
在所有Spark模块中,我愿称SparkSQL为最强!
共 11139字,需浏览 23分钟
· 2021-07-27
点击上方蓝色字体,选择“设为星标”
回复”面试“获取更多惊喜

我们之前已经学习过了《我们在学习Spark的时候,到底在学习什么?》,这其中有一个关于SQL的重要模块:SparkSQL。
在实际的开发过程中,SQL化已经是数据领域的共识,大家疯狂的将大数据框架的易用性做到了最高,即使一个刚刚毕业的同学,只要有SQL基础就可以看懂甚至上手开发了。
那么我们有必要对SparkSQL这个模块进行一个全面的解析。我之前也写过一篇文章可以参考:《Spark SQL重点知识总结》。
SparkSQL的前世今生
Spark SQL的前身是Shark,它发布时Hive可以说是SQL on Hadoop的唯一选择(Hive负责将SQL编译成可扩展的MapReduce作业),鉴于Hive的性能以及与Spark的兼容,Shark由此而生。Shark即Hive on Spark,本质上是通过Hive的HQL进行解析,把HQL翻译成Spark上对应的RDD操作,然后通过Hive的Metadata获取数据库里表的信息,实际为HDFS上的数据和文件,最后有Shark获取并放到Spark上计算。
但是Shark框架更多是对Hive的改造,替换了Hive的物理执行引擎,使之有一个较快的处理速度。然而不容忽视的是Shark继承了大量的Hive代码,因此给优化和维护带来大量的麻烦。为了更好的发展,Databricks在2014年7月1日Spark Summit上宣布终止对Shark的开发,将重点放到SparkSQL模块上。
Spark官网给SparkSQL做了定义:
Spark SQL is Apache Spark's module for working with structured data.
由此可见,Spark SQL是Spark用来处理结构化数据的一个模块。
结构化数据指的是:一般指数据有固定的 Schema(约束),例如在用户表中,name 字段是 String 型,那么每一条数据的 name 字段值都可以当作 String 来使用。并且将要处理的结构化数据封装在DataFrame中,在最开始的版本1.0中,其中DataFrame = RDD + Schema信息。
SparkSQL 在 1.6 时代,增加了一个新的API叫做 Dataset,Dataset 统一和结合了 SQL 的访问和命令式 API 的使用,这是一个划时代的进步。在 Dataset 中可以轻易的做到使用 SQL 查询并且筛选数据,然后使用命令式 API 进行探索式分析。
Spark 2.x发布时,将Dataset和DataFrame统一为一套API,以Dataset数据结构为主,其中DataFrame = Dataset[Row]。
Spark 3.x时代,Spark的开发者似乎对SparkSQL情有独钟,发布了大量的针对SQL的优化。我们在下文中会提到。
Spark SQL运行原理
在SparkSQL中有两种数据抽象。
DataFrame
DataFrame是一种以RDD为基础的带有Schema元信息的分布式数据集,类似于传统数据库的二维表格。
除了数据以外,还记录数据的结构信息,即schema。同时,与Hive类似,DataFrame也支持嵌套数据类型(struct、array和map)。从API易用性的角度上看,DataFrame API提供的是一套高层的关系操作,比函数式的RDD API要更加友好,门槛更低。
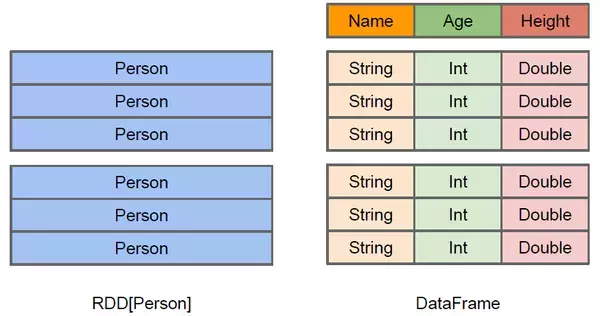
上图直观地体现了DataFrame和RDD的区别。左侧的RDD[Person]虽然以Person为类型参数,但Spark框架本身不了解Person类的内部结构。而右侧的DataFrame却提供了详细的结构信息,使得Spark SQL可以清楚地知道该数据集中包含哪些列,每列的名称和类型各是什么。
