 机器学习算法工程师
机器学习算法工程师




导读
当涉及到在医学领域中应用计算机视觉时,大多数任务涉及到:
(1) 用于诊断的图像分类任务
(2) 识别和分离病变区域的分割任务
然而,在病理学癌症检测中,这并不总是可能的。获取标签既费时又费力。此外,病理切片的分辨率最高可达200000 x 100000像素,并且它们不适合在内存中进行分类,因为例如,ImageNet仅使用224 x 224像素进行训练。下采样通常不是一个选项,因为我们试图检测一个微小的区域,例如从300×300像素区域(图1中的几个点)变化的癌区域。
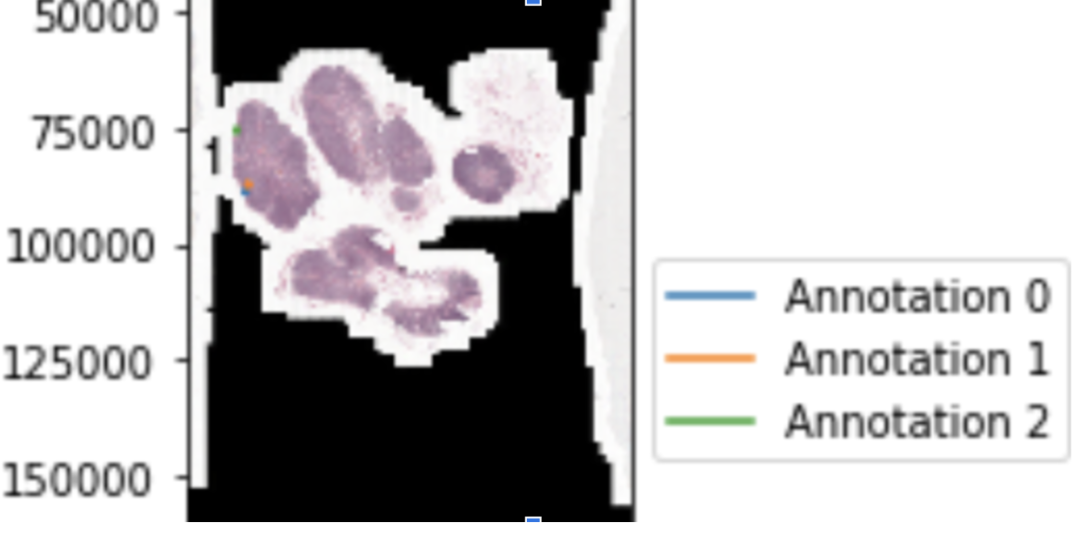
图一:来自patient_ 004 _ node _ 004(cameloyon 17)的幻灯片
在这种情况下,我们可以使用多实例学习(Multiple Instance Learning),这是一种弱监督学习方法,它采用一组包含许多实例的标记包,而不是接收一组标记实例。
假设我们有病理切片和每张切片的标签。因为我们不能在整个幻灯片上训练分类器,所以我们将每个幻灯片分成小块,在GPU上一次只处理几个小块。然而,我们不知道每个图块的标签,因此我们需要多实例学习。在MIL框架中,幻灯片是“包”,切片是“实例”。通过使用它,我们能够节省标记工作,并利用弱标记数据。
当我们有患者的病理切片时,我们希望预测大切片是否包含癌细胞,或者缩小患者是否有恶性细胞,多实例学习是一个很好的选择,因为医生不需要分割单个细胞或标记每个切片。只有整张幻灯片需要标签。
一般来说,多实例学习可以处理分类问题、回归问题、排序问题和聚类问题,但我们这里主要关注分类问题。
在这篇文章中,我将通过一个基于 MNIST 数据集的简单示例来解释 MIL 如何工作。如果你不熟悉 MNIST 数据集,这里有一个[关于 MNIST 数据集](https://www.kaggle.com/ngbolin/mnist-dataset-digit-recognizer)的[Kaggle 竞赛](https://www.kaggle.com/ngbolin/mnist-dataset-digit-recognizer)的链接,你可以看看。
MNIST数据集简介
MNIST数据集是一个手写数字的大型数据库,每个图像都有一个从0到9的标签。它有6万张图像的训练集和1万张图像的测试集。每个的尺寸是28 x 28的灰度图。

图 2: Minst 手写分类数据集
多实例学习的问题简述
一个袋子里的xi每个实例都有一个标签yi。我们将包的标签定义为:
Y = 1,如果存在 yi ==1
Y = 0,如果对于每个yi,yi == 0
在MNIST数据集上应用多元线性回归的流程
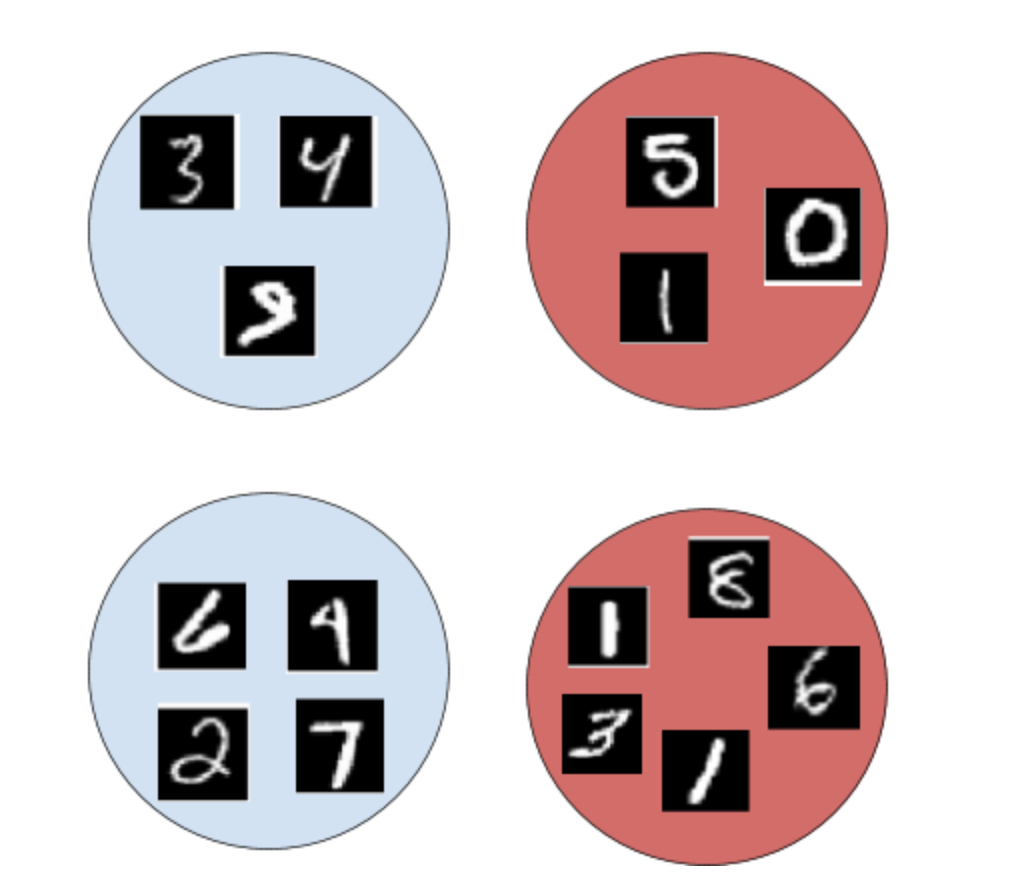
图 3:袋子和实例标签
我们将每个图像随机放入一个包中,每个包包含 3 到 7 个实例。为了节省内存,我们使用索引来表示图像(如下图)。
