
网络割接导致K8S整集群失败
目录
故障描述
处理经过
原因分析
故障总结
处理经过
| 时间 | 处理同学 | 动作 |
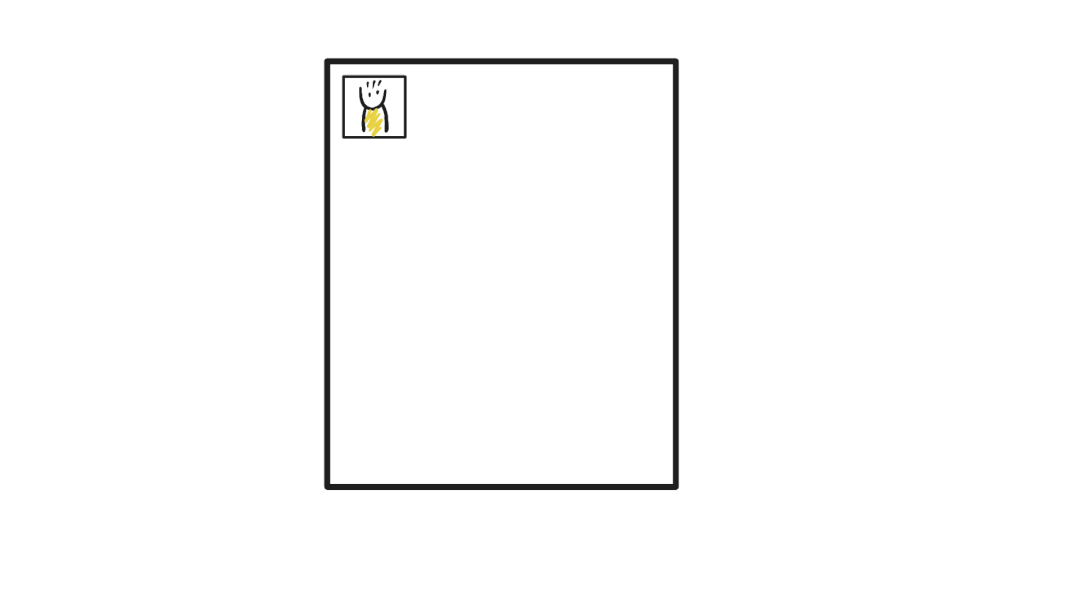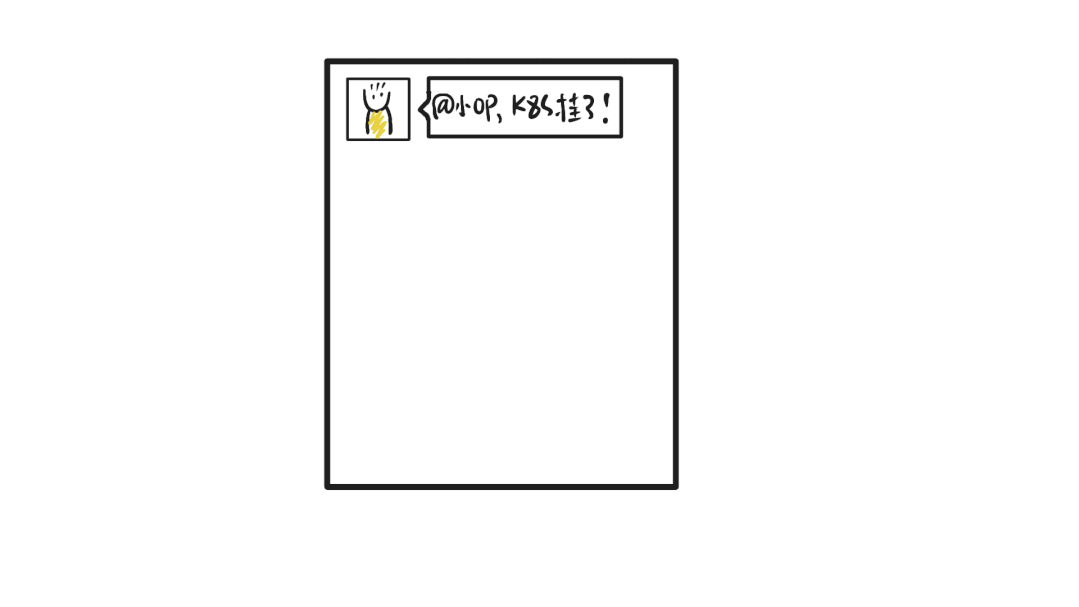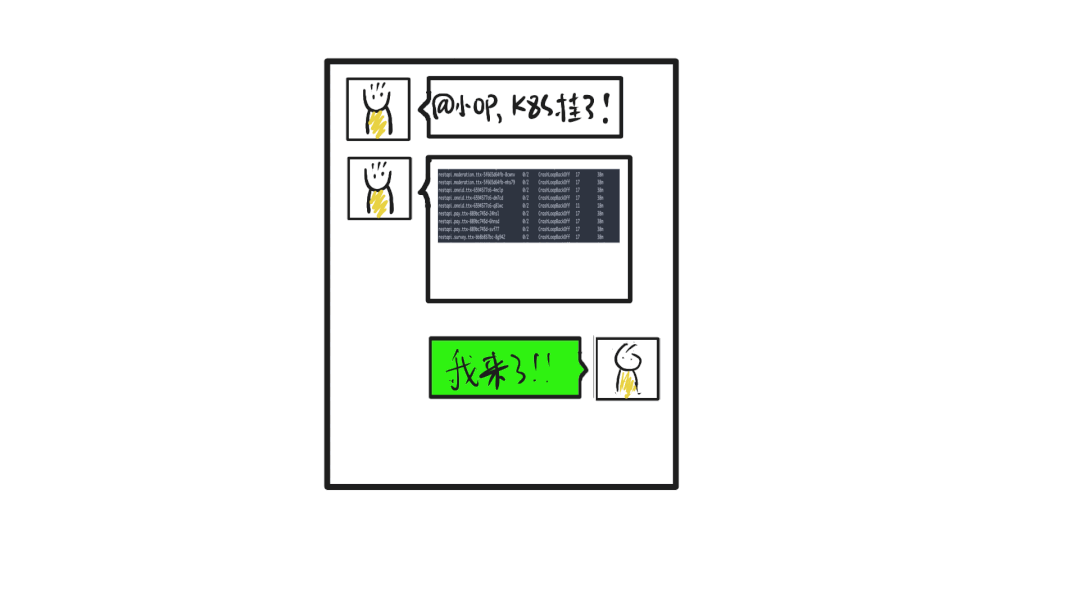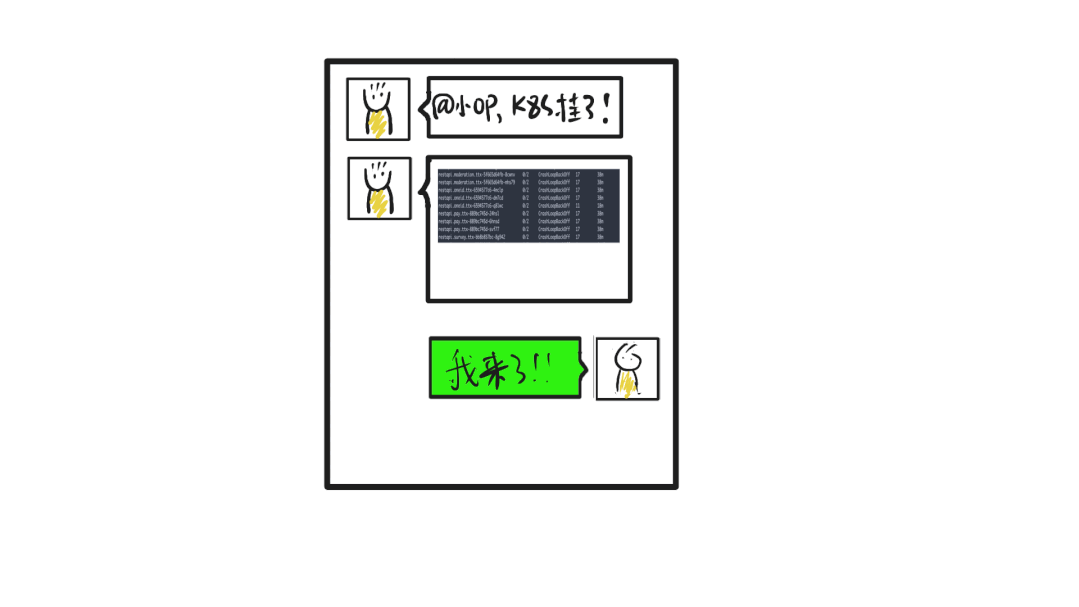
| 23:00 | 小O | 收到告警,起床打开电脑 |
| 23:03 | 小O | 确认集群所有Pod全部处理CrashLoopBackOff状态 |
