Pandas数据分析,你不能不知道的技能
↑↑↑关注后"星标"简说Python
人人都可以简单入门Python、爬虫、数据分析 简说Python推荐 来源:简说Python 编辑:老表
作者:修罗闪空、pluto、乔瞧、石墨锡
一、前言
二、本文概要
三、pandas merge by 修罗闪空
3.1 merge函数用途
3.2 merge函数的具体参数
3.3 merge函数的应用
四、pandas apply by pluto、乔瞧
4.1 pandas apply by pluto
4.2 pandas apply by 乔瞧
pandas pivot_table by 石墨锡
一、前言
本文来自四位读者的合作,这四位读者是之前推文14个pandas神操作,手把手教你写代码中赠书活动的中奖者,奖品是赠书《深入浅出Pandas:利用Python进行数据处理与分析》。
这里赠书有要求:获赠读者需要先说一下自己对对应最爱pandas操作函数的理解+一个对应函数应用小案例,于是也就有了今天这篇文章。
后面赠书也会更多这样,一来确保图书赠送出去是给到了确实有需要、是想学习的读者,再者获赠读者的分享也可以给其他未获得赠书的读者学习,也可以给公众号推文积累素材。
废话不多说,开始今天的学习吧,三个pandas中经典中经典的函数使用分享,欢迎大家点赞、转发本文,支持作者,公众号简说Python技术文章,只要点赞破百,老表就会在视频号开直播带带大家一起进行项目复现。
二、本文概要
pandas merge by 修罗闪空 pandas apply by pluto、乔瞧 pandas pivot_table by 石墨锡
三、pandas merge by 修罗闪空
3.1 merge函数用途
pandas中的merge()函数类似于SQL中join的用法,可以将不同数据集依照某些字段(属性)进行合并操作,得到一个新的数据集。
3.2 merge函数的具体参数
用法:
DataFrame1.merge(DataFrame2,
how=‘inner’, on=None, left_on=None,
right_on=None, left_index=False,
right_index=False, sort=False, suffixes=(‘_x’, ‘_y’))
参数说明: how:默认为inner,可设为inner/outer/left/right; on:根据某个字段进行连接,必须存在于两个DateFrame中(若未同时存在,则需要分别使用left_on和right_on来设置); left_on:左连接,以DataFrame1中用作连接键的列; right_on:右连接,以DataFrame2中用作连接键的列; left_index:将DataFrame1行索引用作连接键; right_index:将DataFrame2行索引用作连接键; sort:根据连接键对合并后的数据进行排列,默认为True; suffixes:对两个数据集中出现的重复列,新数据集中加上后缀_x,_y进行区别。
3.3 merge函数的应用
3.3.1 merge一般应用
import pandas as pd
# 定义资料集并打印出来
left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
print(left)
print('------------')
print(right)

单个字段连接
# 依据key1 column合并,并打印
res = pd.merge(left, right, on='key1')
print(res)
多字段连接
# 依据key1和key2 column进行合并,并打印出四种结果['left', 'right','outer', 'inner']
res = pd.merge(left, right, on=['key1', 'key2'], how='inner')
