
从NeRF -> GRAF -> GIRAFFE,2021 CVPR Best Paper诞生记

极市导读
本文根据NeRF、GRAF、GIRAFFE三篇文章,看看2021 CVPR Best Paper GIRAFFE是如何诞生的。文章中公式众多,作者尽可能的用通俗的语言来描述三个算法的设计思路,帮助大家更好的理解公式。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

最近2021年的CVPR公布了best paper归属-GIRAFFE,满怀激动的心情想第一时间品读一下,然而我发现字我都认识,但是压根看不懂在讲什么(迷茫),于是开始追根溯源,先找GIRAFFE的前置研究,发现从NeRF -> GRAF -> GIRAFFE,best paper的主线非常的清晰,下面根据NeRF、GRAF、GIRAFFE三篇文章,看看2021 CVPR Best Paper GIRAFFE是如何诞生的。文章中公式众多,我尽可能用通俗的语言来描述三个算法的设计思路,以便更好的理解公式。
三维重建是计算机视觉和深度学习的重要任务。目前三维重建按照其表达方式主要分为两大类:一类是显式表达,以点云为代表(也有生成网格和体素),由神经网络直接回归生成三维空间中的几何元素;另一类是隐式表达(如NeRF),神经网络只是建模三维物体的空间占用,需要后续的渲染或表面提取获得显式三维形状。
NeRF
NeRF就是隐式表达进行三维重建经典方法。不需要中间三维重建的过程,仅根据相机pose内参和图像,直接合成3D场景( 一个模型表达一个场景)。
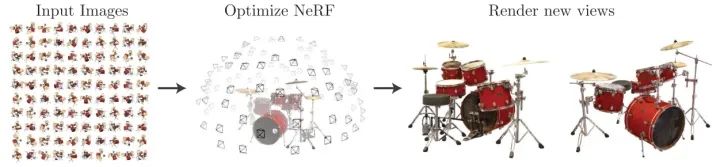
如图所示,通过大量不同视角的图片和相机pose来合成3D场景,然后通过render的方法渲染成新视角的2D图片。
Neural Radiance Field是2D转3D的过程,Volume Rendering是3D转2D的过程,下面介绍一下Neural Radiance Field和Volume Rendering两个部分是怎么实现的,然后介绍NeRF的两个优化trick。
Neural Radiance Field
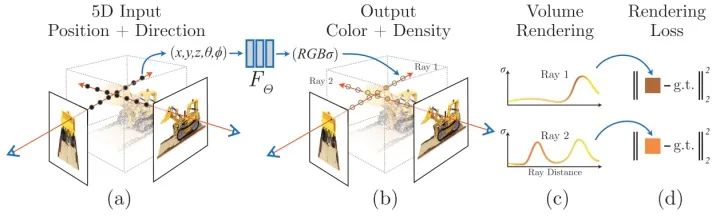
NeRF把整个三维空间的几何信息与纹理信息全部用一个MLP的权重来表达,输入任意一个空间坐标以及观察角度,MLP会预测一个RGB值和体素密度(如图a到图b的蓝色箭头过程所示)。具体的,NeRF函数是将一个连续的场景表示为一个输入为5D向量的函数,包括一个空间点的3D坐标位置 ,以及视角方向 。这个神经网络可以写作:
输出结果中, 是对应体素的密度,而 是视角相关的该3D点颜色。 首先输入到MLP网络中,并输出 和中间特征,中间特征和 再输入到额外的全连接层中并预测颜色。因此,体素密度只和空间位置有关,而颜色则与空间位置以及观察的视角都有关系。基于view dependent 的颜色预测,能够得到不同视角下不同的光照效果。
Volume Rendering
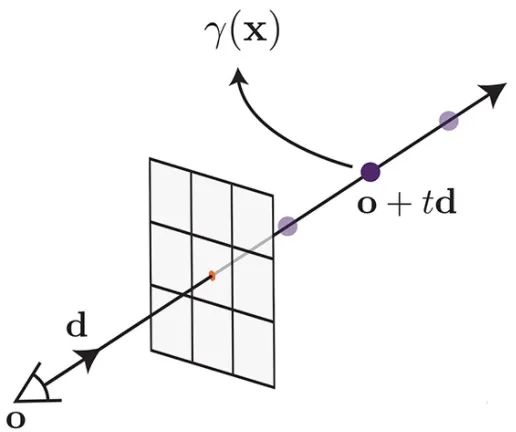
Volume Rendering一般过程如下,如图所示,假设当前相机光心的位置为 ,图像上的任意像素与光心连接,可以得到视角方向 ,根据光心以及视角方向可以得到一条光线 ,那么volume rendering可以写成积分的形式:
其中T ( t )是射线的积累透明度。积分结果即为该视角下图像的预测结果,如图d所示,预测结果和图像上该点进行监督学习。但是实际优化中不能连续的采集3D坐标点进行积分,NeRF对积分公式进行离散近似,从射线等距离采样N个点进行求和。
两个优化tricks
Positional encoding

