 极市平台
极市平台





极市导读
复旦大学计算机科学技术学院邱锡鹏教授团队对种类繁多的 X-former 进行了综述。本文对该文进行的详细编译和解读。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

论文链接:https://arxiv.org/pdf/2106.04554.pdf
这是复旦大学出品的一份Transformer的综述,里面涵盖内容很广泛,长文预警,完整读完可能需要15-20分钟
介绍
Transformer现在是一种在各个领域被广泛使用的模型,包括NLP,CV,语音领域。随着这几年发展,一些Transformer的变体在以下几个方面进行改进:
1. 模型效率
由于self-attention模块的计算,存储复杂度都很高,让Transformer在处理长序列数据时效率较低。主要的解决方法是对Attention做轻量化以及引入分治思想。
2. 模型泛化
Transformer没有像CNN引入归纳偏置,导致其在小规模数据集上难以训练。解决方法是引入结构偏置或正则项,在大数据集上进行预训练等等。
3. 模型适应能力
这方面工作主要是将Transformer引入下游任务中
背景知识
原始Transformer
这部分我们主要介绍原始Transformer中几个关键模块
Attention模块
Attention公式原型如下:
而Transformer中使用的是多头注意力机制,首先使用多组来分别计算,然后将多组注意力结果拼接起来,并最后再和做一次线性变换。整个过程如下:
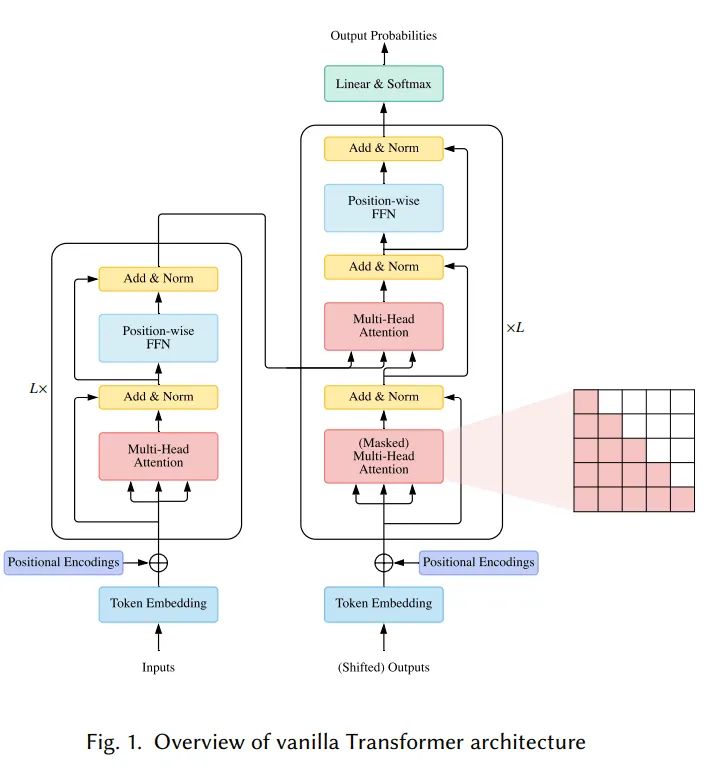
在Transformer中,分以下三种Attention:
self-attention,自注意力机制,即上述公式中的Q,K,V都设置为输入X。 Masked self-attention: 用于decoder中,其中掩码保证计算注意力的时候只使用该位置以内的信息。 Cross-Attention: 其中Query使用的是解码器的输出,而Key和Value使用的是编码器输出。
FFN模块
前馈层就是两层全连接层加一个激活层,可以写为
残差连接和LayerNorm
在每个Transformer Block中,都加入了残差连接和LayerNorm。整个过程可以写为
位置编码
由于Transformer没有引入循环结构以及卷积结构,模型本身是缺失位置信息的。我们通过给Encoder和Decoder的输入加入位置编码,让数据带有一定位置信息
模型使用方法
通常有以下三种
Encoder-Decoder 常用于Sequence to Sequence的建模(如机器翻译) Encoder-Only 只用了前面的编码器,常用于分类,序列标注问题 Decoder-Only 只用了后面的解码器,常用于序列生成任务
模型分析
这里主要分析其中两个组件FFN和self-attention的复杂度和参数量 这里我们假设序列长度为T,通道数为D,FFN中间全连接层大小为4D,那么有以下表格

简单推导
我们以self-attention为例子,其中self-attention需要三个矩阵 ,进而将输入X投影得到Q,K,V。而这三个矩阵大小都是DxD(因为输入维度是D,输出维度也是D),而最后计算完注意力后,还需要经过一个线性层,其矩阵大小也为DxD,因此参数量就是
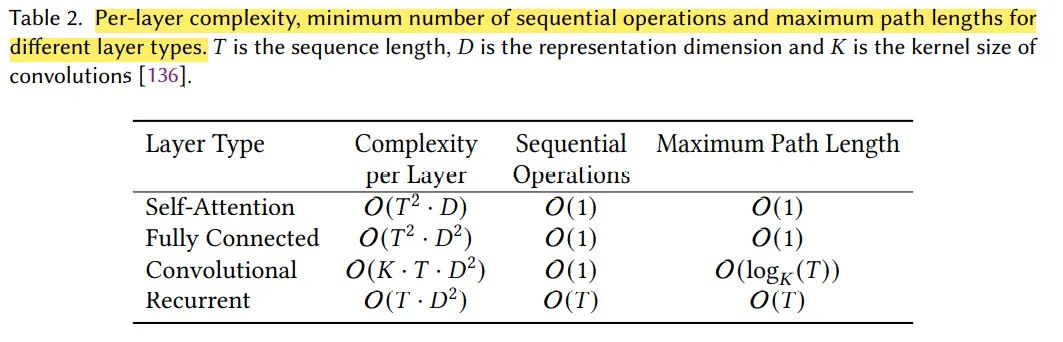
