 极市平台
极市平台





极市导读
本文将YOLOX训练的模型转到ncnn进行推理加速。>>加入极市CV技术交流群,走在计算机视觉的最前沿
YOLOX最近刷屏了,关键是官方仓库直接给出了ncnn、tensorRT、openvino、onnxruntime实现,简直是无 比 良 心!!!
0x00 YOLOX目标检测
懂得都懂,异常强大。贴上链接方便大家感受:https://github.com/Megvii-BaseDetection/YOLOX;
以及https://arxiv.org/abs/2107.08430。
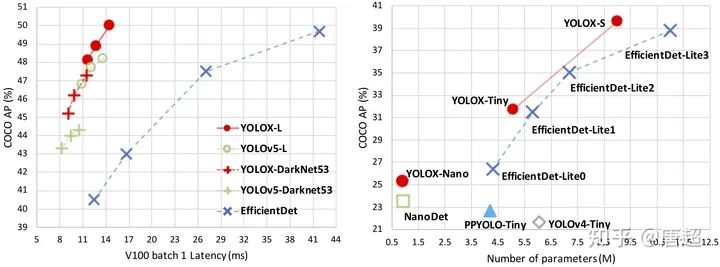
具体算法解析啥的,极市之前有过解读,详见吊打一切现有版本的YOLO!旷视重磅开源YOLOX:新一代目标检测性能速度担当!一文,本文主要是照顾有些人想自己转YOLOX训练的模型到ncnn进行推理加速。
0x01 配置环境
因为只是需要导出原始pytorch模型到onnx,所以机器配置可以随意,不过建议还是用带gpu的设备,跑demo需要用gpu才能行,我尝试改成cpu之后并不能出结果/sad。
git clone git@github.com:Megvii-BaseDetection/YOLOX.git
cd YOLOX
pip3 install -U pip && pip3 install -r requirements.txt
pip3 install -v -e . # or python3 setup.py develop
git clone https://github.com/NVIDIA/apex
cd apex
pip3 install -v --disable-pip-version-check --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" ./
其实跟着官网git上面流程走就行,到目前为止就可以试试demo看看模型效果了。我这里用的是yolox-nano这个模型来做说明。
python tools/demo.py image -n yolox-nano -c /path/to/your/yolox_nano.pth.tar --path assets/dog.jpg --conf 0.3 --nms 0.65 --tsize 640 --save_result
上述命令执行完成之后会打印出以下信息:

检测的结果存储在./YOLOX\_outputs/nano/vis\_res/2021\_07\_21\_15\_54\_30/dog.jpg。具体效果如下图所示:
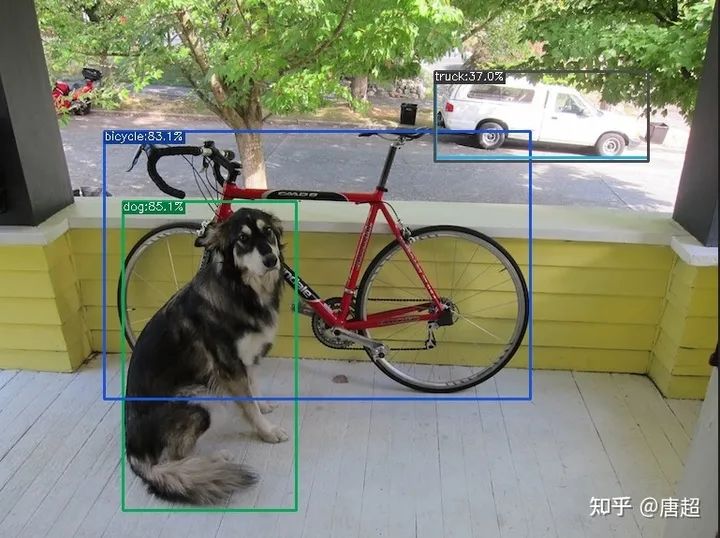
(小声BB,用官方model以及demo程序跑出来还是有一丢丢问题,我也提了issue,不过回答的我并不怎么满意。有兴趣的可以自己去翻......当然了,那个误识别可以设置conf为0.4剔除。)