print(res)
res = pd.merge(left, right, on=['key1', 'key2'], how='outer')
print(res)
res = pd.merge(left, right, on=['key1', 'key2'], how='left') # 以left为主进行合并
print(res)
res = pd.merge(left, right, on=['key1', 'key2'], how='right') # 以right为主进行合并
print(res)
3.3.2 merge进阶应用
indicator 设置合并列数据来源
# indicator 设置合并列数据来源
df1 = pd.DataFrame({'coll': [0, 1], 'col_left': ['a', 'b']})
df2 = pd.DataFrame({'coll': [1, 2, 2], 'col_right': [2, 2, 2]})
print(df1)
print('---------')
print(df2)
# 依据coll进行合并,并启用indicator=True,最后打印
res = pd.merge(df1, df2, on='coll', how='outer', indicator=True)
print(res)
'''
left_only 表示数据来自左表
right_only 表示数据来自右表
both 表示两个表中都有,也就是匹配上的
'''

# 自定义indicator column的名称并打印出
res = pd.merge(df1, df2, on='coll', how='outer', indicator='indicator_column')
print(res)
依据index合并
# 依据index合并
# 定义数据集并打印出
left = pd.DataFrame({'A': ['A0', 'A1', 'A2'],
'B': ['B0', 'B1', 'B2']},
index = ['K0', 'K1', 'K2'])
right = pd.DataFrame({'C': ['C0', 'C2', 'C3'],
'D': ['D0', 'D2', 'D3']},
index = ['K0', 'K2', 'K3'])
print(left)
print('---------')
print(right)
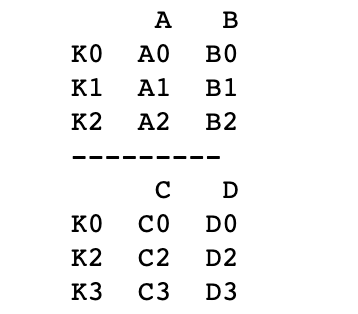
# 依据左右数据集的index进行合并,how='outer',并打印
res = pd.merge(left, right, left_index=True, right_index=True, how='outer')
print(res)
# 依据左右数据集的index进行合并,how='inner',并打印
res = pd.merge(left, right, left_index=True, right_index=True, how='inner')
print(res)
解决overlapping的问题
# 解决overlapping的问题
# 定义资料集
boys = pd.DataFrame({'k': ['K0', 'K1', 'K2'], 'age': [1, 2, 3]})
girls = pd.DataFrame({'k': ['K0', 'K1', 'K3'], 'age': [4, 5, 6]})
print(boys)
print('---------')
print(girls)