DataFrame多了数据的结构信息,即schema。
RDD是分布式的Java对象的集合。
DataFrame是分布式的Row对象的集合。
DataFrame除了提供了比RDD更丰富的算子以外,更重要的特点是提升执行效率、减少数据读取以及执行计划的优化,比如filter下推、裁剪等。
DataFrame为数据提供了Schema的视图。可以把它当做数据库中的一张表来对待,DataFrame也是懒执行的。性能上比RDD要高,主要原因:优化的执行计划:查询计划通过Spark catalyst optimiser进行优化。
SparkSQL的解析过程我们直接应用《图解Spark核心技术与案例实战》这本书中的内容,大概分为四个步骤:
词法和语法解析Parse:生成逻辑计划
绑定Bind:生成可执行计划
优化Optimize:生成最优执行计划
执行Execute:返回实际数据
SparkSQL对SQL语句的处理和关系型数据库采用了类似的方法, SparkSQL会先将SQL语句进行解析Parse形成一个Tree,然后使用Rule对Tree进行绑定、优化等处理过程,通过模式匹配对不同类型的节点采用不同的操作。而SparkSQL的查询优化器是Catalyst,它负责处理查询语句的解析、绑定、优化和生成物理计划等过程,Catalyst是SparkSQL最核心的部分,其性能优劣将决定整体的性能。
SparkSQL由4个部分构成:
Core:负责处理数据的输入/输出,从不同的数据源获取数据(如RDD、Parquet文件),然后将查询结果输出成DataFrame
Catalyst:负责处理查询语句的整个过程,包括解析、绑定、优化、物理计划等
Hive:负责对Hive数据的处理
Hive-thriftserver:提供CLI和JDBC/ODBC接口等
Tree
Tree是Catalyst执行计划表示的数据结构。LogicalPlans,Expressions和Pysical Operators都可以使用Tree来表示。Tree具备一些Scala Collection的操作能力和树遍历能力。Tree提供三种特质:
UnaryNode:一元节点,即只有一个子节点
BinaryNode:二元节点,即有左右子节点的二叉节点
LeafNode:叶子节点,没有子节点的节点
针对不同的节点,Tree提供了不同的操作方法。对Tree的遍历,主要是通过迭代将Rule应用到该节点以及子节点。Tree有两个子类继承体系,即QueryPlan和Expression。
QueryPlan下面的两个子类分别是LogicalPlan(逻辑执行计划)和SparkPlan(物理执行计划)。QueryPlan内部带有output:Seq[Attribute]、transformExpressionDown和transformExpressionUp等方法,它的主要子体系是LogicalPlan,即逻辑执行计划表示,它在Catalyst优化器里有详细实现。LogicalPlan内部带一个reference:Set[Attribute],主要方法为resolve(name:String): Option[NamedExpression],用于分析生成对应的NamedExpression。对于SparkPlan,即物理执行计划表示,需要用户在系统中自己实现。LogicalPlan本身也有很多具体子类,也分为UnaryNode,BinaryNode和LeafNode三类。
Expression是表达式体系,是指不需要执行引擎计算,而可以直接计算或处理的节点,包括Cast操作、Porjection操作、四则运算和逻辑操作符运算等等。
Rule
