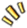服务端思维
服务端思维




点击上方“服务端思维”,选择“设为星标”
回复”669“获取独家整理的精选资料集
回复”加群“加入全国服务端高端社群「后端圈」

JVM 预热是一个非常头疼而又难解决的问题。本文讨论了在运行在 Kubernetes 集群中的 Java 服务如何解决 JVM 预热问题的一些方法和经验。
在这篇文章中,我们将讨论在运行在 Kubernetes 集群中的 Java 服务如何解决 JVM 预热问题的经验。
起因
几年前,我们逐步从整体中分离出服务,开始在 Kubernetes 上进行迁移到基于微服务的体系结构。大多数新服务都是在 Java 中开发的。当我们在印度市场上运行一个这样的服务时,我们第一次遇到了这个问题。我们通过负载测试进行了通常的容量规划过程,并确定 N 个 Pod 足以处理超过预期的峰值流量。
与此同时,我们开始收到来自部署时间段内的大量投诉,几乎都关于高响应时间和超时错误。
第一步:花钱解决问题
我们很快意识到这个问题与 JVM 预热阶段有关,但当时有其他的重要事情,因此我们没有太多时间进行调查,直接尝试了最简单的解决方案——增加 Pod 数量,以减少每个 Pod 的吞吐量。我们将 Pod 数量增加了近三倍,以便每个 Pod 在峰值处理约 4k RPM 的吞吐量。我们还调整了部署策略,以确保一次最多滚动更新 25%(使用 maxSurge 和 maxUnavailable 参数)。这样就解决了问题,尽管我们的运行容量是稳定状态所需容量的 3 倍,但我们能够在我们的服务中或任何相关服务中没有问题地进行部署。
随着后面几个月里更多的迁移服务,我们开始在其他服务中常常看到这个问题。因此我们决定花一些时间来调查这个问题并找到更好的解决方案。
第二步:预热脚本
在仔细阅读了各种文章后,我们决定尝试一下预热脚本。我们的想法是运行一个预热脚本,向服务发送几分钟的综合请求,来完成 JVM 预热,然后再允许实际流量通过。
initialDelaySeconds,以确保预热脚本在 Pod 为 ready 并开始接受流量之前完成。令人吃惊的是,尽管结果有一些改进,但并不显著。我们仍然经常观察到高响应时间和错误。此外,预热脚本还带来了新的问题。之前,Pod 可以在 40-50 秒内准备就绪,但用了脚本,它们大约需要 3 分钟,这在部署期间成为了一个问题,更别说在自动伸缩期间。我们在预热机制上做了一些调整,比如允许预热脚本和实际流量有一个短暂的重叠期,但也没有看到显著的改进。最后,我们认为预热脚本的收益太小了,决定放弃。
第三步:启发式发现
由于预热脚本想法失败了,我们决定尝试一些启发式技术-
GC(G1、CMS 和 并行)和各种 GC 参数 堆内存 CPU 分配


