
颜水成团队又出王炸!不需要额外数据,Transformers超越CNN问鼎ImageNet
共 2523字,需浏览 6分钟
· 2021-07-08

新智元报道
新智元报道
来源:reddit
编辑:LRS
【新智元导读】颜水成博士加入Sea AI lab后有了新工作,提出一种新的注意力机制outlook,不借助额外数据,Transformers首次在ImageNet榜单上问鼎,超越CNN模型!但网友却不买账:有人认为这就是CNN的蒸馏,也有人认为参数更多了,自然效果更好了!
今年年初,原依图科技的CTO颜水成博士离职后,加入了东南亚电商平台Shopee。
Shopee是东南亚及中国台湾的电商平台 ,该公司于2009年由李小冬(Forrest Li,中国大陆天津人)创立,发迹中国目前已扩展到马来西亚、泰国、印度尼西亚、越南、菲律宾和中国台湾,为全世界华人地区用户的在线购物和销售商品提供服务。
当时Shopee的母公司冬海集团公布财报,公告除了披露了公司2020的财务情况,也特别确认了颜水成的加入。
其中还显示,颜水成博士担任集团首席科学家,其中还特别提到,颜博士将建设和领导Sea人工智能实验室。

如今Sea AI Lab的研究成果来了!
一出手就是王炸,把以往需要吞噬海量数据才能超越CNN模型的Visual Transformers抬到了新高度!
不需要额外数据,Transformers超越CNN问鼎ImageNet!

多年来,视觉识别一直是卷积神经网络(CNNs)的天下。
但随着基于自注意的视觉Transformers(pre-ViTs)的问世,模型在 ImageNet 分类任务中已经取得了很大的发展,但如果在没有提供额外数据的情况下,其性能仍然不如最新的 SOTA CNN 模型。
基于这个想法,他们的目标是弥补CNN和ViT之间由数据产生的性能差距,并证明基于注意力的模型确实能够胜过CNN。
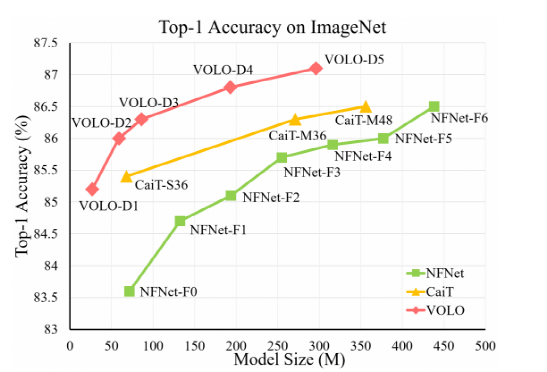
研究人员发现,限制 ViTs 在 ImageNet 分类中的性能的主要因素是它们在将精细级别的特征编码到词表示中的效率低。
为了解决这个问题,文中介绍了一种新颖的前景(outlook)注意力,并提出了一种简单而通用的体系结构——视觉前瞻器( Vision Outlooker, VOLO)。
与自我注意不同,outlook 的注意力集中在粗糙的全局去频率建模上,能够有效地将更精细的特征和上下文编码成标记,这些标记对于识别性能非常重要,但是自我注意却很大程度上忽略了它们。
实验表明,VOLO 在没有使用任何额外训练数据的情况下,达到了87.1% 的top1精度 ImageNet-1K 分类,是第一个在这个竞争性基准上超过87% 精度的模型。
此外,预训练的volo 可以很好地转移到下游任务中,例如语义分割。在ADE20k 验证集上获得了84.3% 的 mIoU 分数,在 ADE20K 价值集上获得了54.3% 的分数。
论文中的代码已经上传到GitHub上。
文中的模型可以看作是两个分开的阶段。
第一阶段由一堆outlooker组成,这些outlooker生成精细级别的token表示。这个第二阶段部署一系列Transformer block聚合全局信息。
在每个阶段的开始,利用贴片嵌入模块对输入进行映射用设计好的shape来表示。
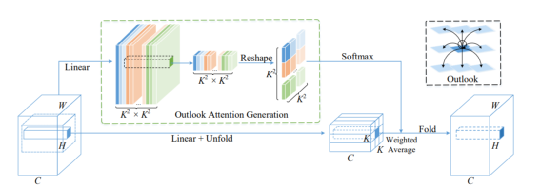
Outlooker由一个outlook注意层组成,空间信息编码与多层感知器(MLP)用于通道间信息交互。
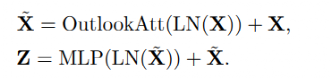
LN指的是Layer Normalization。
对比Transformer和CNN,前景注意力通过对空间信息进行编码,通过测量符号表示对之间的相似性,参数学习比卷积更有效。
其次,注意力采用滑动窗口机制在精细级别对token表示进行局部编码,并在视觉任务上某种程度上保留了关键的位置信息。
第三,产生注意权重的方法简单有效。不像自我注意力这依赖于query-key矩阵乘法,outlook的权重可以直接产生一个简单的整形操作,节省计算。
论文的第一作者袁粒(Li Yuan)来自新加坡国立大学。
据悉,颜水成曾在2008年就加入新加坡国立大学,现在也已是新加坡国立大学终身教职;在2011年,颜水成还被新加坡国家科学院授予新加坡青年科学家奖。

颜水成博士是人工智能领域的顶尖专家,尤其专注于计算机视觉、机器学习和多媒体分析。他是ACM院士和新加坡工程院院士。
Sea AI Labs打算吸引人工智能领域的顶尖人才并与之合作,目标是探索和发展与我们现有业务相关的长期见解和技术,以及其他新的机会。颜博士和Sea AI Labs将加强我们在创新和研究方面的能力,以符合我们对推动技术发展的承诺,推动整个地区数字经济的发展。
大佬的工作却遭到Reddit网友的质疑:
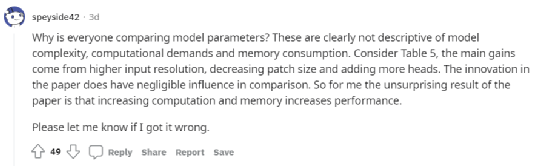
为什么每个人都在比较模型参数?这些显然不能描述模型的复杂性、计算需求和内存消耗。例如表5,主要收益来自更高的输入分辨率,减少补丁大小和增加更多的头。相比之下,本文的创新之处影响不大。所以对我来说,这篇论文的结果并不令人惊讶,那就是计算和内存的增加提高了性能。
值得一提的是,GitHub上传的代码还特意提到表5中存在一个错误。

从LV-ViT-S[32]基线到我们的VOLO-D1。所有的实验都期望更高的输入分辨率,并且在3天内使用带有8 V100的单个GPU服务器节点2天8 A100 GPU完成训练。显然,文中提出的VOLO架构只有2700万个可学习参数,性能就可以从83.3提高到85.2(+1.9)。“T”和“O”指分别是Transformer和Outlooker。

也有网友认为这不就是CNN的蒸馏吗?

还有网友说arxiv上的论文摘要中有太多的拼写错误,让他感觉对论文的内容很没有信心。网友回复说,这就是预印的意思!
参考资料:
https://www.reddit.com/r/MachineLearning/comments/o7gcl0/r_volo_vision_outlooker_for_visual_recognition/
