
一文读懂SmartNIC
传统网卡仅实现了 L1-L2 层的逻辑,而由 Host CPU 负责处理网络协议栈中更高层的逻辑。即:CPU 按照 L3-L7 的逻辑,负责数据包的封装与解封装;网卡则负责更底层的 L2 层数据帧的封装和解封装,以及 L1 层电气信号的相应处理。
为适应高速网络,现代网卡中普遍卸载了部分 L3-L4 层的处理逻辑(e.g. 校验和计算、传输层分片重组等),来减轻 Host CPU 的处理负担。甚至有些网卡(e.g. RDMA 网卡)还将整个 L4 层的处理都卸载到硬件上,以完全解放 Host CPU。得益于这些硬件卸载技术,Host OS 的网络协议栈处理才能与现有的高速网络相匹配。
然而,由于 SDN、NFV 驱动的云计算/数据中心网络通信的快速增长,例如:随着 100G 浪潮的到来,Host CPU 将面临更大的压力,异构计算 Offload(异构加速技术)已是大势所趋。市场上需要一种具有更强卸载能力的新型 Smart NIC。
0.0 代。具体来说,传统网卡面向的用户痛点包括:
随着 VXLAN 等 Overlay 网络协议,以及 OpenFlow、Open vSwitch 等虚拟交换技术的引入,使得基于服务器的网络数据平面的复杂性急剧增加。
网络接口带宽的增加,意味着在软件中执行这些功能会给 CPU 资源造成难以承受的负载,留给应用程序运行的 CPU 资源很少或根本没有。
传统网卡固定功能的流量处理功能无法适应 SDN 和 NFV。
1.0 代。在 SmartNIC 出现之前,解决这些问题的方法大概有:
使用 DPDK 作为加速手段,但处理过程仍然依赖标配(未针对数据传输进行优化)的服务器及网卡,这始终是一个瓶颈,吞吐量性能低下,并且需要大量的 CPU 资源,还是没能节省昂贵的 CPU 资源。
使用 SR-IOV 技术,将 PF 映射为多个 VFs,使得每个 VF 都可以绑定到 VM。如此,吞吐量性能和 CPU 使用效率确实得到了改善,但灵活性却降低了,复杂性也增加了。并且,大多数 SR-IOV 网卡最多有效支持 1Gb 以太网端口的 8-16 个 VFs,和 10Gb 以太网端口的 40-64 个 VFs。
2.0 代。而 SmartNIC 的存在能够:
将 vSwitch 完全 Offload 到 SmartNIC,释放昂贵的 Host CPU 资源,将计算能力还给应用程序。
可以实现基于服务器的复杂网络数据平面功能,例如:多匹配操作处理、计量整形、流统计等。
支持网络的可编程性(通过更新的固件或客户编程),即便 SmartNIC 已经被插入到服务器使用。