矩阵乘计算复杂度补充,假设矩阵A是(N, M),矩阵B是(M, P), 那么得到的矩阵C是(N, P),而每一个元素计算需要M次乘法,因此复杂度为O(NMP),其他操作对比可参考 Transformer/CNN/RNN的对比(时间复杂度,序列操作数,最大路径长度)(https://zhuanlan.zhihu.com/p/264749298)
在Q和K进行矩阵乘的时候,是(T, C)和(C, T)(K转置后)矩阵相乘,因此复杂度为,FFN的参数量和计算复杂度也以此类推。可以看到在长序列下,self-attention的操作复杂度以2次方增加。
Transformer与其他网络的比较
self-attention的分析
我们总结了以下三个优点
它与全连接层有相同的最大路径长度,适合长距离建模。 相比卷积有限的感受野(在CNN中,需要堆叠很多层才能得到全局感受野),self-attention能以有限的层数建模长期依赖关系。 相比于循环层(RNN系列),self-attention的并行度更高。
关于归纳偏置
CNN使用卷积核,引入图像局部性。RNN将时间不变性引入。而Transformer抛弃了这些归纳偏置,一方面能让其足够通用灵活,另一方面Transformer很容易对小规模数据过拟合。另一个与其相关的是GNN图网络,Transformer可以被看作一个完全有向图(带自环)上的GNN,其中每个输入都是图中的一个节点(PS: 笔者对GNN不理解,这里翻译比较僵硬)。
不同种类的Transformer
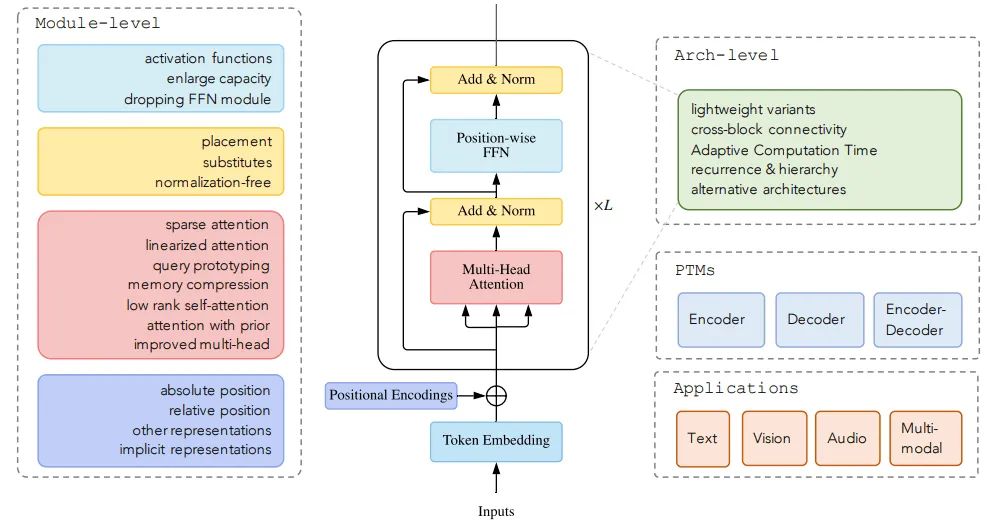 后续的Transformer变体都是在以上几个组件加以改进得到。
后续的Transformer变体都是在以上几个组件加以改进得到。
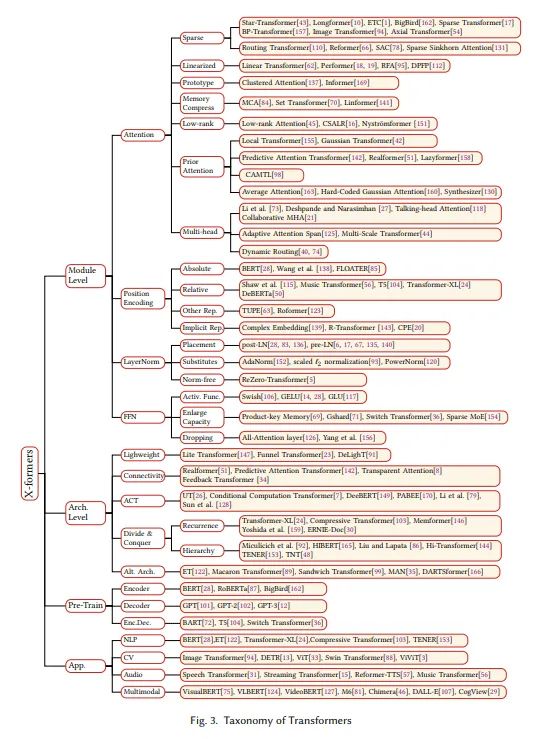
Attention
自注意力机制是很重要的一个组件,它有如下两个问题
复杂度,在处理长序列的时候计算开销很大 结构先验,抛弃了所有归纳偏置,导致其在小型数据容易过拟合
解决方法有以下:
Sparse Attention,将稀疏偏置引入到注意力计算 Linearized Attention,将注意力矩阵和特征映射分离,降低至线性复杂度 显存压缩,减少QKV的数量来减小注意力矩阵 低秩self Attention,这类工作主要是抓住自注意力的低秩性 带有先验的Attention,使用预先注意力分配来补充标准的自注意力机制 改进Multi-head机制
Sparse Attention
在一些训练好的Transformer模型中,可以观察到注意力矩阵通常是稀疏的,因此可以通过限制query-key对的数量来减少计算复杂度。我们可以将稀疏化方法进一步分成两类,基于位置信息Position-based和基于内容Content-based两种方法。
基于位置信息的稀疏化注意力
基础的稀疏注意力模式
主要来说有以下五种稀疏注意力的基本模式
Global Attention 为了增强模型模拟长距离依赖关系,我们可以加入一些全局节点。 Band Attention 大部分数据都带有局部性,我们限制query只与相邻的几个节点进行交互 Dilated Attention 跟CNN中的Dilated Conv类似,通过增加空隙以获取更大的感受野 Random Attention 通过随机采样,提升非局部的交互 Block Local Attention 使用多个不重叠的Block来限制信息交互
