 机器学习算法与Python实战
机器学习算法与Python实战




作者:Will Badr 翻译:顾伟嵩 校对:欧阳锦
无论是通过识别错误还是主动预防,检测异常值对任何业务都是重要的。本文将讨论五种检测异常值的方法。

图来源于Will Myers在Unsplash上的拍摄
什么是异常值?

为什么我们要关注异常值?
方法1——标准差:
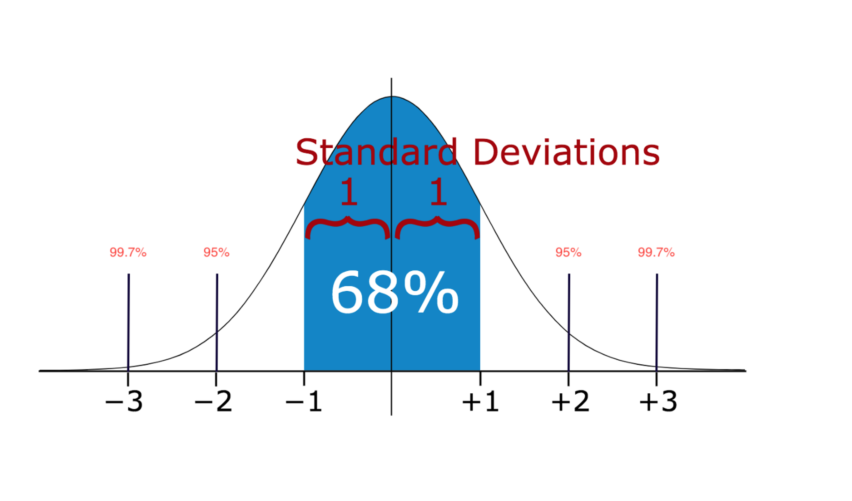
因此,如果你有任何出现在三个标准差范围外的数据点,那么那些点就极有可能是异常值。
让我们看看代码。
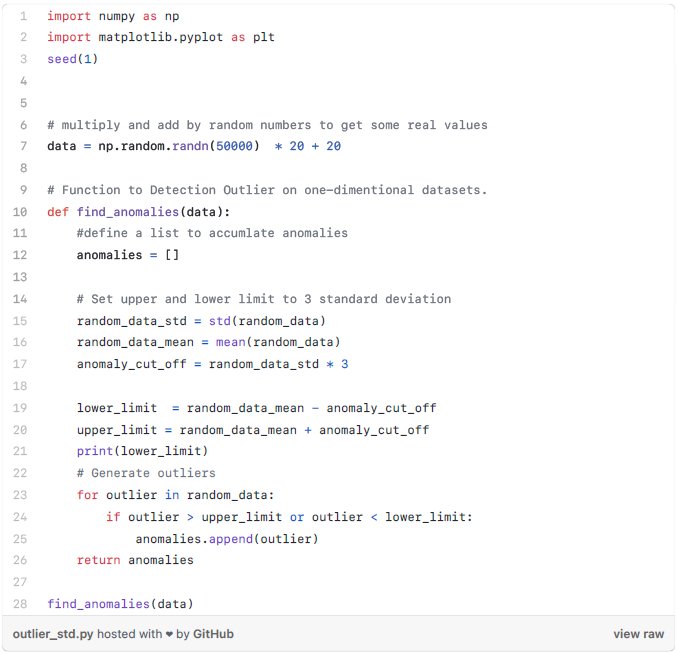
方法2——箱线图:


上面的代码输出如下的箱线图。如你所见,它把大于75或小于-35的值看作异常值。这个结果非常接近上述的方法1得到的结果。

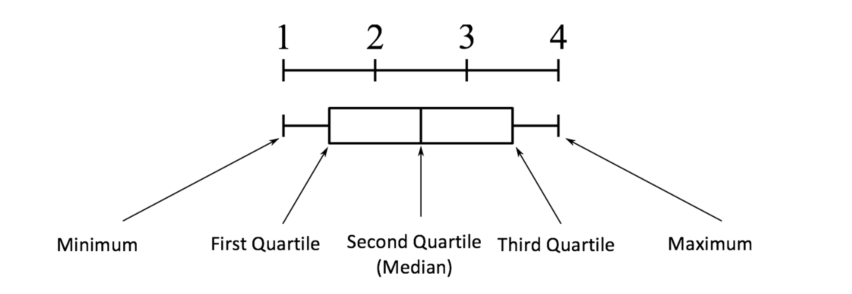
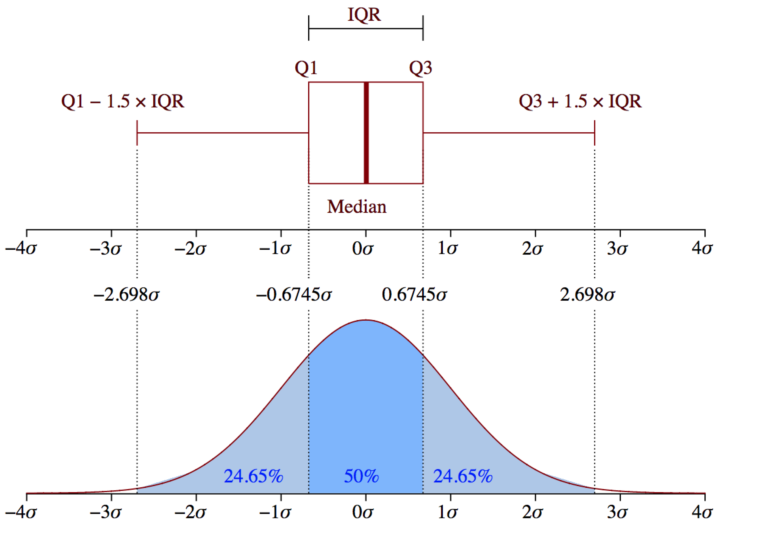
四分位差是重要的,因为它用于定义异常值。它是第三个四分位数和第一个四分位数的差(IQR=Q3-Q1). 这种情况下的异常值被定义为低于(Q1-1.5IQR)或低于箱线图下须触线或高于(Q3+1.5IQR)或高于箱线图上须触线的观测值。
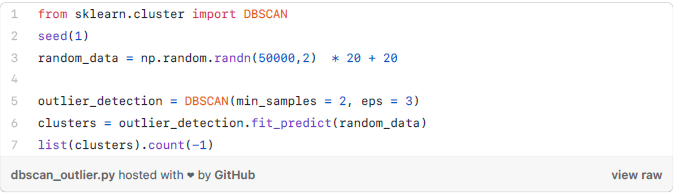
方法3——DBScan集群:
核心点:为了理解核心点,我们需要访问一些用于定义DBScan工作的超参数。第一个超参数是最小值样本(min_samples)。这只是形成集聚的核心点的最小数量。第二重要的超参数eps,它是两个被视为在同一个簇中的样本之间的最大距离。
边界点:是与核心点在同一集群的点,但是要离集群中心远得多。
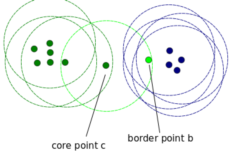
其他的点被称为噪声点,那些数据点不属于任何集群。它们可能是异常点,可能是非异常点,需要进一步调查。现在让我们看看代码。
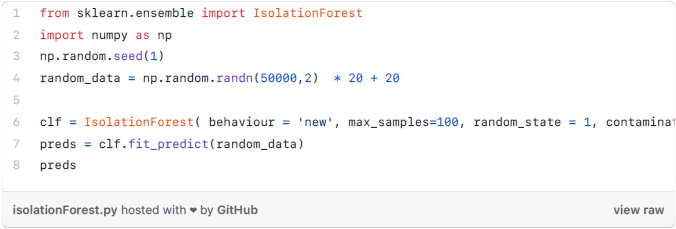
方法4——孤立森林
方法5——Robust Random Cut Forest
http://proceedings.mlr.press/v48/guha16.pdf
该算法的论文给出了一些与孤立森林相比较的性能标准。论文结果表明,RCF比孤立森林更加准确和快速。
amazon-sagemaker-examples/introduction_to_amazon_algorithms/random_cut_forest at master · aws/amazon-sagemaker-examples · GitHub
结论
推荐阅读
(点击标题可跳转阅读)
老铁,三连支持一下,好吗?↓↓↓