与现有的开源生态系统无缝协作,以最大程度地提高软件功能的速度和影响力。
3.0 代。白盒交换机作为最受欢迎的 COTS 硬件,可以加入 Plugin 轻松实现 SDN 和 NFV 的各种计算及网络功能。
简而言之,SmartNIC 就是通过从 Host CPU 上 Offload(卸载)工作负载到网卡硬件,以此提高 Host CPU 的处理性能。其中的 “工作负载” 不仅仅是 Networking,还可以是 Storage、Security 等。
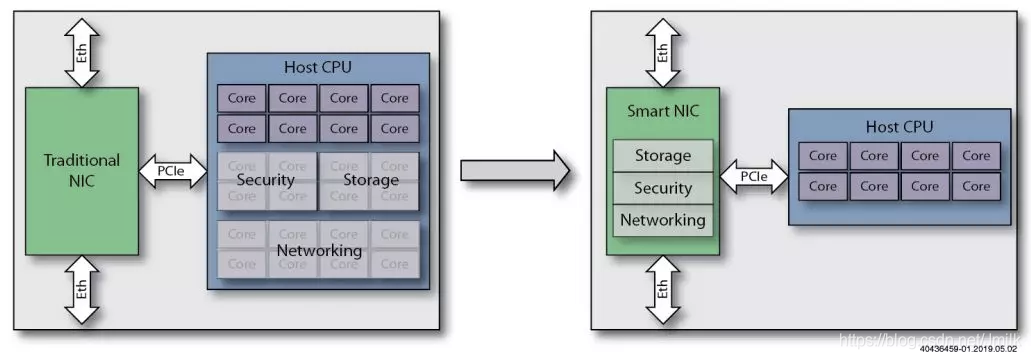
1、多核智能网卡,基于包含多个 CPU 内核的 ASIC(特殊应用集成电路)芯片:ASIC 具有价格优势,但灵活性有限,尽管基于 ASIC 的 NIC 相对容易配置,但最终功能将受到基于 ASIC 中定义的功能的限制,这可能会导致某些工作负载无法得到支持。
2、基于 FPGA(可编程门阵列)的智能网卡:FPGA 是高度可编程的,并且可以相对有效地支持几乎任何功能,不过众所周知的是,FPGA 最大的问题是编程难度大且价格昂贵。
3、FPGA 增强型智能网卡,将 FPGA 与 ASIC 网络控制器相结合。
多核智能网卡
多核智能网卡设计可能包括一个集成了许多 ASIC。这些 ASIC 内核通常是性能更高的 ARM 处理器,它们处理数据包并从主服务器 CPU(昂贵)上卸载任务。多核智能网卡 ASIC 还可以集成固定功能硬件引擎,它们可以卸载定义明确的任务,如标准化的安全和存储协议。
多核智能网卡至少受到两个制约因素的限制:
1、这些智能网卡基于软件可编程处理器,由于缺乏处理器并行性,它们在被用于网络处理时速度较慢。
2、这些多核 ASIC 中的固定功能硬件引擎缺乏智能网卡卸载功能越来越需要的数据平面可编程性和灵活性。
基于处理器的多核智能网卡设计在 10G 这一代网卡中得到了广泛的应用。然而,随着数据中心中的以太网数据速率从 10G 上升到 25G、40G、50G、100G 甚至更高,这些以软件为中心的多核智能网卡就已经难以跟上了。
这些多核智能网卡在这些较高的数据速率下无法达到所需的峰值带宽。同时,多核智能网卡 ASIC 中的固定功能引擎无法扩展去处理新的加密或安全算法,这是因为它们缺乏足够的可编程性,只能适应算法的细微改变。
基于 FPGA 的智能网卡
基于 FPGA 的智能网卡利用 FPGA 更大硬件可编程性来构建卸载到智能网卡上的任务所需的任何数据平面功能。由于 FPGA 是可重编程的,利用 FPGA 实现的数据平面功能可以任意并且实时地去除和重新配置。所有这些卸载功能都以硬件而非软件速度运行。