# 使用suffixes解决overlapping的问题
# 比如将上面两个合并时,age重复了,则可通过suffixes设置,以此保证不重复,不同名(默认会在重名列名后加_x _y)
res = pd.merge(boys, girls, on='k', suffixes=['_boy', '_girl'], how='inner')
print(res)
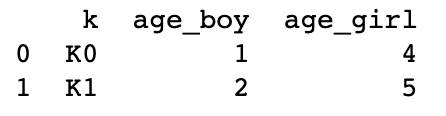
四、pandas apply by pluto、乔瞧
4.1 pandas apply by pluto
apply函数是pandas中极其好用的一个函数,它可以对dataframe在行或列方向上进行批量化处理,从而大大简化数据处理的过程。
apply函数的基本形式:
DataFrame.apply(func,
axis=0, broadcast=False,
raw=False, reduce=None, args=(), **kwds)
我们最常用前两个参数,分别是func运算函数和axis运算的轴,运算轴默认是axis=0,按列作为序列传入func运算函数,设置axis=1则表示按行进行计算。
在运算函数并不复杂的情况下,第一个参数通常使用lambda函数。当函数复杂时可以另外写一个函数来调用。下面通过一个实例来说明:
import pandas as pd
df = pd.DataFrame({'A':[3,1,4,1,5,9,None,6],
'B':[1,2,3,None,5,6,7,8]})
d = df.apply(lambda x: x.fillna(x.mean()))
print(df)
print('----------')
print(d)
处理前的数据: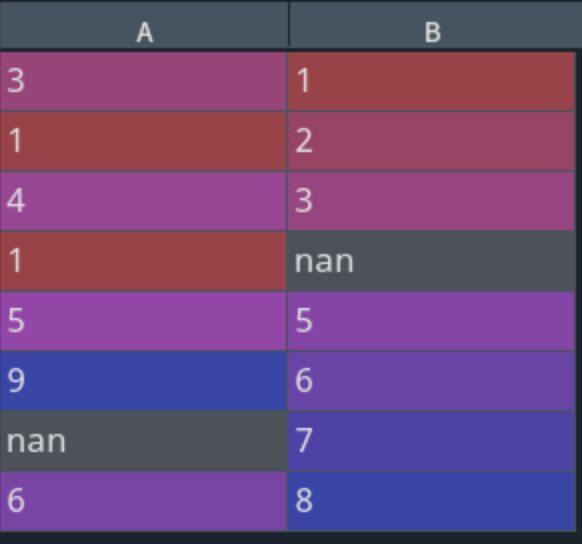 处理后的数据:
处理后的数据: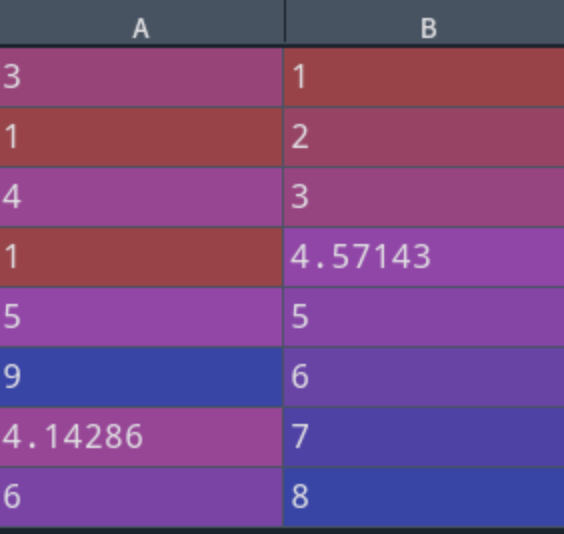
可以看到上面代码通过apply对nan值进行了均值填充,填充的为nan值所在列的均值。
在默认情况下,axis参数值为0,表示在行方向上进行特定的函数运算,即对每一列进行运算。
我们可以设置axis=1来对每一行进行运算。例如我将上例设置为axis=1,结果变为: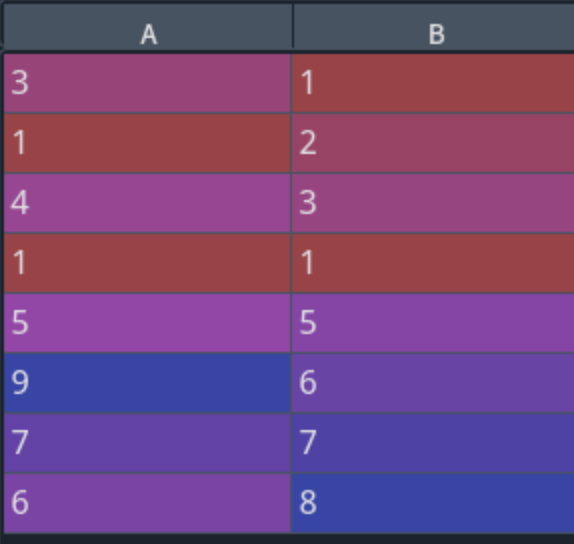
可以看出它是使用每行的均值对nan值进行了填充。
apply也可以另写函数来调用:
import pandas as pd
df = pd.DataFrame({'A':[3,1,4,1,5,9,None,6],
'B':[1,2,3,None,5,6,7,8]})
def add(x):
return x+1
d = df.apply(add, axis=1)
print(df)
print('----------')
print(d)
这个函数实现了对每一列上的数字加一:
注意:行方向,不是指对行进行运算。
比如:一行有[a, b, c, d],行方向运算指的是按先计算a列,然后计算b列,再计算c列,最后计算d列,所以行方向指的只是运算顺序的方向。
(不用过度纠结,记住axis=0是对列进行计算,axis=1是对行进行计算即可)
4.2 pandas apply by 乔瞧
首先还是要感谢【老表Max】推送的视频及文档,都比较精华,为初学者指明了方向。
今天是学习pandas的第四天,最深感触是其在处理EXCEL数据方面可为鬼斧神工,无论增、删、查、分都高效快捷,本以为Pandas做到这种程度已经相当棒了,但是当学到apply函数时,才发觉它超出了自己的想象力。
Apply简单案例如下:
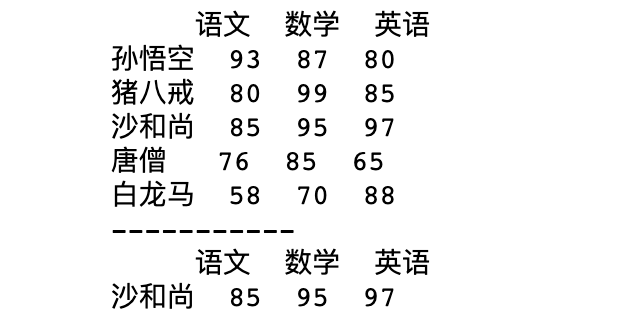
唐僧师徒加上白龙马一行五人去参加成人考试,考试科目包含语文、数学、英语共三门,现在想要知道三门科目成绩均不小于85分的人有哪些?
