 七月在线实验室
七月在线实验室





项目一:FinBERT 基于 BERT 架构的金融领域预训练语言模型
项目二:nanodet 超快速和轻量级的anchor-free物体检测模型
项目三:TJU-DHD 用于物体检测和行人检测的新建高分辨率数据集
项目四:HALO 基于编译器技术的异构计算加速平台
项目五:xingtian 基于深度学习的图像半监督异常检测和分割的端到端框架
项目六:spikingjelly 使用脉冲神经网络进行深度学习的框架
FinBERT 基于 BERT 架构的金融领域预训练语言模型
项目地址:
https://github.com/valuesimplex/FinBERT
为了促进自然语言处理技术在金融科技领域的应用和发展,熵简科技 AI Lab 近期开源了基于 BERT 架构的金融领域预训练语言模型 FinBERT 1.0。这是国内首个在金融领域大规模语料上训练的开源中文BERT预训练模型。相对于Google发布的原生中文BERT、哈工大讯飞实验室开源的BERT-wwm 以及 RoBERTa-wwm-ext 等模型,本次开源的 FinBERT 1.0 预训练模型在多个金融领域的下游任务中获得了显著的性能提升,在不加任何额外调整的情况下,F1-score 直接提升至少 2~5.7 个百分点。
当前开源的各类中文领域的深度预训练模型,多是面向通用领域的应用需求,在包括金融在内的多个垂直领域均没有看到相关开源模型。
模型结构:
熵简 FinBERT 在网络结构上采用与 Google 发布的原生BERT 相同的架构,包含了 FinBERT-Base 和 FinBERT-Large 两个版本,其中前者采用了 12 层 Transformer 结构,后者采用了 24 层 Transformer 结构。考虑到在实际使用中的便利性和普遍性,本次发布的模型是 FinBERT-Base 版本,本文后面部分统一以 FinBERT 代指 FinBERT-Base。
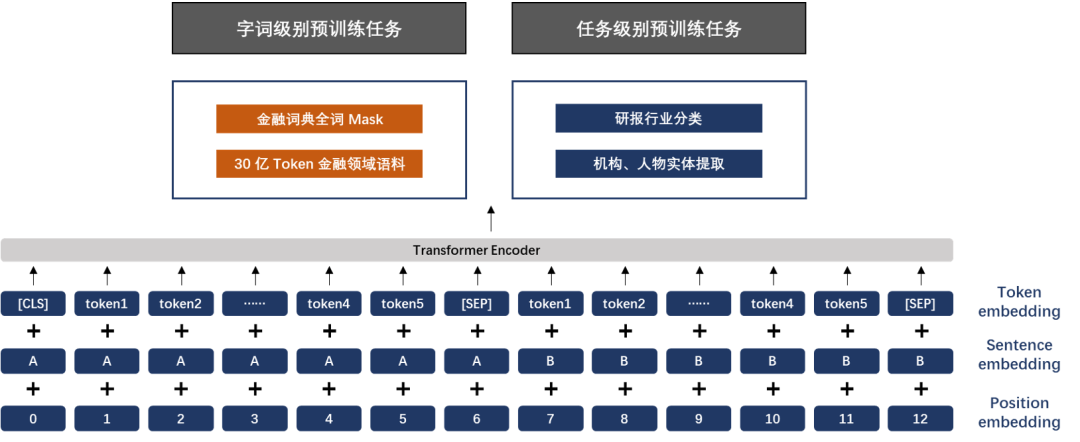
训练语料:
FinBERT 1.0 所采用的预训练语料主要包含三大类金融领域的语料,分别如下:
金融财经类新闻: 从公开渠道采集的最近十年的金融财经类新闻资讯,约 100 万篇;
研报/上市公司公告: 从公开渠道收集的各类研报和公司公告,来自 500 多家境内外研究机构,涉及 9000 家上市公司,包含 150 多种不同类型的研报,共约 200 万篇;
金融类百科词条: 从 Wiki 等渠道收集的金融类中文百科词条,约 100 万条。
对于上述三类语料,在金融业务专家的指导下,对于各类语料的重要部分进行筛选、预处理之后得到最终用于模型训练的语料,共包含 30亿 Tokens,这一数量超过了原生中文BERT的训练规模。
实验结果:
TASK\MODEL | BERT | BERT-wwm | RoBERTa-wwm-ext | FinBERT |
金融短讯类型分类 | 0.86(0.874) | 0.86(0.877) | 0.877(0.885) | 0.89(0.897) |
nanodet 超快速和轻量级的anchor-free物体检测模
项目地址:

超轻量:模型文件只有 980KB(INT8) 或 1.8MB(FP16)。 超快:97fps(10.23ms) 在移动 ARM CPU 上。 训练友好:与其他模型相比,GPU 内存成本低得多。Batch-size=80 在 GTX1060 6G 上可用。 易于部署:提供各种后端的C++实现和基于ncnn推理框架的Android演示。