Rule[TreeType <: TreeNode[__]]是一个抽象类,子类需要复写apply(plan: TreeType)方法来指定处理逻辑。对 于Rule的具体实现是通过RuleExecutor完成的,凡是需要处理执行计划树进行实施规则匹配和节点处理的,都需要继承RuleExecutor[TreeType]抽象类。
在RuleExecutor的实现子类(如Analyzer和Optimizer)中会定义Batch,Once和FixedPoint。其中每个Batch代表着一套规则,这样可以简便地、模块化地对Tree进行Transform操作。Once和FixedPoint是配备策略。RuleExecutor内部有一个Seq[Batch]属性,定义的是该RuleExecutor的处理逻辑,具体的处理逻辑由具体的Rule子类实现。RuleExecutor中的apply方法会按照Batch顺序和Batch内的Rules顺序,对传入的节点进行迭代操作。
在Analyzer过程中处理由解析器(SqlParser)生成的未绑定逻辑计划Tree时,就定义了多种Rules应用到该Unresolved逻辑计划Tree上。
Analyzer过程中使用了自身定义的多个Batch,如MultiInstanceRelations,Resolution,CheckAnalysis和AnalysisOperators:每个Batch又由不同的Rules构成,每个Rule又有自己相对应的处理函数。注意,不同Rule的使用次数不同(Once FixedPoint)。
整个Spark SQL运行流程如下:
将SQL语句通过词法和语法解析生成未绑定的逻辑执行计划(Unresolved LogicalPlan),包含Unresolved Relation、Unresolved Function和Unresolved Attribute,然后在后续步骤中使用不同的Rule应用到该逻辑计划上。
Analyzer使用Analysis Rules,配合元数据(如SessionCatalog 或是 Hive Metastore等)完善未绑定的逻辑计划的属性而转换成绑定的逻辑计划。具体流程是县实例化一个Simple Analyzer,然后遍历预定义好的Batch,通过父类Rule Executor的执行方法运行Batch里的Rules,每个Rule会对未绑定的逻辑计划进行处理,有些可以通过一次解析处理,有些需要多次迭代,迭代直到达到FixedPoint次数或前后两次的树结构没变化才停止操作。
Optimizer使用Optimization Rules,将绑定的逻辑计划进行合并、列裁剪和过滤器下推等优化工作后生成优化的逻辑计划。
Planner使用Planning Strategies,对优化的逻辑计划进行转换(Transform)生成可以执行的物理计划。根据过去的性能统计数据,选择最佳的物理执行计划CostModel,最后生成可以执行的物理执行计划树,得到SparkPlan。
在最终真正执行物理执行计划之前,还要进行preparations规则处理,最后调用SparkPlan的execute执行计算RDD。
如果这么抽象晦涩的内容你看不懂,可以看这里:
Spark SQL优化
在聊SparkSQL优化前,我们需要知道:
在Spark3.0之前,我们经常做的优化包括:
代码层面的优化
使用reduceByKey/aggregateByKey替代groupByKey。
使用mapPartitions替代普通map。
mapPartitions类的算子,一次函数调用会处理一个partition所有的数据,而不是一次函数调用处理一条,性能相对来说会高一些。但是有的时候,使用mapPartitions会出现OOM(内存溢出)的问题。因为单次函数调用就要处理掉一个partition所有的数据,如果内存不够,垃圾回收时是无法回收掉太多对象的,很可能出现OOM异常。所以使用这类操作时要慎重!