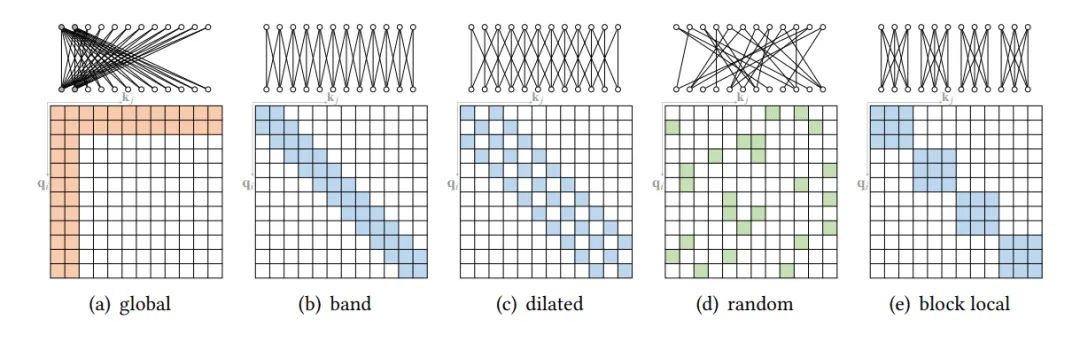
复合的稀疏注意力模式
使用上面的基础稀疏注意力模式进行结合,这里就不展开叙述了。
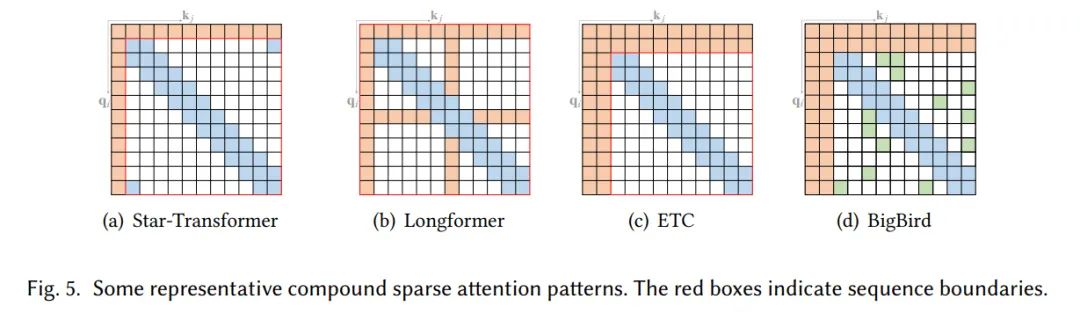
扩展的稀疏注意力模式
不同于上面基础的几种注意力模式,针对一些特殊数据类型也有一些扩展的稀疏注意力。BP-Transformer构造了一个基于二叉树的注意力模式,所有的token作为叶子节点,而内部节点则包含了多个token。更高层的span node能包含更长距离内的token。在视觉方面的数据上,Image Transformer尝试了两种稀疏注意力模式
将图像展平,并应用一个block local sparse attention 以2维的形式,应用一个2D block local attention
Axial Transformer对于图像的每个轴,应用独立的注意力模块
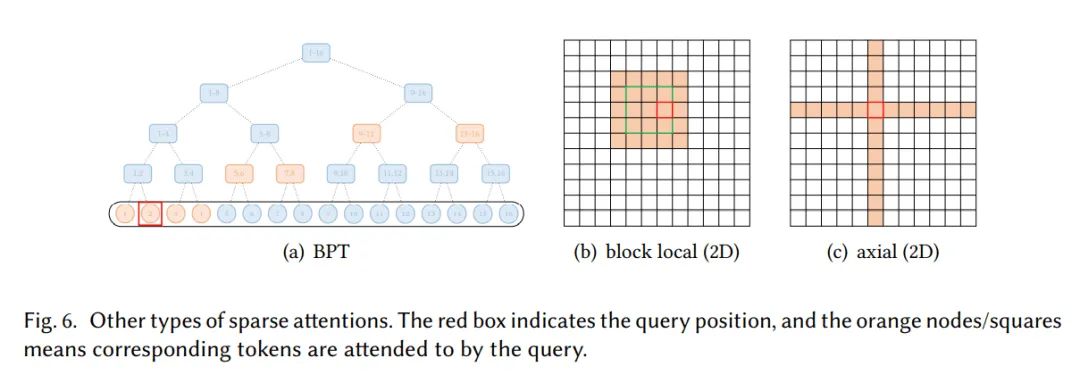
基于内容的稀疏注意力
一些工作是根据输入数据来创建稀疏注意力,其中一种很简单的方法是选择和给定query有很高相似度的key。Routing Transformer采用K-means聚类方法,对中心向量集合上的key和query进行聚类。每个query只与其处在相同cluster下的key进行交互。
中心向量采用滑动平均的方法进行更新:
Reformer则采用local-sensitive hashing(LSH)哈希方法来为每个query选择key-value。其主要思想是对query和key哈希,分到多个桶内,在同一个桶内的query,key参与交互。
设b为桶的个数,给定一个大小为的矩阵,LSH可写为
此外,Sparse Adaptive Connection将序列看作是一个图,自适应学习稀疏连接。Sparse Sinkhorn Attention使用一个排序网络,给query,key分到多个块内,并给每个query块分配一个key块,每个query只允许和对应的key进行交互。
Linearized Attention
这类方法主要是使用 来近似或替代计算Attention中的 , 以降低计算复杂度至 (其中 是在行方向上的特征映射)

我们先写出Attention的一般形式:
其中 sim 是一个用于计算向量相似性的函数。在原始Transformer是对向量做内积+softmax,我们选择用一个核函数来代替
那么前面的Attention可以改写为
这类方法有两个关键的组件,分别是特征映射和特征聚合方法
特征映射
即前面提到的 , Linear Transformer使用的是 , 其目的不是近似标准 Attention中的点积, 只是性能能与标准Transformer相当。
在第一个版本中,Performer受启发于随机傅里叶特征映射(常用于近似高斯核)。其中:
l = 2 f1 = sin, f2=cos
然而第一个版本不能保证attention计算得到的score是非负的,第二版改进为:
l = 1 f1 = exp
当然还有其他特征映射方法,这里不过多阐述
聚合方法
在前面的公式中, 通过简单的求和进行特征聚合。
RFA引入一种门机制,当给记忆矩阵S添加一个新关联,它通过一个可学习的标量g来让历史关联呈现出指数衰减的形式。