import pandas as pd
df = pd.DataFrame({'语文':[93,80,85,76,58],
'数学':[87,99,95,85,70],
'英语':[80,85,97,65,88]},
index=['孙悟空','猪八戒','沙和尚','唐僧','白龙马']
)
print(df)
print('-----------')
df1 = df.loc[df['语文'].apply(lambda x:85<=x<100)] \
.loc[df['英语'].apply(lambda x:85<=x<100)] \
.loc[df['数学'].apply(lambda x:85<=x<100)]
print(df1)
pandas pivot_table by 石墨锡
在pandas中 除了pivot_table 还有pivot函数也一样可以实现数据透视功能,前者可以看成后者的增强版。
pivot_table函数的基本形式:
DataFrame.pivot_table(self, values=None, index=None, columns=None, aggfunc='mean', fill_value=None, margins=False, dropna=True, margins_name='All', observed=False)
pivot_tabel对数据格式要求不高,而且支持aggfunc/fillvalue等参数,所以应用更加广泛。
pivot_table函数的参数有values(单元格值)、index(索引)、columns(列名),这些参数组成一个数据透视表的基本结构。
复杂一点 要用到aggfunc方法,默认是求均值(针对于数值列),当然也可以求其他统计量或者得到数据类型的转换,而且可以多个统计方法同时使用。
总而言之,pivot_table可以转换各个维度去观察数据,达到“透视”的目的。
案例说明:
import numpy as np
import pandas as pd
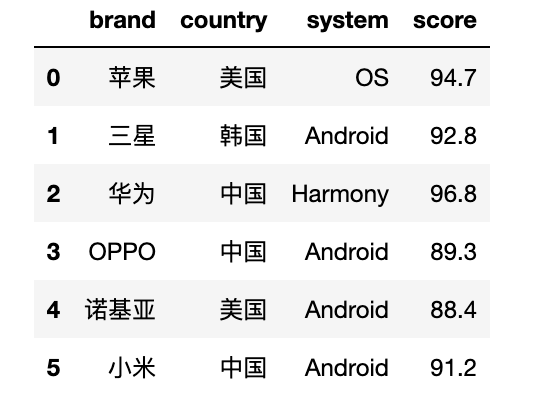
df = pd.DataFrame({'brand': ['苹果', '三星', '华为', 'OPPO', '诺基亚', '小米'],
'country': ['美国','韩国','中国','中国','美国','中国'],
'system': ['OS', 'Android', 'Harmony', 'Android', 'Android', 'Android'],
'score': [94.7, 92.8, 96.8, 89.3, 88.4, 91.2]})
