Number of attention heads in transformer. |+---------------------------------+------------------+--------------------------------------------------------------+| use_key_relative_attention | False | If 'True' use key relative embeddings in attention. |+---------------------------------+------------------+--------------------------------------------------------------+| use_value_relative_attention | False | If 'True' use value relative embeddings in attention. |+---------------------------------+------------------+--------------------------------------------------------------+| max_relative_position | None | Maximum position for relative embeddings. |+---------------------------------+------------------+--------------------------------------------------------------+| batch_size | [64, 256] | Initial and final value for batch sizes. || | | Batch size will be linearly increased for each epoch. || | | If constant `batch_size` is required, pass an int, e.g. `8`. |+---------------------------------+------------------+--------------------------------------------------------------+| batch_strategy | "balanced" | Strategy used when creating batches. || | | Can be either 'sequence' or 'balanced'. |+---------------------------------+------------------+--------------------------------------------------------------+| epochs | 1 | Number of epochs to train. |+---------------------------------+------------------+--------------------------------------------------------------+| random_seed | None | Set random seed to any 'int' to get reproducible results. |+---------------------------------+------------------+--------------------------------------------------------------+| embedding_dimension | 20 | Dimension size of embedding vectors. |+---------------------------------+------------------+--------------------------------------------------------------+| number_of_negative_examples | 20 | The number of incorrect labels. The algorithm will minimize || | | their similarity to the user input during training. |+---------------------------------+------------------+--------------------------------------------------------------+| similarity_type | "auto" | Type of similarity measure to use, either 'auto' or 'cosine' || | | or 'inner'. |+---------------------------------+------------------+--------------------------------------------------------------+| loss_type | "softmax" | The type of the loss function, either 'softmax' or 'margin'. |+---------------------------------+------------------+--------------------------------------------------------------+| ranking_length | 10 | Number of top actions to normalize scores for loss type || | | 'softmax'. Set to 0 to turn off normalization. |+---------------------------------+------------------+--------------------------------------------------------------+| maximum_positive_similarity | 0.8 | Indicates how similar the algorithm should try to make || | | embedding vectors for correct labels. || | | Should be 0.0 < ... < 1.0 for 'cosine' similarity type. |+---------------------------------+------------------+--------------------------------------------------------------+| maximum_negative_similarity | -0.2 | Maximum negative similarity for incorrect labels. || | | Should be -1.0 < ... < 1.0 for 'cosine' similarity type. |+---------------------------------+------------------+--------------------------------------------------------------+| use_maximum_negative_similarity | True | If 'True' the algorithm only minimizes maximum similarity || | | over incorrect intent labels, used only if 'loss_type' is || | | set to 'margin'. |+---------------------------------+------------------+--------------------------------------------------------------+| scale_loss | True | Scale loss inverse proportionally to confidence of correct || | | prediction. |+---------------------------------+------------------+--------------------------------------------------------------+| regularization_constant | 0.001 | The scale of regularization. |+---------------------------------+------------------+--------------------------------------------------------------+| negative_margin_scale | 0.8 | The scale of how important it is to minimize the maximum || | | similarity between embeddings of different labels. |+---------------------------------+------------------+--------------------------------------------------------------+| drop_rate_dialogue | 0.1 | Dropout rate for embedding layers of dialogue features. || | | Value should be between 0 and 1. || | | The higher the value the higher the regularization effect. |+---------------------------------+------------------+--------------------------------------------------------------+| drop_rate_label | 0.0 | Dropout rate for embedding layers of label features. || | | Value should be between 0 and 1. || | | The higher the value the higher the regularization effect. |+---------------------------------+------------------+--------------------------------------------------------------+| drop_rate_attention | 0.0 | Dropout rate for attention. Value should be between 0 and 1. || | | The higher the value the higher the regularization effect. |+---------------------------------+------------------+--------------------------------------------------------------+| weight_sparsity | 0.8 | Sparsity of the weights in dense layers. || | | Value should be between 0 and 1. |+---------------------------------+------------------+--------------------------------------------------------------+| evaluate_every_number_of_epochs | 20 | How often to calculate validation accuracy. || | | Set to '-1' to evaluate just once at the end of training. |+---------------------------------+------------------+--------------------------------------------------------------+| evaluate_on_number_of_examples | 0 | How many examples to use for hold out validation set. || | | Large values may hurt performance, e.g. model accuracy. || | | Keep at 0 if your data set contains a lot of unique examples || | | of dialogue turns. |+---------------------------------+------------------+--------------------------------------------------------------+| tensorboard_log_directory | None | If you want to use tensorboard to visualize training || | | metrics, set this option to a valid output directory. You || | | can view the training metrics after training in tensorboard || | | via 'tensorboard --logdir <path-to-given-directory>'. |+---------------------------------+------------------+--------------------------------------------------------------+| tensorboard_log_level | "epoch" | Define when training metrics for tensorboard should be || | | logged. Either after every epoch ('epoch') or for every || | | training step ('minibatch'). |+---------------------------------+------------------+--------------------------------------------------------------+| checkpoint_model | False | Save the best performing model during training. Models are || | | stored to the location specified by `--out`. Only the one || | | best model will be saved. || | | Requires `evaluate_on_number_of_examples > 0` and || | | `evaluate_every_number_of_epochs > 0` |+---------------------------------+------------------+--------------------------------------------------------------+MemoizationPolicy
MemoizationPolicy记住了训练数据中的对话。如果在正式运行过程中,用户对话出现在训练数据中,它预测下一个action的置信度为1.0,否则输出None,置信度为0.0。MemoizationPolicy去匹配训练数据的时候,是取最近max_history轮的数据,每轮数据包括用户消息和机器人发的消息。max_history是MemoizationPolicy的配置参数。
Augmented Memoization Policy
Augmented Memoization Policy和MemoizationPolicy一样,也是通过记住训练数据的对话,但是不同的是,它增加了遗忘机制,会遗忘一定数量的历史记录,然后在缩减后的历史记录中寻找匹配的信息。同样,如果用户对话出现在训练数据中,它预测下一个action的置信度为1.0,否则输出None,置信度为0.0。
如果有一些对话,训练数据中的槽位信息在预测时没有被填充,那就需要将对应的没有槽位信息的话术也添加到训练数据中。
基于规则的策略
RulePolicy处理固定模式的回答,例如和业务相关的。它根据规则预测action,如果匹配规则,则下一个action的置信度为1.0,否则输出None,置信度为0.0。
RASA提供非常丰富的规则,通过规则组合可以形成各种各样的策略。诸如RASA 1.x中的Fallback Policy,Two-Stage Fallback Policy,Form Policy都可以通过规则来实现。但RASA也提了个醒,不能过度使用Rule Policy,因为当业务复杂到一定程度的时候,规则会变得非常难以维护,尤其当多个规则有冲突的时候。
开启规则的策略配置如下:
policies:
- ... # Other policies
- name: RulePolicy策略相关配置
max_history
一个重要的超参数是max_history,它指示RASA需要考虑多少轮对话历史来预测下一步的action。值得注意的是,RulePolicy并没有这个参数,它考虑的是整个对话历史。
这个参数的设置,与故事和规则相关,例如考虑下面场景:
stories:
- story: utter help after 2 fallbacks
steps:
- intent: out_of_scope
- action: utter_default
- intent: out_of_scope
- action: utter_default
- intent: out_of_scope
- action: utter_help_message这个场景是连续3次都没有识别用户的意图,然后播放一个帮助列表。在这种情况下,max_history至少设置为4。
max_history值变大,会增加训练时长。有个技巧就是,可以把上文信息设置为slot,slot信息会在整个对话过程中有效。这样就可以做到不增加max_history,而又更多的上文信息。
2.数据增强
在训练模型时,Rasa Core将随机地将故事文件中的故事粘在一起,从而创建更长的故事。
可以通过使用--augmentation来设置augmentation_factor。augmentation_factor参数决定在训练的时候有多少个扩增的故事。扩增的故事是在训练之前进行采样的,数量增加的很快,因此我们需要限制它。采样的故事的数量是augmentation_factor的10倍。默认情况下augmentation是20,因此最大是200个扩增故事。--augmentation 0将禁止所有的扩增行为。Memoization policies不会受这个参数的影响,会自动忽略所有扩增的故事。
3、状态的特征化
在前面的讨论中,用户数据进入NLU之前必须进行Featurizer才能被处理。在RASA Core中,Policy模块会根据用户的历史对话综合当前对话来预测下一轮动作,因此也需要用户的历史状态数据转换成特征向量,供Policy使用。
RASA的每个故事都对应一个追踪器,它将历史记录中的每个事件都会创建一个状态(例如,运行bot操作、接收的用户消息、设置的插槽等)。对跟踪器的单个状态进行特征化有两个步骤:
第一步,将追踪器提供一系列活动的特征,包括:
指示当前定义的槽位,例如,
slot_location指示用户正在搜索餐厅的区域。指示存储在插槽中的任何API调用结果,例如
slot_matches指示上次Action或机器人响应的对话是什么(例如
prev_action_listen)指示是否有对话循环处于活动状态,以及哪个对话循环处于活动状态
第二步,将所有的特征转成数字向量
SingleStateFeaturizer使用Rasa NLU管道将intent和bot操作名称或bot消息转换为数字向量。实体、插槽和活动循环被特征化为一个one-hot编码。
4、跟踪器特征化器
在预测一个动作时,除了当前状态之外,还应该包含更多的历史记录。TrackerFeaturizer遍历跟踪器状态,并为每个状态调用SingleStateFeaturizer为策略创建数字输入特征。目标标签对应于bot操作或bot语句被表示为所有可能操作的列表中的索引。
有两种不同的跟踪器特性化器:
第一种:FullDialogueTrackerFeaturizer
在整个对话都传入递归神经网络,并且梯度学习算法在所有time-step进行反向传播时候使用。它创建所有故事的数字表示,对于较小的对话将在特征向量里面填充0。
第二种:MaxHistoryTrackerFeaturizer
MaxHistoryTrackerFeaturizer只跟踪历史状态最多max_history轮。如果max_history未指定,则算法会考虑对话的整个长度。较小对话的特征向量将填充0。重复状态会自动滤除。
对于某些算法来说,需要Flat特征向量,因此将输入特征reshape为(num_unique_turns, max_history * num_input_features)。
5、自定义策略
您还可以编写自定义策略并在配置中引用它们。在下面的示例中,最后两行显示了如何使用自定义策略类并向其传递参数。
policies:
- name: "TEDPolicy"
max_history: 5
epochs: 200
- name: "RulePolicy"
- name: "path.to.your.policy.class"
arg1: "..."