与单纯基于软件的实现相比,基于 FPGA 的智能网卡设计可以将网络功能提速几个数量级。在智能网卡设计中使用 FPGA 可提供定制硬件的线速性能和功率效率,并能够创建支持复杂卸载任务和提高单数据流网络性能的深度数据包/网络处理流水线。
通过利用 FPGA 中固有的大量硬件并行性来复制这些流水线,可以提高巨大数据性能,足以满足基于更快的以太网网络的下一代数据中心架构的高性能、高带宽、高吞吐量需求。
FPGA 增强型智能网卡
对向后兼容性的需求催生了 FPGA 增强型智能网卡,它为多核智能网卡网卡增加了 FPGA 功能。基于这种设计,网卡可以是现有的多核智能网卡,也可以只是一个简单的网卡专用集成电路(NIC ASIC)。
集成到这些设计中的网卡提供了向后兼容性,特别是对于超级管理程序的兼容性。因此,基于现有网卡的 FPGA 增强型智能网卡设计,加上用于扩展功能的 FPGA,可以立即实现其投资收益,因为它自动与现有网络 API 和接口协议兼容,因此可以使用现有的 API 和驱动程序。一个 FPGA 增强型智能网卡设计中的板载 FPGA 能够显著提高性能和扩展功能。
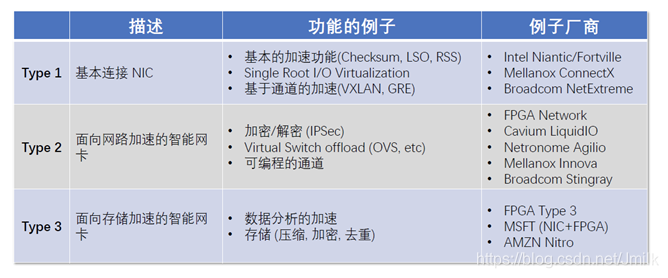
面向网络加速的 Smart NIC
以 FPGA 来实现 Smart NIC 举例,了解到底有什么网络功能任务是可以 Offload 到 Smart NIC 上进行处理的。并且,使用 FPGA 可以根据需要轻松添加、或删除这些功能。
示例 1 到 13 说明了可以添加到 base NIC 的处理元素,以创建功能更加强大的 Smart NIC。
1、base NIC。采用多个 Ethernet MAC 和一个用于 Host CPU 接口的 PCIe Block。Host CPU 必须处理所有的 Ethernet 通信,包括主动的从 NIC 的存储器读取 pkts。
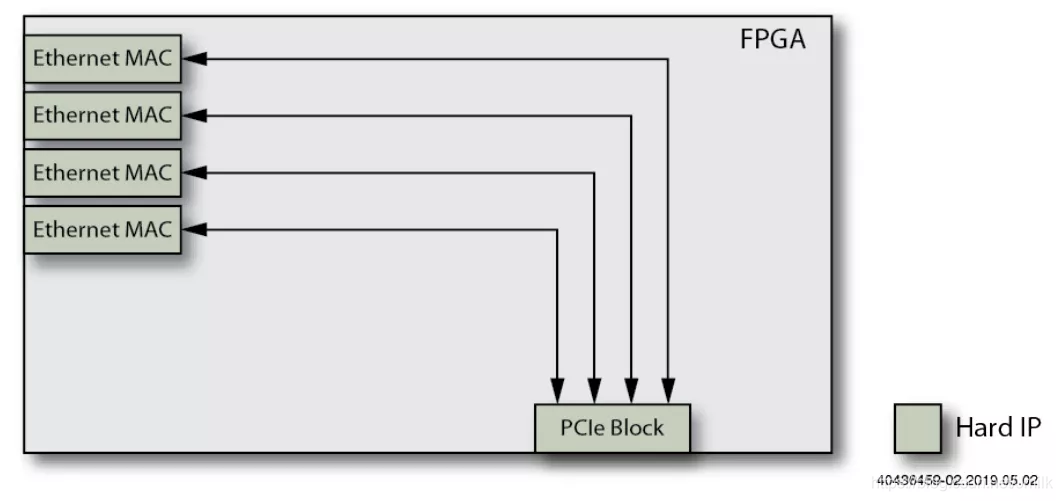
2、添加 DMA Engine 功能。NIC 的存储器 Mapping 到 Memory,CPU 可以直接从 Memory 读取 pkts,而不需要从 NIC 存储器中 Copy,从而减少了 Host CPU 的工作负载。
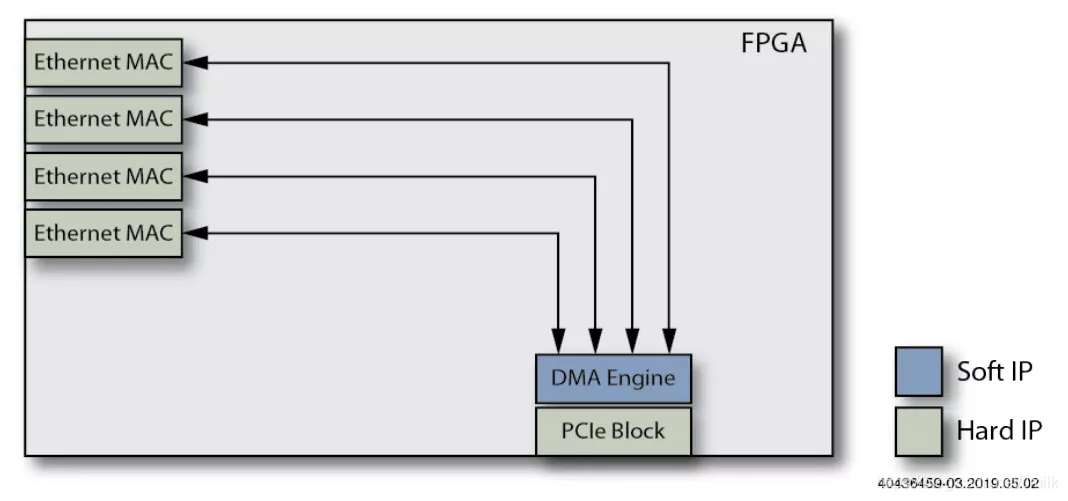
3、添加 Filter Engine 功能。过滤器会阻止无需 Host CPU 处理的 pkts,进一步减少了 Host CPU 的任务负载。
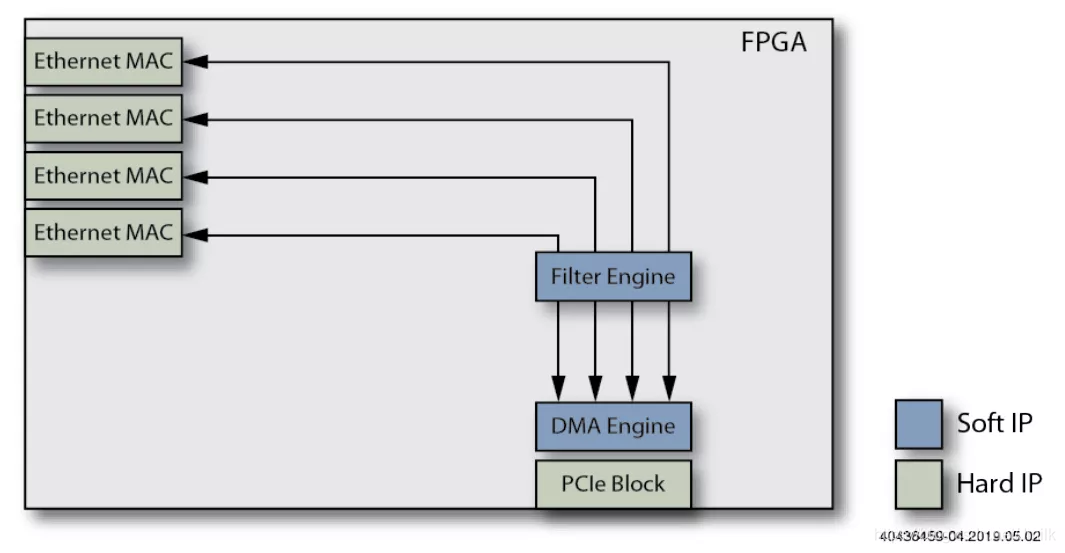
