 AI算法与图像处理
AI算法与图像处理




点击下方“AI算法与图像处理”,一起进步!
重磅干货,第一时间送达
写在前面
基于Self-Attention的Transformer结构,首先在NLP任务中被提出,最近在CV任务中展现出了非常好的效果。然而,大多数现有的Transformer直接在二维特征图上的进行Self-Attention,基于每个空间位置的query和key获得注意力矩阵,但相邻的key之间的上下文信息未得到充分利用。
论文和代码地址

论文地址:https://arxiv.org/abs/2107.12292代码地址:https://github.com/JDAI-CV/CoTNet核心代码:https://github.com/xmu-xiaoma666/External-Attention-pytorch#22-CoTAttention-Usage
Motivation
起初,CNN由于其强大的视觉表示学习能力,被广泛使用在各种CV任务中,CNN这种局部信息建模的结构充分使用了空间局部性和平移等边性。但是同样的,CNN由于只能对局部信息建模,就缺少了长距离建模和感知的能力,而这种能力在很多视觉任务中又是非常重要的。

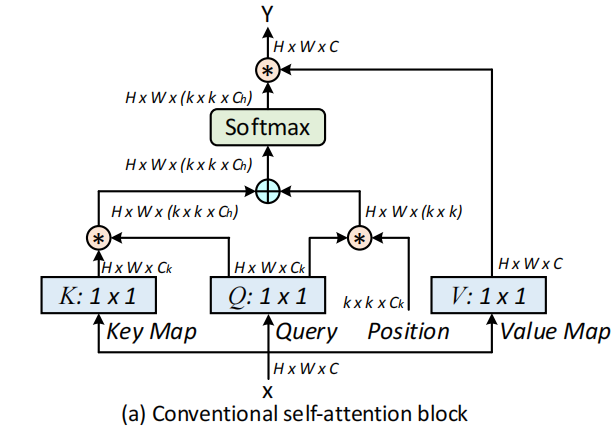
Transformer由于其强大的全局建模能力,被广泛使用在了各种NLP任务中。受到Transformer结构的启发,ViT、DETR等模型也借鉴了Transformer的结构来进行长距离的建模。然而,原始Transformer中的Self-Attention结构(如上图所示)只是根据query和key的交互来计算注意力矩阵,因此忽略了相邻key之间的联系。
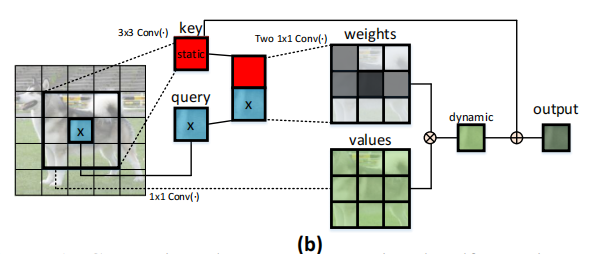
基于此,作者提出了这样一个问题——“有没有一种优雅的方法可以通过利用二维特征图中输入key之间的上下文来增强Transformer结构?”因此作者就提出了上面的结构CoT block。传统的Self-Attention只是根据query和key来计算注意力矩阵,从而导致没有充分利用key的上下文信息。
方法
3.1. Multi-head Self-attention
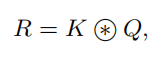
由于原始的Self-Attention对输入特征的位置是不敏感的,所以还需要在Q上加上位置信息,然后将结果与关系矩阵相加:
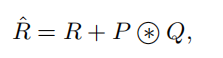
接着,我们还需要对上面得到的结果进行归一化,得到Attention Map:

得到Attention Map之后,我们需要将kxk的局部信息进行聚合,然后与V相乘,得到Attention之后的结果:
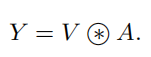
3.2. Contextual Transformer Block
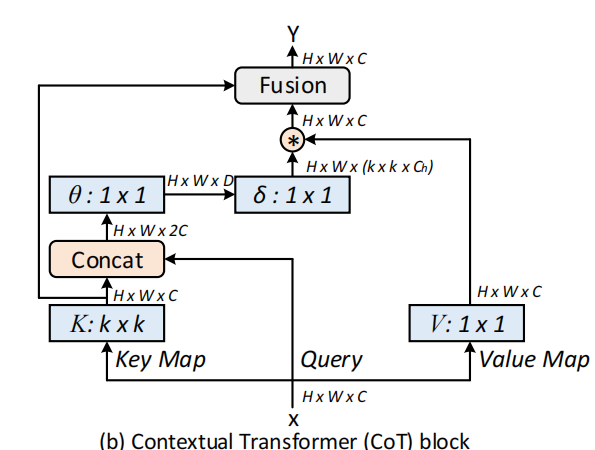
传统的Self-Attention可以很好地触发不同空间位置的特征交互。然而,在传统的Self-Attention机制中,所有的query-key关系都是通过独立的quey-key pair学习的,没有探索两者之间的丰富上下文,这极大的限制了视觉表示学习。
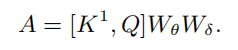
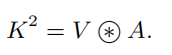
3.3. Contextual Transformer Networks
CoT的设计是一个统一的自我关注的构建块,可以作为ConvNet中标准卷积的替代品。
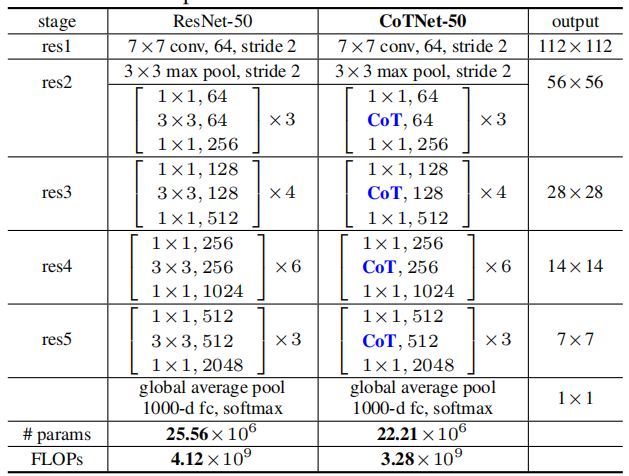
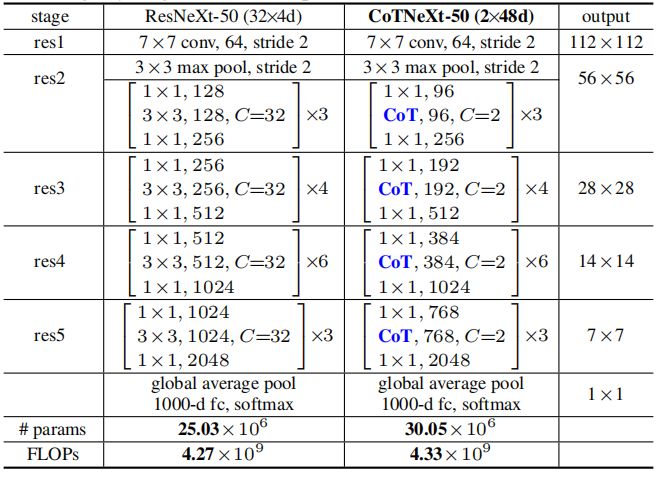
实验
4.1. Image Recognition
4.1.1. Performance
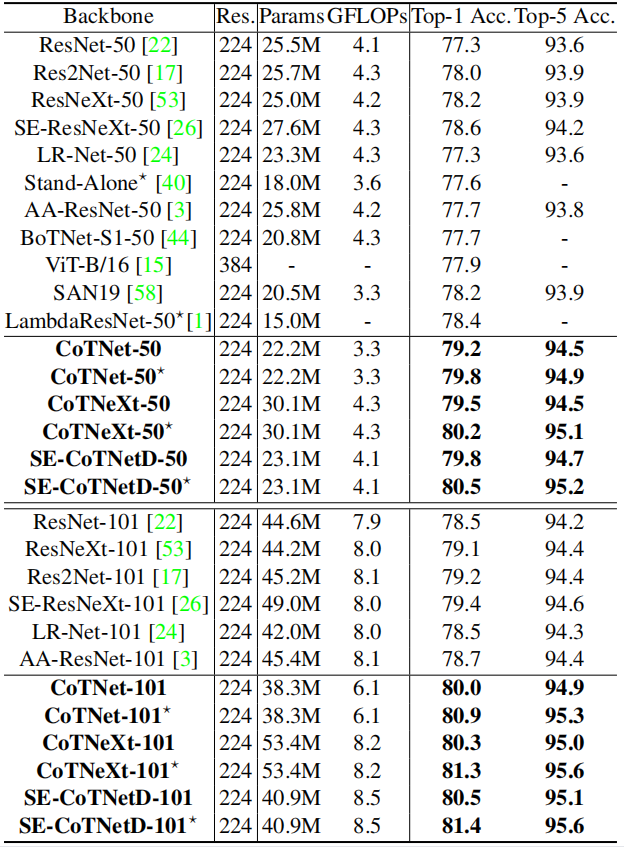