| 23:05 | 小O | 业务为多集群部署,入口摘除此集群流量,业务恢复 |
| 23:30 | 小O | 重启kube-DNS Pod,集群恢复 |
原因分析
两天前
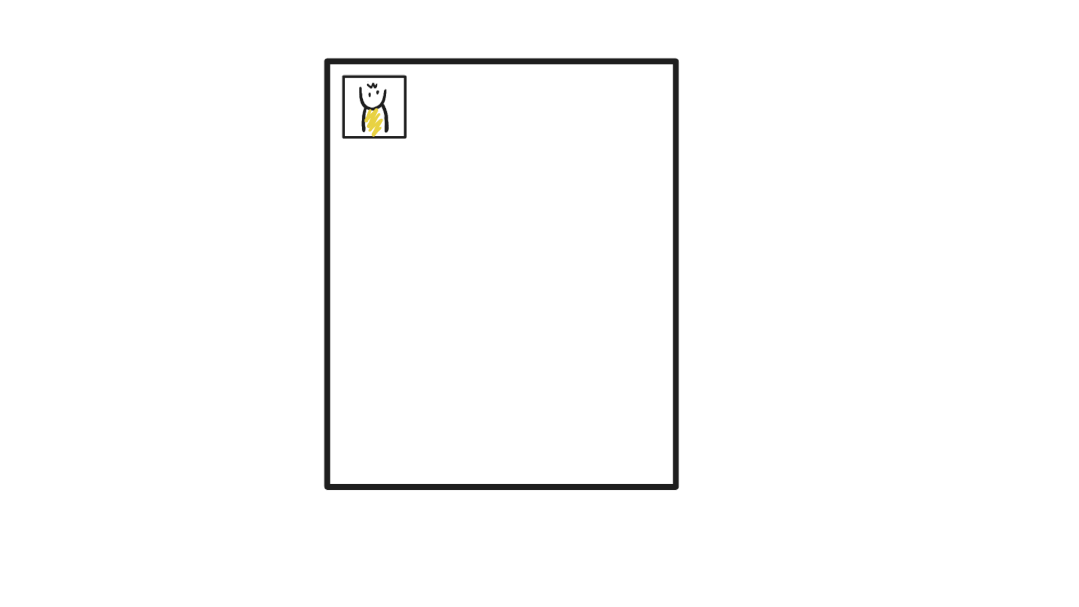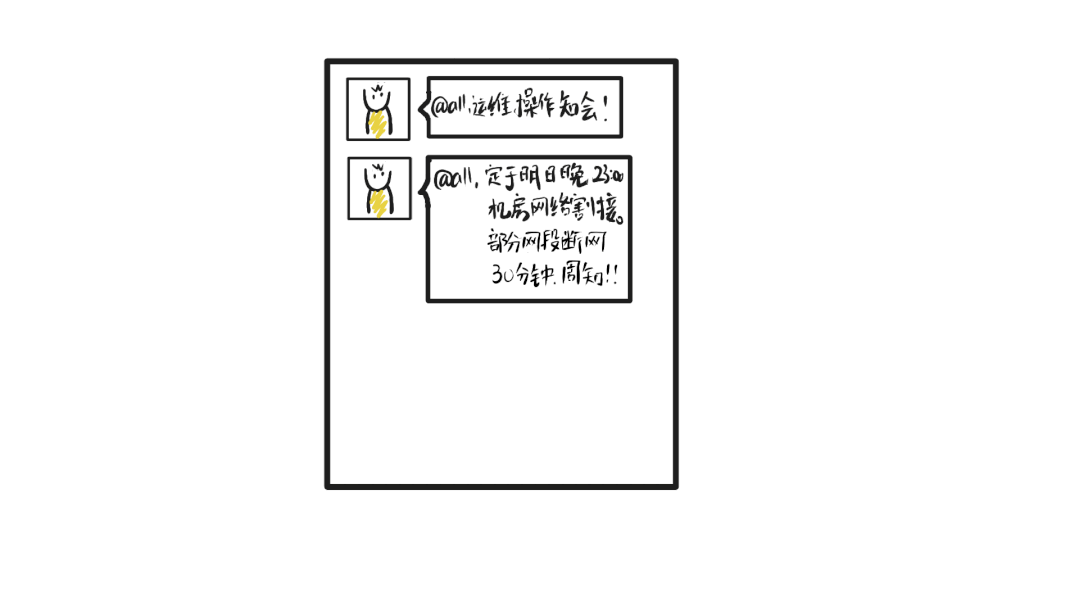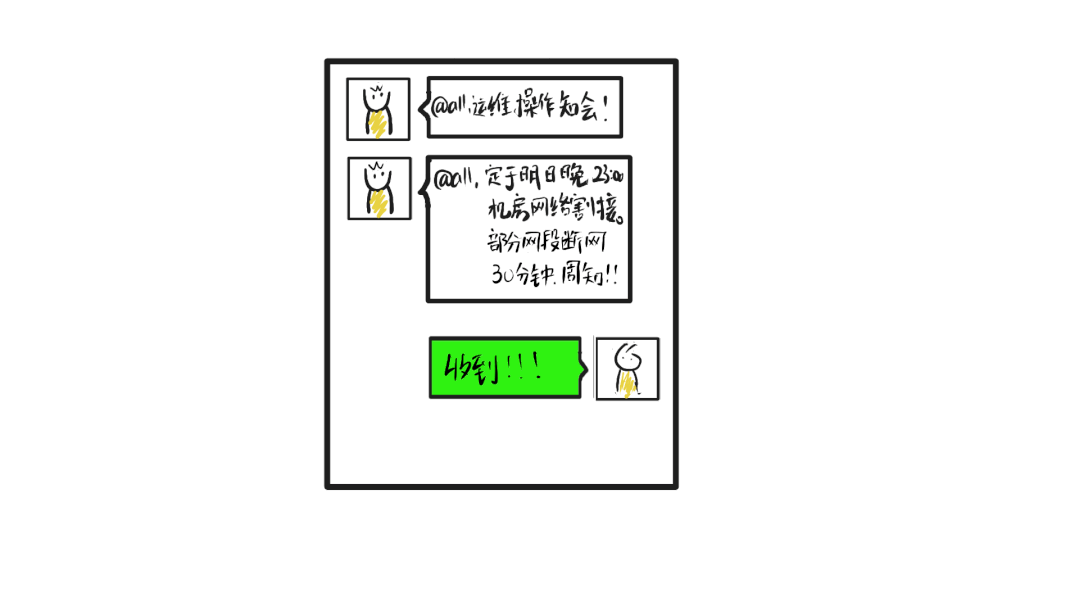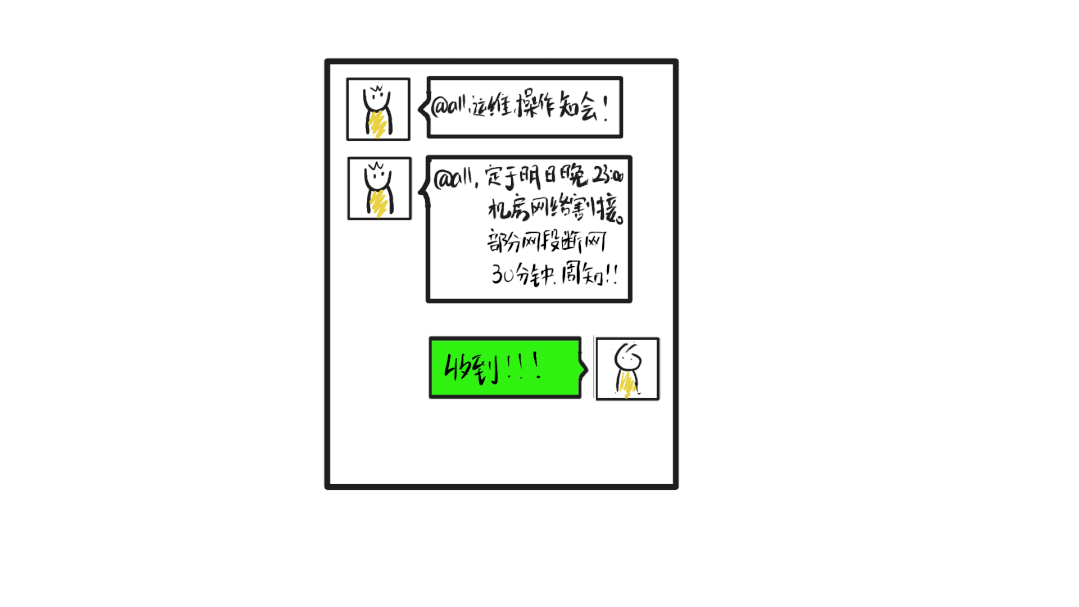
