 云原生实验室
云原生实验室





吃饱了撑的,尝试一下 Prometheus 在 K3S 集群外抓取集群内指标的若干姿势。
背景
前一阵子收了块树莓派 4,顺手在上面搭了一个单节点的 K3S[1]. 几个月前在家里的服务器上搭过一个 Prometheus 的实例,于是就决定研究下如何在集群外收集 K3S 集群内 Pod 的指标。
先上一个简单的网络拓扑图: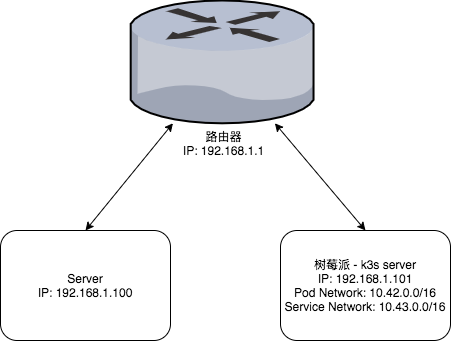
众所周知(?),Pod Network 和 Node Network 是两个不同的网段,所以在 Node 之外是无法直接访问到 Pod 的。所以我们需要通过一些方法,让我们直接或间接地访问 Pod 中提供的 HTTP 接口,进而完成指标抓取。
我们在 k3s 集群中部署了一个暴露接口的 Deployment 用于指标抓取测试,它的指标端点为 http://localhost/metrics.
Deployment 配置如下:
apiVersion: apps/v1
kind: Deployment
metadata:
name: promtest
namespace: default
spec:
selector:
matchLabels:
app: promtest
replicas: 1
template:
metadata:
labels:
app: promtest
annotations:
prometheus.io/scrape: "true"
spec:
containers:
- name: main
image: prometheus-test:v0.1
command: ["/bin/promtest"]
args: ["-listen", "0.0.0.0:80"]
ports:
- containerPort: 80
NodePort Service
最简单、最直观的方法,是将 metrics endpoint 通过 NodePort Service 或 Ingress 暴露出来,然后在 Prometheus 中通过配置 static_config 来抓取。
比如我们可以配置如下的 Service 和 Ingress:
apiVersion: v1
kind: Service
metadata:
name: promtest
namespace: default
labels:
app: promtest
annotations:
prometheus.io/scrape: "true"
spec:
selector:
app: promtest
ports:
- protocol: TCP
port: 80
targetPort: 80
type: NodePort
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: promtest
namespace: default
spec:
rules:
- host: promtest.k3s
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: promtest
port:
number: 80
部署后查看 Service 的 NodePort(如 30080),则可以通过 Node 的端口访问到指标端点(也就是 http://192.168.1.101:30080/metrics);类似的,通过配置的 Ingress 也可以正常访问(http://promtest.k3s/metrics)。
Prometheus 抓取规则如下:
job_name: "exported-services"
static_configs:
- targets:
- 192.168.1.101:30080 # NodePort
- promtest.k3s # Ingress
这种方式部署比较直观简单,但缺陷也比较明显:
由于抓取规则都是静态的,所以不能做服务发现; 每添加一个 Deployment,需要配置对应的 Service 来暴露指标; Service 自带负载均衡,所以如果 Service 背后的 Endpoint 有多个,那么多次抓取的数据来源则可能是 Serivce 背后的任意一个 Pod,而且我们也无法对来源进行区分。因此,当我们分析业务指标时,通常都会通过服务发现来抓取所有 Pod 的指标,然后通过 PromQL 根据实际场景对指标进行聚合。
Kubernetes API Proxy
这种方式略微有点奇怪:使用 K8S 提供的 pod/service proxy 接口[2],通过代理来访问集群内的 Pod 指标端点.