df
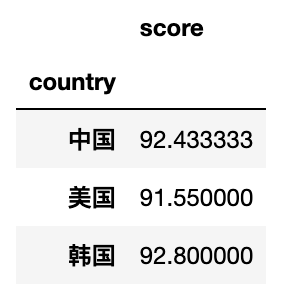
# 按country进行分组,默认计算数值列的均值
df.pivot_table(index='country')
# 按country进行分组,除了计算score均值,另外计算每个国家出现的品牌个数(不重复)
df.pivot_table(index='country',aggfunc={'score':np.mean,'brand':lambda x : len(x.unique())})
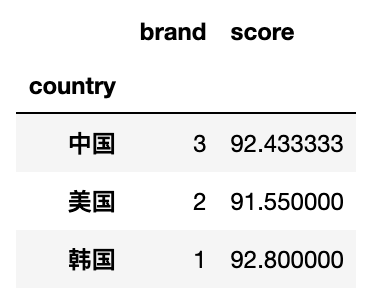
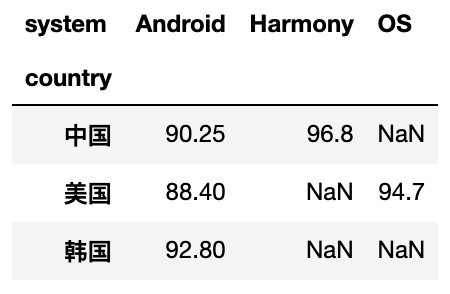
# 按country进行分组,system作为列名,score作为表中的值(重复的取均值),取对应的数据生成新的表
df.pivot_table(index='country',columns='system',values='score')
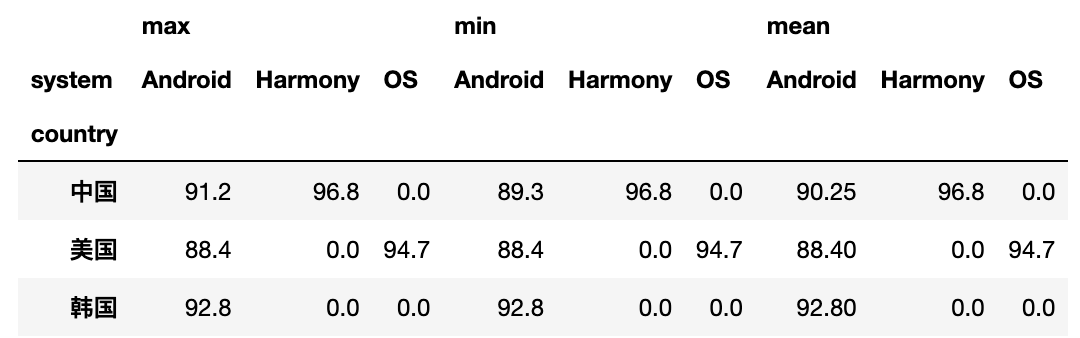
# 统计各个国家手机的最高分 最低分 平均分,空值填充为零
df.pivot_table(index='country',columns='system',values='score',aggfunc=[max,min,np.mean],fill_value=0)
最后,再次给大家安利下《深入浅出Pandas:利用Python进行数据处理与分析》,将pandas相关知识讲的特别齐全、详细,最后一章节还要大量的实践项目和案例,我在编辑本文时,对于读者分享内容中不确定的部分,也有查看图书说明,深感这本图书对于pandas使用者的好处。
今天就到这里啦,欢迎大家在评论区留言说说你学习本文的感受或者你想推荐的其他pandas使用技巧,优秀分享将有可能获得赠书或者红包奖励哦~
--END--
本文所有源码,都已在Jupyter Notebook中调试通过(Python3.7+),需要源码的,可以扫下方二维码,添加老表微信获取,回复:pandas数据分析 即可。
扫码即可加我微信
老表朋友圈经常有赠书/红包福利活动
新玩法,以后每篇技术文章,点赞超过100+,我将在个人视频号直播带大家一起进行项目实战复现,快嘎嘎点赞吧!!!
直播将在我的视频号:老表Max 中开展,扫上方二维码添加我微信即可查看我的视频号。
大家的 点赞、留言、转发是对号主的最大支持。
学习更多: 整理了我开始分享学习笔记到现在超过250篇优质文章,涵盖数据分析、爬虫、机器学习等方面,别再说不知道该从哪开始,实战哪里找了 “点赞”就是对博主最大的支持