此次割接会使k8s控制面和宿主机之间断开连接,小O基于上家公司macvlan网络架构的历史经验认为
K8S控制面失败,只会让集群无法调度,但是Pod正常运行不会受影响
割接当晚
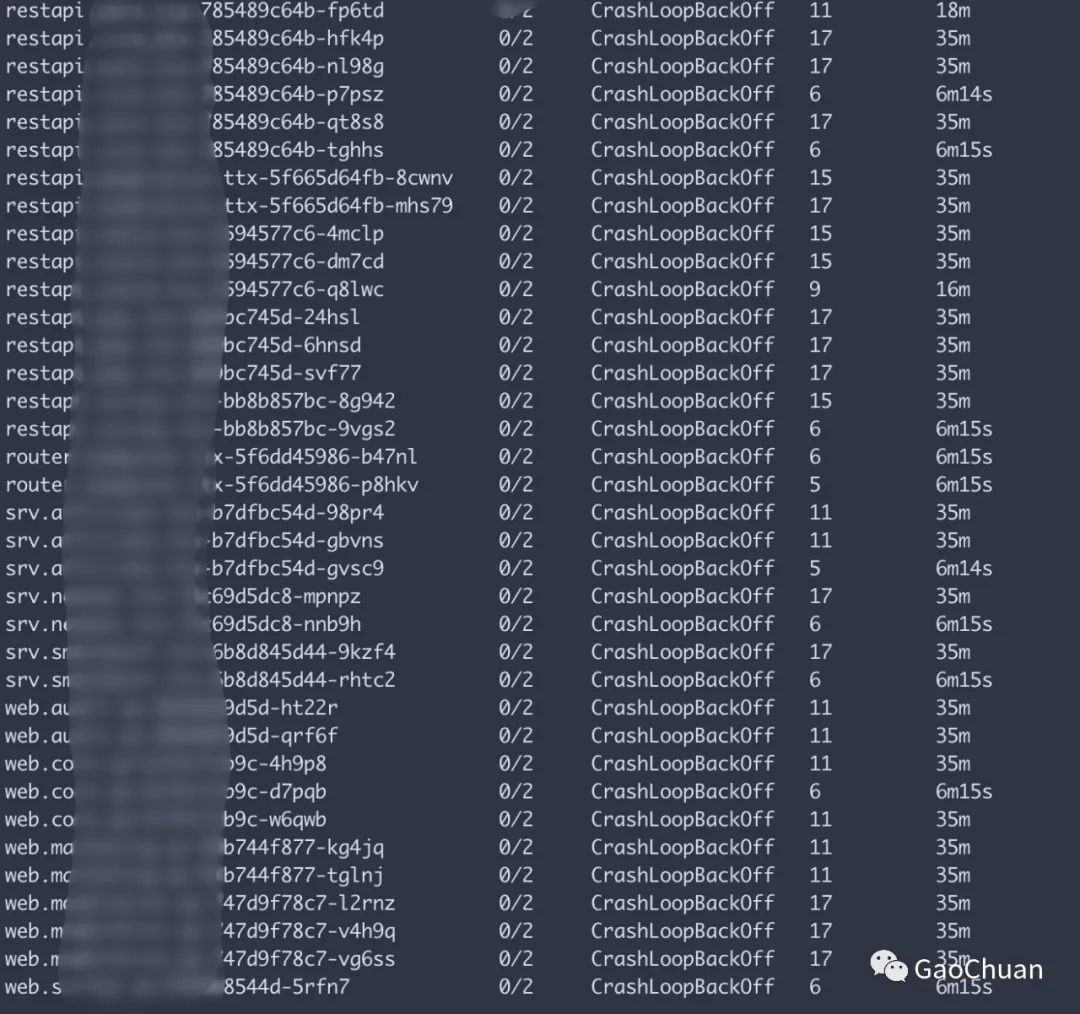

好在公司业务有多集群容灾,失败一个集群对业务没有太大影响。
公司架构
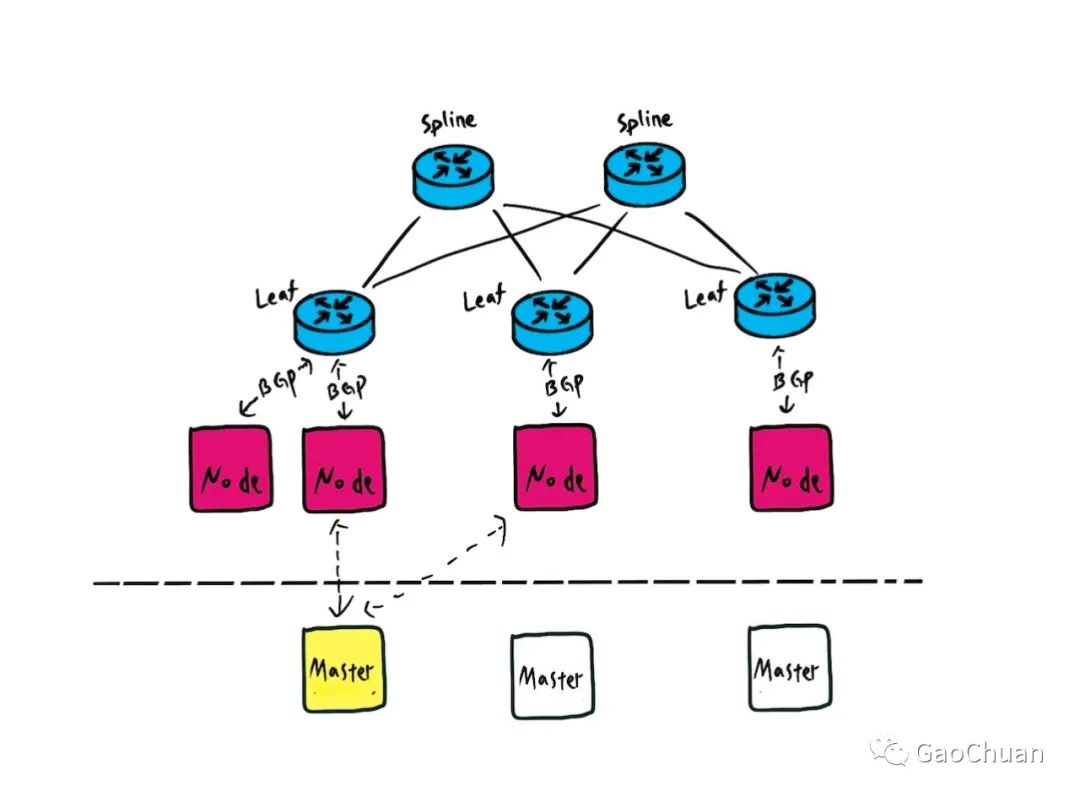
发生故障的集群是基于Calico+Istio的组成的:
其中BGP只存在Node和Leaf交换机
基于Istio的ServiceMesh模型则流量都有边车envoy接管