Schlag等人利用写入/删除的方法来增加记忆矩阵容量(这里看不懂,不展开讲了)
Query原型和显存压缩
除了对注意力稀疏化和线性化,另外一个减少注意力复杂度的方法是减少query或key-value的数量。
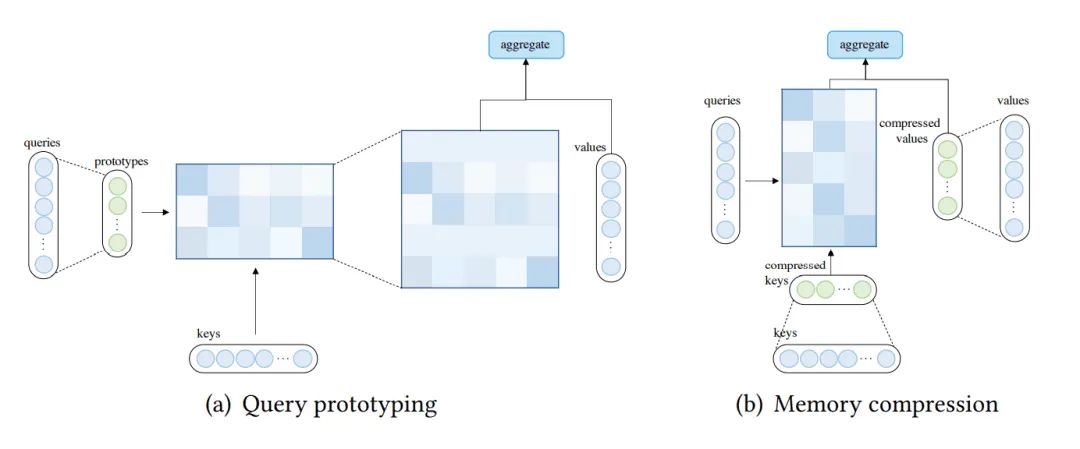
使用Query原型的Attention
这里使用Query原型作为计算Attention分布的主要来源,模型可以将分布复制到对应query的位置,也可以用离散均匀分布来填充。
Cluster Attention将query分组到多个cluster当中,为每个cluster的中心向量计算注意力分布。
Informer则是显式地使用query稀疏度度量选取query原型,该度量由query注意力分布和离散均匀分布之间的KL散度近似推导出来。
使用压缩Key-Value显存的注意力
这类方法减少key-value对的数量,来减少复杂度。
Liu等人提出MCA,使用卷积层减少key-value数量
Set Transformer和Luna使用一些外部可训练全局节点,来对输入进行压缩
Linformer则将key,values投影(即和一个矩阵相乘),减少其长度。
Poolingformer则使用两阶段Attention,包含一个滑窗Attention和一个压缩显存Attention。
低秩自注意力
相关研究者发现自注意力矩阵大多是低秩的,进而引申出两种方法:
使用参数化方法显式建模 使用低秩近似自注意力矩阵
低秩参数化
事实上注意力矩阵的秩是小于序列长度的,而序列特别短的时候,会造成over-parameterization,甚至过拟合。
Guo等人使用一个低秩注意力模块建模长距离依赖和一个band attention来捕获局部依赖,来代替原始注意力矩阵。
低秩近似
Performer使用随机傅里叶映射来去近似高斯核函数。
Nyström method对输入使用平均池化进行降采样,选取m个landmark节点,
记 和 为landamark query和key, 近似的注意力矩阵可以按如下所示计算:
先验注意力
先验注意力分布可以补充或替代注意力矩阵
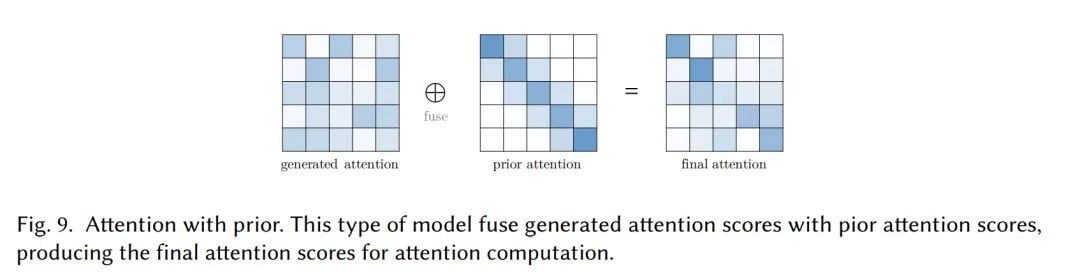
模型局部先验注意力
一些特定的数据类型(如文本)对位置有强烈偏好,我们可以根据这种特性来设计先验注意力。
Gaussian Transformer认为句子中的词符合距离正态分布(离中心词越近则越重要),于是给注意力矩阵加入了高斯先验。
从底层模块获取先验
相关研究者观察到相邻几层的注意力分布是相似的,很自然想到使用前面层的注意力矩阵参与当前层注意力的运算
Predictive Transformer则对先前的attention score进行二维卷积 并加入到当前层运算,可以写为
Realformer则是将先前的attention score直接加到当前层
Lazyformer则是在相邻层内共享一个注意力矩阵
多任务适配先验
(这段也不是很懂)
通过在预训练网路的特定位置添加适配器,进而实现跨任务参数共享
只使用先验的注意力
Zhang等人使用一个离散正态分布作为注意力来源
You等人使用高斯分布作为注意力分布
Synthesizer使用了一个随机初始化的可学习Attention矩阵,只用query参与计算最终attention scores。
提升多头注意力机制
头部行为建模