使用foreachPartitions替代foreach。
原理类似于“使用mapPartitions替代map”,也是一次函数调用处理一个partition的所有数据,而不是一次函数调用处理一条数据。在实践中发现,foreachPartitions类的算子,对性能的提升还是很有帮助的。比如在foreach函数中,将RDD中所有数据写MySQL,那么如果是普通的foreach算子,就会一条数据一条数据地写,每次函数调用可能就会创建一个数据库连接,此时就势必会频繁地创建和销毁数据库连接,性能是非常低下;但是如果用foreachPartitions算子一次性处理一个partition的数据,那么对于每个partition,只要创建一个数据库连接即可,然后执行批量插入操作,此时性能是比较高的。实践中发现,对于1万条左右的数据量写MySQL,性能可以提升30%以上。
使用filter之后进行coalesce操作。
通常对一个RDD执行filter算子过滤掉RDD中较多数据后(比如30%以上的数据),建议使用coalesce算子,手动减少RDD的partition数量,将RDD中的数据压缩到更少的partition中去。因为filter之后,RDD的每个partition中都会有很多数据被过滤掉,此时如果照常进行后续的计算,其实每个task处理的partition中的数据量并不是很多,有一点资源浪费,而且此时处理的task越多,可能速度反而越慢。因此用coalesce减少partition数量,将RDD中的数据压缩到更少的partition之后,只要使用更少的task即可处理完所有的partition。在某些场景下,对于性能的提升会有一定的帮助。
使用repartitionAndSortWithinPartitions替代repartition与sort类操作。
repartitionAndSortWithinPartitions是Spark官网推荐的一个算子。官方建议,如果是需要在repartition重分区之后还要进行排序,就可以直接使用repartitionAndSortWithinPartitions算子。因为该算子可以一边进行重分区的shuffle操作,一边进行排序。shuffle与sort两个操作同时进行,比先shuffle再sort来说,性能可能是要高的。
尽量减少shuffle相关操作,减少join操作。
写入数据库时,设置批量插入,关闭事务
result.write.mode(SaveMode.Append).format("jdbc")
.option(JDBCOptions.JDBC_URL,"jdbc:mysql://127.0.0.1:3306/db?rewriteBatchedStatement=true") //开启批量处理
.option("user","root")
.option("password","XXX")
.option(JDBCOptions.JDBC_TABLE_NAME,"xxx")
.option(JDBCOptions.JDBC_TXN_ISOLATION_LEVEL,"NONE") //不开启事务
.option(JDBCOptions.JDBC_BATCH_INSERT_SIZE,10000) //设置批量插入数据量
.save()
缓存复用数据
如在代码下方反复用到了Result数据,可以考虑将此数据缓存下来。
val Result = spark.sql(
"""
