
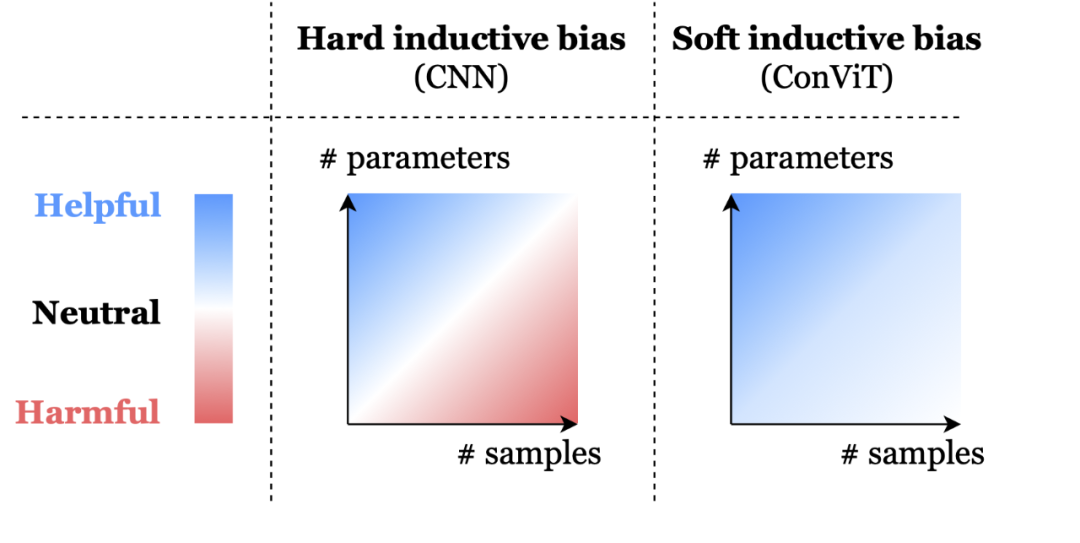
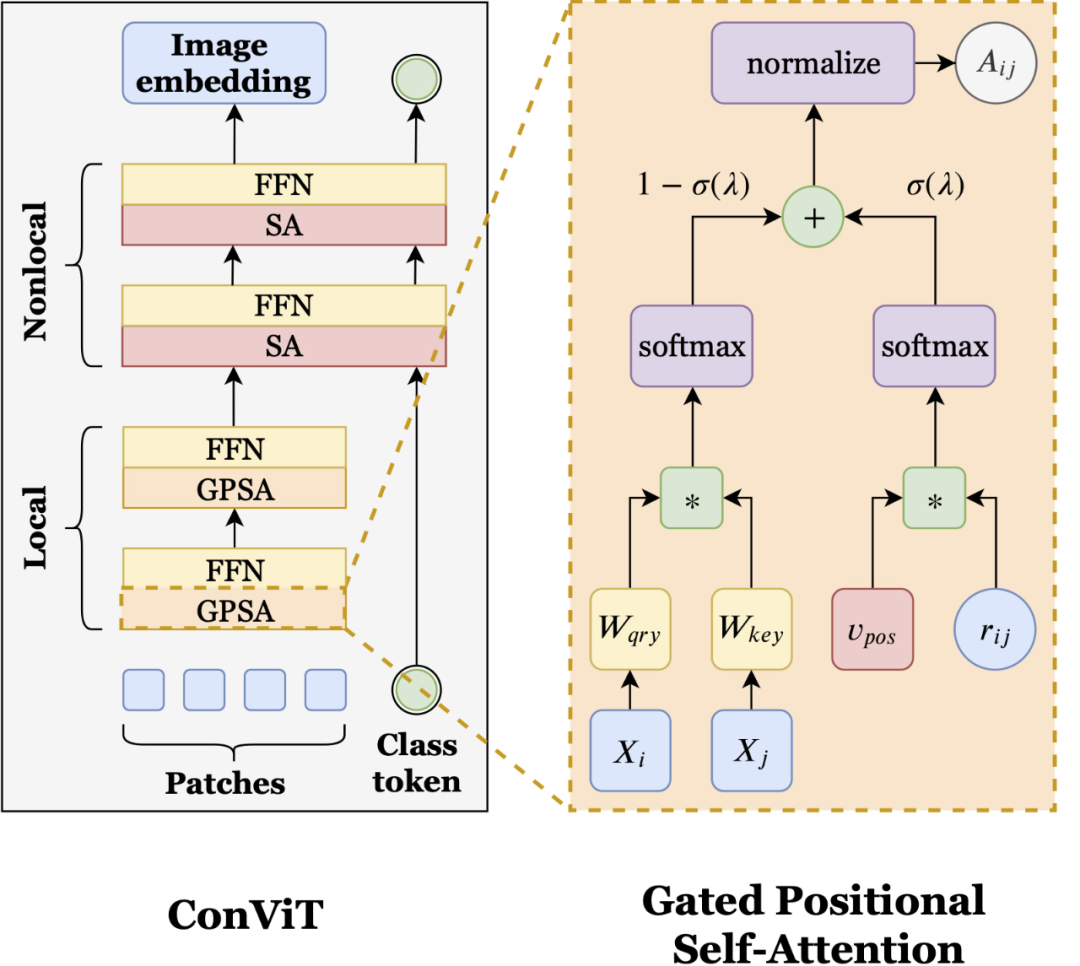
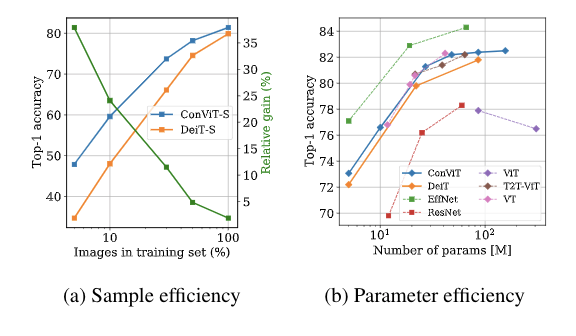
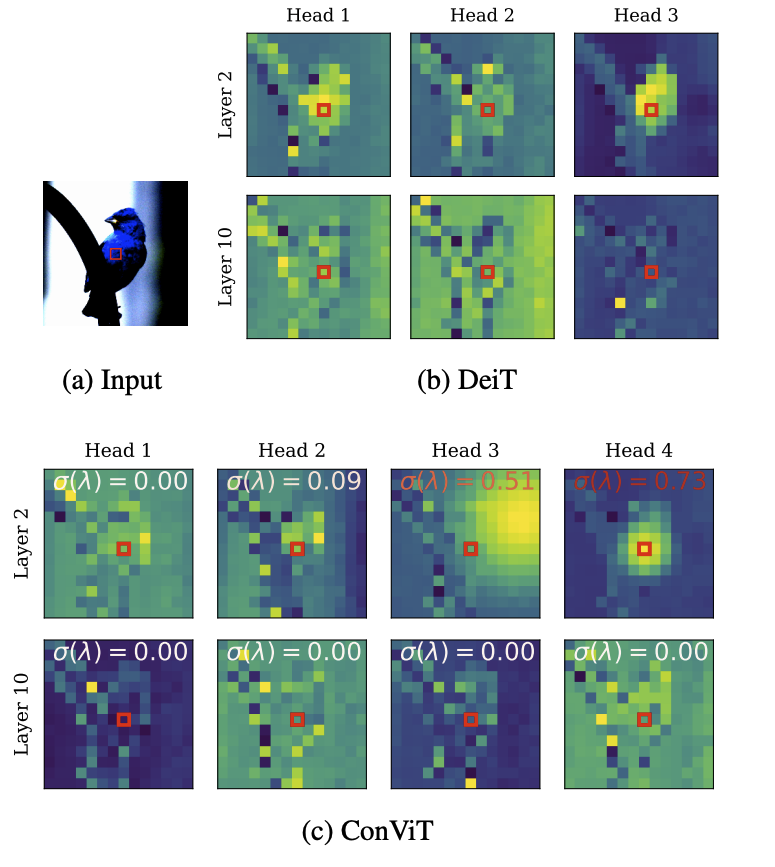
兼具CNN和Transformer优势,灵活使用归纳偏置,Facebook提出ConViT
视学算法
共 2629字,需浏览 6分钟
· 2021-07-18
点击上方“视学算法”,选择加"星标"或“置顶”
重磅干货,第一时间送达

论文地址:
https://arxiv.org/pdf/2103.10697.pdf
GitHub 地址:
https://github.com/facebookresearch/convit
特别鸣谢
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。

点个在看 paper不断!
评论