4、添加外部 DRAM 到 Filter Engine。外部 DRAM 用于存储 Filter Engine 的 Rules,有了足够的外部 DRAM,NIC 可以管理数百万条规则。
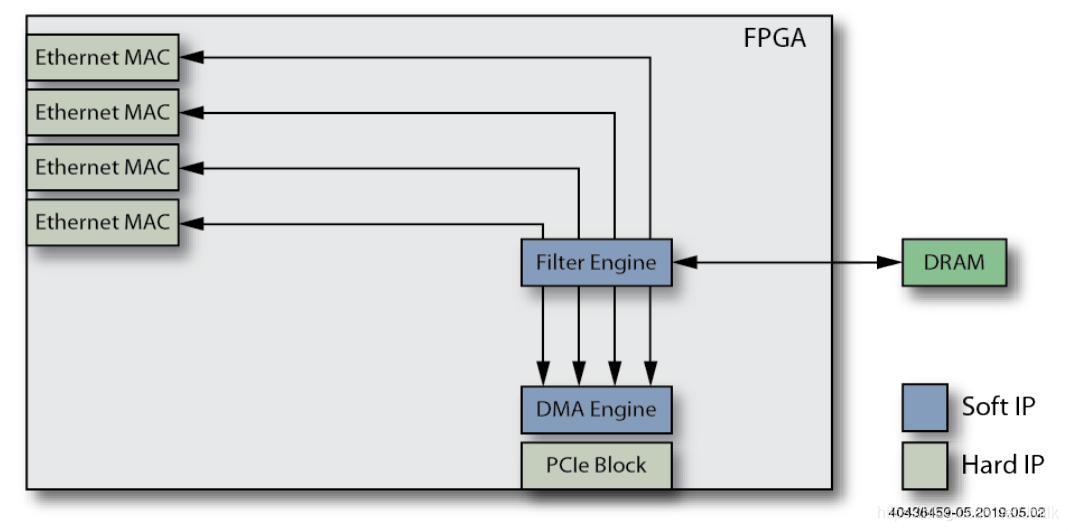
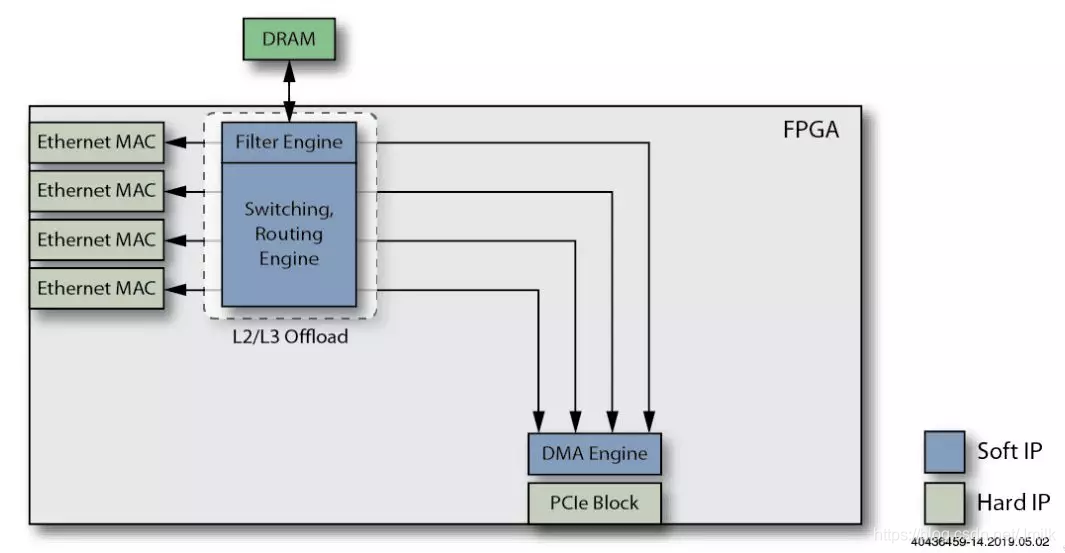
5、添加 L2/L3 Offload Engine 功能。用于处理 NIC 的 Ethernet Ports 之间的低层 L2 交换和 L3 路由,进一步减少 Host CPU 的工作负载。同样的,可以为 L2/L3 Offload Engine 共用外部 DRAM 来缓冲网络数据包。
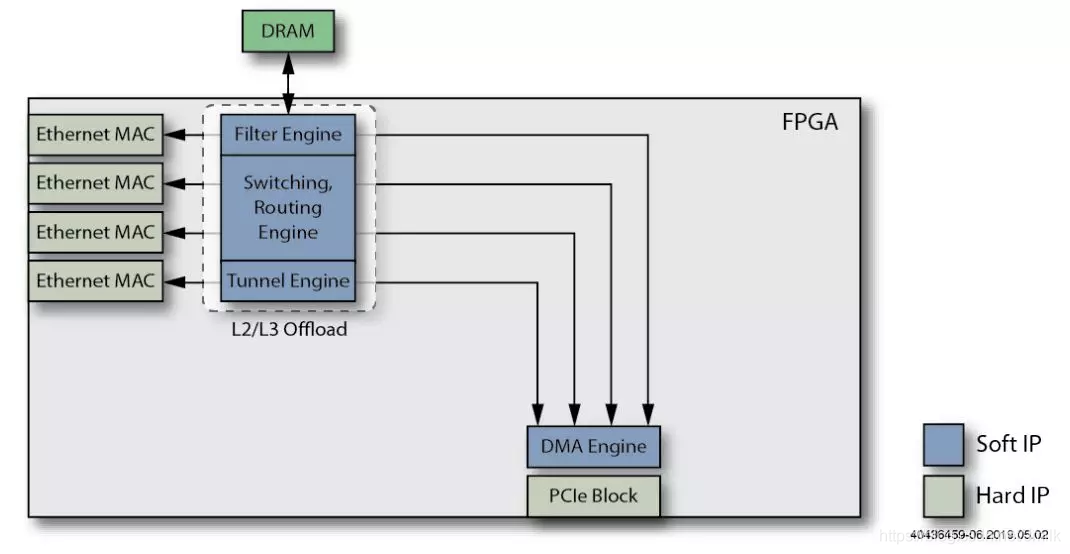
6、添加 Tunnel Offload Engine 功能。用于卸载各种隧道协议封包(e.g. VxLAN、GRE),并进一步减轻 Host CPU 的周期密集型隧道性需求。
7、添加 Deep Buffering(深度缓冲)外部存储。用于对输入的 pkts 进行深度缓冲,从而实现了线速数据包交换和具有多个队列的分层 QoS 调度。
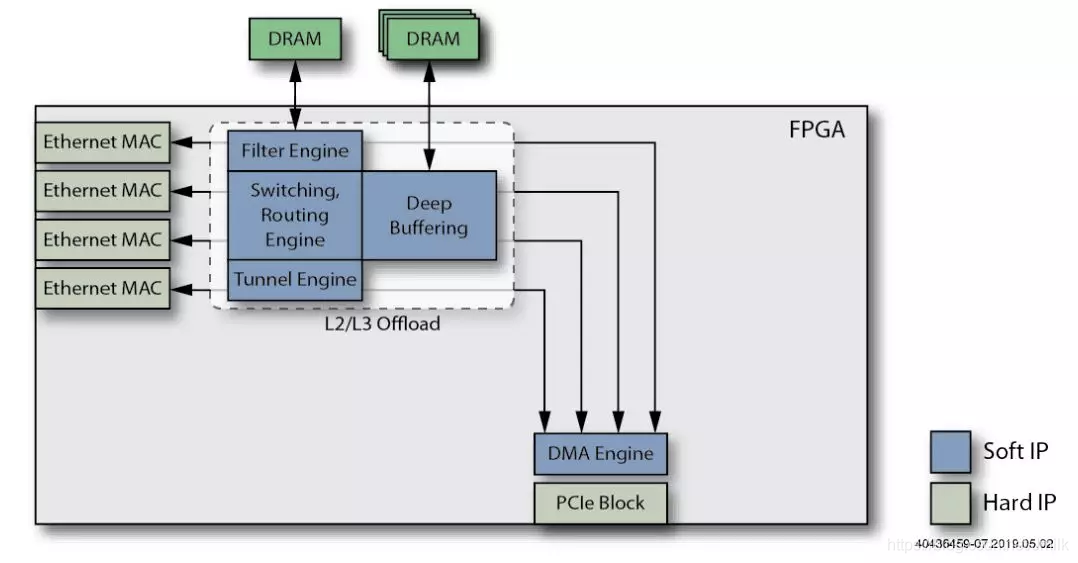
8、添加一个具有自己的外部 DRAM 存储的 Flows Engine 功能。使 Smart NIC 的 Routing Engine 能够处理数百万个路由表条目,同时还有助于卸载 NAT/PAT 网络能力。
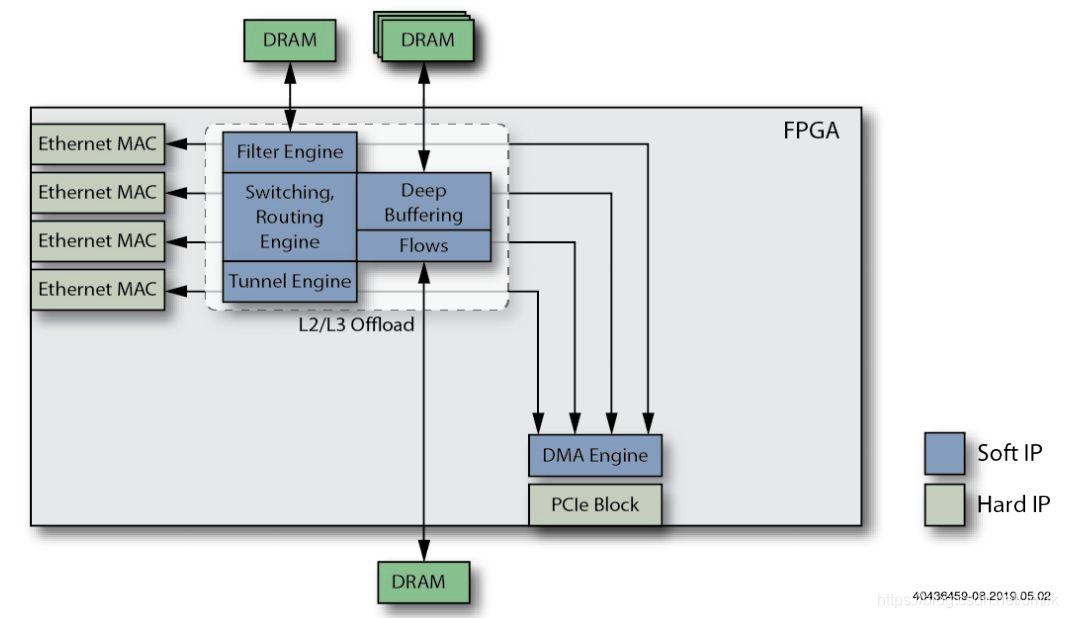
9、添加 TCP Offload Engine 功能。用于处理 TCP 协议的全部或部分工作,这样可以在不消耗更多 CPU 周期的情况下提高 Smart NIC 性能。

10、添加 Security Offload Engine 功能。将部分/全部安全引擎添加到 Smart NIC 中,以每个 Flows 为基础从 Host CPU 卸载加密/解密任务。

11、添加 QoS Engine 功能。Smart NIC 以此提供 SLA(服务等级协议)功能,而无需 Host CPU 的干预。
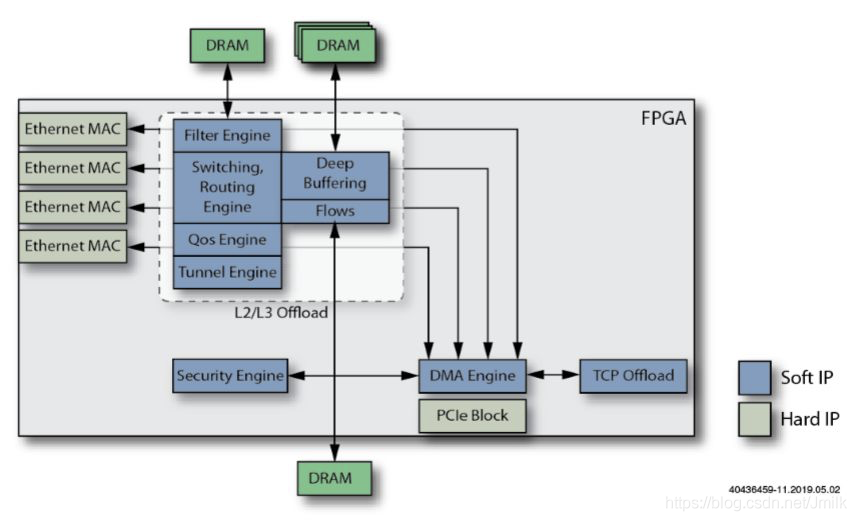
12、添加一个可编程的数据包解码器。该解码器将类似 P4 的可编程功能集成到 Smart NIC 中。P4 是一种标准的网络编程语言,专门用于描述和编程分组数据包转发面的操作。
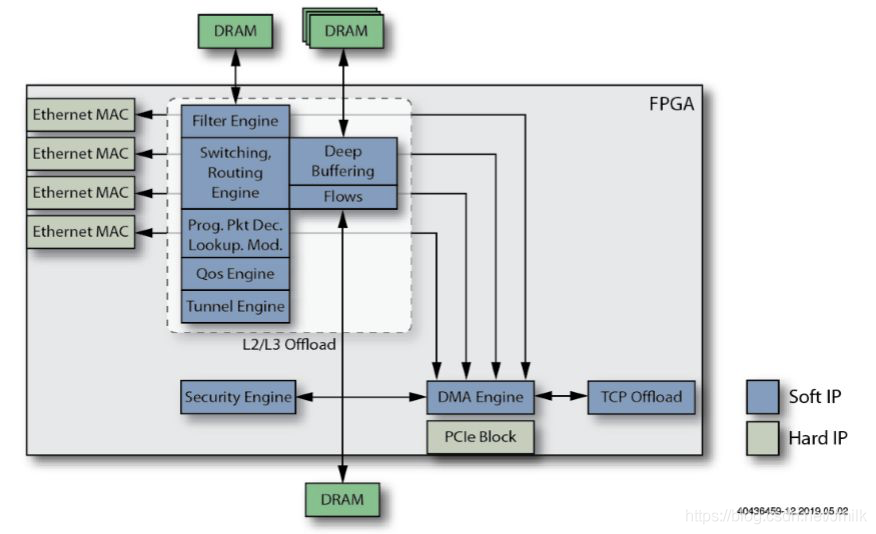