如图所示,作者发现直接将位置和角度作为网络的输入得到的结果是相对模糊的。而用positon encoding 的方式将位置信息映射到高频则能有效提升清晰度效果,position encoding 能够帮助网络更容易建模3D位置信息。
Hierarchical volume sampling
使用volume rendering会遇到如何采样的问题,采样点过多计算开销过大,采样点过少近似误差有太大。直观的想法是,尽可能的在密集部分进行更多的采样,因为密集部分对颜色的贡献更多,基于这一想法 NeRF 提出分层采样训练的方式,如下图所示:
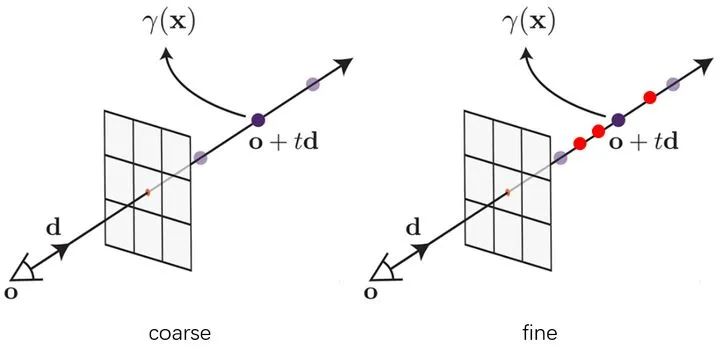
使用两个网络同时进行训练 (后称 coarse 和 fine 网络), coarse 网络输入的点是通过对光线均匀采样得到的,根据 coarse 网络预测的体密度值,对光线的分布进行估计,然后根据估计出的分布进行第二次重要性采样,然后再把所有的采样点 一起输入到 fine 网络进行预测(同时优化coarse和fine)。如图所示,紫色点为第一次均匀采样,红色点为第二次重要性采样。
GRAF
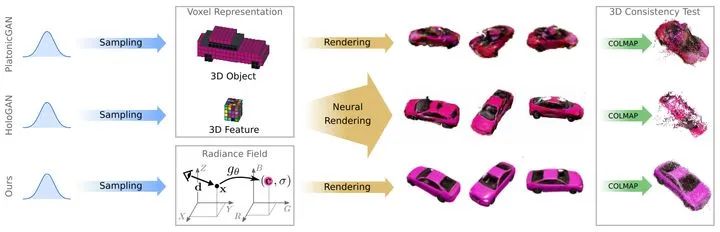
GRAF中提出Voxel Reresentation显示生成3D Object和3D Feature的方法,由于学习的是投影函数,分别会导致离散化物体或者降低生成图像的视图一致性。另外NeRF的隐式方法需要很多不同角度的视图,需要对每个场景重新训练,并且不能生成新的场景。受到NeRF的启发,GRAF设计了一种NeRF表示的条件变体,展示了如何从一组未设定pose的2D图像中学习出丰富的生成模型。
Generative Radiance Fields
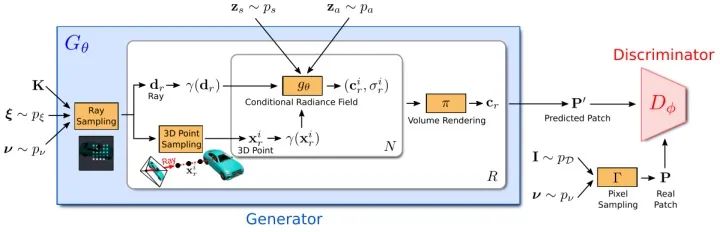
GRAF的整体框架如图所示,和GAN类似(GAN相关原理可以看我之前的文章TransGAN),GRAF分成Generator和Discriminator两个部分。generator部分将相机矩阵 ,相机位姿 ,2D采样模板 和形状/外观编码 作为输入预测一个图像patch ,其中每个Ray由 、 、 三个输入决定,conditional radiance field是generator唯一可学习的部分。discriminator对预测合成的patch 和真实图片采样得到真实patch 进行判断。训练阶段,GRAF使用稀疏的K x K个像素点2D采样模板进行高效优化,测试阶段,预测出目标图片的每个像素的颜色值。
