 极市平台
极市平台





极市导读
训练大模型时,如何优雅地减少 GPU 内存消耗?你不妨试试这个 TorchShard 库,兼具模型并行与数据并行等特点,还具有与 PyTorch 相同的 API 设计。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
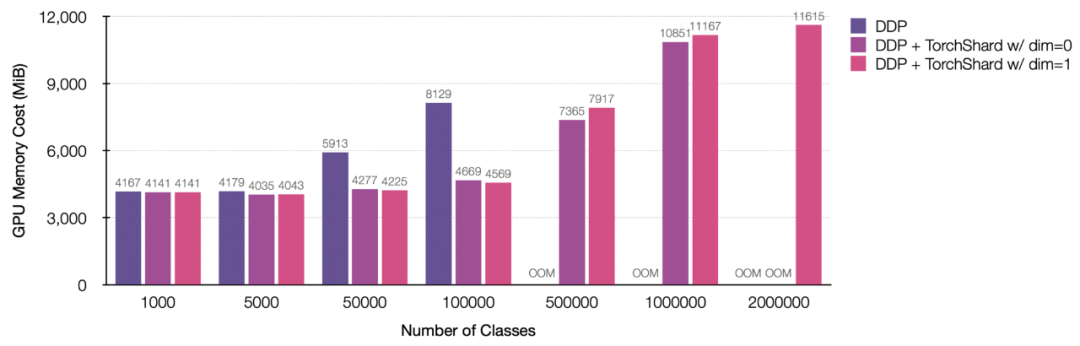
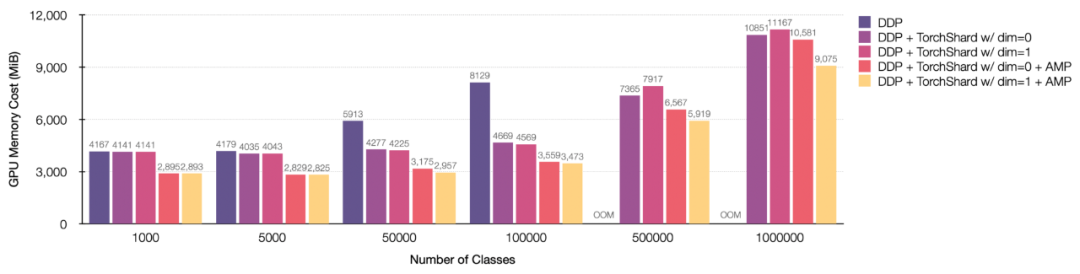
模型并行性能够促进视觉任务的性能。但是目前,还没有一个标准库可以让我们像采用混合精度等其他 SOTA 技术那样轻松地采用模型并行性。
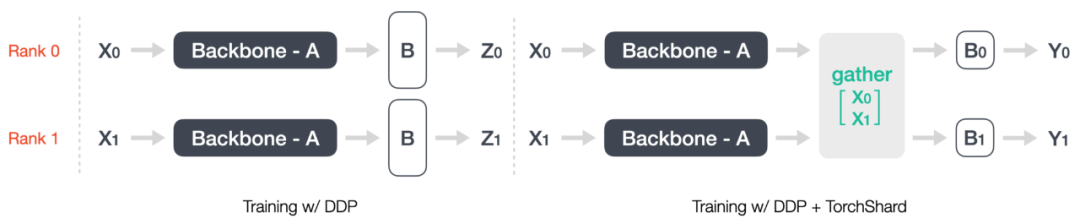
最近,马里兰大学帕克分校计算机科学系的研究者 Kaiyu Yue 开源了一个工具TorchShard,这是一个轻量级的引擎,用于将 PyTorch 张量切片成并行的 shard。当模型拥有大量的线性层(例如 BERT、GPT)或者很多类(数百万)时,TorchShard 可以减少 GPU 内存并扩展训练规模,它具有与 PyTorch 相同的 API 设计。

建立一个标准的 PyTorch 扩展库,用于使用模型并行性进行扩展训练;
以一种简单、自然的方式使用 PyTorch。
import torchshard as tsts.init_process_group(group_size=2) # init parallel groupsm = torch.nn.Sequential(torch.nn.Linear(20, 30, bias=True),ts.nn.ParallelLinear(30, 30, bias=True, dim=None), # equal to nn.Linear()ts.nn.ParallelLinear(30, 30, bias=True, dim=0), # parallel in row dimensionts.nn.ParallelLinear(30, 30, bias=True, dim=1), # parallel in column dimension).cuda()x = m(x) # forwardloss = ts.nn.functional.parallel_cross_entropy(x, y) # parallel loss functionloss.backward() # backwardtorch.save(ts.collect_state_dict(m, m.state_dict()), 'm.pt') # save model state
torchshard 包含必要的功能和操作,如 torch 包;
torchshard.nn 包含图形的基本构建块,如 torch.nn 包;
torchshard.nn.functional 包含 torchshard.nn 的相应功能操作,如 torch.nn.functional 包;
torchshard.distributed 包含处理分布式张量和组的基本功能,如 torch.distributed 包更容易使用。
pip install torchshard
import torchshard as ts
ts.distributed.init_process_group(group_size=args.world_size)
import resnetmodel = resnet.__dict__[args.arch](pretrained=args.pretrained)ts.nn.ParallelLinear.convert_parallel_linear(model, dim=args.model_parallel_dim)print("=> paralleling model'{}'".format(args.arch))
criterion = ts.nn.ParallelCrossEntropyLoss().cuda(args.gpu)
x = ts.distributed.gather(x, dim=0) # gather input along the dim of batch sizex = self.fc(x)
output = model(images)if args.enable_model_parallel:target = ts.distributed.gather(target, dim=0)loss = criterion(output, target)
state_dict = model.state_dict()# collect states across all ranksstate_dict = ts.collect_state_dict(model, state_dict)if ts.distributed.get_rank() == 0:torch.save(state_dict, 'resnet50.pt') # save as before
if ts.distributed.get_rank() == 0:state_dict = torch.load('resnet50.pt')# relocate state_dict() for all ranksstate_dict = ts.relocate_state_dict(model, state_dict)model.load_state_dict(state_dict) # load as before
# gradscalerscaler = torch.cuda.amp.GradScaler(enabled=args.enable_amp_mode)with torch.cuda.amp.autocast(enabled=args.enable_amp_mode): # compute outputoutput = model(images)if args.enable_model_parallel:target = ts.distributed.gather(target, dim=0)loss = criterion(output, target)# compute gradient and do SGD stepscaler.scale(loss).backward()scaler.step(optimizer)scaler.update()optimizer.zero_grad()
from torch.distributed.optim import ZeroRedundancyOptimizerif args.enable_zero_optim:=> using ZeroRedundancyOptimizer')optimizer = torch.distributed.optim.ZeroRedundancyOptimizer(model.parameters(),optimizer_class=torch.optim.SGD,lr=args.lr,momentum=args.momentum,weight_decay=args.weight_decay)else:optimizer = torch.optim.SGD(model.parameters(), args.lr,momentum=args.momentum,weight_decay=args.weight_decay)

如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“ICCV2021”获取最新论文合集~


# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~


