
用pandas做数据分析不知道从哪下手?那是因为你没有套路!
因此,对于一份数据分析报告:
第一,要明确自己的分析目的和服务的对象 第二,就是要掌握一些常用的套路,这个是技术层面的东西,也是我们这一次要分享的。
产品的强度是否真的变化大 生产过程中哪些因素对产品的强度影响大? 能有什么方案改善
首先导入必要的库,和数据集
我们主要是用pandas和matplot/seabron进行分析和可视化。在导入之后我会习惯性的同时输出一下各个库的版本,核对一下开发环境
# 先导入必要的计算包并查看版本,最好将pandas升级到0.24以上
import numpy as np
import pandas as pd
import matplotlib as mpl
import seaborn as sns
import matplotlib.pyplot as plt
for model in np,pd,mpl,sns:
print(model.__name__, model.__version__)
>>>
numpy 1.19.5
pandas 1.2.4
matplotlib 3.3.4
seaborn 0.11.1
另外,为了做出的图美观一点,我们可以使用plt.style设置图形的样式。这里我喜欢使用bmh或者ggplot风格。
# 去掉警告,不影响程序运行
import warnings
warnings.filterwarnings('ignore')
#图形显示风格, ggplot或者bmh, 比默认的好看
plt.style.use('bmh')
#省去plt.show(),直接出图
%matplotlib inline
之后在导入数据。导入完之后都是df.head查看一下前五行,目的是了解一下数据集包含哪些字段,同时也验证一下数据集是否有问题。本次的数据集和字段含义如下: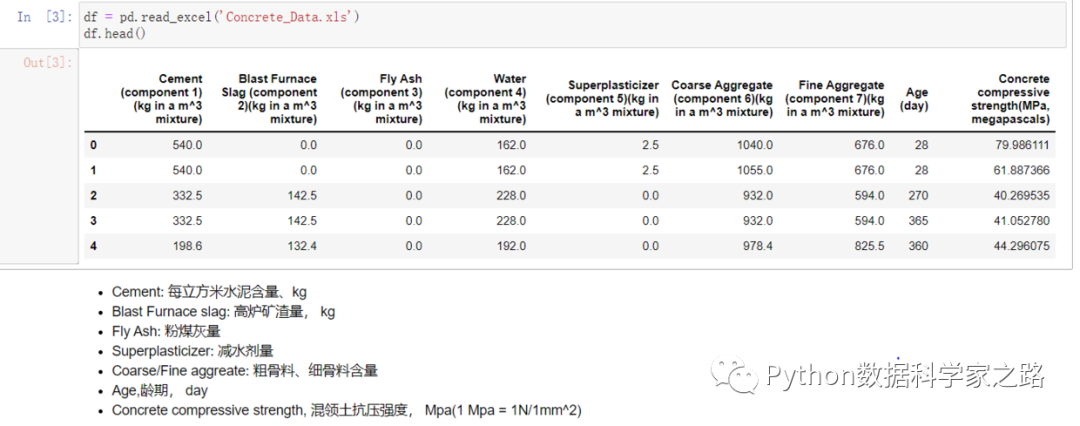
原数据集中的字段名称(列明)太长,我们可以将其简化,变化后期展示:
# 简化字段名称
df.columns = ['水泥含量', '高炉矿渣含量', '粉煤灰量', '含水量', '减水剂含量', \
'粗骨料含量', '细骨料含量', '龄期', '强度/Mpa']
df.head()
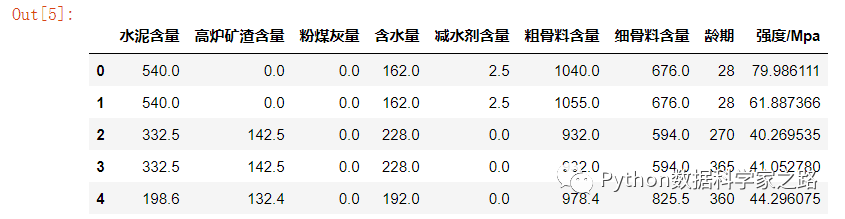
改完后清爽许多了
下面是本次的重点,我们看看有哪些套路帮助我们分析
套路一:基本的数据查看
df.info 可以输出总体的数据量以及每个字段的数据类型 df.describe是pandas中我最喜欢的一个功能之一,可以输出所有数值型字段的均值标准差等
>>>df.info()
>>>
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1030 entries, 0 to 1029
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 水泥含量 1030 non-null float64
1 高炉矿渣含量 1030 non-null float64
2 粉煤灰量 1030 non-null float64
3 含水量 1030 non-null float64
4 减水剂含量 1030 non-null float64
5 粗骨料含量 1030 non-null float64
6 细骨料含量 1030 non-null float64
7 龄期 1030 non-null int64
8 强度/Mpa 1030 non-null float64
dtypes: float64(8), int64(1)
memory usage: 72.5 KB
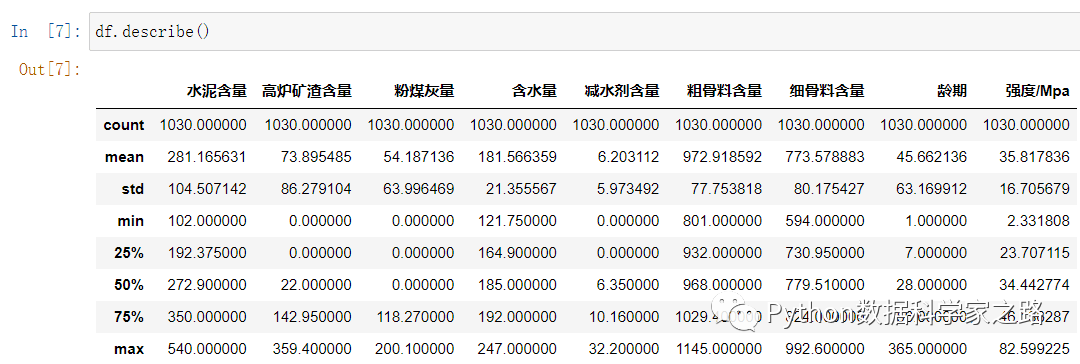
通过df.describe 我们可以发现:
粉煤灰/高炉矿渣/减水剂的含量可以为0, 且有至少25%的混凝土中含量为0 因为我们的目的是最终产品的强度,我们重点关注一下最后一列强度的情况,包括均值最大值最小值标准差等,上面都能看到