13、添加一个或多个 ASIC 板载处理器。它们为 Smart NIC 提供了完整的软件可编程性(用于诸如 OAM 等任务),进一步实现了 Host CPU 的任务卸载。
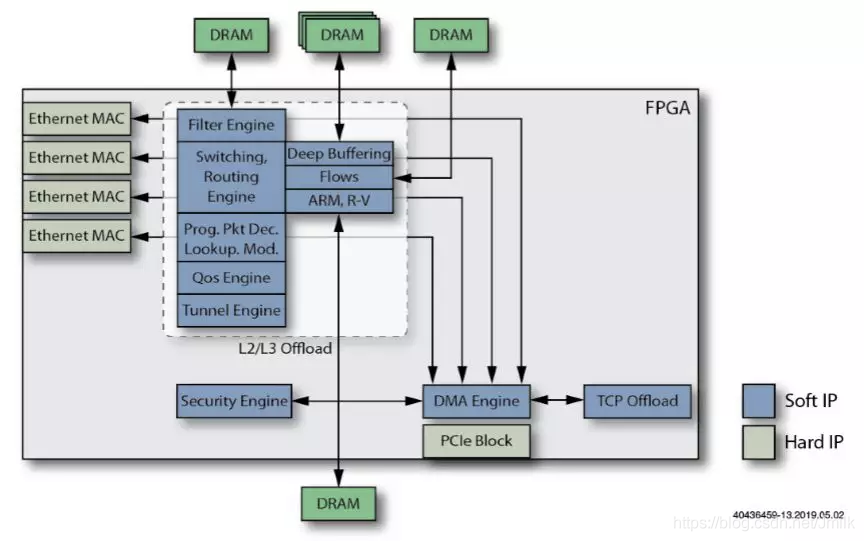
可见,Smart NIC 为面向 SDN、NFV 的云计算/数据中心带来的优势主要有:
CPU(昂贵)资源的节约。
NIC 数据处理性能(网络带宽、吞吐量)的提升。
面向存储加速的 Smart NIC
在虚拟化爆发之前,大多数服务器只是运行本地存储,这虽然不是很高效,但是很容易使用。然后是网络存储的兴起:SAN、NAS、NVMe-oF(NVMe over Fabrics)。
但是,并非每个应用程序都可识别 SAN,并且某些操作系统和虚拟机管理程序(e.g. Windows 和 VMware)尚不支持 NVMe-oF。SmartNIC 可以虚拟化网络存储,效率更高、更易于管理,且应用程序更易于使用。
面向超融合基础设施的 Smart NIC
超融合基础设施使用了 VMM 来虚拟化本地存储和网络,以使其可用到群集中的其他服务器或客户端,能够实现快速部署,有利于共享存储资源。但是 VMM 占用了本应用于运行应用程序的 CPU 周期。与标准服务器一样,网络运行的速度越快,存储设备的速度越快,则必须投入更多的 CPU 来虚拟化这些资源。
SmartNIC 一方面可以卸载并帮助虚拟化网络,用于加速私有云和公共云,这就是为什么它们有时被称为 CloudNIC 的原因;另一方面可以卸载网络和大部分的存储虚拟化,可以减轻 SDS 和 HCI 的功能负担,例如:压缩、加密、重复数据删除、RAID、报告等。SmartNIC 甚至可以虚拟化 GPU 或其他神经网络处理器,这样任何服务器都可以在需要的时候通过网络访问任意数量的 GPU。
超融合架构数据中心中,Smart NIC 为 SDN 和虚拟化应用程序提供硬件加速与网络接口紧密结合,并可分布在大型服务器网络中,减小 CPU 负载,提供额外的边缘计算能力,加速特定应用和虚拟化功能,并且通过正确的语言和工具链支持,为用户提供应用加速即服务的附加价值。
赛灵思
赛灵思发布了其首款一体化 SmartNIC 平台 Alveo U25,在单张卡上上实现了网络、存储和计算加速功能的融合。

随着网络端口速度不断攀升,2 级和 3 级云服务提供商、电信和私有云数据中心运营商正面临日益严峻的联网问题和联网成本挑战。与此同时,开发和部署 SmartNIC 所需的大量研发投资,也成为其被广泛采用的障碍。
依托于赛灵思业界领先的 FPGA 技术,Alveo U25 SmartNIC 平台相比基于 SoC 的 NIC,可以提供更高的吞吐量和更强大的灵活应变引擎,支持云架构师快速为多种类型的功能与应用提速。