这部分引入了更复杂的机制来引导不同注意力头的行为,并让不同注意力头进行交互
Li等人在损失函数引入正则项以增加注意力头的多样性
Talking-head Attention使用talking head机制, 到 头生成注意力分数,进行softmax, 并从 来实现value聚合。(也不是很懂这部分工作)
Collaborative Multi-head Attention则对所有注意力头共享使用矩阵 和 , 并用一个混合 向量为第i个注意力头来过滤参数,公式如下:
跨度受限的多头注意力
原始的多头注意力机制是全跨度的,即一个query能和所有key-value对参与运算。但相关研究者观察到一些注意力头只关注局部信息,而一些其他注意力头关注更广的上下文信息。因此对跨度的改进有以下两个方向:
Locality 限制attention的跨度能引入局部性 Efficiency 在合理实现下,一些模型可以扩展到长序列,且不会引入额外显存和计算
Sukhbaatar采取一个可学习的attention span(如下图b),即使用一个可学习的标量z和一个超参数R来生成mask(进而控制跨度),实验中观察到较低的网络层有着更小的学习跨度,较高的网络跨度更大。
Multi-Scale Transformer采用了固定的跨度,但在不同层的不同头中,设定了不同跨度。

Refined聚合机制的多头注意力
原始的多头注意力机制是先将每个头的结果concat拼接到一起,然后经过一个全连接层 。
这种做法可以等价于重参数化注意力输出并求和,我们可以先把最后的全连接层分组为
多头注意力机制可以重写为
也有人认为这种聚合机制过于简单,并对此进行改进。Gu和Feng等人使用了胶囊网络,将注意力头输出作为胶囊的输入,而经过迭代路由后得到输出胶囊,最终这些输出胶囊被拼接在一起得到最后多头注意力的输出。
其他的一些改进
Shazeer提出了multi-query attention,所有的注意力头共享key-value对,能进一步提升解码速度。
Bhojanapalli等人将注意力头的大小和注意力头的个数解耦开来(即没有采用原始多头注意力的做法),而将注意力头大小设置为。
其他模块级别的修改
位置表达
我们知道卷积和循环神经网络不是排列不变(permutation equivariant)的,然而Transformer中的注意力机制和FFN层都是排列不变的,所以我们需要引入位置信息。
绝对位置编码
在原始的Transformer中采取的是绝对正弦位置编码
另外一种方法是采用一个可学习的Embedding层,来添加位置信息。
Wang等人提出使用正弦位置编码, 但是每个频率 是学习得到。
相对位置编码
这种方法主要关注的是token之间的关系(绝对位置编码则是把token都考虑为独立的一个个体)。
Shaw等人将可学习的相对位置编码Emebedding加入到注意力机制中的key,公式如下:
Transformer-XL重新设计attention score计算方式,并引入正弦编码
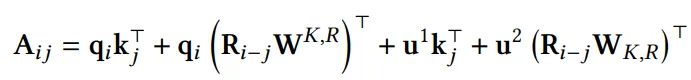
其中 是可学习变量, 而 则是正弦编码矩阵
DeBERT使用了位置编码Embedding,并且采用类似Transformer-XL的计算注意力方式
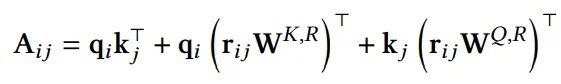
其他位置表示方式
TUPE重新设计计算注意力方式,并且引入一个bias来表征位置信息
