 HBase技术社区
HBase技术社区




DNA 序列在分子生物学和医药研究中有着广泛的应用,比如基因溯源、物种鉴定、疾病诊断等。如果结合正在兴起的基因大数据,采取大量的样本,那么通常实验结果更具说服力,也能够更有效地投入现实应用。
Milvus 作为一款开源的、对海量数据友好的向量数据库,能够高效地存储和检索核酸序列的嵌入。在提高效率的同时,Milvus 也能够帮助降低项目研究或系统搭建的成本。由 Milvus 搭建的 DNA 序列分类系统,不仅毫秒之间能够识别基因的类别,还比机器学习领域里常见的分类器们更加精准。
数据处理
基因是带有遗传信息的 DNA 序列片段,由数个碱基【A, C, G, T】排列组合而成。每个生物都有不同的基因组,比如人类基因组中含有3万个左右基因,约30亿个 DNA 碱基对,每个碱基对有2个对应的碱基。
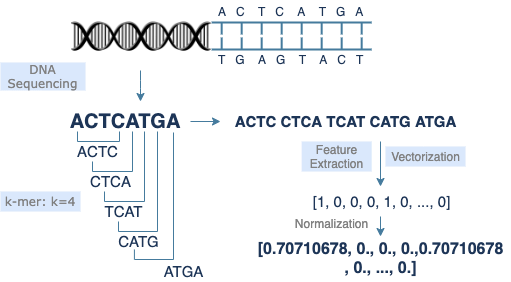
k-mer
向量化
Milvus示例
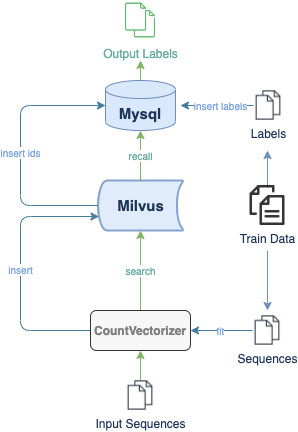
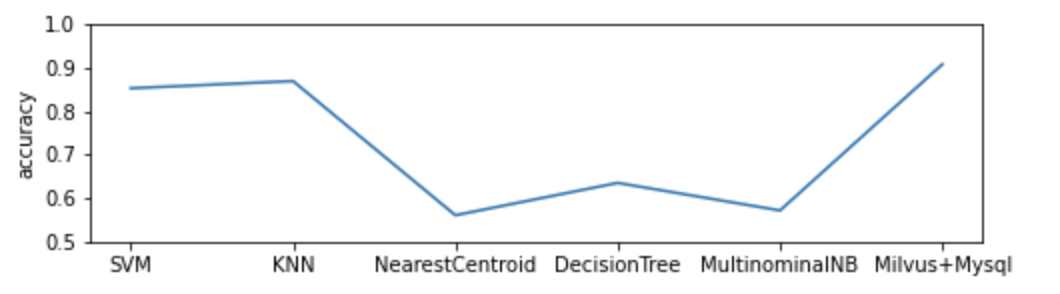
一个简单的演示案例展现了如何使用Milvus搭建 DNA 序列的分类系统,实验数据[3]包含了三个物种的7种基因序列。在插入 Milvus 之前,该示例首先将所有的 DNA 序序列进行了 k-mer 处理,然后训练了词袋模型用以特征提取与向量化。该结合 Milvus 与 Mysql 的分类模型结构如下图所示,包括了插入和搜索两个流程。
(https://github.com/milvus-io/bootcamp/tree/master/solutions/dna_sequence_classification)
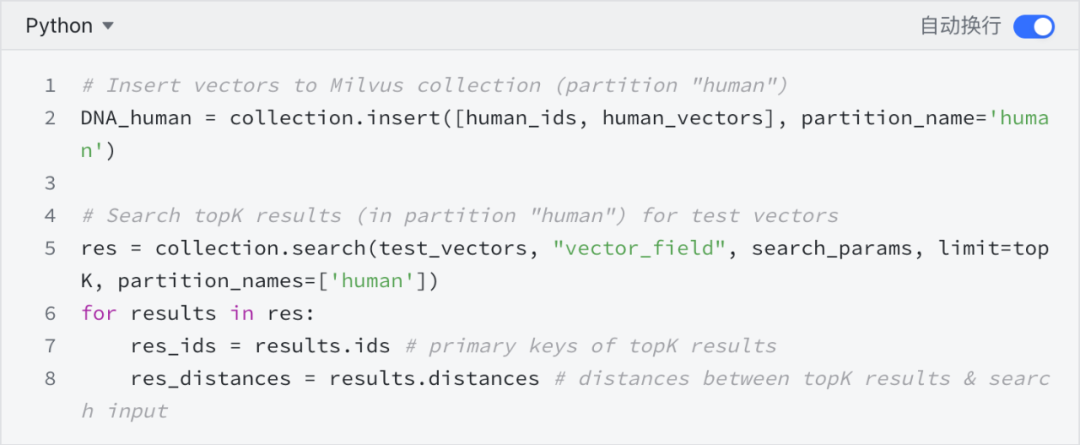
基因序列分类
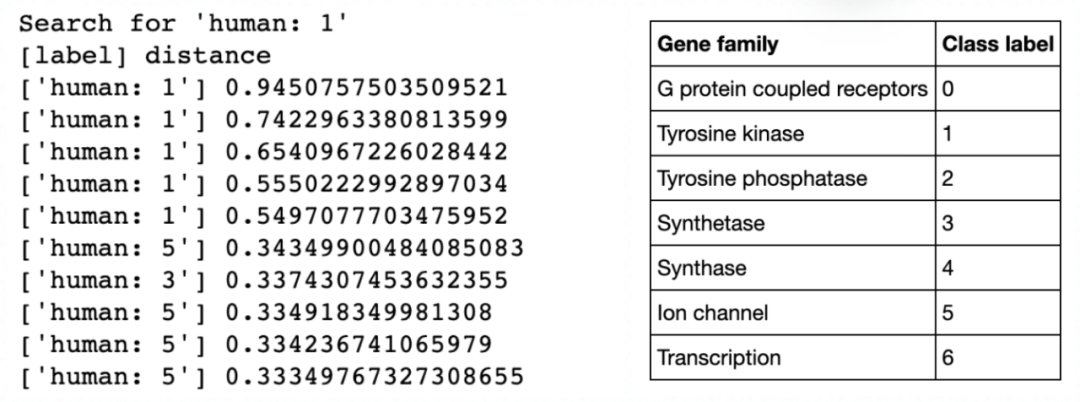
物种相似程度

