水木人工智能学堂
水木人工智能学堂




预计阅读时间:8分钟

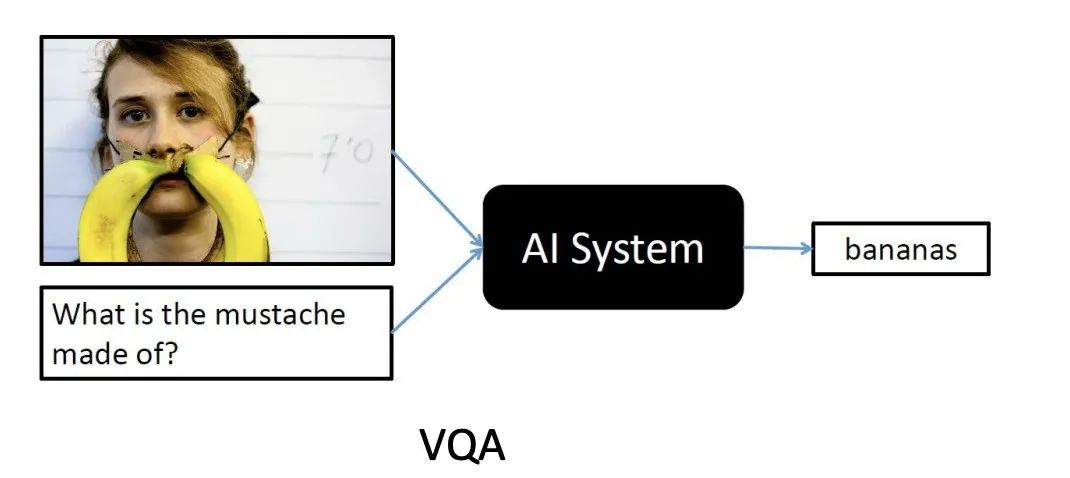
给大家出一道视觉问答题:在下面这张图片中,根据有礼服装饰的小熊玩具照片推理出这些玩具用来做什么的?

一个可能的答案或许是“婚礼”~
这道题对人类而言太简单不过了,那么对 AI 来说呢?
AI 在这视觉问答方面能和人类相比吗?
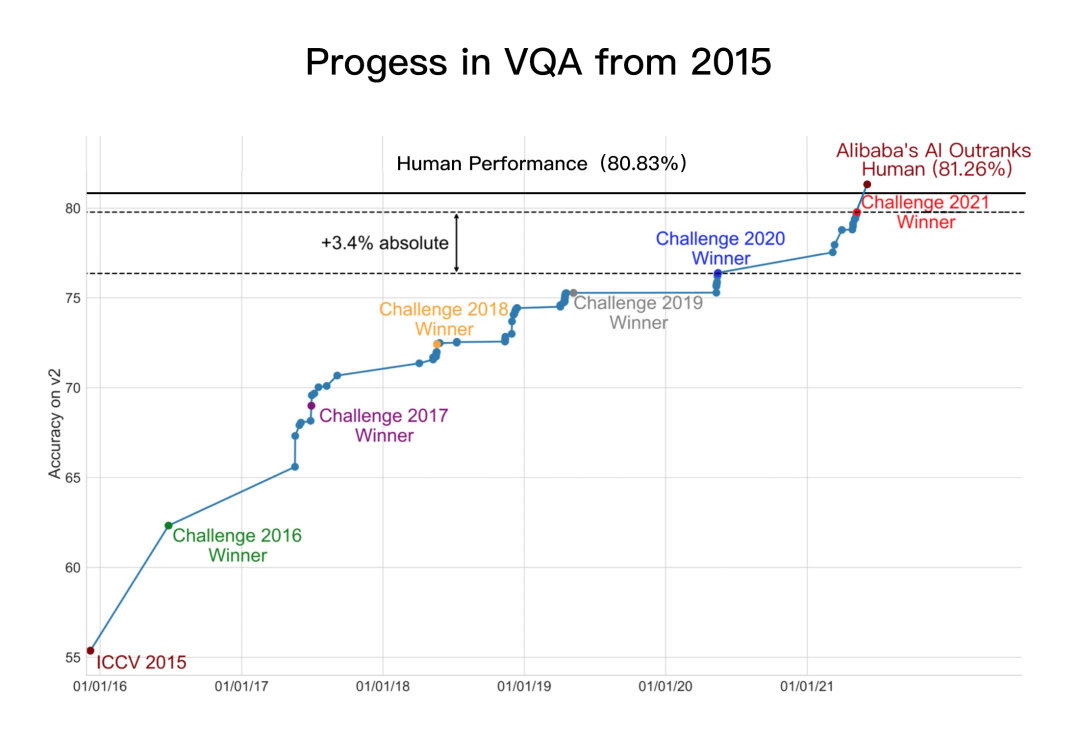
答案来了——历时6年,在机器视觉问答领域,第一位得分超越人类的AI选手诞生了!
8月12日,AI 科技评论注意到,国际权威机器视觉问答榜单 VQA Leaderboard出现关键突破:阿里巴巴达摩院以81.26%的准确率创造了新纪录,让AI在“读图会意”上首次超越人类基准。继2015年、2018年AI分别在视觉识别及文本理解领域超越人类分数后,人工智能在多模态技术领域也迎来一大进展。
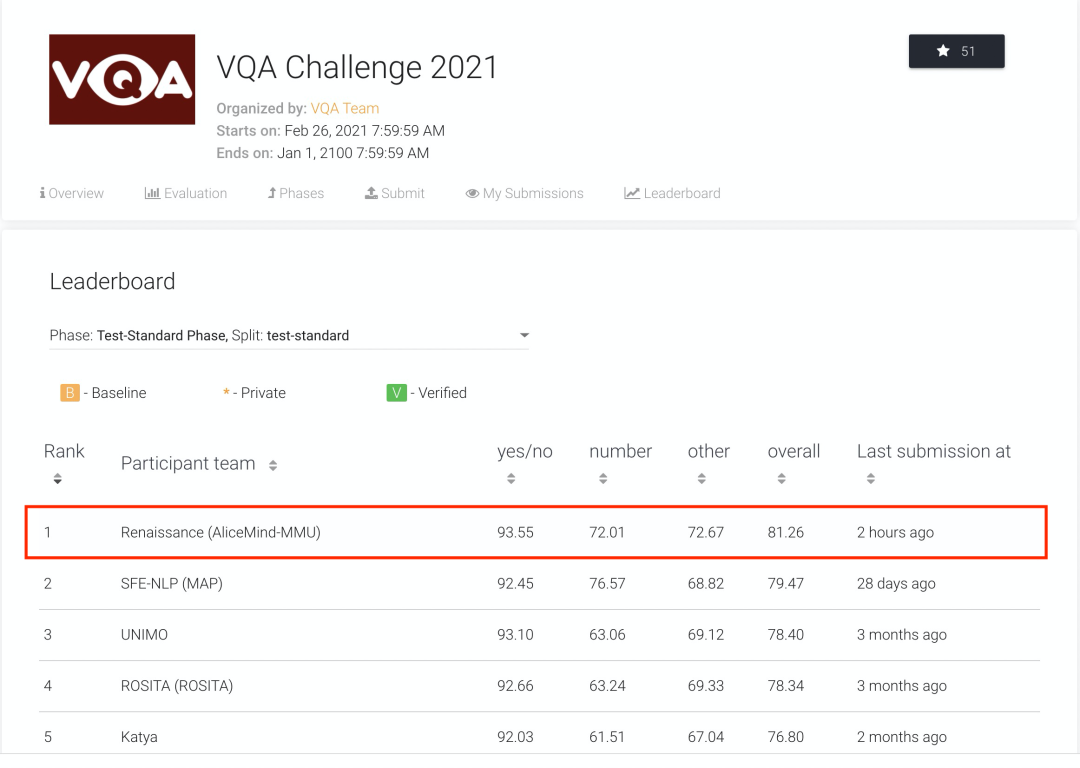
图注:达摩院AliceMind在VQA Leaderboard上创造首次超越人类的纪录
比较难得的是,3年前,让中国AI在文本理解领域历史性超越人类的,同样是达摩院AI研究团队。
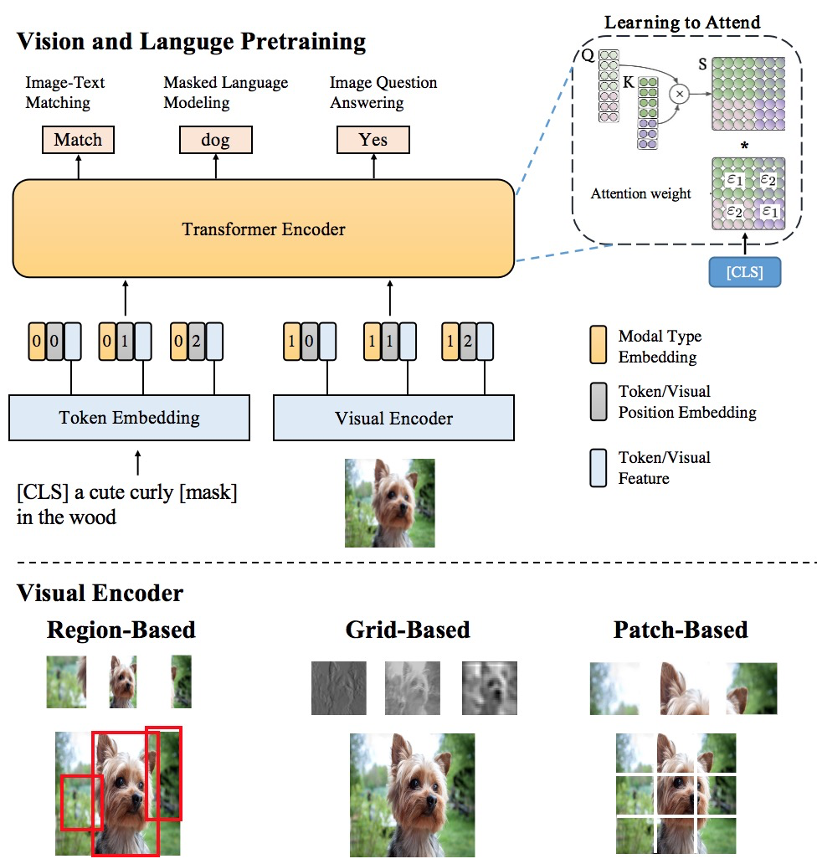
多样性的视觉特征表示,从各方面刻画图片的局部和全局语义信息,同时使用Region,Grid,Patch等视觉特征表示,以更精准地进行单模态理解; 基于海量图文数据和多粒度视觉特征的多模态预训练,用于更好地进行多模态信息融合和语义映射,创新性地提出了SemVLP,Grid-VLP,E2E-VLP和Fusion-VLP等预训练模型; 研发自适应的跨模态语义融合和对齐技术,创新性地在多模态预训练模型中加入Learning to Attend机制来进行跨模态信息地高效深度融合;