我们在将需要重点分析的强度值单独拿出来看一看
# 查看强度的分布情况
plt.figure(figsize=(15,6))
plt.subplot(121)
df['强度/Mpa'].plot(kind = 'hist', width = 3.5)
plt.xlabel('强度/Mpa', fontproperties="SimSun", fontsize=13) # 中文字体显示
plt.title('产品强度的概率密度分布',fontproperties="SimSun", fontsize=15)
plt.subplot(122)
plt.boxplot(df['强度/Mpa'])
plt.title('强度的箱线图',fontproperties="SimSun", fontsize=15)
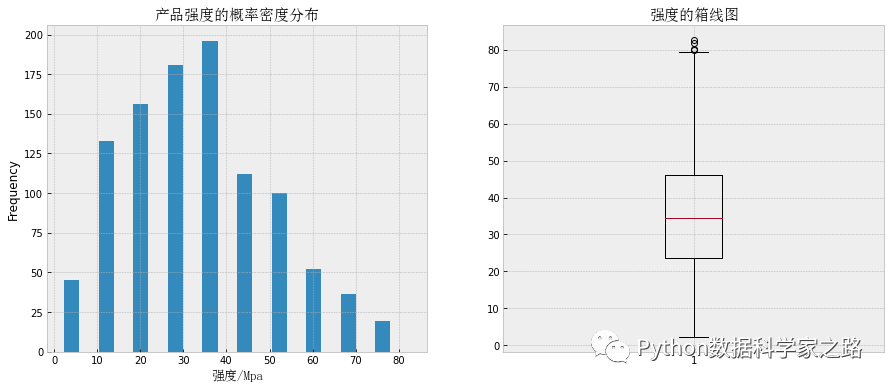
因为强度是一个单一的变量,我们可以使用折线图(变化缺失)、概率密度图(分布情况)、箱线图等进行展示。对于折线图,通常会有一个时间维度来查看变量随着时间的变化的变化趋势,这里数据集中没有时间数据。我们就用概率分布和箱线图来查看,从中我们可以发现:
第一张图中,由1000多个样本组成的概率分布,大概可以看到强度数值成正态分布,均值大概位置30-40之间,但是有个别强度较大(大于70),远离均值形成一个长尾趋势 在箱线图中,直接将大于80的那一部分样本作为异常值来处理。这个也说明一开始的客户投诉——最近的产品强度不稳定,也就是有一些产品有超规现象。
「知识链接」 【箱线图】 箱线图也称盒须图,盒图等,常用于直观地识别数据中异常值(离群点)和判断数据离散分布情况,了解数据分布状态。在箱线图中,盒子的部分是上下四分位数之间的数据,盒子中间的横线代表中位数。另外需要注意箱线图里面的极大值(上边缘值)有时候并非最大值,极小值(下边缘值)也不是最小值。如果数据有存在离群点即异常值,他们超出最大或者最小观察值,此时将离群点以“圆点”形式进行展示。如上图中强度大于80Mpa的部分样本
