 GiantPandaCV
GiantPandaCV





自提出之日起,Transformer模型已经在CV、NLP以及其他更多领域中「大展拳脚」,实力冲击CNN。
Transformer为什么这么有实力?因为它在分类、检测等任务上展现了极其强劲的性能。而且骨干网络上的发展也推动了下游任务的发展,Swin Transformer更是成了屠榜般的存在,在工业界具有广阔的应用前景。所以引起了人工智能研究生的强烈兴趣。
但要想啃透CV Transformer 难度不小:一方面,Transformer本是应用于NLP的论文,其中很多内容都形成了共识,在论文中并不会去详细介绍这些共识内容,例如QKV是什么,embedding是什么等,对于其他方向的人看到这些就很难理解。
另一方面,近小半年,Transformer+CV的论文就已经有40多篇。学术研究更新之快,与脱发速度成正比
如果粉丝们想要系统且高效学习CV Transformer,我推荐大家参加深度之眼 【CV Transformer论文直播精讲】
↓ 扫描下方二维码添加班主任 ↓
↓ 回复:CV 即可免费报名参加 ↓

↑ 班主任:加我进直播群、领取资料哦 ↑
Transformer高手带学 节约21天论文学习时长
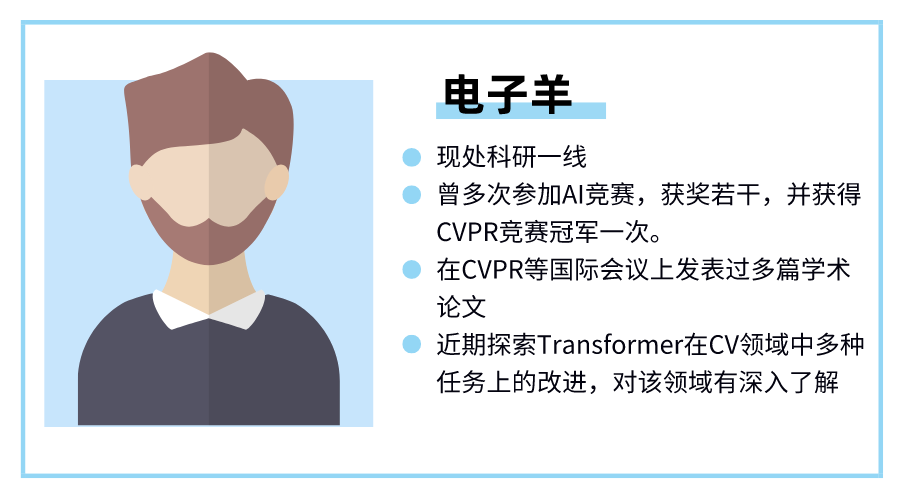
深度之眼电子羊导师结合自己工作及学习经验,并配合深度之眼教研团的打磨,总结出一条CV Transformer 的学习路径:
2场直播+录播 夯实 CV Transformer 基础
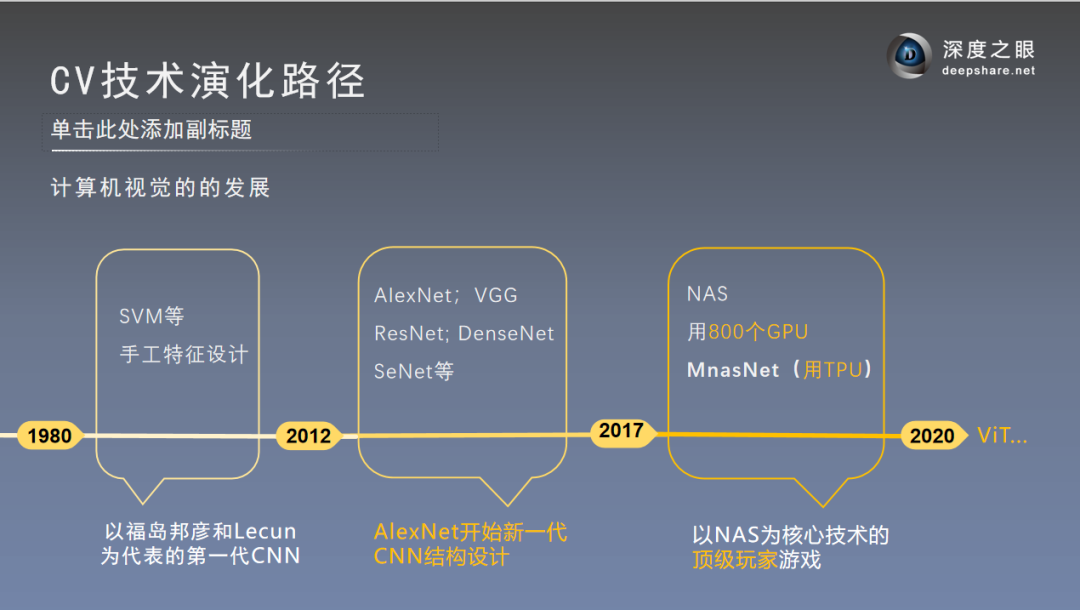
Step1:系统了解CV Transformer 技术演化路径及发展历史
Step2:精讲CV Transformer基石论文 — ViT
《An Image is Worth 16x16 Words:Transformers for Image Recognition at Scale》简称ViT。ViT是Google在2020年提出的第一篇使用纯transformer来进行图片分类任务的论文,其价值在于展现了在CV中使用纯Transformer结构的可能性,后面很多的工作都基于ViT进行改进的。
而且这个模型出来才半年多,github上ViT的repo就有很多了,基于tensorflow和pytorch的都有。star数目前已都是几千,可见影响力之大 。个人感觉ViT对之后的论文影响很大,很多论文都借鉴了VIT里面的相关做法。
深度之眼电子羊导师 将从 研究背景 到 算法模型,带你啃透ViT!
① 深挖研究背景
提纲挚领,从4大维度介绍论文,深入讲解论文发表的研究背景、成果及意义,介绍论文中取得的核心成果,对比解决同一问题,已有解决方法和论文中提出的新的解决方法的优缺点,熟悉论文的整体思路和框架,建立对本篇论文的一个概貌性认识。