container_cpu_cfs_throttled_seconds_total 表示这个 Pod 从开始到现在限制了多少秒 CPU。如果我们用 1000m 配置观察这个指标,应该会在开始时看到很多节流,然后在几分钟后稳定下来。我们使用该配置进行了部署,这是 Prometheus 中所有 Pod 的 container_cpu_cfs_throttled_seconds_total 图: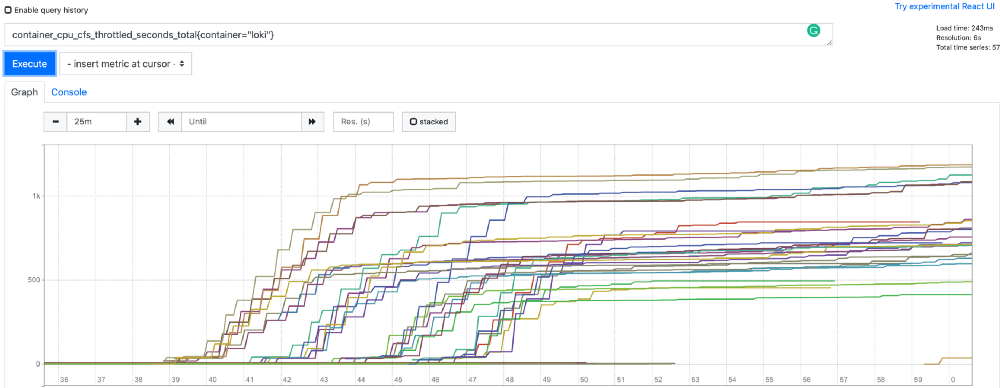
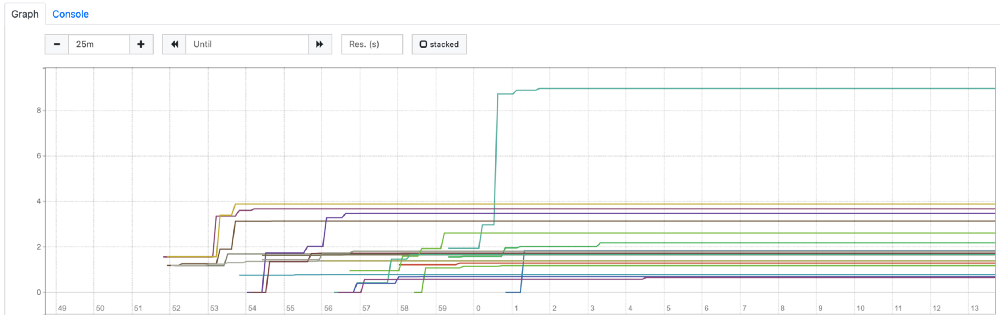
CPU 节流几乎可以忽略不计(几乎所有 Pod 都不到 4 秒)。
第四步:改进
尽管我们发现了这个问题的根本,但就成本而言,该解决方案并不太理想。因为有这个问题的大多数服务都已经有类似的资源配置,并且在 Pod 数量上超额配置,以避免部署失败,但是没有一个团队有将 CPU 的 request、limits 增加三倍并相应减少 Pod 数量的想法。这种解决方案实际上可能比运行更多的 Pod 更糟糕,因为 Kubernetes 会根据 request 调度 Pod,找到具有 3 个空闲 CPU 容量的节点比找到具有 1 个空闲 CPU 的节点要困难得多。它可能导致集群自动伸缩器频繁触发,从而向集群添加更多节点。
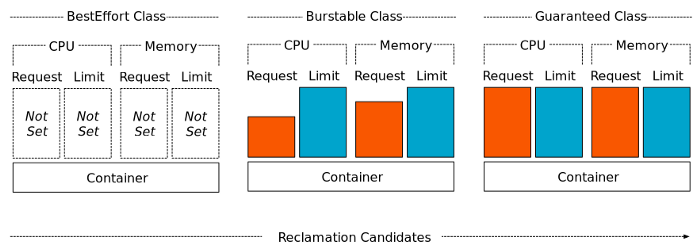
在最初的预热阶段(持续几分钟),JVM 需要比配置的 limits(1000m)更多的 CPU(大约 3000m)。预热后,即使 CPU limits 为 1000m,JVM 也可以充分发挥其潜力。Kubernetes 会使用 request 而不是 limits 来调度 Pod。我们清楚地了解问题后,答案就出现了——Kubernetes Burstable QoS。

container_cpu_cfs_throttled_seconds_total 指标,以下是其中一个 Deployment 的图表: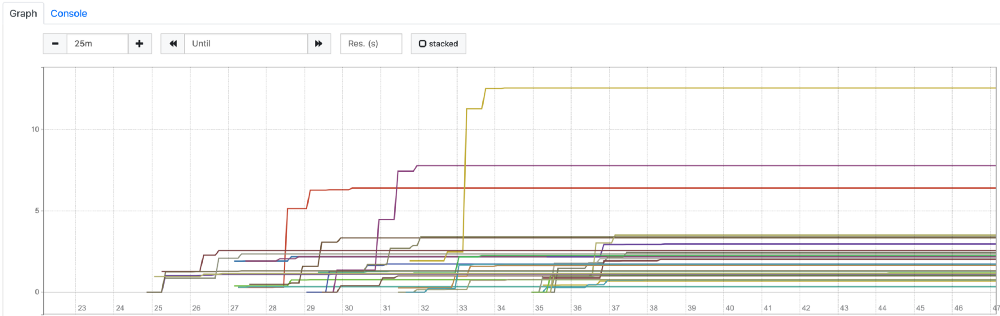
正如我们所看到的,这张图与 3000m CPU 的 Guaranteed QoS 设置非常相似。节流几乎可以忽略不计,它证实了具有 Burstable QoS 的解决方案是有效的。
为了使 Burstable QoS 解决方案正常工作,节点上需要有可用的冗余资源。这可以通过两种方式验证:
就 CPU 而言,节点资源未完全耗尽; 工作负载未使用 request 的 100% CPU。
结论
尽管花了一些时间,最终找到了一个成本效益高的解决方案。Kubernetes 资源限制是一个重要的概念。我们在所有基于 Java 的服务中实现了该解决方案,部署和自动扩展都运行良好,没有任何问题。
要点:
在为应用程序设置资源限制时要仔细考虑。花些时间了解应用程序的工作负载并相应地设置 request 和 limits。了解设置资源限制和各种 QoS 类的含义。 通过 monitoring/alertingcontainer_cpu_cfs_throttled_seconds_total来关注 CPU 节流。如果观察到过多的节流,可以调整资源限制。使用 Burstable QoS 时,确保在 request 中指定了稳定状态所需的容量。
— 本文结束 —


关注我,回复 「加群」 加入各种主题讨论群。
对「服务端思维」有期待,请在文末点个在看
喜欢这篇文章,欢迎转发、分享朋友圈