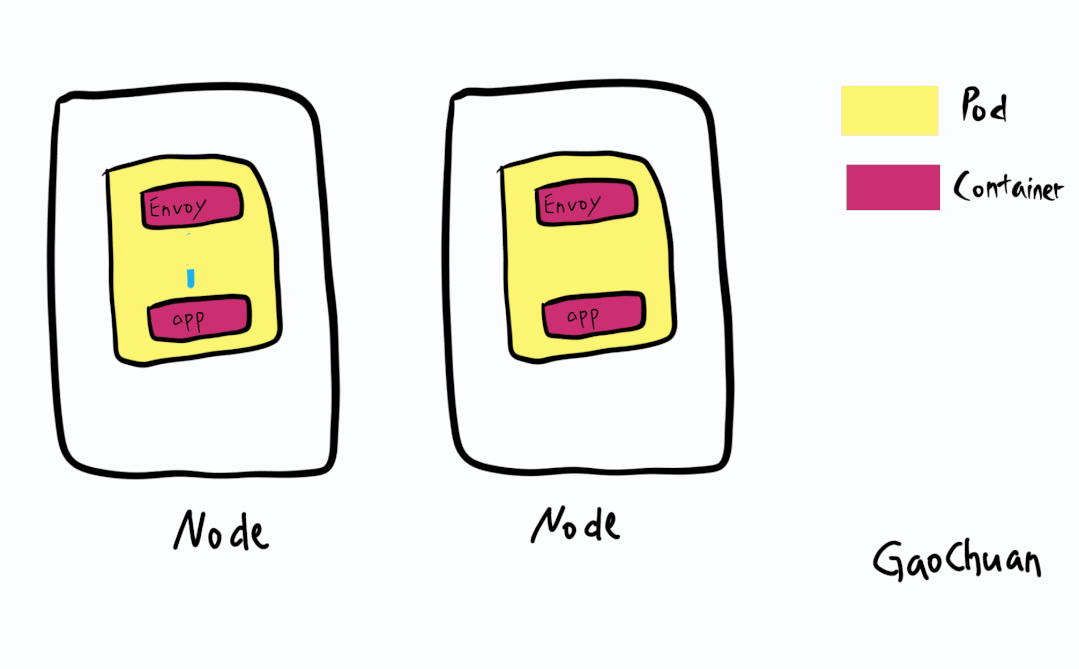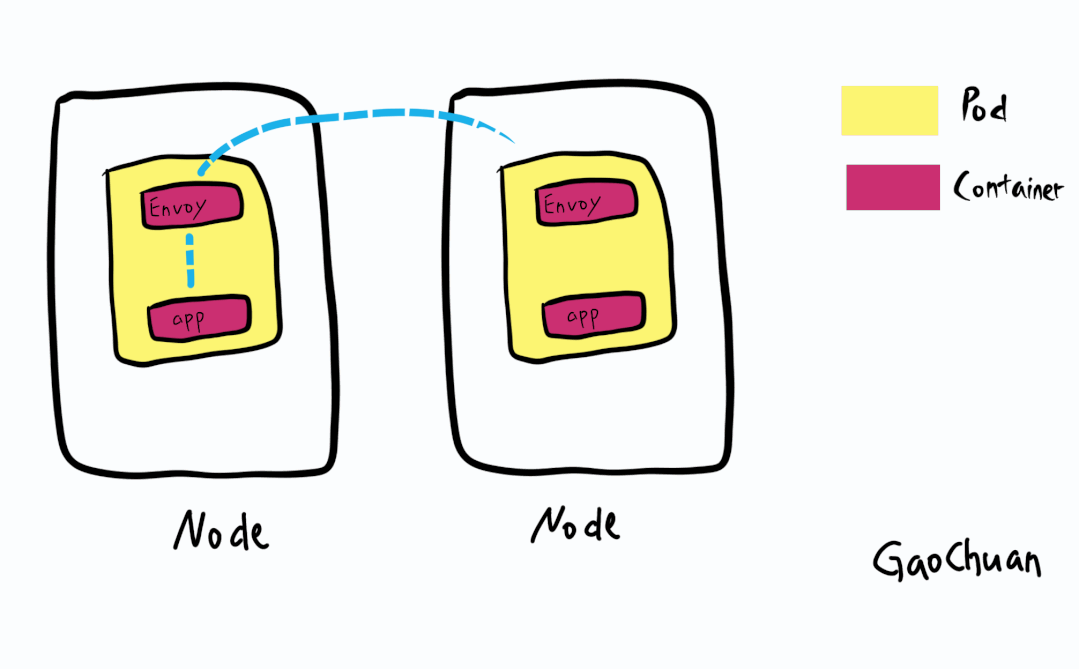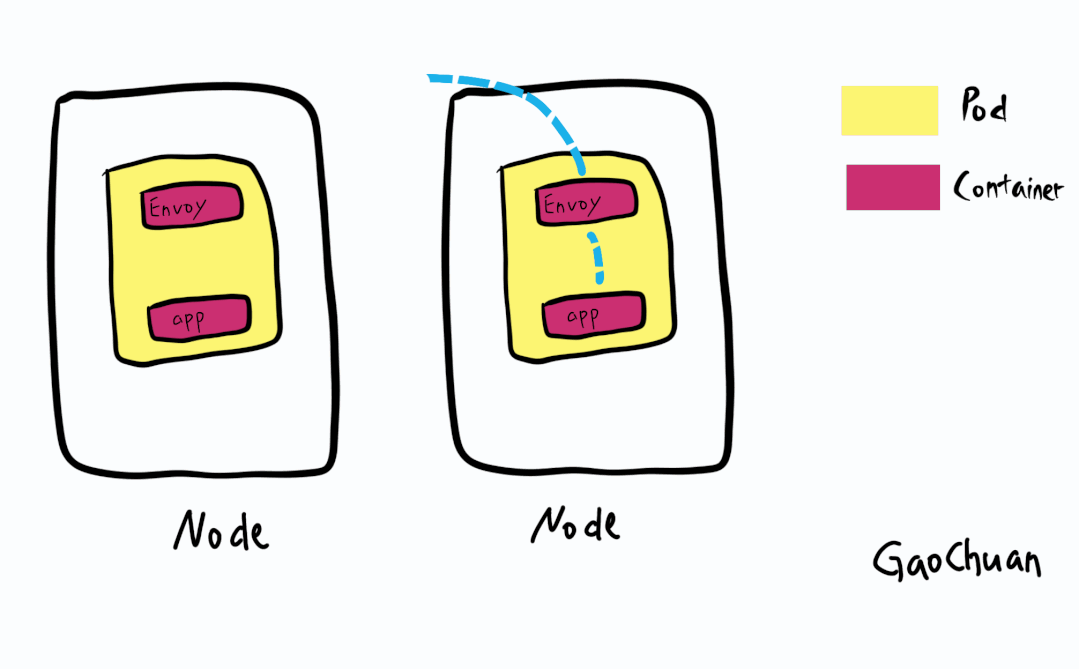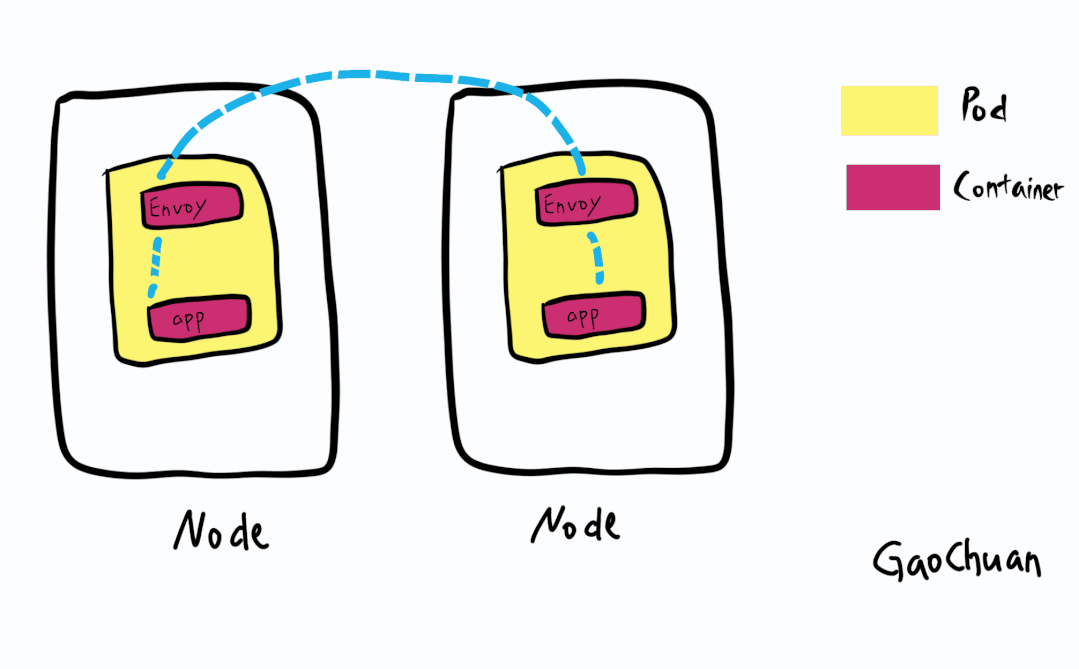
集群分析
小O告诉自己要谈定,开始分析问题。
首先发现所有的Pod的健康检查都失败了。
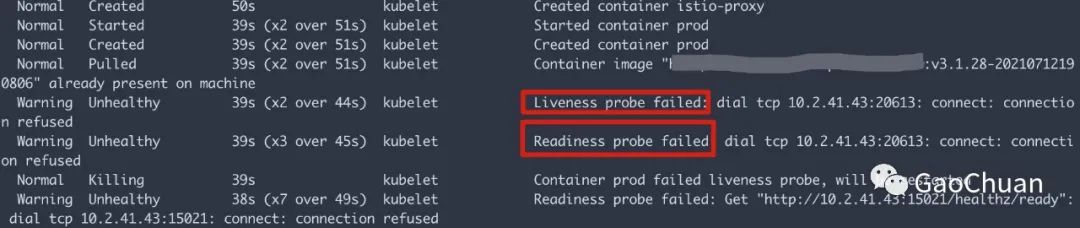
但是K8S的健康检查是在Node内部进行的,这和网络割接又有什么关系呢?接着分析。