下面介绍一下GRAF几个部分的细节。
Ray Sampling
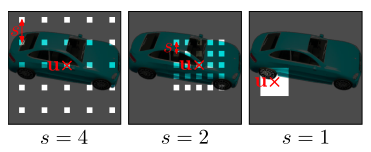
决定KxK个patch的平面位置 和尺度s。给定 和 ,根据 训练阶段采样 个ray,测试阶段采样WH个ray。
3D Point Sampling
和NeRF类似,采用分层采样策略。
Conditional Radiance Field
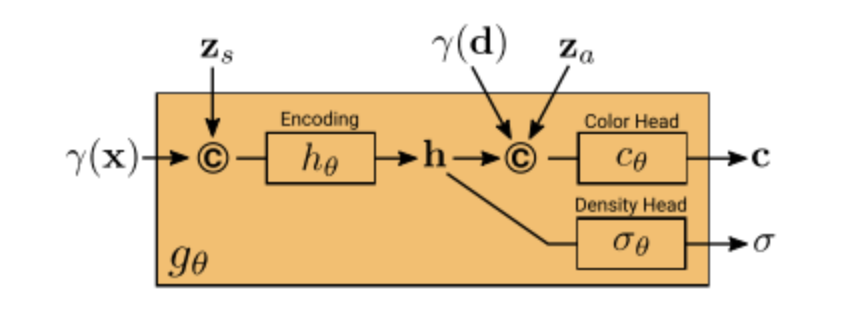
和NeRF不同的地方是,引入了形状编码 和外观编码 。可以通过形状编码 来增加不同3D位置密度生成的自由度,可以通过外观编码 来增加不同3D位置颜色生成的自由度。
Volume Rendering
由于GRAF采用Ray sampling方式进行训练,需要分别对每个ray进行volume rendering,最后结合所有ray的volume rendering产生预测patch 。
GIRAFFE
虽然深度生成模型可以在高分辨率下进行逼真的图像合成,但是许多应用程序还需要生成内容是可以控制的。GRAF虽然实现可控的图像合成在高分辨率,但是只能局限于单物体场景。GIRAFFE提出将场景表示为合成的neural feature fields,能够从背景中分离出一个或多个物体以及单个物体的形状和外观。
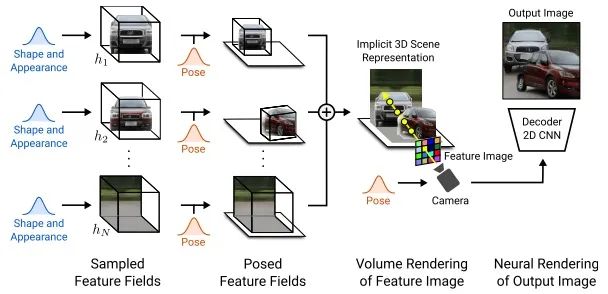
如图所示,GIRAFFE将场景表示为合成的neural feature fields。训练完成后,输入随机采样的相机位姿,可以volume rendering成feature Image,然后通过一个2D neural rendering转化成RGB Image。训练阶段,在原始图片集合上进行,测试阶段,可以同时控制相机位姿、目标位姿和目标的形状和外观来产生2D图片。并且,GIRAFFE可以合成超出训练图片中以外的物体。
Overview
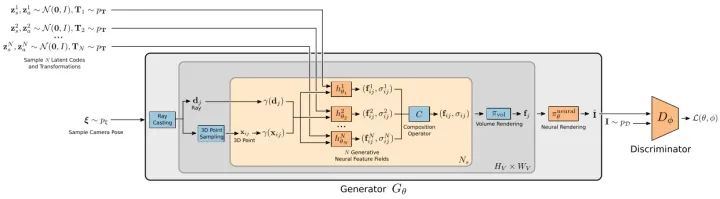
GIRAFFE的整体框架如图所示。generator将相机位姿 和N个形状/外观编码 和仿射变换 作为输入,然后将产生的N-1个物体和一个背景合成一个图片。discriminator将输入图片和预测图片进行判断。其中红色矩形为可学习的部分,蓝色矩形为不可学习部分。
Objects as Neural Feature Fields
NeRF场景表达公式:
输入任意一个空间坐标以及观察角度,MLP会预测一个RGB值和体素密度。