假设 K8S API 地址为 https://k3s:6443,那么当我们想访问 Service proxy 时,就可以通过 https://k3s:6443/api/v1/namespaces/<namespace>/services/<service_name>[:<service_port>]/proxy/metrics 来获取。相应地,抓取 Pod 指标时,对应的 API 地址为 https://k8s:6443/api/v1/namespaces/<namespace>/pods/<pod_name>[:<pod_port>]/proxy/metrics
与 K8S API 进行交互时,需要首先配置身份信息。通常我们可以通过两种方式来访问:
HTTPS 客户端证书,一般情况下人类用户会通过这种方式来访问; 不提供 HTTPS 客户端证书,但在 HTTP 会话中通过 Bearer Token 的方式提供 ServiceAccount 的 JWT Token,而这通常是集群内的程序访问 K8S API 的方式。
Prometheus 对这两种方式均提供了支持,不过我还是选择了配置 ServiceAccount 来与 K8S 交互。
配置 ServiceAccount 及对应的 RBAC 策略
为了完成 K8S 身份认证以及接口鉴权,我们需要配置以下资源:
ServiceAccount,用于身份认证;ClusterRole,定义角色和权限;ClusterRoleBinding,将ClusterRole的权限赋予ServiceAccount.
Prometheus Operator 文档[3] 中提供了一套完整的 Service Account 和 RBAC 配置示例,用于进行服务发现。由于我们还需要调用 service 和 pod 的 proxy 接口,所以我们还需要额外添加两个 API 权限:
- apiGroups: [""]
resources:
- services/proxy
- pods/proxy
verbs: ["get"]
配置好 ServiceAccount 后,我们可以从名为 <service_account_name>_token 的 Secret 中获取用于身份验证的 JWT Token.
配置服务发现和抓取规则
如果 Serivce 或 Pod 名是已经确定好的,那么可以直接通过配置 static_config 来进行抓取;但如果用到了 K8S 的服务发现,那么我们还需要通过服务发现的元信息来确定指标抓取的目标地址。
`relabel_config` 配置[4]中,有几个特殊的 label,可以用来给我们动态配置抓取的地址和协议,它们分别是:
__address__,用于配置目标地址的 host 和端口;__metrics_path__,用于配置目标地址的路径;__scheme__,用于配置抓取时使用的协议(http 或 https);__params_<name>,用于在抓取的 URL 中注入 query.
有了这几个标签,我们就可以通过一定的规则来拼凑出目标地址了。
具体抓取规则如下:
job_name: 'k3s-pod-via-api'
scheme: https
tls_config:
insecure_skip_verify: true # 跳过服务器证书验证,当然也可以用 ca_file 配置服务器证书
authorization:
credentials_file: /etc/prometheus/k8s_token # 文件中存有 ServiceAccount token
kubernetes_sd_configs: # 服务发现配置
- api_server: https://k3s:6443 # K8S API 地址
role: pod
tls_config: # 这部分跟上面差不多
insecure_skip_verify: true
authorization:
credentials_file: /etc/prometheus/k8s_token
namespaces: # 可选的 namespace 配置
names:
- default
selectors: # 可选的 label selector
- role: pod
label: "app=promtest"
relabel_configs:
# 只抓取包含 `prometheus.io/scrape: true` annotation 的 Pod
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: 'true'
# 如果定义了 `prometheus.io/port` 注解,则用它覆盖 Pod 定义中的端口号
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: (\d+)
replacement: $1
target_label: __meta_kubernetes_pod_container_port_number
# 动态构建 K8S proxy API 地址
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_pod_name, __meta_kubernetes_pod_container_port_number]
action: replace
regex: (.+);(.+);(.+)
replacement: api/v1/namespaces/$1/pods/$2:$3/proxy/metrics
target_label: __metrics_path__
# 通过 `prometheus.io/path` 注解自定义抓取路径
- source_labels: [__metrics_path__, __meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
regex: (.+)/metrics;/?(.+)
replacement: $1/$2
target_label: __metrics_path__
# Host 和 Port 是确定的
- source_labels: []
action: replace
regex: ""
replacement: a.r8:6443
target_label: __address__
# 将一些元信息注入到 metrics 标签中
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: k8s_namespace
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: k8s_pod_name
Service 的抓取和 Pod 大同小异,只是目标地址和 meta 标签名不太一样,就不赘述了。