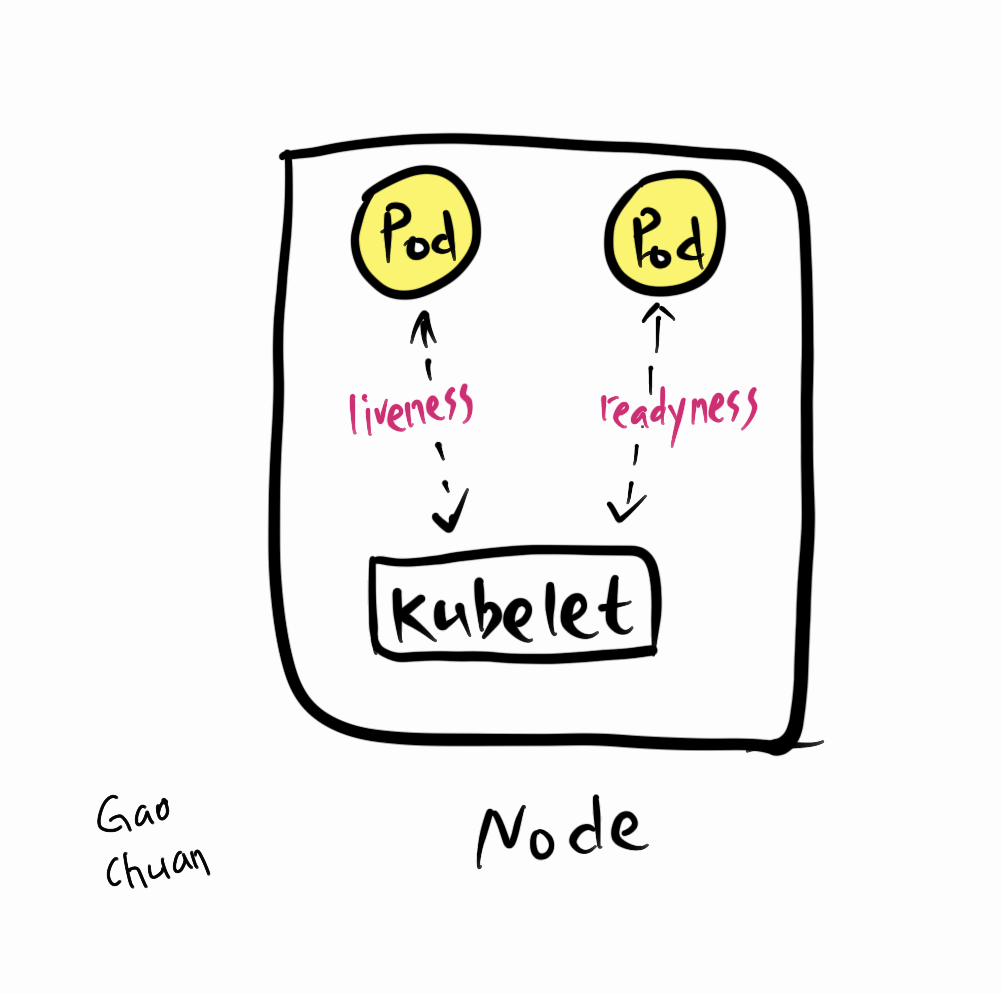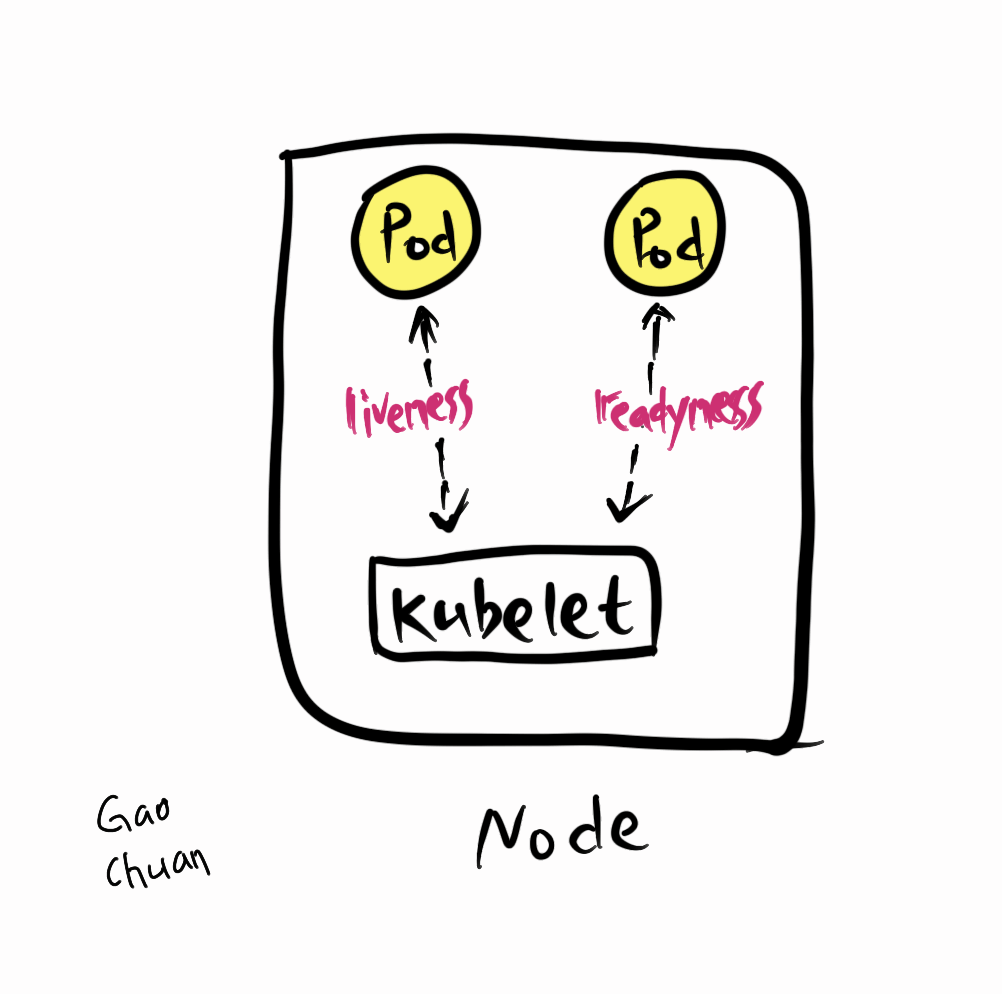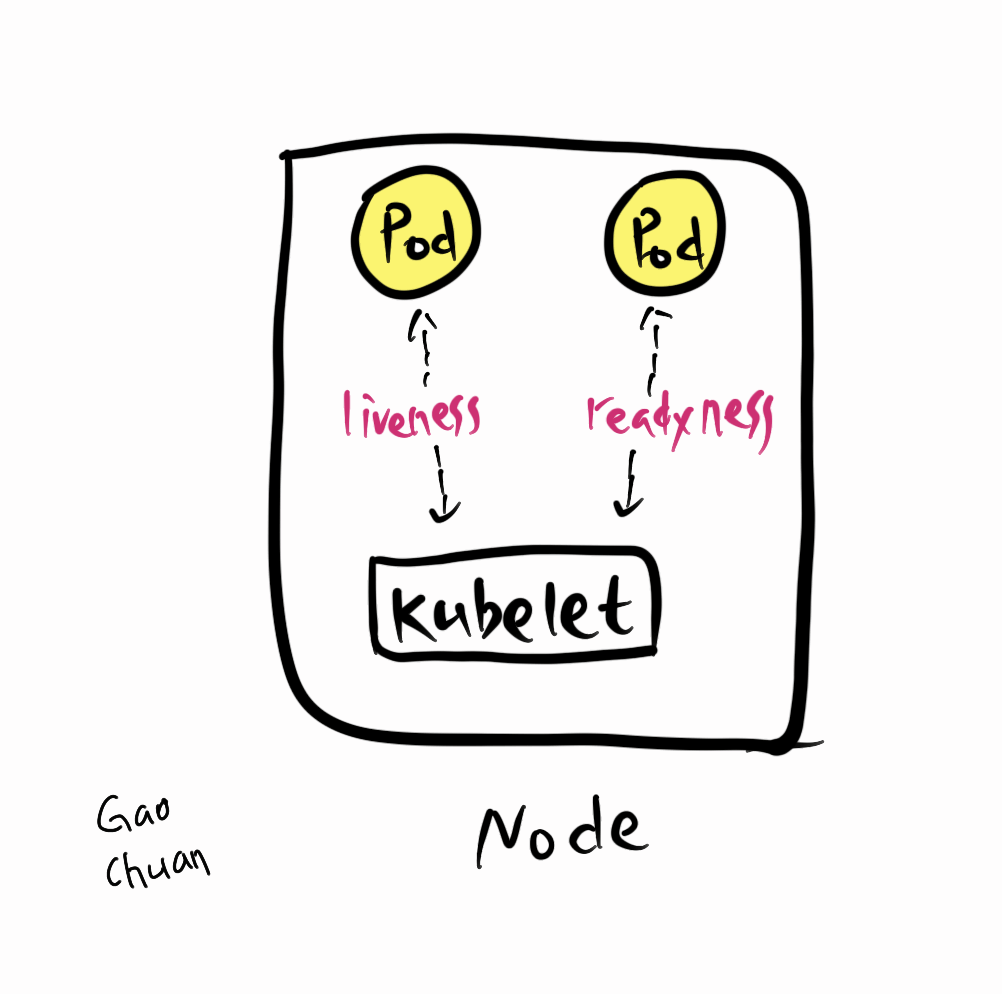
小O通过删除deployment的的healthcheck检查想让Pod起动,发现根本没有业务容器

获得线索一: 业务的Pod似乎没有到创建业务容器的那一步
于是查看边车容器的日志和istio-system空间,发现错误信息


获得线索二:istio出问题了
判断10.2.112.10的网络是不是有问题,卡死。