套路二:各个自变量和因变量的相关性分析
这个是主要内容。我们的主要目的就是想了解最终的混凝土强度和哪些变量最相关,从而找到一些问题的原因和改善的方法。在这里我们主要有定性的散点图查看和定量的相关系数计算。我们分成3个部分来完成这些分析
1 单变量数据分布情况
我们首先对这8个自变量也用箱线图查看一下,看看每个自变量的数据分布情况:
# 先用箱线图查看一下各个变量的分布
plt.figure(figsize=(20,16)) # 设置一张较大的图,容得下8张小图
for i, feature in enumerate(list(df.columns[:-1])):
plt.subplot(2,4,i+1)
plt.boxplot(df[feature], widths=0.2)
plt.title(feature, fontproperties="SimSun", fontsize=13)
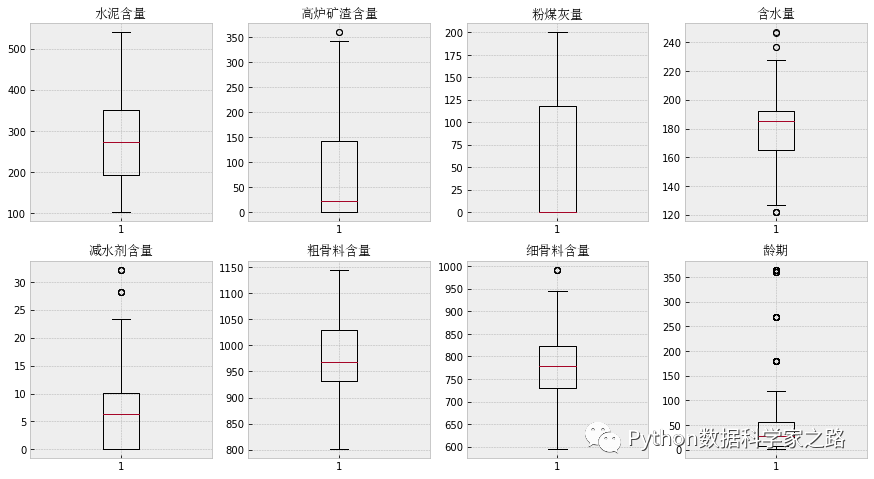
这张图看起来要比上面的describe功能直观的多,同时我们也能发现对于龄期这个变量有很多异常值,这些产品的龄期异常的高,这个是否是问题呢?这个就需要结合业务来分析了。
2 自变量和因变量的相关性定性分析
# 定性分析: 各个变量与因变量的pair-plot散点图查看
plt.figure(figsize=(20,16)) # 设置一张较大的图,容得下8张小图
for i, feature in enumerate(list(df.columns[:-1])):
plt.subplot(3,3,i+1)
plt.scatter(df[feature], df['强度/Mpa'])
plt.xlabel(feature, fontproperties="SimSun", fontsize=13 )
plt.ylabel('强度/Mpa',fontproperties="SimSun", fontsize=13)