这种方式可以使用 K8S 的服务发现功能,但通过 proxy API 来访问 Pod,也加重了 kube-apiserver 的负担。而且,说句实话,写这种拼凑 API 地址的 relabel_config 还是挺蛋疼的。🌚
如果不使用 K8S 的 proxy API 的话,也可以简单在集群内部署一个 HTTP 反向代理,然后通过反代来抓取 Pod 或 Service 的指标。这个方案其实跟上一种差不多,只是把 kube-apiserver 的 proxy 换成了集群内的另外一个 proxy 而已,不过减轻了 kube-apiserver 的负担。考虑到安全因素,我们可以为 proxy 配置 egress NetworkPolicy 来控制它可以访问的 Pod,但这样也会使权限和选择策略变得极为分散。
打通 Node Network 和 Pod/Service Network
这种方法算是从根本上解决问题:打通 Node 和 Pod / Service 网络,这样我们就可以直接访问 Pod 或 Service 的 IP 来抓取指标。
打通网络的操作主要参考了两篇文章:《办公环境下 kubernetes 网络互通方案》[5]以及《打通 Kubernetes 内网与局域网的 N 种方法》[6],最后选择从网络层打通网络。
操作很简单,只需要在 server 中配置两条路由规则即可:
$ ip route add 10.42.0.0/16 via 192.168.1.101 dev enp1s0
$ ip route add 10.43.0.0/16 via 192.168.1.101 dev enp1s0
如果想要在局域网内打通的话,可以在路由器的管理后台来配置静态路由规则;如果集群存在多个节点,则还需在 Node 的 iptables 中配置 MASQUERADE 规则用于转发。配置完成后,Prometheus 就可以直接通过 Pod IP 或 Service 的 Cluster IP 来抓取指标了。
Pod 的抓取规则如下:
job_name: 'k3s-pod'
# 抓取时直接通过 HTTP 协议从 Pod IP 抓取,所以无需鉴权
kubernetes_sd_configs: # 服务发现配置不变
- api_server: https://k8s:6443
role: pod
tls_config:
insecure_skip_verify: true
authorization:
credentials_file: /etc/prometheus/k8s_token
relabel_configs:
# 筛选注解规则同上
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: 'true'
# 根据 `prometheus.io/path` 注解直接覆盖指标路径
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
regex: (.+)
target_label: __metrics_path__
# 根据 `prometheus.io/port` 注解覆盖端口
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
target_label: __address__
# 元信息规则同上
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: k8s_namespace
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: k8s_pod_name
Service 的抓取规则略。
可以看出,如果我们可以直接访问 Pod,那么抓取时的 relabel 规则就可以简化很多。
一个缺乏经验导致的无谓 troubleshooting
之前通过 Argo CD 安装脚本[7] 在集群内安装了 Argo CD. 当我配完上面的规则以后,我发现 argocd-metrics Service 的指标无法通过 Cluster IP 抓取(报错”Connection refused“),而 argocd-server-metrics 就可以。而在 Node 上,两个服务均可以正常访问。
查了 Node 上的 iptables 规则,没有在 Service (argocd-metrics) 到 Pod (argocd-application-controller-0) 的转发链路中发现任何异常,直接访问 Pod IP 也验证了这一点。但由于缺乏 iptables debug 经验,并没有找到访问 Pod IP 被拒绝的原因。
最后通过玄学 debug,发现 argocd namespace 的五个 Pod 里,只有一个可以正常访问,最后找到了安装脚本中配置的 NetworkPolicy[8],发现有五个 NetworkPolicy 限制了每个 Pod 的 ingress 来源。将 Node 所在局域网的 CIDR(192.168.1.1/24)添加至 argocd-application-controller-network-policy 的 ingress 白名单中,问题解决。
说实话,之前确实没有怎么接触过 NetworkPolicy,导致这个问题我查了将近四天才查出来…
事后分析完整的转发链如下:
# Service -> Pod with DNAT
-A KUBE-SERVICES -d 10.43.4.242/32 -p tcp -m tcp --dport 8082 -m comment --comment "argocd/argocd-metrics:metrics cluster IP" -j KUBE-SVC-SZWGFJCG7JW62ZG2
-A KUBE-SVC-SZWGFJCG7JW62ZG2 -m comment --comment "argocd/argocd-metrics:metrics" -j KUBE-SEP-VYRHUQXWRJ6MSGOH
-A KUBE-SEP-VYRHUQXWRJ6MSGOH -p tcp -m tcp -m comment --comment "argocd/argocd-metrics:metrics" -j DNAT --to-destination 10.42.0.38:8082
# Pod 转发至 pod 防火墙
-A KUBE-ROUTER-OUTPUT -d 10.42.0.38/32 -m comment --comment "rule to jump traffic destined to POD name:argocd-application-controller-0 namespace: argocd to chain KUBE-POD-FW-XIOATVM5TOINSO4V" -j KUBE-POD-FW-XIOATVM5TOINSO4V
-A KUBE-POD-FW-XIOATVM5TOINSO4V -m conntrack --ctstate RELATED,ESTABLISHED -m comment --comment "rule for stateful firewall for pod" -j ACCEPT
# 通过 local mode (也就是从 node ip) 访问 pod 的包都会被批准
-A KUBE-POD-FW-XIOATVM5TOINSO4V -d 10.42.0.38/32 -m addrtype --src-type LOCAL -m comment --comment "rule to permit the traffic traffic to pods when source is the pod\'s local node" -j ACCEPT
# 接受 argocd-application-controller-network-policy 的规则判断,通过后会被打上标记
-A KUBE-POD-FW-XIOATVM5TOINSO4V -m comment --comment "run through nw policy argocd-application-controller-network-policy" -j KUBE-NWPLCY-5VLCZNPWIAXAL2HB
-A KUBE-POD-FW-XIOATVM5TOINSO4V -m mark ! --mark 0x10000/0x10000 -m limit --limit 10/min --limit-burst 10 -m comment --comment "rule to log dropped traffic POD name:argocd-application-controller-0 namespace: argocd" -j NFLOG --nflog-group 100
# 没有标记(没通过规则判断),就会拒绝连接
-A KUBE-POD-FW-XIOATVM5TOINSO4V -m mark ! --mark 0x10000/0x10000 -m comment --comment "rule to REJECT traffic destined for POD name:argocd-application-controller-0 namespace: argocd" -j REJECT --reject-with icmp-port-unreachable
# 第一条 namespaceSelector 规则,对应 8082 端口
# namespaceSelector: {}
# 满足条件则会打上标记,然后 return
-A KUBE-NWPLCY-5VLCZNPWIAXAL2HB -p tcp -m set --match-set KUBE-SRC-DRBIHPAD4OLOF546 src -m set --match-set KUBE-DST-DM6ZQPCTKCXEROGZ dst -m tcp --dport 8082 -m comment --comment "rule to mark traffic matching a network policy" -m comment --comment "rule to ACCEPT traffic from source pods to dest pods selected by policy name argocd-application-controller-network-policy namespace argocd" -j MARK --set-xmark 0x10000/0x10000
-A KUBE-NWPLCY-5VLCZNPWIAXAL2HB -p tcp -m set --match-set KUBE-SRC-DRBIHPAD4OLOF546 src -m set --match-set KUBE-DST-DM6ZQPCTKCXEROGZ dst -m tcp --dport 8082 -m comment --comment "rule to RETURN traffic matching a network policy" -m mark --mark 0x10000/0x10000 -m comment --comment "rule to ACCEPT traffic from source pods to dest pods selected by policy name argocd-application-controller-network-policy namespace argocd" -j RETURN
# 自己加上去的第二条 ipBlock cidr 规则,8082 端口
# ipBlock:
# cidr: 192.168.1.0/24
-A KUBE-NWPLCY-5VLCZNPWIAXAL2HB -p tcp -m set --match-set KUBE-SRC-MLGAJX4FU64MJPWH src -m set --match-set KUBE-DST-DM6ZQPCTKCXEROGZ dst -m tcp --dport 8082 -m comment --comment "rule to mark traffic matching a network policy" -m comment --comment "rule to ACCEPT traffic from specified ipBlocks to dest pods selected by policy name: argocd-application-controller-network-policy namespace argocd" -j MARK --set-xmark 0x10000/0x10000
-A KUBE-NWPLCY-5VLCZNPWIAXAL2HB -p tcp -m set --match-set KUBE-SRC-MLGAJX4FU64MJPWH src -m set --match-set KUBE-DST-DM6ZQPCTKCXEROGZ dst -m tcp --dport 8082 -m comment --comment "rule to RETURN traffic matching a network policy" -m mark --mark 0x10000/0x10000 -m comment --comment "rule to ACCEPT traffic from specified ipBlocks to dest pods selected by policy name: argocd-application-controller-network-policy namespace argocd" -j RETURN