|SELECT * from A
|UNION
|SELECT * FROM B
""".stripMargin)
Result.persist(StorageLevel.DISK_ONLY_2)
Result.registerTempTable("Result")
参数优化
注意:具体参数设置需要具体问题具体分析,并不是越大越好,需反复测试寻找最优值。另外不同Spark版本的参数可能有过期,请注意区分。
//CBO优化
sparkConf.set("spark.sql.cbo.enabled","true")
sparkConf.set("spark.sql.cbo.joinReorder.enabled","true")
sparkConf.set("spark.sql.statistics.histogram.enabled","true")
//自适应查询优化(2.4版本之后)
sparkConf.set("spark.sql.adaptive.enabled","true")
//开启consolidateFiles
sparkConf.set("spark.shuffle.consolidateFiles","true")
//设置并行度
sparkConf.set("spark.default.parallelism","150")
//设置数据本地化等待时间
sparkConf.set("spark.locality.wait","6s")
//设置mapTask写磁盘缓存
sparkConf.set("spark.shuffle.file.buffer","64k")
//设置byPass机制的触发值
sparkConf.set("spark.shuffle.sort.bypassMergeThreshold","1000")
//设置resultTask拉取缓存
sparkConf.set("spark.reducer.maxSizeInFlight","48m")
//设置重试次数
sparkConf.set("spark.shuffle.io.maxRetries","10")
//设置重试时间间隔
sparkConf.set("spark.shuffle.io.retryWait","10s")
//设置reduce端聚合内存比例
sparkConf.set("spark.shuffle.memoryFraction","0.5")
//设置序列化
sparkConf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
//设置自动分区
sparkConf.set("spark.sql.auto.repartition","true")
//设置shuffle过程中分区数
sparkConf.set("spark.sql.shuffle.partitions","500")
//设置自动选择压缩码
sparkConf.set("spark.sql.inMemoryColumnarStorage.compressed","true")
//关闭自动推测分区字段类型
sparkConf.set("spark.sql.source.partitionColumnTypeInference.enabled","false")
//设置spark自动管理内存
sparkConf.set("spark.sql.tungsten.enabled","true")