上面的代码中,我们一次性将8个自变量和因变量的三点输出在一张大图上,便于查看,结果如下:
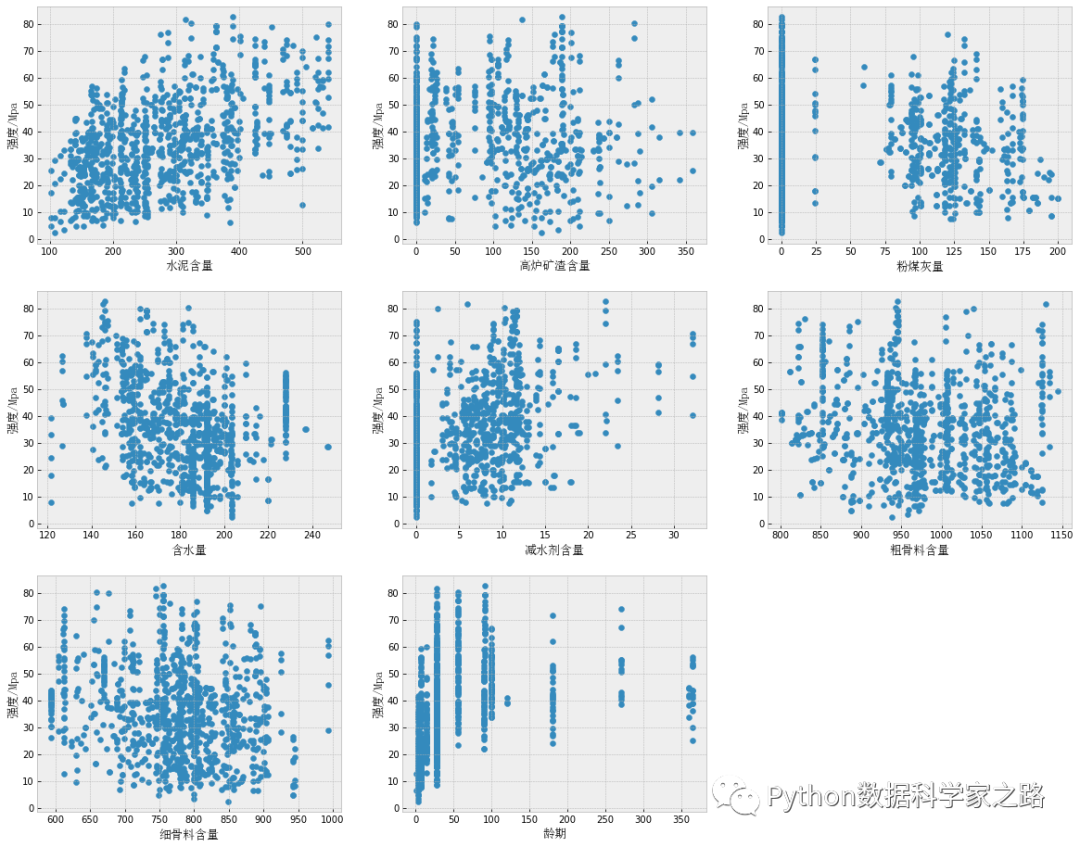
从这些图大概可以得知:
水泥含量cement和superplasticizer(减水剂含量)和强度有较好的正相关关系 water(含水量)和强度有较好的负相关关系 矿渣和龄期和强度没有关系,并且龄期好像还是一个离散型的变量
上面通过图形来进行直观展示,缺乏精确量化指标。下面我们进行定量分析,计算每个自变量和因变量的相关系数。
3 相关系数计算,定量分析
Python中计算相关性非常简单,直接df.corr即可。默认采用的是pearson系数。

我们重点关注 表格中的最后一列,即各个自变量和强度的相关系数。从中我们可以看到:
水泥含量和减水剂含量与强度有一定的相关性 龄期和强度也有一定的相关性,这个和我们从上面的散点图得到的结论有一些不一致。
这个也从侧面说明了对一个具体问题,定量和定性分析都是需要的,有时候图形虽然直观,但是不够精确。
套路三 进一步挖掘
在这里我们需要思考如何从数据中找到更多的线索,挖掘出更多的价值。主要思路有:
我们有8个自变量,我们是否可以考虑按照某些变量的取值将样本分组,每一组单独考虑而不是放在一起呢?即将某些变量的取值固定下来在计算其他指标,这个是一个常用的思路 考虑各个自变量之间的相关性。上面我们重点关注了自变量和因变量之间的关系,有时候我们的自变量之间有时候也是有一定相关性的。如果两个自变量之间相关性较强,我们可以考虑将其中一个变量去掉来为后期的机器学习简化模型 由于篇幅关系,我们仅用第一条举例说明。
我们考虑一下为啥套路二中定性和定量分析得出的关于龄期和强度关系不太一样?其实思考一下就可以发现主要是因为龄期里面有很多值较大,这些离群点作为噪音干扰了分析。那我们就把这些值去掉在看看。因为龄期的取值比较离散化,直至统计各个取值的个数
df['龄期'].value_counts()
>>>