好了,至此,相当于我们整体环境就整完了,接下来就是导出pytorch模型到onnx,然后再转到ncnn了。
PS:我看issue里好多人在问在哪看结果,我的怎么没结果之类的。。。。如果正确执行完成了,会输出检测结果的存储路径。如果你没看到这个,那么不好意思,可能是你姿势有问题(大概率是模型不对,没有用gpu,cpu是没法跑的,但是它又不报错/sad)
0x02 模型转换
其实吧,pytorch模型导出到onnx这块代码YOLOX已经很贴心的提供了,这样就不需要我们自己倒腾啥后处理屏蔽之类的骚操作了。直接按下面命令运行即可:
#如果你环境中还没安装onnx-simplifier,那么需要安装一个,嫌麻烦不安装也可以,后面给另一个方案
pip install onnx-simplifier
python tools/export_onnx.py -n yolox-nano -c /path/to/your/yolox_nano.pth.tar
这个导出onnx的代码非常贴心,之间把onnx-simplifier也放在里面一起做了,可以一定程度上减少模型里面出现的一些胶水OP,如果你嫌安装这个比较麻烦,也可以用“@大缺弦www.zhihu.com/people/33295f2791c588f9df071dddb701278a”的网页版进行模型转换,这里给出链接:一键转换 Caffe, ONNX, TensorFlow 到 NCNN, MNN, Tengineconvertmodel.com
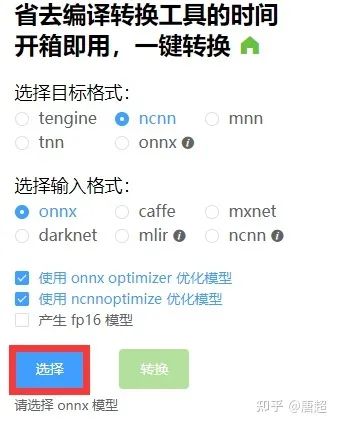
使用非常方便,节约了自己配环境安装的过程(其实主要是有些转换工具编译时需要protobuf支持,但是好多人这里都卡住了)。不过大老师由于太忙了,网页端转换工具有时候并没有更新到最新,所以.....大家还是体谅下吧。
得到由onnx-simplifier的模型之后,就可以开始转换ncnn之旅了!(贴太多图了,模型图就不贴了,大家可以自己用netron打开欣赏)
# ncnn_root代表ncnn根目录
cd /ncnn_root/build/tools/onnx
./onnx2ncnn /path/to/yolox-nano.onnx yolox-nano.param yolox-nano.bin
运行完成之后会出现很多Unsupported slice step,这是focus模块转换的报错,别害怕,up已经帮我们铺好路了。
Unsupported slice step !
Unsupported slice step !
Unsupported slice step !
Unsupported slice step !
Unsupported slice step !
Unsupported slice step !
Unsupported slice step !
Unsupported slice step !