实验表现

应用拓展
随着基因大数据的发展和完善,向量化后的 DNA 序列数据能够更好地参与科学研究与实践应用。如果能够结合生物学的专业知识,便可以更合理地向量化 DNA 序列、计算距离、解读结果。
融入生物学并采用大量的样本能够很大程度地改进基因序列的向量数据库,Milvus 便能够更好地发挥所长。根据现实需求,Milvus 相似性搜索和距离计算有很大的潜力被投入各种应用。
未知序列研究:研究表明向量化序列能够压缩数据,根据已知基因序列研究未知序列的结构、功能、进化关系。[5] 当拥有足够的序列数据进行研究时,实验结果会更加可靠有效,但数据的存储和处理会成为一个问题。将其向量化后使用 Milvus 能够在节约数据处理成本的同时,保持甚至提高模型准确率。 适配硬件:受到传统的生物分子序列比对算法限制,基因序列相似性搜索无法受益于硬件(CPU/GPU)的发展[6][7]。Milvus 的加入可以从距离算法上解决这一问题,更好地根据数据规模适配硬件,从而显著提高搜索效率。 鉴定或溯源病毒:现实中鉴定新冠病毒的起源时,科学家通过比较毒株核苷酸序列推测出新冠病毒或起源于蝙蝠,同时发现其比起 MERS 更接近 SARS 病毒。[8] 该实验采用了 5 例病患的数据,如果在此基础上使用更大的样本进行验证或者研究,结论能够更具说服力,或发现更多的模式。
疾病诊断:临床上一般是对比检查对象与健康人的基因序列,找出可引起疾病的变异基因。[9] 在疾病对应的基因位置得到序列,根据健康与否、严重程度或疾病类型将大量的样本数据分类。将这些数据通过合适的算法提取特征并向量化后插入 Milvus,计算向量距离并转换成患病概率,就可以实现基于基因序列的人工智能疾病诊断系统。除了能够协助疾病诊断外,该应用也能够帮助推进靶向治疗的发展[10]。
参考资料:

 Github @Milvus-io|CSDN @Zilliz Planet|Bilibili @Zilliz-Planet
Github @Milvus-io|CSDN @Zilliz Planet|Bilibili @Zilliz-Planet
Zilliz 以重新定义数据科学为愿景,致力于打造一家全球领先的开源技术创新公司,并通过开源和云原生解决方案为企业解锁非结构化数据的隐藏价值。
Zilliz 构建了 Milvus 向量数据库,以加快下一代数据平台的发展。Milvus 目前是 LF AI & Data 基金会的毕业项目,能够管理大量非结构化数据集。我们的技术在新药发现、计算机视觉、推荐引擎、聊天机器人等方面具有广泛的应用。