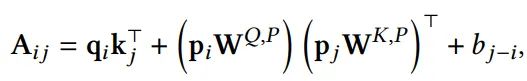
Roformer使用的是旋转位置编码,通过向量的旋转来表示相对位置
这里强力推荐苏剑林老师的博客,Roformer位置编码可参考 Transformer升级之路:2、博采众长的旋转式位置编码(https://zhuanlan.zhihu.com/p/359502624)
没有采取显式编码的位置表示
R-Transformer每一个块里,首先输入到一个RNN中,再进入到注意力模块。RNN能给输入信息带上位置信息。
CPE使用了卷积层来引入位置信息
Decoder中的位置表示
Decoder中的masked self-attention并不是排列不变的,也有研究者发现移除了decoder部分的位置编码能够提升模型性能
Layer Normalization
LN放置的位置
在原始的Transformer中,Layer Normalization放置在中间,我们称为post-LN,后续也有人把LN放到前面,称为pre-LN,具体差别如下图所示
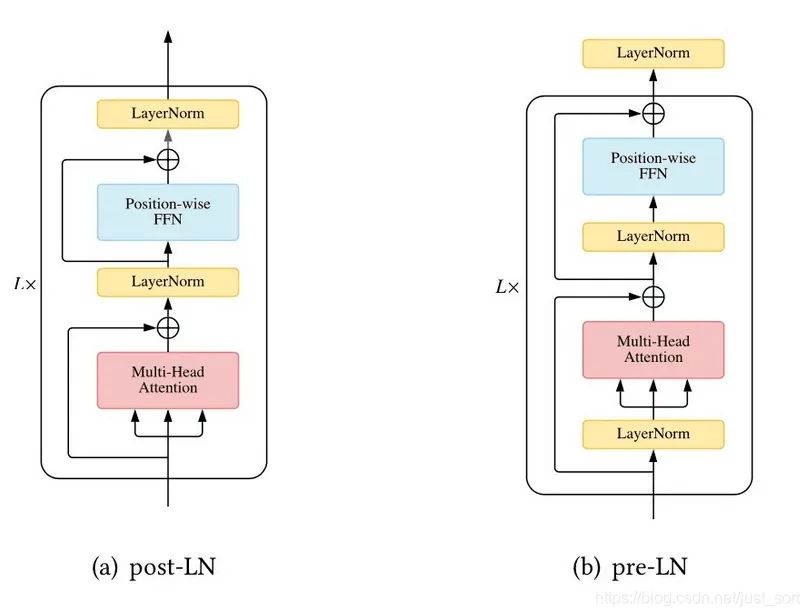
Xiong等人分析得到在post-LN下,输出层的梯度比较大,这也导致使用post-LN的Transformer如果不采用学习率warm-up策略,会出现训练不稳定现象。
尽管post-LN可能导致训练不稳定,它其性能通常比pre-LN要好。Liu等人发现post-LN并不受梯度不均匀的影响,训练不稳定的原因是训练初期,残差连接会导致输出产生较大的偏移。他提出模型自适应初始化,控制了残差分支的贡献度,保证训练的平稳性。
可参考作者本人知乎的回答 如何看待 EMNLP 2020 录用结果?有哪些亮眼的成果?(https://www.zhihu.com/people/liyuan-liu-64)
LN的一些替代品
Xu等人观察到LN中大部分可学习参数不起作用,并且会增加模型过拟合的风险,提出了一种不依赖可学习参数的归一化方法AdaNorm
其中 是超参数
Nguyen和Salazar提出用L2范数来替代
其中g是一个可学习标量
Shen等人探讨了BN在Transformer上表现不好的原因,并提出PowerNorm,作出如下改进:
松弛了0均值的限制 使用平方平均替代了方差 对平方平均值采用了 running statistic方式,而不是使用每个batch内的统计信息
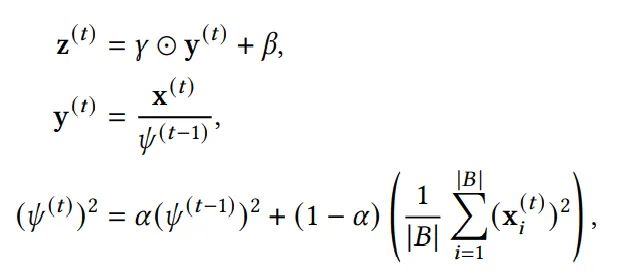
无Normalization的Transformer
ReZero使用了一个可学习残差分支来代替LN, 公式如下
其中 设置为一个可学习参数,并初始化为0
关于Rezero这篇文章,我推荐阅读下香侬科技的解读香侬读 | ReZero: 使用加权残差连接加速深度模型收敛(https://zhuanlan.zhihu.com/p/113384612)
Point-wise前馈层
FFN同样也是很重要的一个组件,相关研究也基于这个模块进行改进
激活函数
原始的Transformer采用的是ReLU激活函数,后续有以下改进:
Ramachandran使用swish激活函数替代 GPT中使用了GELU Shazeer等人使用了GLU(Gated Linear Unit)
获取更大容量的FFN