GRAF场景表达公式:
相比NeRF增加了形状/外观编码 。
GIRAFFE场景表达公式:
相比GRAF,颜色预测从3维变成了 维。
物体表示:
NeRF和GRAF受限制的原因是整个场景都是由一个模型表示的。GIRAFFE将不同物体从场景中分解出来,可以对单个物体的姿态、形状和外观进行控制。于是,引入了一个仿射变换来表示每个物体:
其中s和t控制尺度和平移,R控制旋转。
Scene Compositions
一个场景可以描述成一个背景和N-1个物体。GIRAFFE将背景也看成一个物体,固定住背景的尺度和平移参数,并且以场景空间原点为中心。
总体的密度通过不同物体的密度求和,总体的颜色通过不同物体的密度进行颜色加权求和。
Scene Rendering
GIRAFFE的scene rendering分成3D Volume Rendering和2D Neural Rendering两个部分。其中3D volume rendering和NeRF的相似,只是从3维拓展到了 维。
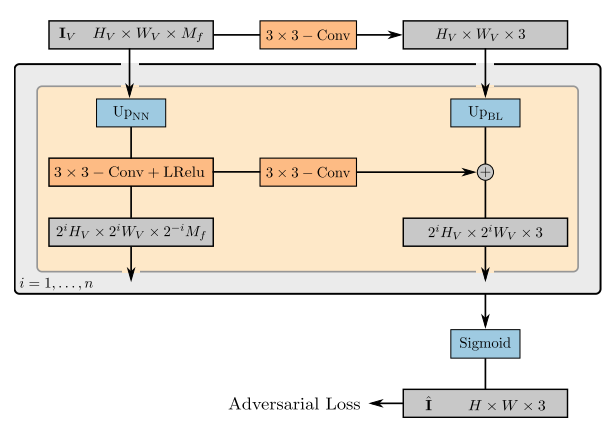
2D neural rendering结构如图所示,将低分辨率的特征映射上采样到高分辨率的RGB图像。
实验结果

可以看到GIRAFFE可以通过控制不同参数来合成不同的场景。

GIRAFFE可以生成训练数据外的物体。

比较HoloGAN、GRAF和GIRAFFE三种方法旋转360度的效果,令人惊叹的是GIRAFFE仍然能够保持车子的外观特征。
总结
NeRF通过神经辐射场来隐式表达3D场景。GRAF通过GAN的形式产生保真度更高的3D场景,并且引入了形状/外观编码来控制单个物体场景的生成。GIRAFFE引入了合成的神经特征场,通过改变相机位姿、目标位姿和目标的形状/外观控制多个物体场景的合成。
得益于NeRF隐式表达的简洁性和可拓展性,GIRAFFE通过各种可变的输入参数来控制3D场景的生成,以完全可微和可学习的方式将多个物体合成3D场景,是NeRF系列中的集大成者。
最终GIRAFFE获得了2021年CVPR best paper,GIRAFFE的胜利,其实是NeRF整个系列的胜利。
Reference
本文亮点总结
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“目标检测综述”获取综述:目标检测二十年(2001-2021)~

# CV技术社群邀请函 #
备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