Intel
2015 年 6 月,Intel 宣布以 167 亿美元的价格收购全球第二大 FPGA 厂商 Altera,成为该公司有史以来最贵的一笔收购,随后 Intel 也在 Altera 的基础上成立了 Intel 可编程事业部,且一直在推进 FPGA 与至强处理器的软硬件结合,但却并没有能够进入大规模商用阶段。
三年后,Intel 终于踏出了历史性的一步。2019 年 4 月 19 日,Intel 宣布旗下的 FGPA 已经被正式应用于主流的数据中心 OEM 厂商中。具体来说,戴尔 EMC PowerEdge R640、R740 和 R740XD 服务器集成了 Intel FPGA ,并且已经可以进行大规模部署;而富士通即将发布的 PRIMERGY RX2540 M4 也采用了 Intel FGPA 的加成,这款产品即将发布,并已经支持重点客户提前使用。

上述 FGPA 主要指的是 Intel Arria 10 GX PAC(Programmable Acceleration Card,可编程加速卡),同时 Intel 还为 OME 厂商提供一个面向包含 FPGA 的 Intel 至强可扩展处理器的 Intel 加速堆栈。二者结合起来,就形成了一个完整的硬软件结合 FPGA 解决方案。
近期推出的 FPGA SmartNIC C5000X 云平台就是基于 Intel Xeon-D 处理器和 Intel Stratix 10 FPGA 实现的。
Intel X800 系列
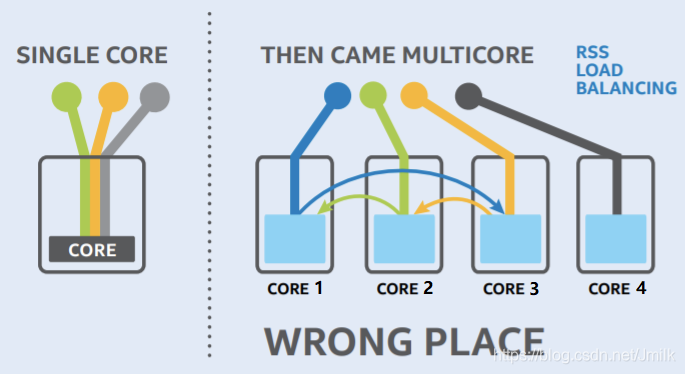
在 CPU 单核时代,数据包经由网卡接收后均被送往唯一的 CPU 进行处理。随着多核时代到来,就出现了负载均衡问题,例如:某些 Core 过载,而另一些 Core 空载的情况。
为解决该问题,RSS(Receive Side Scaling)技术先通过 HASH 操作将数据包发送到不同的 Core 上进行中断处理,然后再经由 Core 间转发将数据包发送到运行目的应用所在的 Core 上。虽然负载看似在多 Core 上均衡了,但由于 HASH 的抗碰撞特性,大量数据包会被送到了不匹配的 Core上,因而数据包的 Core 间转发成为性能瓶颈。
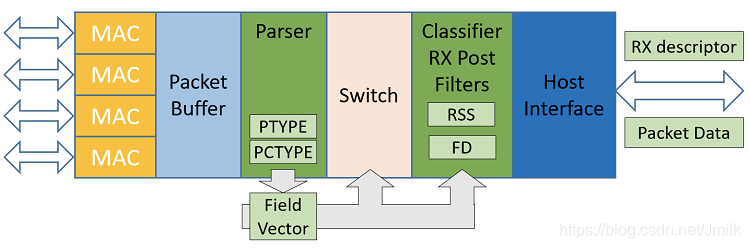
FDIR(Intel Ethernet Flow Director)通过将数据包定向发送到对应应用所在 Core 上,从而弥补了 RSS 的不足,可用来加速数据包到目的应用处理的过程。在新一代 Intel X800 系列 Smart NIC 中,FDIR 有了更多的 Rules 空间硬件资源和更灵活的配置机制。