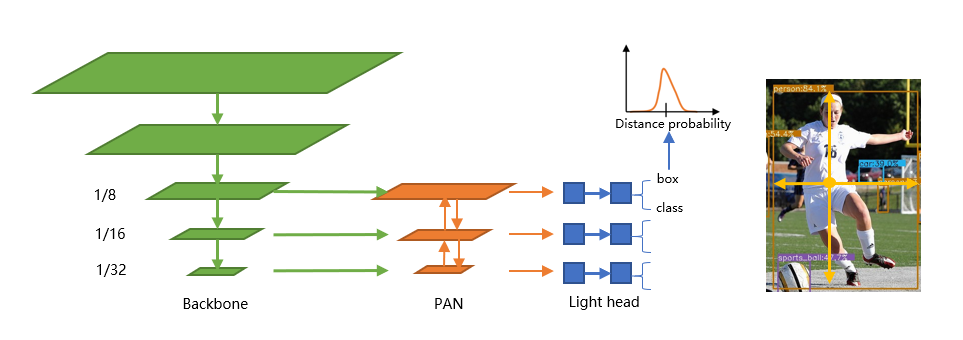
TJU-DHD 用于物体检测和行人检测的新建高分辨率数据集
项目地址:
https://github.com/tjubiit/TJU-DHD
一个全新构建的用于物体检测和行人检测的高分辨率数据集,是“TJU-DHD: A Diverse High-Resolution Dataset for Object Detection (TIP2020)”的实现。
车辆、行人和骑手是自动驾驶汽车和视频监控感知模块中最重要、最有趣的对象。然而,检测此类重要物体(尤其是小物体)的最新性能远不能满足实际系统的需求。大规模、丰富多样、高分辨率的车辆和行人数据集在开发更好的目标检测方法以满足需求方面发挥着重要作用。现有的公共大规模数据集,例如从网站收集的 MS COCO,并没有关注这些特定场景。此外,从这些特定场景中收集的流行数据集(例如 KITTI 和 Citypersons)在图像和实例的数量、分辨率以及季节、天气和光照的多样性方面受到限制。为了尝试解决这个问题,在本文中,我们构建了一个多样化的高分辨率数据集(称为 TJU-DHD)。该数据集包含 115,354 张高分辨率图像(52% 的图像分辨率为 1624x1200 像素,48% 的图像分辨率至少为 2,560x1,440 像素)和总共 709,330 个标记对象,在尺度和外观上有很大差异。同时,该数据集在季节方差、光照方差和天气方差方面具有丰富的多样性。基于这个对象数据集,进一步构建了一个新的多样化行人数据集。使用四种不同的检测器(即一级 RetinaNet、无锚 FCOS、两级 FPN 和 Cascade R-CNN),进行了关于物体检测和行人检测的实验。我们希望新构建的数据集能够帮助推动这两个场景中的目标检测和行人检测的研究

项目特点:
115k+ 图像和 700k+ 实例
场景:交通和校园,任务:物体检测和行人检测
高分辨率:图像分辨率至少为 1624x1200 像素,物体高度从 11 像素到 4152 像素。
多样性:外观、规模、光照、季节和天气的巨大差异
行人检测的跨场景评价和同场景评价
目标检测数据集:
name | DHD-traffic (#images) | DHD-traffic (#instances) | DHD-campus (#images) | DHD-campus (#instances) |
training | 45,266 | 239,980 | 39,727 | 267,445 |
validation | 5,000 | 30,679 | 5,204 | 41,620 |
test | 10,000 | 60,963 | 10,157 | 68,643 |
total | 60,266 | 331,622 | 55,088 | 377,708 |
行人检测数据集:
name | Ped-traffic (#images) | Ped-traffic (#instances) | Ped-campus (#images) | Ped-campus (#instances) |
training | 13,858 | 27,650 | 39,727 | 234,455 |
validation | 2,136 | 5,244 | 5,204 | 36,161 |
test | 4,344 | 10,724 | 10,157 | 59,007 |
total | 20,338 | 43,618 | 55,088 | 329,623 |
