
一万亿模型要来了?谷歌大脑和DeepMind联手发布分布式训练框架Launchpad
新智元
共 2344字,需浏览 5分钟
· 2021-06-28
新智元报道
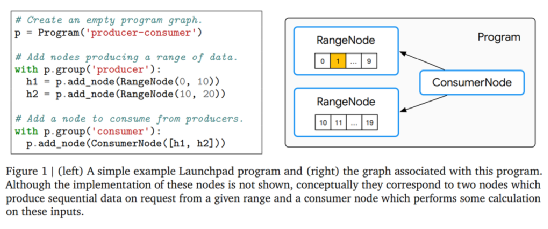
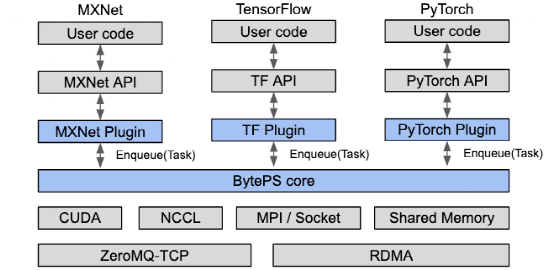
【新智元导读】AI模型进入大数据时代,单机早已不能满足训练模型的要求,最近Google Brain和DeepMind联手发布了一个可以分布式训练模型的框架Launchpad,堪称AI界的MapReduce。








评论
ParlAIAI 对话模型研究和训练框架
ParlAI(发音为“par-lay”)是Facebook开源的,用于在Python中实现的对话AI研究框架。其目标是为研究人员提供:一个用于训练和测试对话模型的统一框架一次对多个数据集进行多任务训练
ParlAIAI 对话模型研究和训练框架
0
Primus分布式训练调度框架
Primus是一个用于机器学习应用程序的通用分布式训练调度框架,管理机器学习框架(如Tensorflow、Pytorch)的训练生命周期和数据分布,帮助训练框架获得更好的分布式能力。功能多训练框架支持
Primus分布式训练调度框架
0