def data_generation(instance_index_label: List[Tuple]) -> List[Dict]:"""bags: {key1: [ind1, ind2, ind3],key2: [ind1, ind2, ind3, ind4, ind5],... }bag_lbls:{key1: 0,key2: 1,... }"""bag_size = np.random.randint(3,7,size=len(instance_index_label)//5)data_cp = copy.copy(instance_index_label)np.random.shuffle(data_cp)bags = {}bags_per_instance_labels = {}bags_labels = {}for bag_ind, size in enumerate(bag_size):bags[bag_ind] = []bags_per_instance_labels[bag_ind] = []try:for _ in range(size):inst_ind, lbl = data_cp.pop()bags[bag_ind].append(inst_ind)# simplfy, just use a temporary variable instead of bags_per_instance_labelsbags_per_instance_labels[bag_ind].append(lbl)bags_labels[bag_ind] = bag_label_from_instance_labels(bags_per_instance_labels[bag_ind])except:breakreturn bags, bags_labels
生成包标签:
def bag_label_from_instance_labels(instance_labels):return int(any(((x==1) for x in instance_labels)))
第 2 步:对 MNIST 数据集的 2 个部分进行预训练
1. 构造一个2D卷积神经网络,kernel_size=(7, 7), stride=(2, 2), padding=(3, 3)
2. 训练 5 个 epoch,批大小为 256
3. 保存模型
import torchfrom torchvision.models.resnet import ResNet, BasicBlockclass MnistResNet(ResNet):def __init__(self):super(MnistResNet, self).__init__(BasicBlock, [2, 2, 2, 2], num_classes=10)self.conv1 = torch.nn.Conv2d(1, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)def forward(self, x):return torch.softmax(super(MnistResNet, self).forward(x), dim=-1)
第 3 步:加载预训练模型并从最后一层提取特征
1. 将其余数据拆分为训练、验证和测试集
2. 获取训练、验证和测试集的特征
3. 获取 bag_indices 和 bag_labels
4. 使用基于索引的特征映射 bag_indices 并创建 bag_features
为了摆脱最后一层:
model = MnistResNet()model.load_state_dict(torch.load('mnist_state.pt'))body = nn.Sequential(*list(model.children()))# extract the last layermodel = body[:9]# the model we will usemodel.eval()
提取特征:
下面的代码展示了我们如何从数据生成函数中获取包索引和包特征:
bag_indices, bag_labels = data_generation(instance_index_label)bag_features = {kk: torch.Tensor(feature_array[inds]) for kk, inds in bag_indices.items()}
袋子索引、袋子标签和袋子特征如下所示:
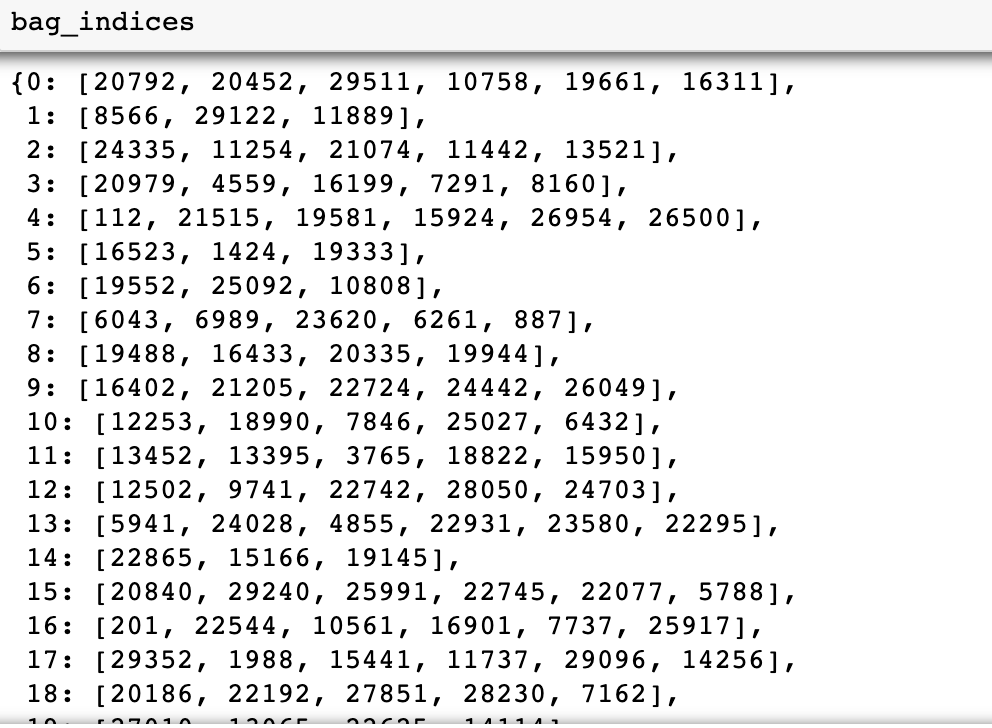
图 7:带图像索引的袋子索引
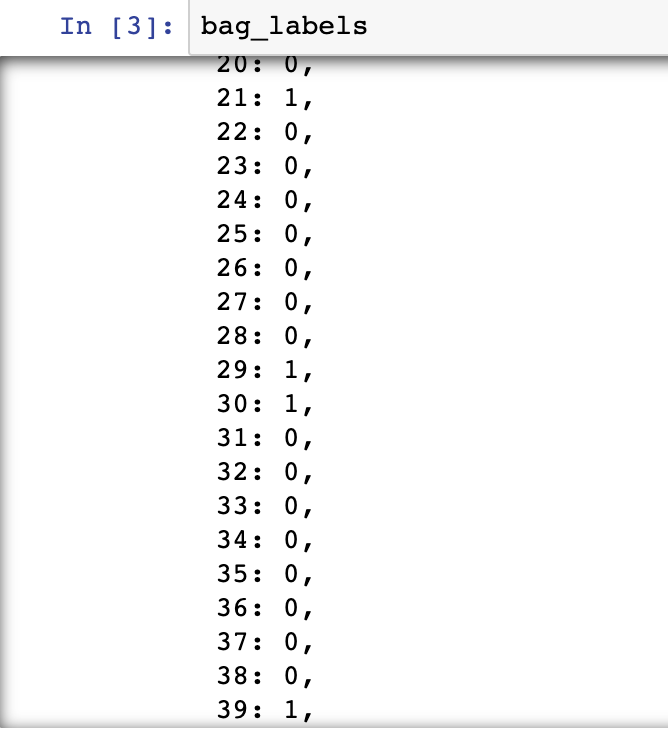
图 8:袋子标签

图 9:袋子特征
第 4 步:在 bag_features 和 bag_labels 上训练 MIL 模型并在测试集上进行评估
由于每个包都有不同数量的实例,我们需要在将张量放入模型之前将它们填充到相同的大小。
多实例学习模型:
该算法执行三个步骤。它们中的任何一个都可以是固定函数或可优化函数(神经网络):
1. 将实例转换为低维嵌入。(固定的)
2. 通过置换不变聚合函数传递嵌入。(可优化)
3. 转化为包概率。(可优化)
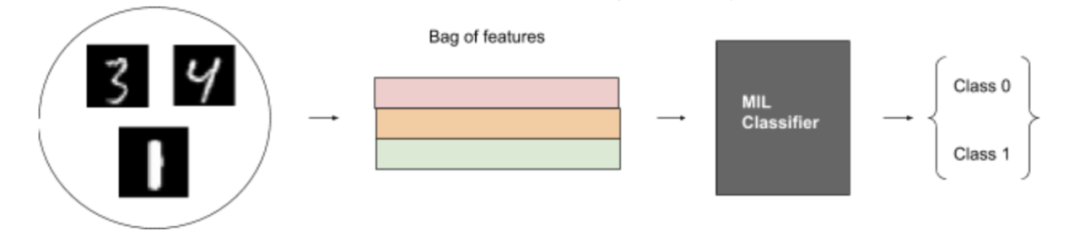
图 9:MIL-MNIST 玩具数据集上的 MIL 图
一般来说,工作流程如下:
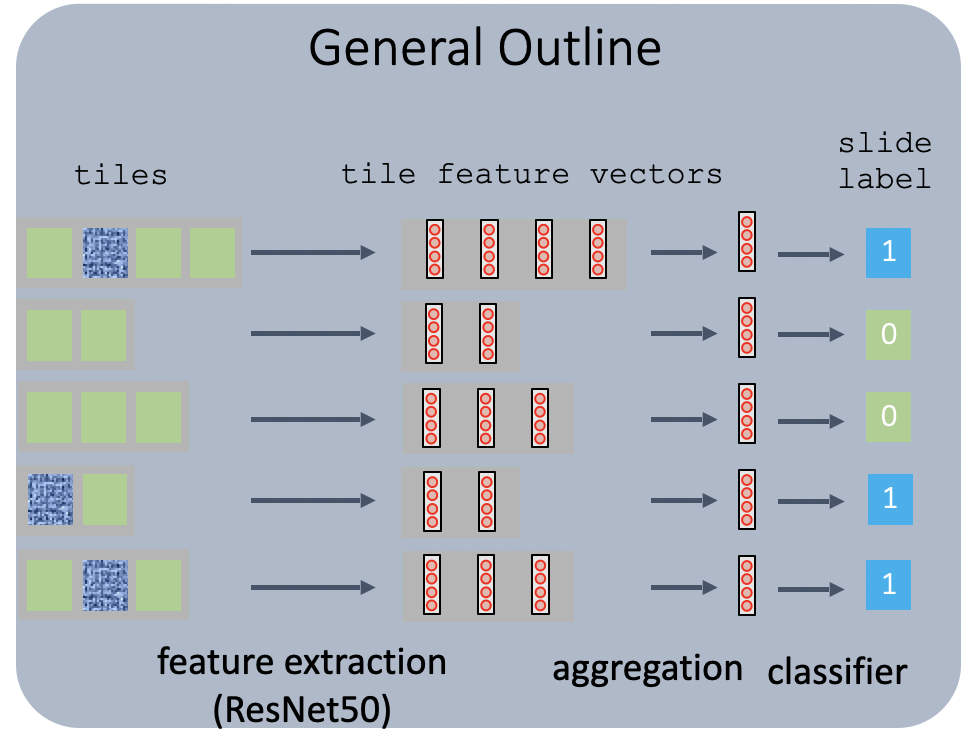
图 10:病理切片上的 MIL 算法框架图(参见参考文献 #5)
为简单起见,我们将步骤 1 固定为固定。对于第 2 步,虽然我们仍然可以使用固定函数,例如 max 或 mean,但为了启用可以通过反向传播端到端学习的参数优化,我们使用神经网络作为聚合函数。对于第 3 步,我们还希望使用反向传播来优化参数。
1. 线性层和 LeakyReLu
class NoisyAnd(torch.nn.Module):def __init__(self, a=10, dims=[1,2]):super(NoisyAnd, self).__init__()# self.output_dim = output_dimself.a = aself.b = torch.nn.Parameter(torch.tensor(0.01))self.dims =dimsself.sigmoid = nn.Sigmoid()def forward(self, x):# h_relu = self.linear1(x).clamp(min=0)mean = torch.mean(x, self.dims, True)res = (self.sigmoid(self.a * (mean - self.b)) - self.sigmoid(-self.a * self.b)) / (self.sigmoid(self.a * (1 - self.b)) - self.sigmoid(-self.a * self.b))return resclass NN(torch.nn.Module):def __init__(self, n=512, n_mid = 1024,n_out=1, dropout=0.2,scoring = None,):super(NN, self).