② 死磕算法模型
老师会重点讲解论文中的模型原理,深入拆解模型结构,对关键公式逐步推导,让你了解算法每一个因子是如何对结果产生影响的,掌握实验手段及结果,老师会帮你拎出论文中的关键点、创新点和启发点,节约你自己摸索的时间。

高手伴学 共同提升
· 3天高质量社群服务,导师全程陪伴
· 2场直播+录播,开启 CV Transformer 新篇章
· 100+学员同群交流,学习经验up up⬆⬆⬆
· 助教24小时答疑,再也不怕debug
· 专属班主任私信督学,治疗学习拖延症
完课即赠价值298元学习大礼包
为了激励大家完成学习,我们还准备了价值298元的算法工程师面试锦囊。只要完成全部课程的学习,你就能私信班主任获取!

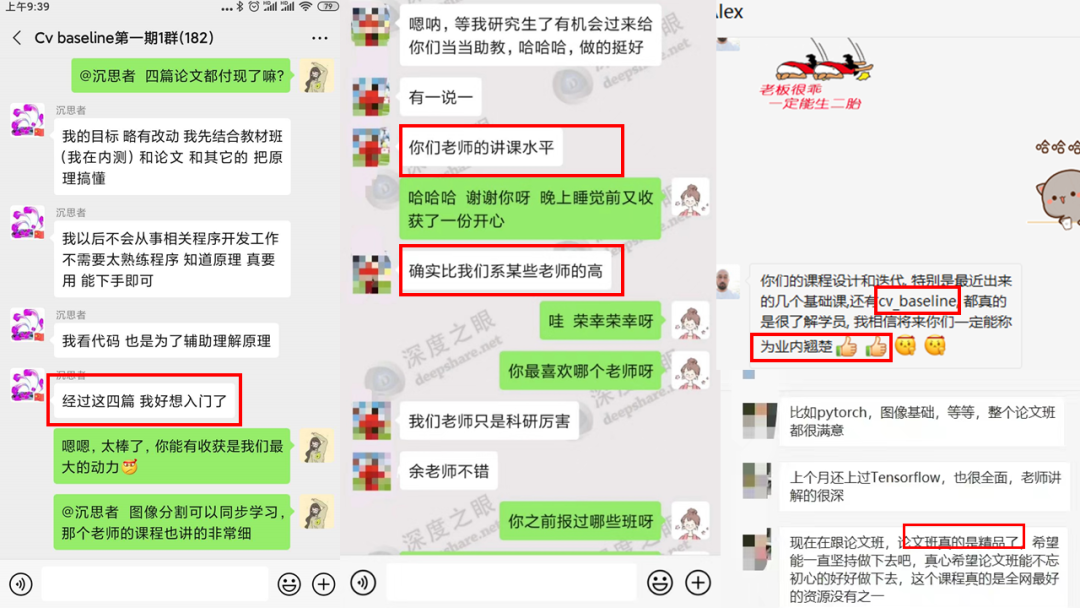
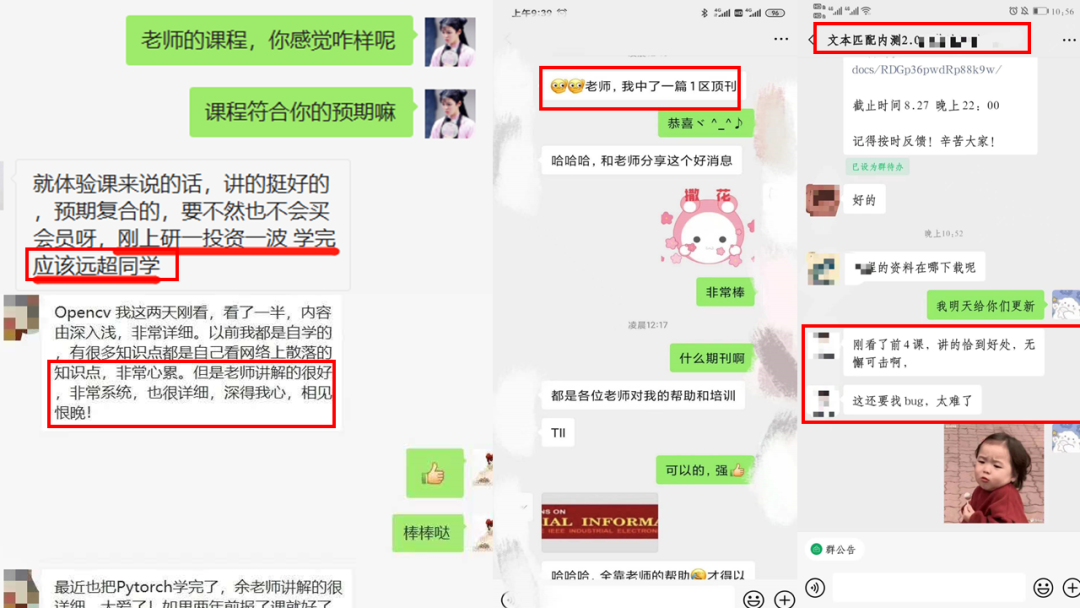
学员好评,真香!
这一次,我给粉丝们申请了30个直播福利名额,参加即赠秘籍:《效率提升3倍的Paper阅读方法》。
↓ 扫描下方二维码添加班主任 ↓
↓ 回复:CV 即可免费报名参加 ↓
↑ 班主任:加我进直播群、领取资料哦 ↑
如果你不知道怎么读论文、不知道如何正确复现论文,一定要跟着这门课程学习一次,因为正确的方法可以节约你10倍的阅读时间。