技巧:使用curl命令进行判断,如果目标机器存在,但是没有相应端口,则会收到Connection Refused(ping命令有时会误判,比如k8s的ClusterIP就不会响应ICMP)
到这里小O似乎明白了
53端口是DNS 的端口,10.2.112.10是DNS地址
istiod.istio-system.svc 是istio的的控制面的域名

原因找到了
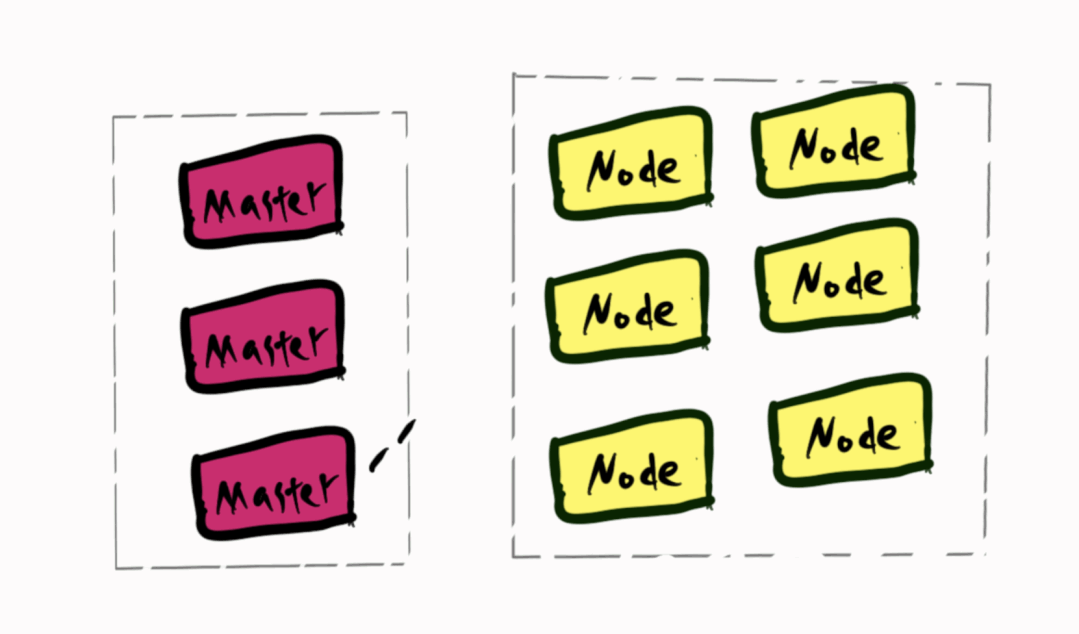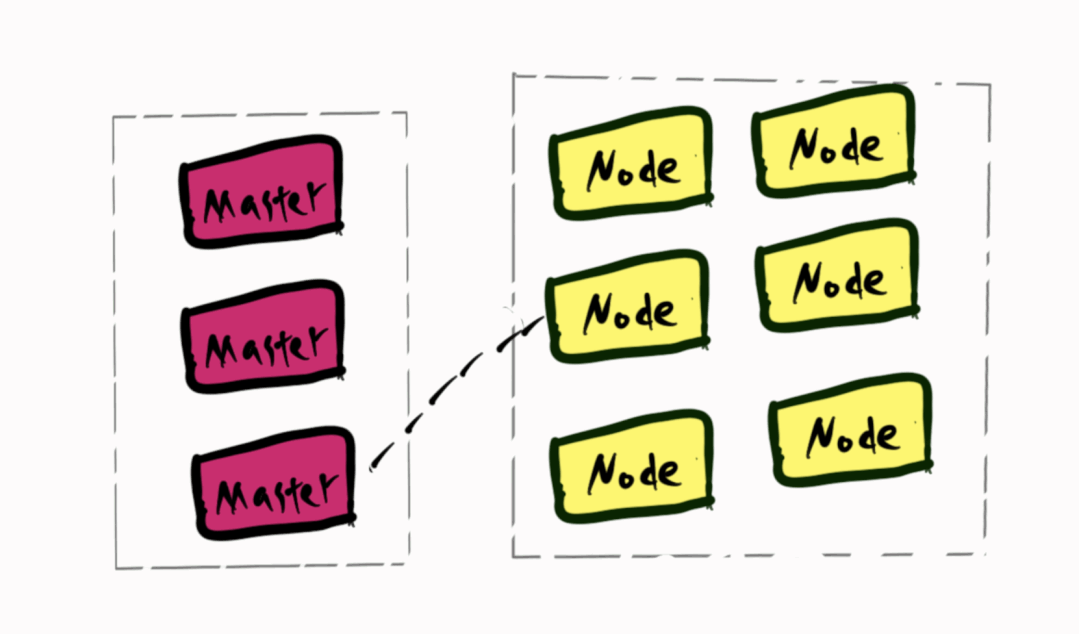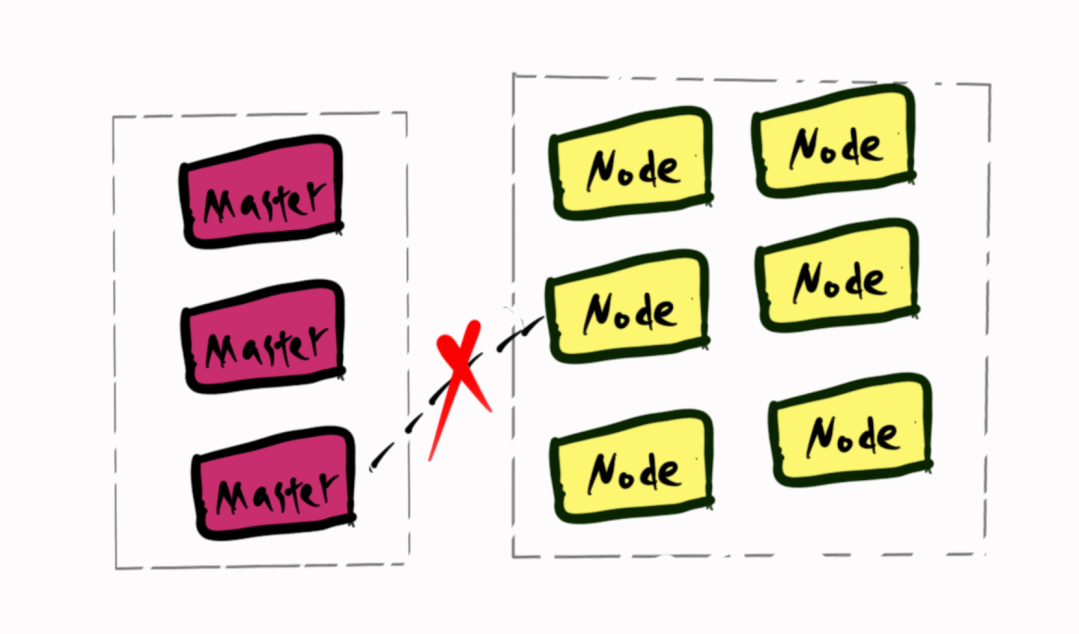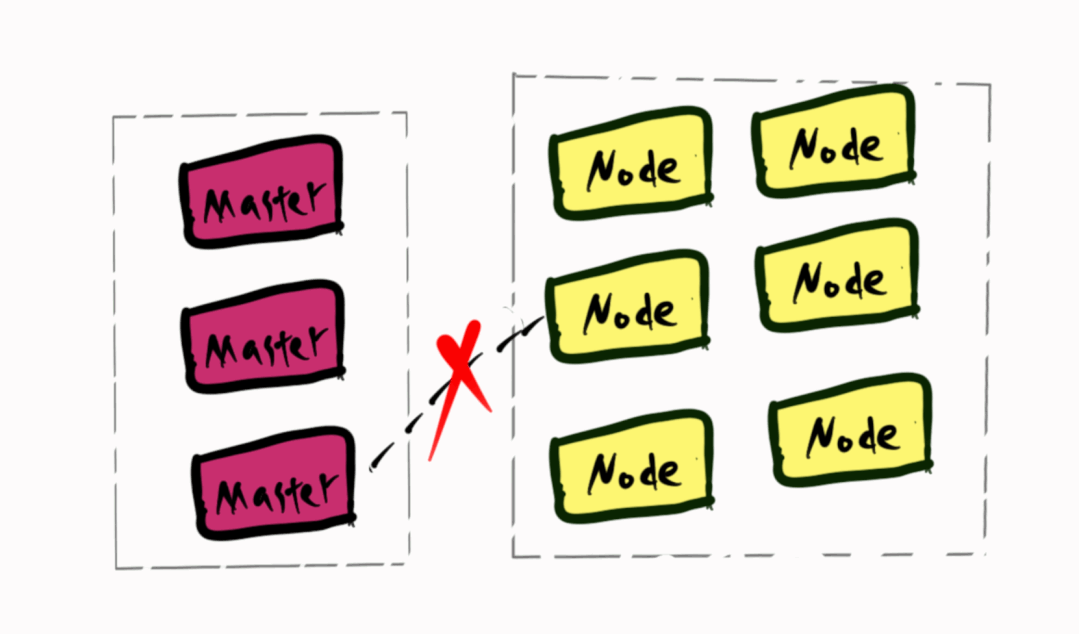