__init__()self.linear1 = torch.nn.Linear(n, n_mid)self.non_linearity = torch.nn.LeakyReLU()self.linear2 = torch.nn.Linear(n_mid, n_out)self.dropout = torch.nn.Dropout(dropout)if scoring:self.scoring = scoringelse:self.scoring = torch.nn.Softmax() if n_out>1 else torch.nn.Sigmoid()def forward(self, x):z = self.linear1(x)z = self.non_linearity(z)z = self.dropout(z)z = self.linear2(z)y_pred = self.scoring(z)return y_predclass LogisticRegression(torch.nn.Module):def __init__(self, n=512, n_out=1):super(LogisticRegression, self).__init__()self.linear = torch.nn.Linear(n, n_out)self.scoring = torch.nn.Softmax() if n_out>1 else torch.nn.Sigmoid()def forward(self, x):z = self.linear(x)y_pred = self.scoring(z)return y_preddef regularization_loss(params,reg_factor = 0.005,reg_alpha = 0.5):params = [pp for pp in params if len(pp.shape)>1]l1_reg = nn.L1Loss()l2_reg = nn.MSELoss()loss_reg =0for pp in params:loss_reg+=reg_factor*((1-reg_alpha)*l1_reg(pp, target=torch.zeros_like(pp)) +\reg_alpha*l2_reg(pp, target=torch.zeros_like(pp)))return loss_reg
注意:我们设置 n = 7*512,其中 7 是一个包中的实例数,512 是每个特征的大小。
2. 聚合函数:AttensionSoftmax