具体怎么写focus可以去看up写的转换yolov5s到ncnn的文章,我这里主要只讲具体操作过程:nihui:详细记录u版YOLOv5目标检测ncnn实现zhuanlan.zhihu.com

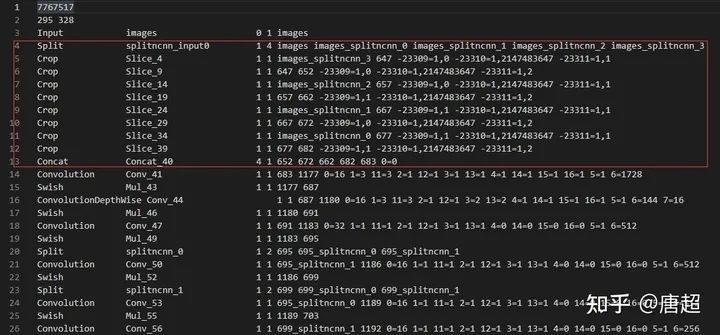
打开上面转换好的yolox-nano.param文件,可以看到如上图所示的样子,红框中的内容实际上就是focus,我们只需要把这里修改下就好了,具体是在第四行插入以下内容:
YoloV5Focus focus 1 1 images 683
然后把原先的4-13行全部删除,这里需要注意的是,1 1 images 683分别代表的意思是一个输入、一个输出、输入blob名称为images、输出blob名称为683。有可能你自己改结构转出来的名字不一样,所以需要对照上面红框来取。images也就是第三行的输出blob name,而683则是第13行Concat的输出blob name,因为这个Concat的输入是4个,输出有一个,也就是652 672 662 682都是输出,而683是输出。这样就把这里修改完成了。
你以为这样就完事了?NO,其实还有个关键的东西没改,那就是param文件的第二行的数字没改,第一个数是layer count,我们删除了一些层,如果还是按照这个走后面载入模型会报错。这里给个简单的修改方法(免得你要自己记删除了多少增加了多少......),直接看param整体行数,然后减去开头的两行就行了,我们这里改成focus之后需要把layer count改成286,而至于第二个数,代表的是blob count,这个可以多,但是别少就行了!因为我们之后还有个很重要的操作,可以把这里的数量改对。
接下来可以用ncnnoptimize对模型进行优化,顺便转为 fp16 存储减小模型体积
./ncnnoptimize ./onnx/yolox-nano-sim.param ./onnx/yolox-nano-sim.bin yolox-nano-sim.param yolox-nano-sim.bin 65536
前面两个参数是优化前的模型,后面两个是优化后的模型。
create_custom_layer YoloV5Focus
fuse_convolution_activation Conv_314 Sigmoid_330
fuse_convolution_activation Conv_328 Sigmoid_329
fuse_convolution_activation Conv_347 Sigmoid_363
fuse_convolution_activation Conv_361 Sigmoid_362
fuse_convolution_activation Conv_380 Sigmoid_396
fuse_convolution_activation Conv_394 Sigmoid_395
model has custom layer, shape_inference skipped
model has custom layer, estimate_memory_footprint skipped
0x03 run起来
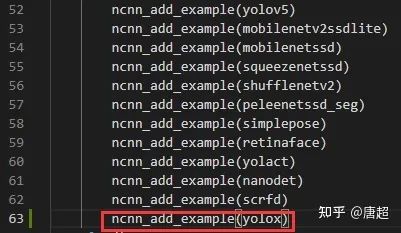
模型转换完成之后,运行起来就比较简单了(主要是YOLOX自己提供了ncnn的代码),为看简单起见,咱们直接把yolox.cpp文件挪到ncnn工程的examples目录下,然后在/ncnn\_root/examples/CMakeLists.txt中做如图修改:
接下来就是正常的编译环节了,另外,由于yolox.cpp中模型路径是写的绝对路径,大家可以根据自己的情况去做更改。
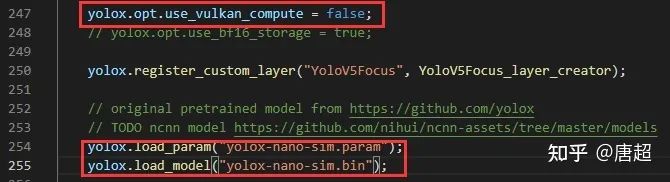
上图中第一个红框因为我只是跑流程,没有编译vulkan,所以把这个关掉了,大家根据自己的来,第二个位置就是把模型改成自己的模型路径。
./yolox /path/to/YOLOX/assets/dog.jpg
(反正已经是保姆级别了,就再提一下,因为模型是传的相对路径,对于上图而言,你需要将可执行程序和模型放到同级目录才能正常运行。或者你直接给绝对路径也行)
最后附上ncnn的结果(有彩蛋,大概算吧).

啊,彩蛋就是ncnn没有出现那个误检的框......参数配置都是一样,conf0.3,nms0.65, size 416。官方说法是nms实现不一样,咱也没看,后面再细究吧,反正本文不是为了讲技术实现(主要是菜)。
0x04 总结
其实没啥好总结的,很多工作大家都已经做好了,我只是搬运然后写细致了一点,只希望能够帮助到有些刚入门或者对这块感兴趣的人吧。
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“ICCV2021”获取最新论文合集~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~