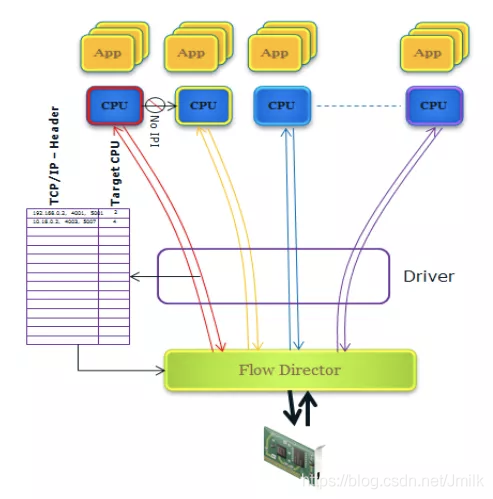
如同 Linux 提供了纯软件实现的 RSS 版本一样,Linux 也提供了纯软件实现的 ATR(Application Targeting Routing)模式的 Flow Director,称为 RFS(Receive Flow Steering)。尽管功能上等效,但是 RFS 无法达到 FDIR 对网络性能的提升效果,因为它必须通过某个 Core 来执行调度数据包,而且该 Core 大概率不是目的应用所在的 Core。因此,ATR 模式的 FDIR 可被看作 RFS 的智能卸载硬件加速方案。
迈络思
2019 年英伟达收购以色列著名网络设备制造商 Mellanox。Mellanox 是端到端以太网和 InfiniBand 智能互联技术的绝对领导者。在收购之前 Mellanox 就已推出了多款智能网卡。

NVIDIA Mellanox ConnectX-6 Lx SmartNIC
NVIDIA Mellanox ConnectX-6 Lx SmartNIC,是一款高效且高度安全的 25、50Gb/s 以太智能网卡。这款产品专为满足现代化数据中心的需求而设计,在这个市场,25Gb/s 已成为各种主流应用的标准,例如:企业级应用、AI 和实时分析等。这款全新的 SmartNIC 充分利用了软件定义、硬件加速的引擎来扩展加速计算,将更多的安全和网络处理工作从 CPU 卸载到网卡上来。
Mellanox ConnectX-6 Lx 提供:
两个 25Gb/s 端口或一个 50Gb/s 端口、从主机到网络之间采用 PCIe Gen 3.0 或 4.0 x8。
安全功能,包括硬件信任根(Hardware Root of Trust)、用于有状态 L4 防火墙的连接追踪(Connection Tracking)技术。
IPSec 在线加密加速。
GPU Direct RDMA 加速技术,专为 NVMe over Fabrics(NVMe-oF)存储、可扩展加速计算和高速视频传输等应用加速。
Zero Touch RoCE(ZTR)功能,实现了高性能 RoCE(RDMA over converged Ethernet)网络的可扩展和易部署,且无需配置交换机。
加速交换和数据包处理(Accelerated switching and packet processing ,ASAP2)技术,内置面向虚拟化和容器化应用的 SR-IOV 和 VirtIO 硬件卸载引擎,可加速新一代软件定义网络,以及对于防火墙服务进行连接追踪。