class SoftMaxMeanSimple(torch.nn.Module):def __init__(self, n, n_inst, dim=0):"""if dim==1:given a tensor `x` with dimensions [N * M],where M -- dimensionality of the featur vector(number of features per instance)N -- number of instancesinitialize with `AggModule(M)`returns:- weighted result: [M]- gate: [N]if dim==0:..."""super(SoftMaxMeanSimple, self).__init__()self.dim = dimself.gate = torch.nn.Softmax(dim=self.dim)self.mdl_instance_transform = nn.Sequential(nn.Linear(n, n_inst),nn.LeakyReLU(),nn.Linear(n_inst, n),nn.LeakyReLU(),)def forward(self, x):z = self.mdl_instance_transform(x)if self.dim==0:z = z.view((z.shape[0],1)).sum(1)elif self.dim==1:z = z.view((1, z.shape[1])).sum(0)gate_ = self.gate(z)res = torch.sum(x* gate_, self.dim)return res, gate_class AttentionSoftMax(torch.nn.Module):def __init__(self, in_features = 3, out_features = None):"""given a tensor `x` with dimensions [N * M],where M -- dimensionality of the featur vector(number of features per instance)N -- number of instancesinitialize with `AggModule(M)`returns:- weighted result: [M]- gate: [N]"""super(AttentionSoftMax, self).__init__()self.otherdim = ''if out_features is None:out_features = in_featuresself.layer_linear_tr = nn.Linear(in_features, out_features)self.activation = nn.LeakyReLU()self.layer_linear_query = nn.Linear(out_features, 1)def forward(self, x):keys = self.layer_linear_tr(x)keys = self.activation(keys)attention_map_raw = self.layer_linear_query(keys)[...,0]attention_map = nn.Softmax(dim=-1)(attention_map_raw)result = torch.einsum(f'{self.otherdim}i,{self.otherdim}ij->{self.otherdim}j', attention_map, x)return result, attention_map