//执行sort溢写到磁盘
sparkConf.set("spark.sql.planner.externalSort","true")
//增加executor通信超时时间
sparkConf.set("spark.executor.heartbeatInterval","60s")
//cache限制时间
sparkConf.set("spark.dynamicAllocation.cachedExecutorIdleTimeout","120")
//设置广播变量
sparkConf.set("spark.sql.autoBroadcastJoinThreshold","104857600")
//其他设置
sparkConf.set("spark.sql.files.maxPartitionBytes","268435456")
sparkConf.set("spark.sql.files.openCostInBytes","8388608")
sparkConf.set("spark.debug.maxToStringFields","500")
//推测执行机制
sparkConf.set("spark.speculation","true")
sparkConf.set("spark.speculation.interval","500")
sparkConf.set("spark.speculation.quantile","0.8")
sparkConf.set("spark.speculation.multiplier","1.5")
Spark3.0 YYDS
Apache Spark 3.0 增加了很多令人兴奋的新特性,包括动态分区修剪(Dynamic Partition Pruning)、自适应查询执行(Adaptive Query Execution)、加速器感知调度(Accelerator-aware Scheduling)、支持 Catalog 的数据源API(Data Source API with Catalog Supports)、SparkR 中的向量化(Vectorization in SparkR)、支持 Hadoop 3/JDK 11/Scala 2.12 等等。这个版本一共解决了 3400 多个 ISSUES。
Spark3.0中对SparkSQL进行了重大更新,可以看出Spark社区对待SparkSQL的态度。
动态分区修剪(Dynamic Partition Pruning)
在 Spark 2.x 里面加了基于代价的优化,但是这个并不表现的很好。主要有以下几个原因:统计信息的缺失;统计信息过期;很难抽象出一个通用的 cost model。
为了解决这些问题,Apache Spark 3.0 引入了基于 Runtime 的查询优化。
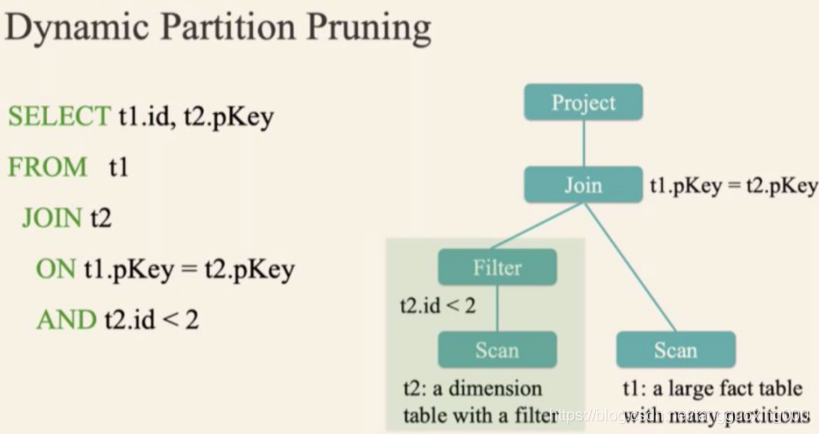
比如上面的 SQL 查询,假设 t2 表 t2.id < 2 过滤出来的数据比较少,但是由于之前版本的 Spark 无法进行动态计算代价,所以可能会导致 t1 表扫描出大量无效的数据。有了动态分区裁减,可以在运行的时候过滤掉 t1 表无用的数据。
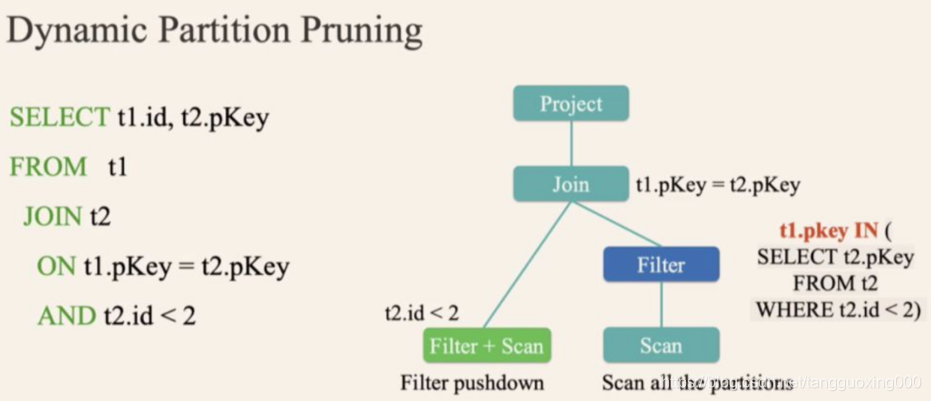
经过这个优化,查询扫描的数据大大减少,性能提升了 30+ 倍。
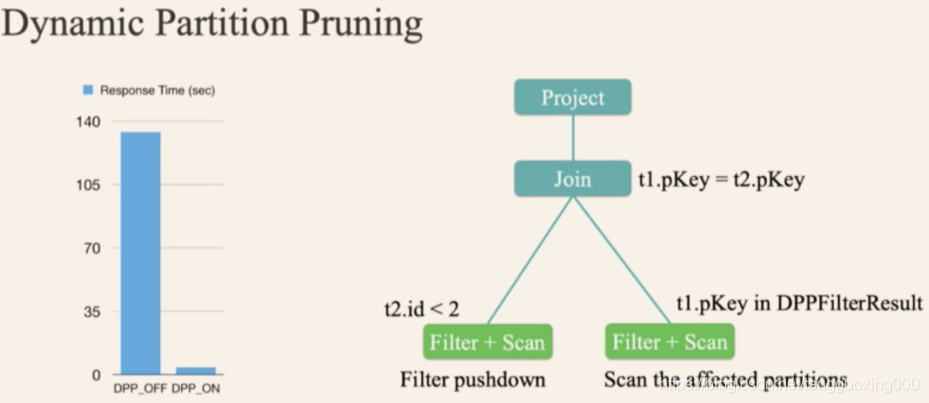