一些工作着重于拓展FFN,以获得更大的模型容量Lample等人使用product-key memory layers来代替部分FFN,输入经过query network投影到隐空间,然后采取两组sub-key,构成一个笛卡尔积product keys,生成的q和key比较,检索,得到K个key,然后与value做加权和。
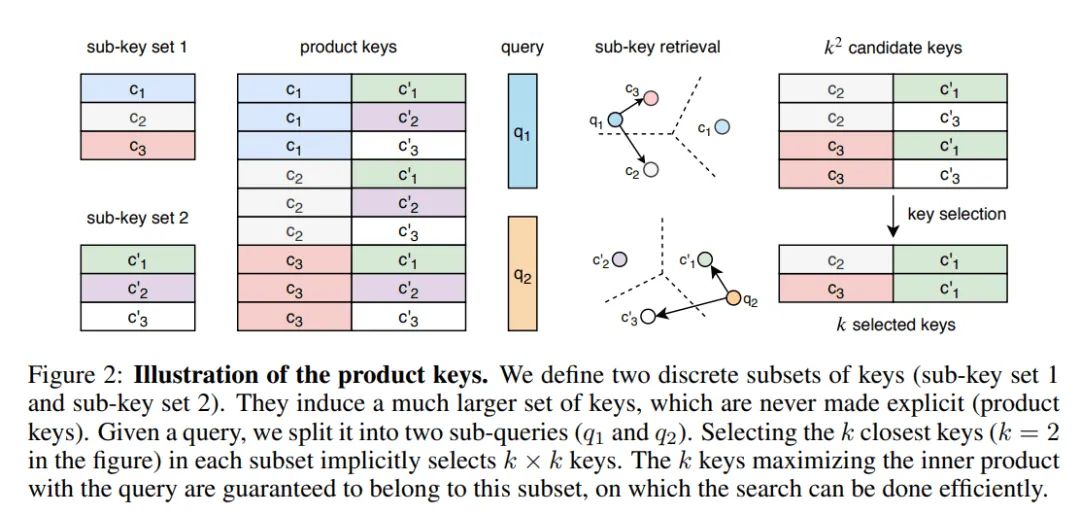
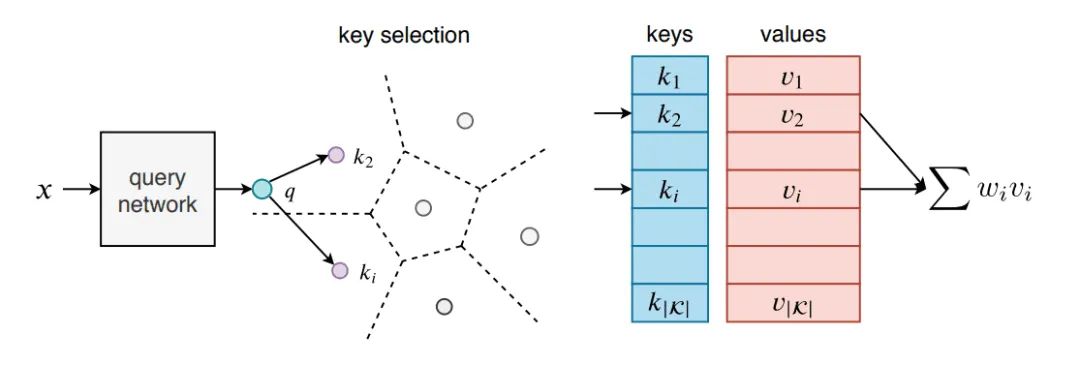
关于这篇文章,我推荐这篇解读large memory layer(https://zhuanlan.zhihu.com/p/76501184)
Gshard则采用MoE(Mixture of Experts)来代替FFN,每个MoE有多个FFN层,MoE的输出则是FFN的加权和,门控值使用一个路由函数g计算得到。MoE每次前向传播,只有门限值在topK内的专家(即对应的FFN)被激活,参与最终运算。
MoE解读推荐GShard论文笔记(1)-MoE结构(https://zhuanlan.zhihu.com/p/344344373)
Switch Transformer和每次选取kge专家的MoE不同,其每次只使用有最大门限值的专家。Yang等人将专家进行分组,在每个组里选取top1的专家参与运算。
丢弃FFN
Sukhbaatar等人将FFN的ReLU替换成softmax,并且将FFN中的bias丢弃,将FFN转换为注意力模块
Yang等人发现在Decoder部分,可以安全地丢掉FFN,不会损失过多地性能,同时能提升训练,推理速度。
架构级别的变体
轻量化Transformer
LiteTransformer将原始Attention分为两个分支,一个分支继续采用attention机制捕捉长距离上下文,另一个分支使用depthwise卷积捕捉局部信息
Funnel Transformer引入池化操作减少序列长度,随后使用上采样恢复序列
DelighT替换了原始的Block,具体改进为:
使用了先expand后reduce的DeLighT变换 使用单头注意力 使用了先reduce后expand的FFN
增强跨网络块的连接
在前面有介绍过Realformer和Predictive Attention Transformer,通过引入额外路径,增强信息流动
在一些encoder-decoder模型中,decoder中的cross-attention模块只用了最后一个解码器的输出。Transparent Attention则改进为encoder层的加权和。
Feedback Transformer引入了一个Feedback机制,对所有层做一个加权和,来聚合历史信息
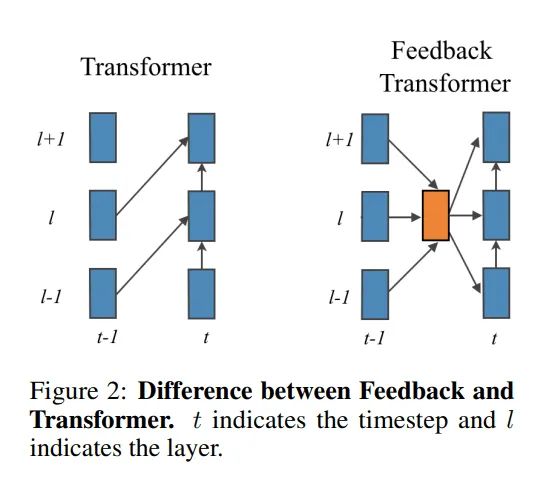
自适应调整计算时间(Adaptive Computation Time)
将自适应调整计算时间引入Transforer有以下好处:
难样本的特征调整,对于一些难以处理的数据,可以送入更深的层,以获得更好的特征表达。 提高简单样本的效率,对于简单样本,浅层的表示足以完成任务。
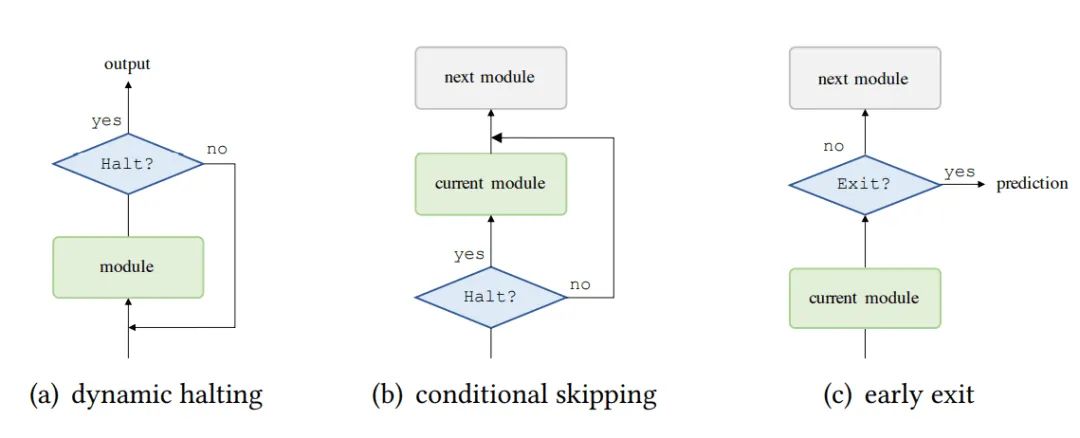
Universal Transformer使用了一种循环机制来调整特征表达,如图a所示。
Conditional Computation Transformer加入一个门控模块,来决定是否跳过当前层,如图b所示
也有一部分工作如DeeBERT,PABEE引入早退机制,如图c所示