博通
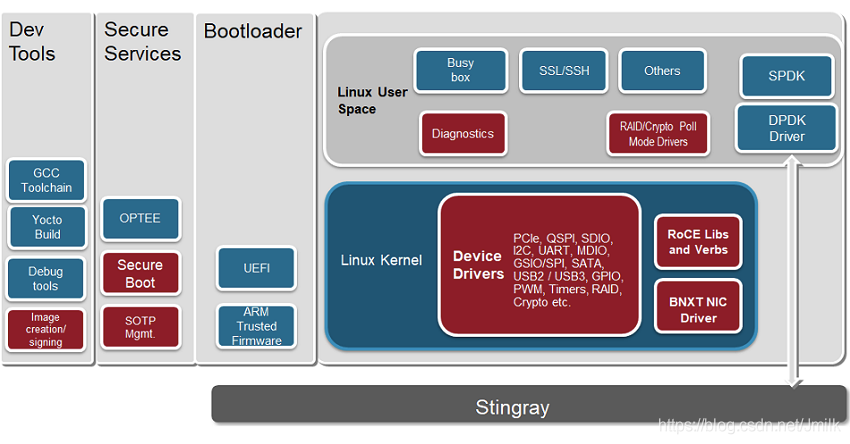
博通的 Stingray SmartNIC SoC 系列具有集成的全功能 100G NIC,强大的 8 核 CPU,运行在 3GHz 下,支持数据包处理、加密、RAID 和重复数据删除等硬件引擎,是用于主机卸载、裸机服务和网络功能虚拟化的理想 SmartNIC 解决方案。
今年 4 月,百度云宣布正在与博通紧密合作,利用 Stingray SmartNIC 的可编程性,提供高级的云原生应用、网络功能虚拟化和分布式安全。博通的 Stingray 适配器提供 8 个 ARM A72 CPU 内核,运行在 3GHz、300G 内存带宽和 100G NetXtreme Ethernet 网卡上。
一众公有云厂商
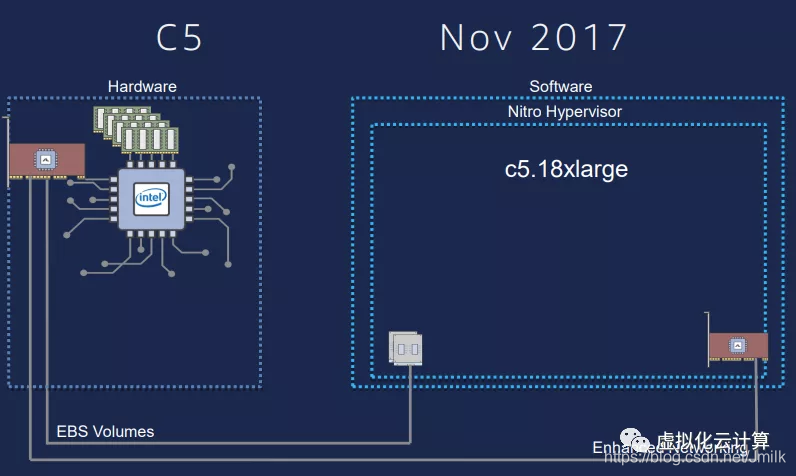
2015 年,AWS 收购以色列芯片制造商 Annapurna Labs。在 2017 re: Invernt 大会上,AWS 宣布了 EC2 架构的新演进:Nitro System 架构。Nitro System 重新定义了虚拟化基础架构,将虚拟化功能被卸载到专用的 Nitro Card 上。而 Nitro Card 就是使用 Annapurna Labs 定制的 ASIC 芯片。
2015 年,微软 Azure 服务器上部署了其 FPGA 加速网络 AccelNet。自 2015 年底以来,微软已在超过 100 万台主机的新 Azure 服务器上部署了实施 AccelNet 的 Azure SmartNIC。自 2016 年以来,AccelNet 服务已向 Azure 客户提供了一致的 <15μs VM-VM TCP 延迟,和 32Gbps 吞吐量。
2017 年,阿里云也在数据中心中部署了神龙。
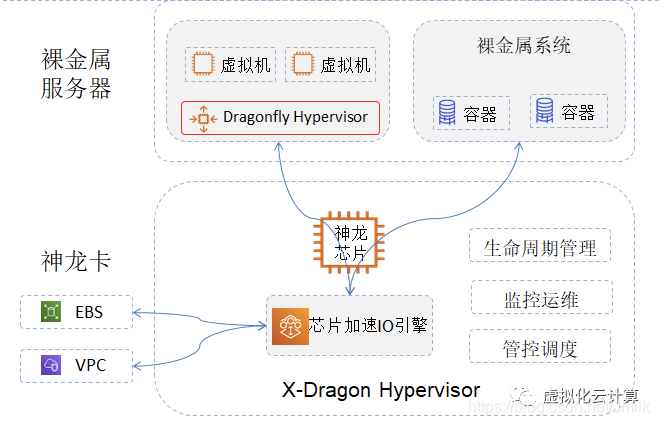
与传统的智能网卡厂家比,云计算巨头完全是为了满足自身云计算需求。在他们看来,SmartNIC 就是一个完整的计算、存储、网络一体化处理单元,只视乎于想把如何具体的业务卸载下来,而具体业务只有使用云厂商自己最清楚了。
因此,对云厂商来说,自研 SmartNIC 似乎是一条正确的道路,其 “智能网卡” 的概念已经很薄弱了,它不仅仅是个 NIC 这么简单,它已经深深的融入他们的血液里了。
来源:SDNLAB
往期推荐
关注「开源Linux」加星标,提升IT技能