自适应查询执行(Adaptive Query Execution)
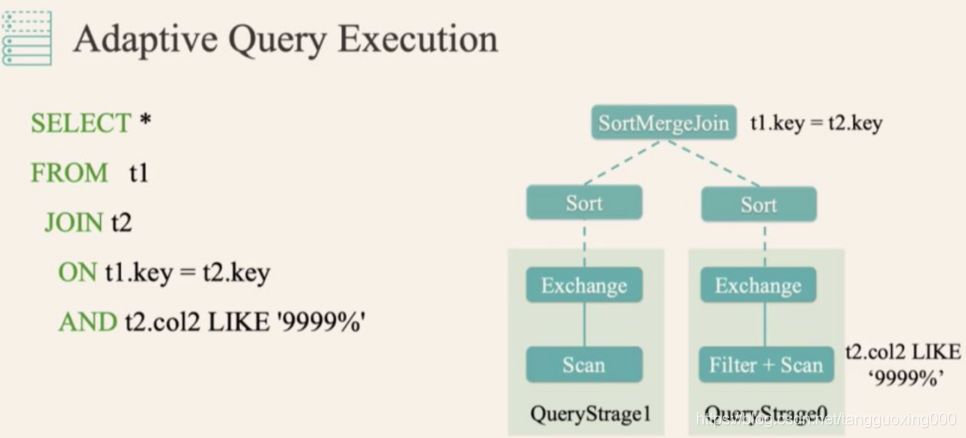
而有了 AQE(自适应查询执行) 之后,Spark 就可以动态统计相关信息,并动态调整执行计划,比如把 SortMergeJoin 变成 BroadcastHashJoin:
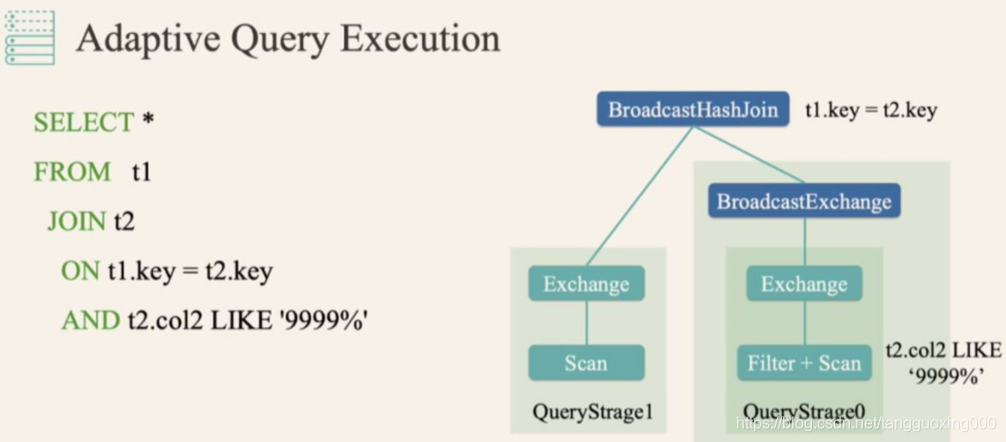
spark.sql.optimizer.dynamicPartitionPruning.enabled 参数必须设置为 true。
映射下推(Project PushDown)
说到列式存储的优势,映射下推是最突出的,它意味着在获取表中原始数据时只需要扫描查询中需要的列,由于每一列的所有值都是连续存储的,所以分区取出每一列的所有值就可以实现TableScan算子,而避免扫描整个表文件内容。
在Parquet中原生就支持映射下推,执行查询的时候可以通过Configuration传递需要读取的列的信息,这些列必须是Schema的子集,映射每次会扫描一个Row Group的数据,然后一次性得将该Row Group里所有需要的列的Cloumn Chunk都读取到内存中,每次读取一个Row Group的数据能够大大降低随机读的次数,除此之外,Parquet在读取的时候会考虑列是否连续,如果某些需要的列是存储位置是连续的,那么一次读操作就可以把多个列的数据读取到内存。
谓词下推(Predicate PushDown)
在数据库之类的查询系统中最常用的优化手段就是谓词下推了,通过将一些过滤条件尽可能的在最底层执行可以减少每一层交互的数据量,从而提升性能,
例如”select count(1) from A Join B on A.id = B.id where A.a > 10 and B.b < 100”SQL查询中,在处理Join操作之前需要首先对A和B执行TableScan操作,然后再进行Join,再执行过滤,最后计算聚合函数返回,但是如果把过滤条件A.a > 10和B.b < 100分别移到A表的TableScan和B表的TableScan的时候执行,可以大大降低Join操作的输入数据。
无论是行式存储还是列式存储,都可以在将过滤条件在读取一条记录之后执行以判断该记录是否需要返回给调用者,在Parquet做了更进一步的优化,优化的方法时对每一个Row Group的每一个Column Chunk在存储的时候都计算对应的统计信息,包括该Column Chunk的最大值、最小值和空值个数。通过这些统计值和该列的过滤条件可以判断该Row Group是否需要扫描。另外Parquet还增加诸如Bloom Filter和Index等优化数据,更加有效的完成谓词下推。
在使用Parquet的时候可以通过如下两种策略提升查询性能:
类似于关系数据库的主键,对需要频繁过滤的列设置为有序的,这样在导入数据的时候会根据该列的顺序存储数据,这样可以最大化的利用最大值、最小值实现谓词下推。
减小行组大小和页大小,这样增加跳过整个行组的可能性,但是此时需要权衡由于压缩和编码效率下降带来的I/O负载。
此外,关于SparkSQL的任务提交和案例代码,我们会在后面有专门的实战文章出来,请大家拭目以待。

你好,我是王知无,一个大数据领域的硬核原创作者。
做过后端架构、数据中间件、数据平台&架构、算法工程化。
专注大数据领域实时动态&技术提升&个人成长&职场进阶,欢迎关注。