3. 中间以LeakyReLu为激活函数,dropout,sigmoid为最终激活函数的神经网络:
class MIL_NN(torch.nn.Module):def __init__(self, n=512,n_mid=1024,n_classes=1,dropout=0.1,agg = None,scoring=None,):super(MIL_NN, self).__init__()self.agg = agg if agg is not None else AttentionSoftMax(n)if n_mid == 0:self.bag_model = LogisticRegression(n, n_classes)else:self.bag_model = NN(n, n_mid, n_classes, dropout=dropout, scoring=scoring)def forward(self, bag_features, bag_lbls=None):"""bag_feature is an aggregated vector of 512 featuresbag_att is a gate vector of n_inst instancesbag_lbl is a vector a labelsfigure out batches"""bag_feature, bag_att, bag_keys = list(zip(*[list(self.agg(ff.float())) + [idx]for idx, ff in (bag_features.items())]))bag_att = dict(zip(bag_keys, [a.detach().cpu() for a in bag_att]))bag_feature_stacked = torch.stack(bag_feature)y_pred = self.bag_model(bag_feature_stacked)return y_pred, bag_att, bag_keys
4. 优化器:SGD
5. 损失函数:BCELoss
6. 准确度:~0.99
结论
我们使用 MIL 在 MNIST 数据集上获得了大约 0.99 的准确率,这是一个令人满意的结果。如果我们愿意,我们可以使用更复杂的聚合函数作为我们的中间转换,并构建更复杂的 NN 模型用于最终转换到包级别。结果还表明,MIL 是一个很好的工具,可以节省标记工作并利用弱标记数据。
Jupyter 笔记本演示链接:
https://github.com/lsheng23/Practicum/blob/master/MIL_MNIST/end_to_end_mnist_MIL.ipynb 点蓝色字关注“机器学习算法工程师”
点蓝色字关注“机器学习算法工程师”
设为星标,干货直达!
推荐阅读
谷歌AI用30亿数据训练了一个20亿参数Vision Transformer模型,在ImageNet上达到新的SOTA!
"未来"的经典之作ViT:transformer is all you need!
PVT:可用于密集任务backbone的金字塔视觉transformer!
涨点神器FixRes:两次超越ImageNet数据集上的SOTA
不妨试试MoCo,来替换ImageNet上pretrain模型!
机器学习算法工程师
一个用心的公众号