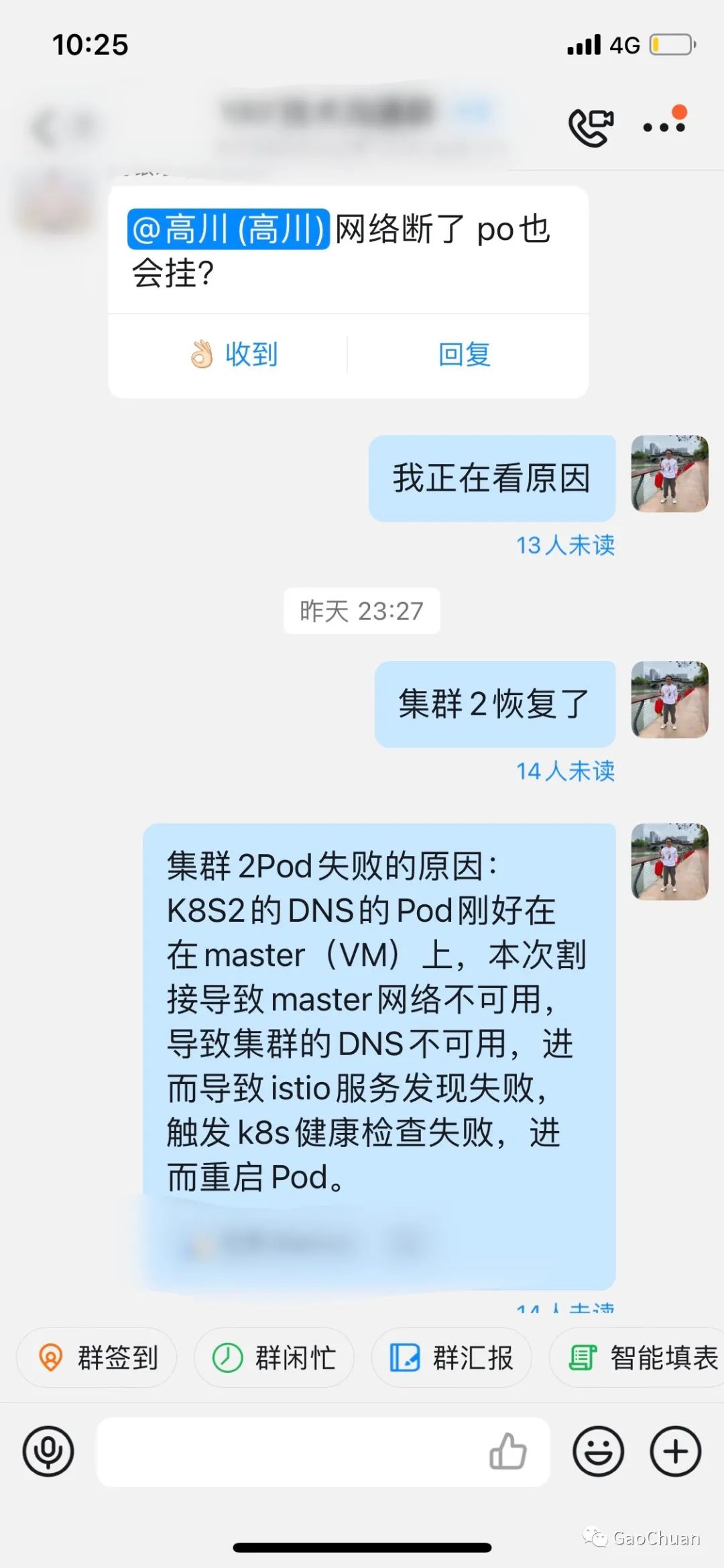
网络割接时,k8s认为所有Node不可用,将kube-dns的Pod调度到Master节点,网络不通导致所有业务无法解析DNS,envoy无法获得istio的控制面istiod的地址,进而所有sidecar无法获得xDS信息。健康检查来的请求由于被劫持到envoy找不到相应的后端,返回ConnectionRefused。进而触发K8S的健康检查失败,重启Pod,envoy启动时获取不到istiod的地址而无法启动。
紧急恢复
由于控制面没有和交换机做BGP,所以kube-dns的Pod调度到Master上,它的IP也不会广播到生产环境。这也是为什么即使网络割接结束了,curl 它的IP也会超时了。这时只要简单的删除kube-dns的Pod将它重新调度到Node上。一切就恢复正常了。
故障总结
控制面失败根据整体方案的不同对业务的影响不同。在使用了K8S的DNS或者Istio的情况下,控制面的全部失败对业务会有重在影响。
业务多集群部署提高了比较好的容灾机制,在集群全挂情况下保障了业务不受影响。
envoy的默认占用了15xxx的几个端口,下次可以快速发现问题
记录那些年我们一起处理过的故障~