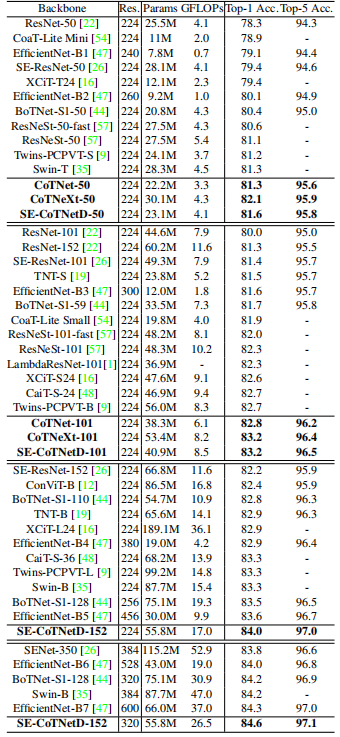
4.1.2. Inference Time vs. Accuracy
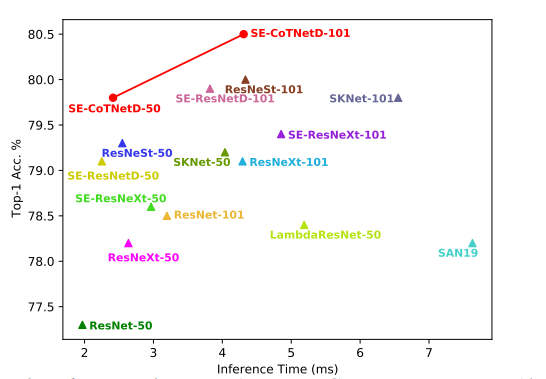
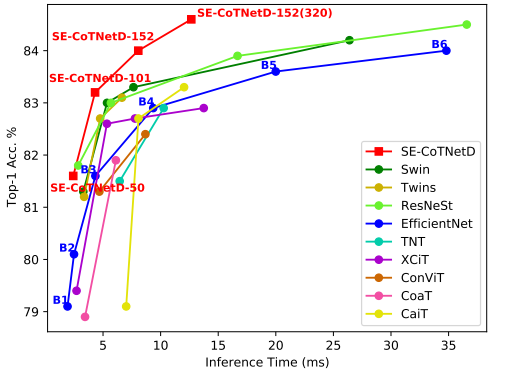
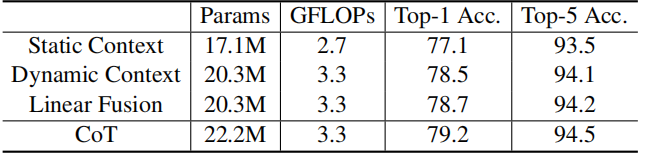
4.1.3. Ablation Study
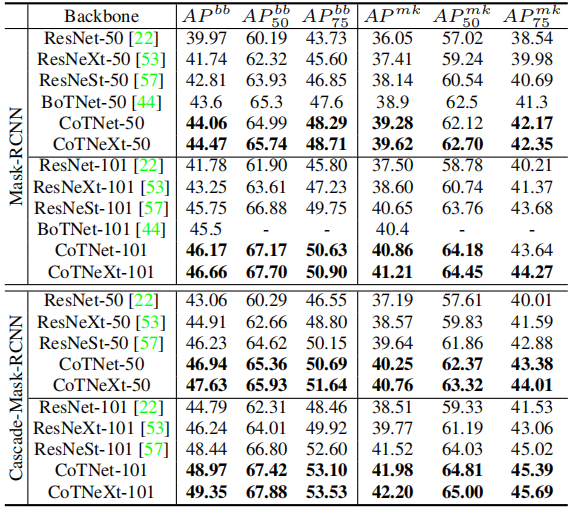
4.2. Object Detection
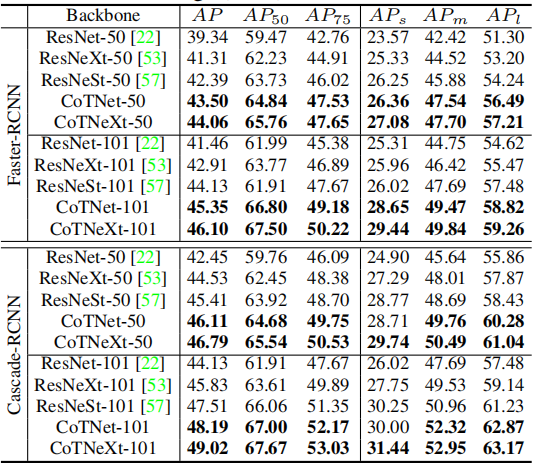
4.3. Instance Segmentation
总结
作者任务传统的Self-Attention在进行计算Attention Map的时候,只考虑了Q和K的关系,而忽略了K内部的上下文信息,因此作者提出了CoT 模块,利用输入key的上下文信息来指导自注意力的学习。
努力分享优质的计算机视觉相关内容,欢迎关注:
个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!

下载3 CVPR2021 在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文
点亮  ,告诉大家你也在看
,告诉大家你也在看