28 425
3 134
7 126
56 91
14 62
90 54
100 52
180 26
91 22
365 14
270 13
360 6
120 3
1 2
Name: 龄期, dtype: int64
可以看到28天将近一半,取值在56天以上的样本比较少,我们将龄期取值在56天以内的样本放在一起单独分析看看
(df['龄期'] <= 56).sum() / len(df['龄期']) #统计龄期在56天以内的占比
>>> 0.8155339805825242
# age <= 56有超过80%的样本,单独分析
df_age56 = df[df['龄期'] <= 56]
df_age56.shape
>>> (840, 9)
上面创建一个新的Dataframe,其实是将原数据集中龄期在56天以内的样本放在一起。我们在套用上面的散点图和相关系数计算看一看
# 先定量分析,通过pariplot查看
plt.figure(figsize=(20,16))
for i, feature in enumerate(list(df_age56.columns[:-1])):
plt.subplot(3,3,i+1)
plt.scatter(df_age56[feature], df_age56['强度/Mpa'])
plt.xlabel(feature,fontproperties="SimSun", fontsize=13)
plt.ylabel('强度/Mpa',fontproperties="SimSun", fontsize=13)
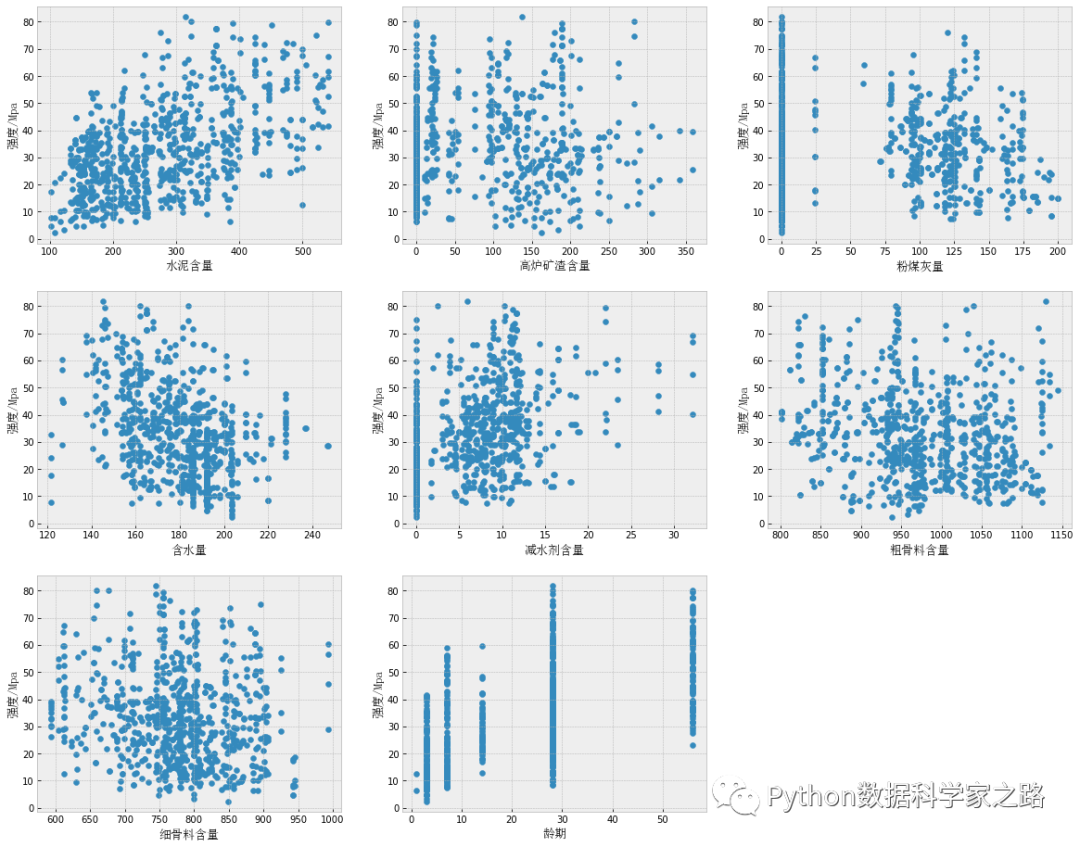
将龄期较大的样本去除后,龄期和强度的相关性明朗许多了!在定量计算看一看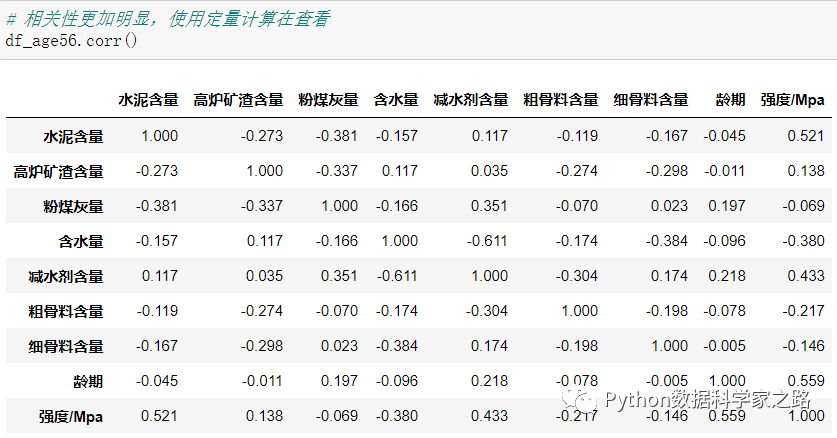
OK,去除噪声后,龄期和强度相关性更强了。和上面的定性分析统一起来了。关于其他变量的分组分析各位可以按照此套路自己尝试了。本次分享就到这里。
相关阅读: