
20亿参数+30亿张图像,刷新ImageNet最高分!谷歌大脑华人研究员领衔发布最强Transformer
数据派THU
共 2203字,需浏览 5分钟
· 2021-07-12

来源:新智元 本文约1300字,建议阅读5分钟 视觉Transformer进阶。
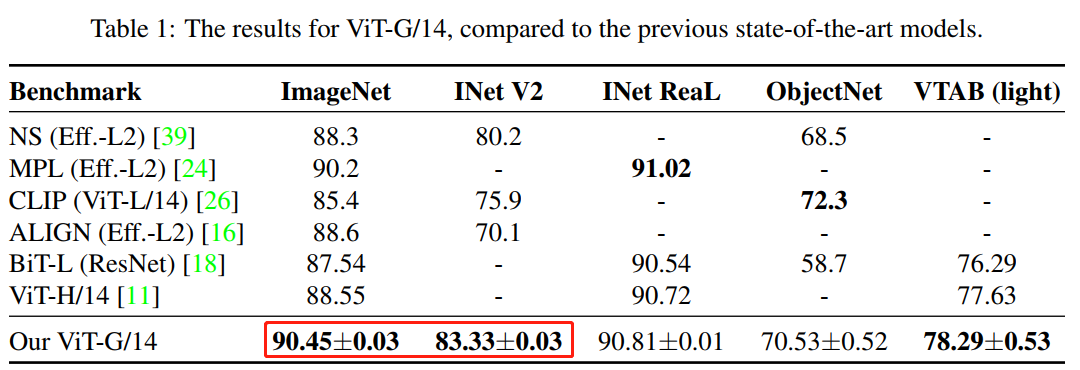

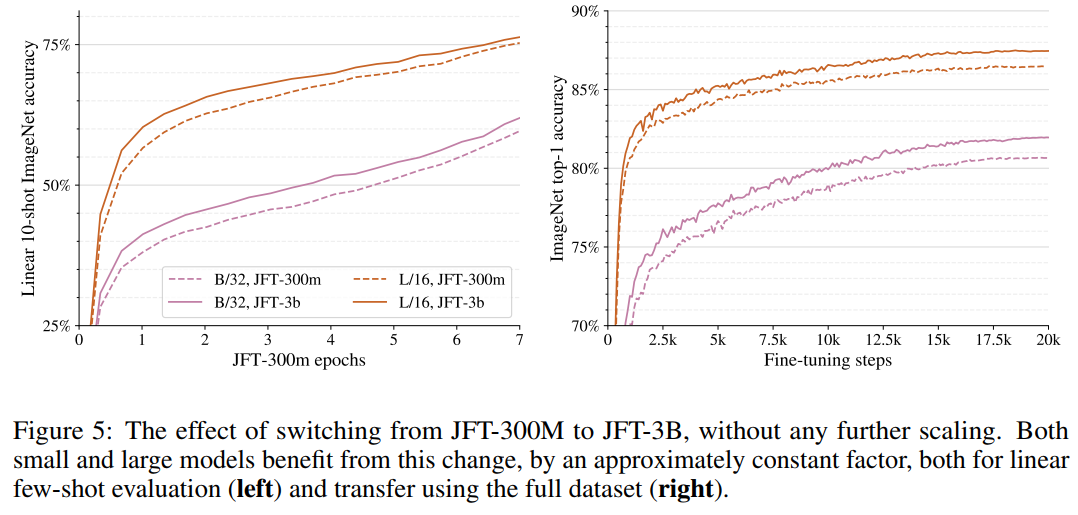
作者团队




参考资料:
https://arxiv.org/pdf/2106.04560.pdf
https://www.marktechpost.com/2021/06/28/google-trains-an-ai-vision-model-with-two-billion-parameter/
评论
IntelliJ IDEA 2024 首个大版本发布,好用到爆!
关注我们,设为星标,每天7:40不见不散,架构路上与您共享回复架构师获取资源大家好,我是你们的朋友架构君,一个会写代码吟诗的架构师。JetBrains 为多款 IDE 发布了 2024 年度首个大版本更新 (2024.1),包括 IntelliJ IDEA 、WebSt
Java架构师社区
0
特斯拉中国Model Y、S、X全系降价;盒马否认侯毅张勇出价20亿美元联手买下盒马;瑞幸回应“不招聘上海人”
特斯拉中国Model Y、S、X全系降价特斯拉中国Model Y售价降至24.99万元人民币,MODEL Y长续航版售价降至29.09万元人民币。特斯拉中国 MODEL Y高性能版售价降至35.49万元人民币。特斯拉中国MODEL S售价降至68.49万元人民币。特斯拉中国 MODEL S PLAI
亿欧网
0
小美播报|3月IPTV数据排行榜发布!
小美播报3月IPTV数据排行榜:《与凤行》登顶连续剧榜榜首拥有4.05亿家庭用户的中国IPTV平台已经成为国内主流视听平台,IPTV平台数据对视听产业各环节都具有重要意义。截至2024年4月,全国已有29个省级IPTV加入“看中国”,覆盖全国超2.25亿户家庭、辐射近7亿人。点击查看详情湖南广电与马
流媒体网
0
图解 transformer 中的自注意力机制
↓推荐关注↓本文将将介绍注意力的概念从何而来,它是如何工作的以及它的简单的实现。注意力机制在整个注意力过程中,模型会学习了三个权重:查询、键和值。查询、键和值的思想来源于信息检索系统。所以我们先理解数据库查询的思想。假设有一个数据库,里面有所有一些作家和他们的书籍信息。现在我想读一些Rabindra
Python学习与数据挖掘
0
5G RedCap贯通行动政策文件发布,这些关键词值得关注
作者:赵小飞物联网智库 原创近日,工信部发布了《关于开展2024年度5G轻量化(RedCap)贯通行动的通知》,从标准、网络、芯片模组、终端、应用、安全、保障7大方面采取具体措施,并给出明确目标,在政策层面对5G RedCap进一步发展提供保障。RedCap承担着5G物联网连接数增长的重要任务,但同
物联网智库
0
第二十四届中国·盱眙国际龙虾节重点活动菜单发布!
今天盱眙龙虾开捕活动现场发布第二十四届中国·盱眙国际龙虾节重点活动菜单盱眙老妹微信自媒体主要从事:品牌推广︎、活动策划︎、微信平台营销代运营︎、免费发布公益便民信息、企业招聘︎、商标注册、征婚交友、公益救助、维权爆料等服务。欢迎广大网友积极参与。免责声明:盱眙老妹微信平台是面向普通网友的信息发布平台
盱眙老妹
0
图像处理基础知识
点击上方“小白学视觉”,选择加"星标"或“置顶”重磅干货,第一时间送达图像1、模拟图像模拟图像,又称连续图像,是指在二维坐标系中连续变化的图像,即图像的像点是无限稠密的,同时具有灰度值(即图像从暗到亮的变化值)。2、数字图像数字图像,又称数码图像或数位图像,是二维图像用有限数字数值像素的表示。数字图
小白学视觉
429
如何使用 Python比较两张图像并获得准确度?
点击上方“小白学视觉”,选择加"星标"或“置顶”重磅干货,第一时间送达本文,将带你了解如何使用 Python、OpenCV 和人脸识别模块比较两张图像并获得这些图像之间的准确度水平。首先,你需要了解我们是如何比较两个图像的。我们正在使用Face Recognition python 模块来获取两张图
小白学视觉
142