ipset 规则如下:
# 第一条 namespaceSelector 规则
Name: KUBE-SRC-DRBIHPAD4OLOF546
Type: hash:ip
Revision: 4
Header: family inet hashsize 1024 maxelem 65536 timeout 0
Size in memory: 1008
References: 4
Number of entries: 16
Members:
10.42.0.41 timeout 0
10.42.0.40 timeout 0
# 后面的 pod ip 地址略
# 第二条 ipblock cidr 规则
Name: KUBE-SRC-MLGAJX4FU64MJPWH
Type: hash:net
Revision: 6
Header: family inet hashsize 1024 maxelem 65536 timeout 0
Size in memory: 440
References: 4
Number of entries: 1
Members:
192.168.1.0/24 timeout 0
# 目标地址规则(NetworkPolicy 中 podSelector 列出的所有 IP)
# podSelector:
# matchLabels:
# app.kubernetes.io/name: argocd-application-controller
Name: KUBE-DST-DM6ZQPCTKCXEROGZ
Type: hash:ip
Revision: 4
Header: family inet hashsize 1024 maxelem 65536 timeout 0
Size in memory: 168
References: 8
Number of entries: 1
Members:
10.42.0.38 timeout 0
……
总结
从集群外访问集群内的接口有很多种方式,如果是一般的业务需求,我们通常还是会用 Service / Ingress 来完成。但为了简化配置,使用集群层面的服务发现,我们还需要绕些弯路来访问指标接口。
如果实在是希望在集群外收集指标的话(比如使用了指标收集的 PaaS 服务,如阿里云 SLS),那么从安全性和便捷性出发,我认为最合理的架构还是应该在 K8S 集群内部署一个 Prometheus 用于集群内的指标抓取。集群内的 Prometheus 可以通过 Service / Ingress 将暴露出来,这样集群外的 Prometheus 实例可以通过 federate 接口[9]直接抓取到集群内 Prometheus 的指标。由于集群内的 Prometheus 主要用于抓取和数据转发,所以无需保留过多数据,也不需要太关注持久化因素。
那么,折腾了半天,我为什么要在集群外抓取集群内的指标呢。
参考资料
除了 Kubernetes 和 Prometheus 官网外,我还参考了以下页面:
Prometheus kuberenetes_sd_config 示例[10] Prometheus RBAC 配置[11] 《办公环境下 kubernetes 网络互通方案》[12] 《打通 Kubernetes 内网与局域网的 N 种方法》[13]
脚注
K3S: https://k3s.io
[2]pod/service proxy 接口: https://kubernetes.io/zh/docs/tasks/access-application-cluster/access-cluster/#manually-constructing-apiserver-proxy-urls
[3]Prometheus Operator 文档: https://github.com/prometheus-operator/prometheus-operator/blob/master/Documentation/rbac.md#prometheus-rbac
[4]relabel_config 配置: https://prometheus.io/docs/prometheus/latest/configuration/configuration/#relabel_config
《办公环境下 kubernetes 网络互通方案》: https://www.qikqiak.com/post/office-env-k8s-network/
[6]《打通 Kubernetes 内网与局域网的 N 种方法》: https://zhuanlan.zhihu.com/p/187548589
[7]Argo CD 安装脚本: https://github.com/argoproj/argo-cd/blob/master/manifests/install.yaml
[8]NetworkPolicy: https://kubernetes.io/zh/docs/concepts/services-networking/network-policies/#networkpolicy-resource
[9]federate 接口: https://prometheus.io/docs/prometheus/latest/federation/
[10]Prometheus kuberenetes_sd_config 示例: https://github.com/prometheus/prometheus/blob/release-2.28/documentation/examples/prometheus-kubernetes.yml
[11]Prometheus RBAC 配置: https://github.com/prometheus-operator/prometheus-operator/blob/master/Documentation/rbac.md#prometheus-rbac
[12]《办公环境下 kubernetes 网络互通方案》: https://www.qikqiak.com/post/office-env-k8s-network/
[13]《打通 Kubernetes 内网与局域网的 N 种方法》: https://zhuanlan.zhihu.com/p/187548589
原文链接:https://blog.stdioa.com/2021/07/scrape-prometheus-metrics-outside-kubernetes/


你可能还喜欢
点击下方图片即可阅读


云原生是一种信仰 🤘
关注公众号
后台回复◉k8s◉获取史上最方便快捷的 Kubernetes 高可用部署工具,只需一条命令,连 ssh 都不需要!


点击 "阅读原文" 获取更好的阅读体验!
发现朋友圈变“安静”了吗?


