 DayNightStudy
DayNightStudy




作者简介
原文:https://zhuanlan.zhihu.com/p/338355413
转载者:杨夕
面筋地址:https://github.com/km1994/NLP-Interview-Notes
个人笔记:https://github.com/km1994/nlp_paper_study

作为RASA NLU的最后一节,我们讨论下自定义组件,pipeline里面配置的所有组件,都来自一个基类Component。虽然rasa提供非常丰富的pipeline组件,但我们的需求千差万别,当预置组件不满足需求的时候,我们需要自定义组件。下面我们以SentimentAnalyzer为例,介绍下自定义组件的过程。
组件的生命周期
在开始写组件之前,我们要清楚组件的调用过程。每个组件处理一个输入或创建一个输出。组件的顺序由它们在yml中列出的顺序决定。一个组件的输出可以被管道中后面的组件使用。某些组件只生成管道中其他组件使用的信息。假设有这样一个配置:
pipeline:
- name: "Component A"
- name: "Component B"
- name: "Last Component"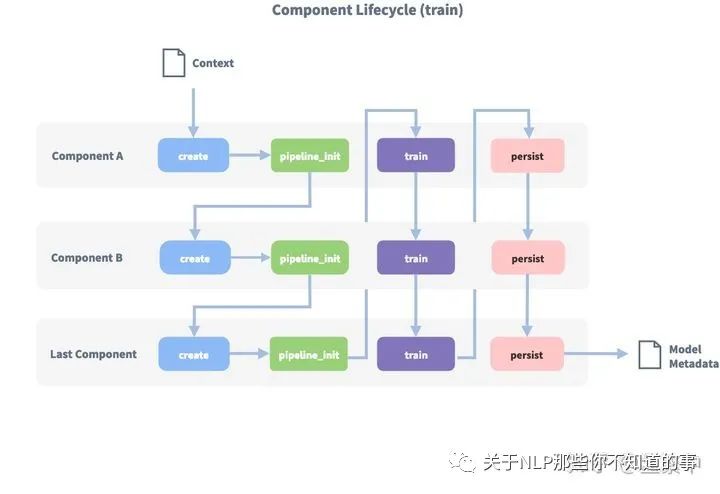
在使用create函数创建第一个组件之前,将创建一个上下文(一个python dict)。此上下文用于在组件之间传递信息。例如,一个组件可以计算训练数据的特征向量,将其存储在上下文中,另一个组件可以从上下文中检索这些特征向量并进行意图分类。最初,上下文填充所有配置值。图像中的箭头显示调用顺序并显示传递的上下文的路径。在对所有组件进行训练和持久化之后,将使用最终的上下文字典来持久化模型的元数据。
组件的定义
我们写组件,可以使用rasa提供的一个模板,这里包含应该实现的最重要方法。
import typing
from typing import Any, Optional, Text, Dict, List, Type
from rasa.nlu.components import Component
from rasa.nlu.config import RasaNLUModelConfig
from rasa.shared.nlu.training_data.training_data import TrainingData
from rasa.shared.nlu.training_data.message import Message
if typing.TYPE_CHECKING:
from rasa.nlu.model import Metadata
class MyComponent(Component):
"""A new component"""
# Which components are required by this component.
# Listed components should appear before the component itself in the pipeline.
@classmethod
def required_components(cls) -> List[Type[Component]]:
"""Specify which components need to be present in the pipeline."""
return []
# Defines the default configuration parameters of a component
# these values can be overwritten in the pipeline configuration
# of the model. The component should choose sensible defaults
# and should be able to create reasonable results with the defaults.
defaults = {}
# Defines what language(s) this component can handle.
# This attribute is designed for instance method: `can_handle_language`.
# Default value is None which means it can handle all languages.
# This is an important feature for backwards compatibility of components.
supported_language_list = None
# Defines what language(s) this component can NOT handle.
# This attribute is designed for instance method: `can_handle_language`.
# Default value is None which means it can handle all languages.
# This is an important feature for backwards compatibility of components.
not_supported_language_list = None
def __init__(self, component_config: Optional[Dict[Text, Any]] = None) -> None:
super().__init__(component_config)
def train(
self,
training_data: TrainingData,
config: Optional[RasaNLUModelConfig] = None,
**kwargs: Any,
) -> None:
"""Train this component.
This is the components chance to train itself provided
with the training data. The component can rely on
any context attribute to be present, that gets created
by a call to :meth:`components.Component.pipeline_init`
of ANY component and
on any context attributes created by a call to
:meth:`components.Component.train`
of components previous to this one."""
pass
def process(self, message: Message, **kwargs: Any) -> None:
"""Process an incoming message.
This is the components chance to process an incoming
message. The component can rely on
any context attribute to be present, that gets created
by a call to :meth:`components.Component.pipeline_init`
of ANY component and
on any context attributes created by a call to
:meth:`components.Component.process`
of components previous to this one."""
pass
def persist(self, file_name: Text, model_dir: Text) -> Optional[Dict[Text, Any]]:
"""Persist this component to disk for future loading."""
pass
@classmethod
def load(
cls,
meta: Dict[Text, Any],
model_dir: Optional[Text] = None,
model_metadata: Optional["Metadata"] = None,
cached_component: Optional["Component"] = None,
**kwargs: Any,
) -> "Component":
"""Load this component from file."""
if cached_component:
return cached_component
else:
return cls(meta)
组件的使用
可以通过添加模块路径将自定义组件添加到管道中。因此,如果您有一个名为“sentiment”的模块,其中包含一个SentimentAnalyzer类:
pipeline:
- name: "sentiment.SentimentAnalyzer"自定义Tokenizer
Tokenizer继承Component,已经做了很多处理,如果自定义Tokenizer,不用从Component继承,我们可以直接从Tokenizer继承,然后只处理tokenize这个方法就可以了。下面是自定义Tokenizer的模板:
class MyTokenizer(Tokenizer):
language_list = ["zh"]
def __init__(self, component_config: Dict[Text, Any] = None) -> None:
"""Construct a new Tokenizer."""
super().__init__(component_config)
@classmethod
def required_packages(cls) -> List[Text]:
return []
def tokenize(self, message: Message, attribute: Text) -> List[Token]:
"""Construct a new Tokenizer."""
return tokens
自定义Featurizer
同样,Featurizer继承Component,已经做了很多处理,如果自定义Featurizer,不用从Component继承,我们可以直接从Featurizer继承。这里要注意的是,生成的特征的维度,序列特征是一个大小矩阵(TOKEN数x特征维数),例如,该矩阵包含序列中每个TOKEN的特征向量。句子特征由一个大小矩阵(1 x特征维数)表示。生成特征在下面的代码段中_compute_features。
def train(
self,
training_data: TrainingData,
config: Optional[RasaNLUModelConfig] = None,
**kwargs: Any,
) -> None:
"""Featurize all message attributes in the training data with the ConveRT model.
Args:
training_data: Training data to be featurized
config: Pipeline configuration
**kwargs: Any other arguments.
"""
for attribute in DENSE_FEATURIZABLE_ATTRIBUTES:
#......
(
batch_sequence_features,
batch_sentence_features,
) = self._compute_features(batch_examples, attribute)
self._set_features(
batch_examples,
batch_sequence_features,
batch_sentence_features,
attribute,
)
def process(self, message: Message, **kwargs: Any) -> None:
"""Featurize an incoming message with the ConveRT model.
Args:
message: Message to be featurized
**kwargs: Any other arguments.
"""
for attribute in {TEXT, ACTION_TEXT}:
if message.get(attribute):
sequence_features, sentence_features = self._compute_features(
[message], attribute=attribute
)
self._set_features(
[message], sequence_features, sentence_features, attribute
)