使用分治策略的Transformer
将序列分割为多个子序列来处理,能够提升Transformer的效率,主要分为两大类方法,一种是循环Transformer,一种是层级Transformer
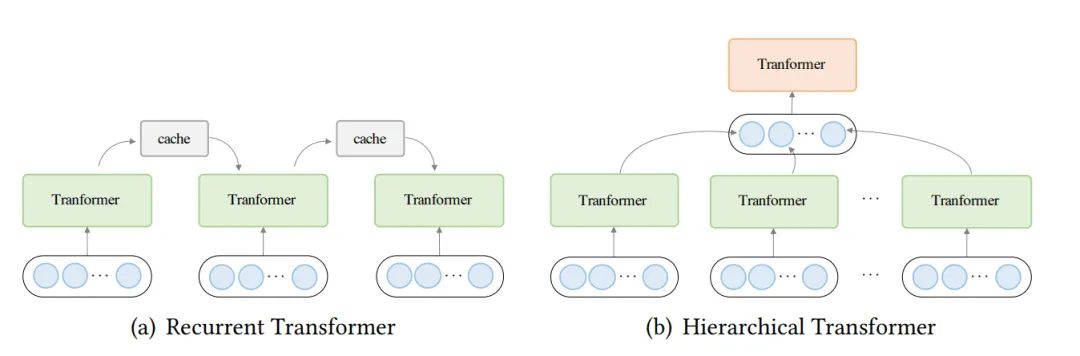
循环Transformer
类似于RNN,循环Transformer设置了一个cache来存储历史信息,每次处理一段子序列,网络会将cache作为额外输入进行运算,运算完后写入新的cache。如上图a所示。
Transformer XL则重用了前面片段的cache, 进而生成K, 。对于第 层和 个片段
其中SG表示停止梯度更新,o表示拼接操作
Compressive Transformer将cache拓展成两个层级的memory,引入一些压缩操作,来减少反向传播更新的时间。
Memformer则将循环机制引入encoder-decoder结构(前面几种针对的是decoder-only结构),给encoder加入memory cross attention。还有一些其他方法这里不过多赘述。
层级Transformer
低层特征送入encoder,将输出特征聚合得到高层特征,并由高层Transformer处理,这种方法有两个好处:
能够在有限的资源处理长序列 能够产生更丰富的特征表达
这里涉及的比较杂,感兴趣的可以翻原论文6.4.2
探索替代架构
Lu等人设计了Macaron Tranasoformer,使用FFN-attention-FFN来替代原始Transformer Block
Sandwich Transformer调整了attention和FFN的位置,将attention置于地层,FFN置于高层
Mask Attention Network引入了动态掩码注意力机制,掩码由token的表征,相对距离和所属头的索引生成。
还有一些使用NAS搜索得到的架构,如Evolved Transformer,DARTSformer等。
预训练Transformer
主要分为三个方向
Encoder:代表的有Bert,使用了掩码语言建模和 Next sentence prediction(NSP)来作为自监督训练目标。RoBERTa则在此基础上删除了NSP ,因为发现NSP会降低下游任务的性能。Decoder:代表的有GPT系列。 Encoder-decoder: BART在BERT基础上引入去噪目标。Encoder-Decoder的结构能让模型拥有语言理解和生成的能力。
Transformer应用领域
NLP:这里不多废话 CV:最近大火的视觉Transformer 音频应用:语音识别,合成,增强;音乐生成 多模态
总结和未来展望
我们认为未来发展方向有以下三大方面:
理论分析:相比CNN和RNN,Transformer更适合在大数据上训练,相对而言性能也会更好,然而原因还不详,需要理论支持。 超越注意力的更好的全局交互机制 多模态数据统一框架
最后希望这篇综述能让你了解当前Transformer的进展,帮助读者们为其他应用改进Transformer。
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“ICCV2021”获取最新论文合集~


# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~