HALO 基于编译器技术的异构计算加速平
项目地址:
https://github.com/alibaba/heterogeneity-aware-lowering-and-optimization
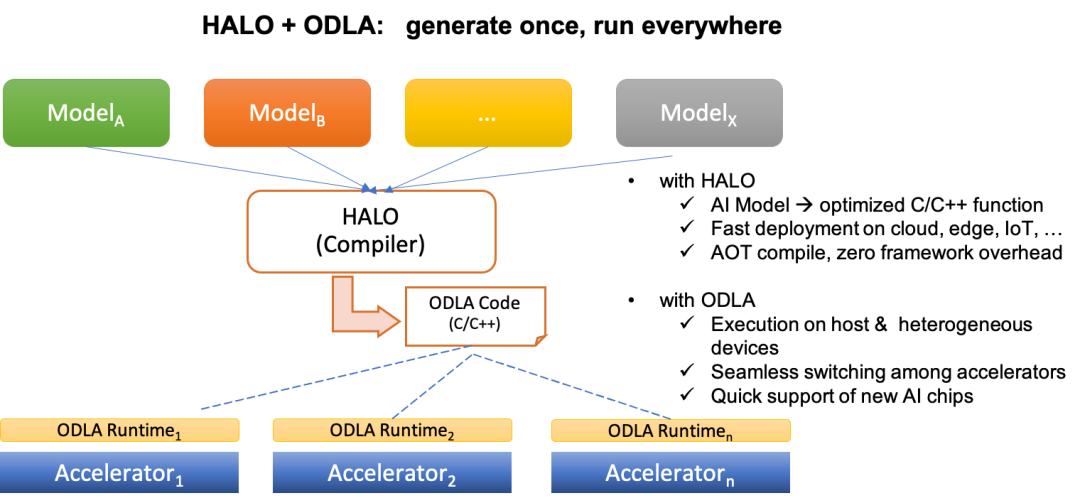
Caffe ONNX TensorFlow TFLite
使用 HALO 将模型文件编译为基于 ODLA 的 C/C++ 源文件。 使用 C/C++ 编译器将生成的 C/C++ 文件编译为目标文件。 将目标文件、权重二进制文件和特定的 ODLA 运行时库链接在一起。
xingtian 基于深度学习的图像半监督异常检测和分割的端到端框
高性能 1K+ CPU并行数据采样 易于使用 模块化设计 支持并行调参
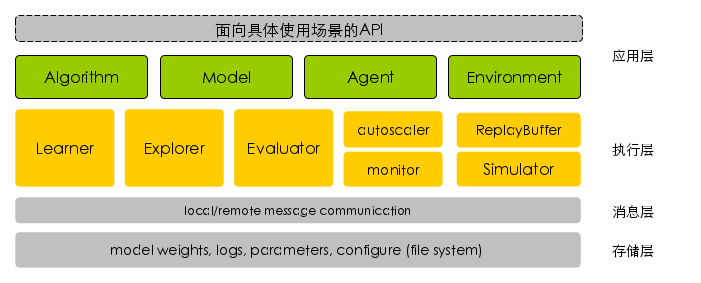
应用层:各模块解耦设计,提供统一的对外接口,目前已集成众多业界主流的algorithm、model、agent、environment等模块,用户可以通过配置文件灵活配置,像搭建乐高似的搭建自己的强化学习任务系统,同时用户可以方便地注册自定义模块: 算法,algorithm:对不同的强化学习算法提供统一的抽象封装,对外提供统一的数据处理prepare_data() 和 训练train()接口 模型,model:定义算法的网络架构,设计上解耦深度学习后端,可以支持TensorFlow、PyTorch等主流框架 代理智能体,agent:定义任务交互的相关属性,包含基于环境的最新state推导action,和执行动作后处理环境返回的反馈信息这两部分 仿真环境,environment:对不同环境抽象统一接口,屏蔽不同仿真环境的差异性 存储层:提供对模型weights,训练/评估相关log,以及其他系统配置的同步与统一 消息层:抽象统一的消息通信模型,提供分发,同步模型weights,以及汇总采样轨迹的能力 执行层:提供高效的分布式处理能力,充分发挥硬件能力,提升强化学习效率,主要有如下特点: 基于多进程的并行化 基于共享内存的高效进程通信 基于ZMQ的高效节点间通信 自动化的跨节点代码和数据同步,如同单机般的使用体验
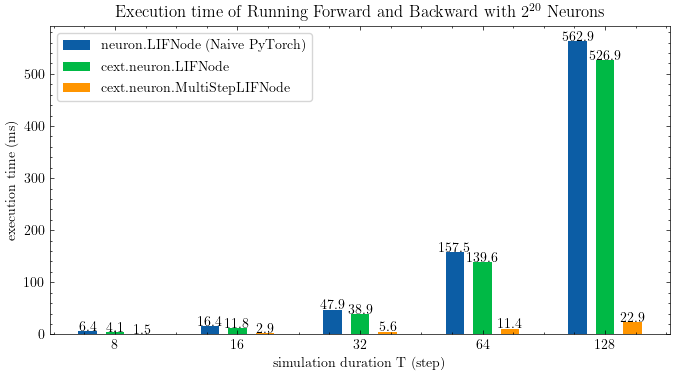
spikingjelly 使用脉冲神经网络进行深度学习的框架
项目地址:
https://github.com/fangwei123456/spikingjelly
数据集 | 来源 |
ASL-DVS | Graph-based Object Classification for Neuromorphic Vision Sensing |
CIFAR10-DVS | CIFAR10-DVS: An Event-Stream Dataset for Object Classification |
DVS128 Gesture | A Low Power, Fully Event-Based Gesture Recognition System |
N-Caltech101 | Converting Static Image Datasets to Spiking Neuromorphic Datasets Using Saccades |
N-MNIST | Converting Static Image Datasets to Spiking Neuromorphic Datasets Using Saccades |

推荐阅读 点击标题可跳转 戳↓↓“阅读原文”了解更多!

