
10 种创建 DataFrame 的方式,你知道几个?
DataFrame数据创建
本文介绍如何创建 DataFrame,也是 pandas 中最常用的数据类型,必须掌握的,后续的所有连载文章几乎都是基于DataFrame数据的操作。
导入库
pandas 和 numpy 建议通过 anaconda 安装后使用;pymysql 主要是 python 用来连接数据库,然后进行库表操作的第三方库,也需要先安装
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
import pymysql # 安装:pip install pymysql
10种方式创建 DataFrame
下面介绍的是通过不同的方式来创建 DataFrame 数据,所有方式最终使用的函数都是:pd.DataFrame()
1、创建空 DataFrame

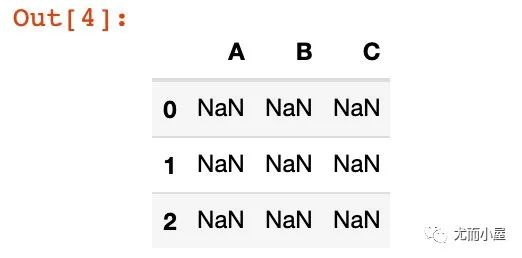
2、创建数值为 NaN 的 DataFrame
df0 = pd.DataFrame(
columns=['A','B','C'], # 指定列属性
index=[0,1,2] # 指定行索引
)
df0
改变数据的行索引:
df0 = pd.DataFrame(
columns=['A','B','C'],
index=[1,2,3] # 改变行索引:从1开始
)
df0

手动创建 DataFrame
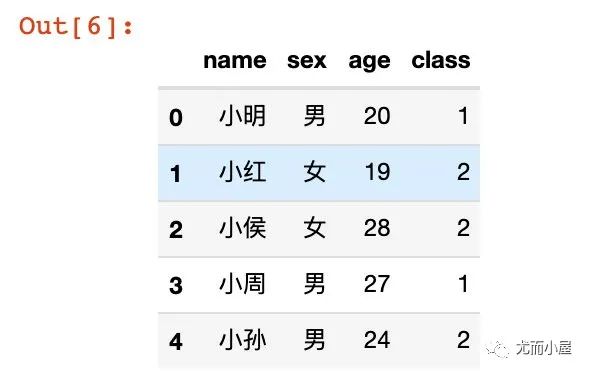
将每个列字段的数据通过列表的形式列出来
df1 = pd.DataFrame({
"name":["小明","小红","小侯","小周","小孙"],
"sex":["男","女","女","男","男"],
"age":[20,19,28,27,24],
"class":[1,2,2,1,2]
})
df1
读取本地文件创建
pandas 可以通过读取 Excel、CSV、JSON 等文件来创建 DataFrame 数据
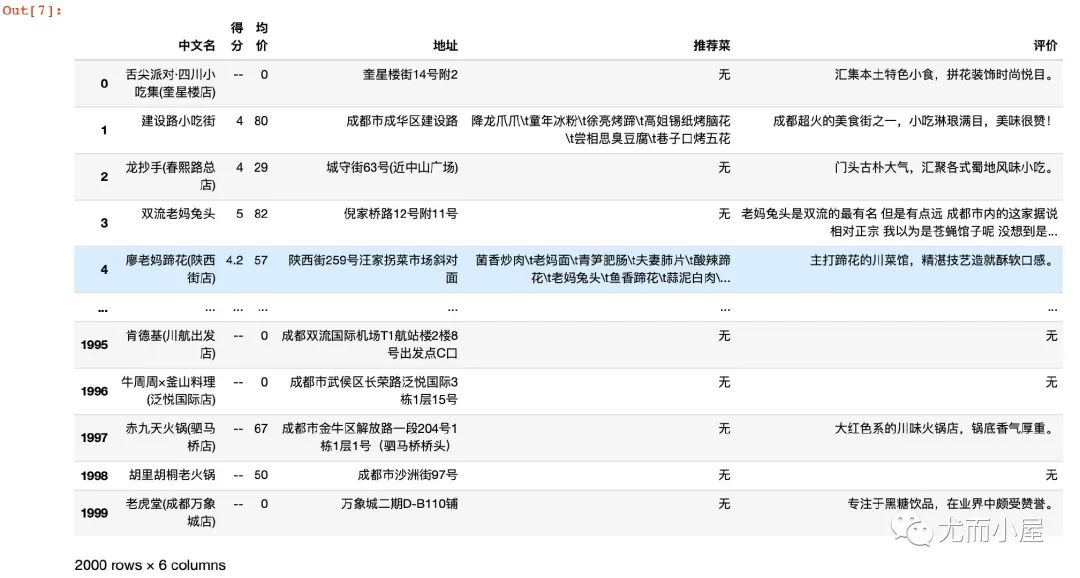
1、读取 CSV 文件
比如曾经爬到的一份成都美食的数据,是 CSV 格式的:
df2 = pd.read_csv("成都美食.csv") # 括号里面填写文件的路径:本文的文件在当然目录下
df2
2、读取 Excel 文件
如果是 Excel 文件,也可以进行读取:
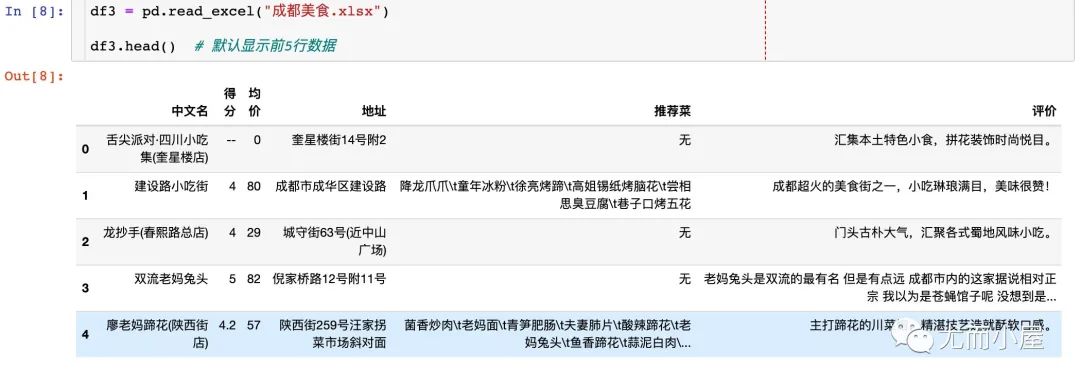
df3 = pd.read_excel("成都美食.xlsx")
df3.head() # 默认显示前5行数据
3、读取 json 文件
比如本地当前目录下有一份 json 格式的数据:
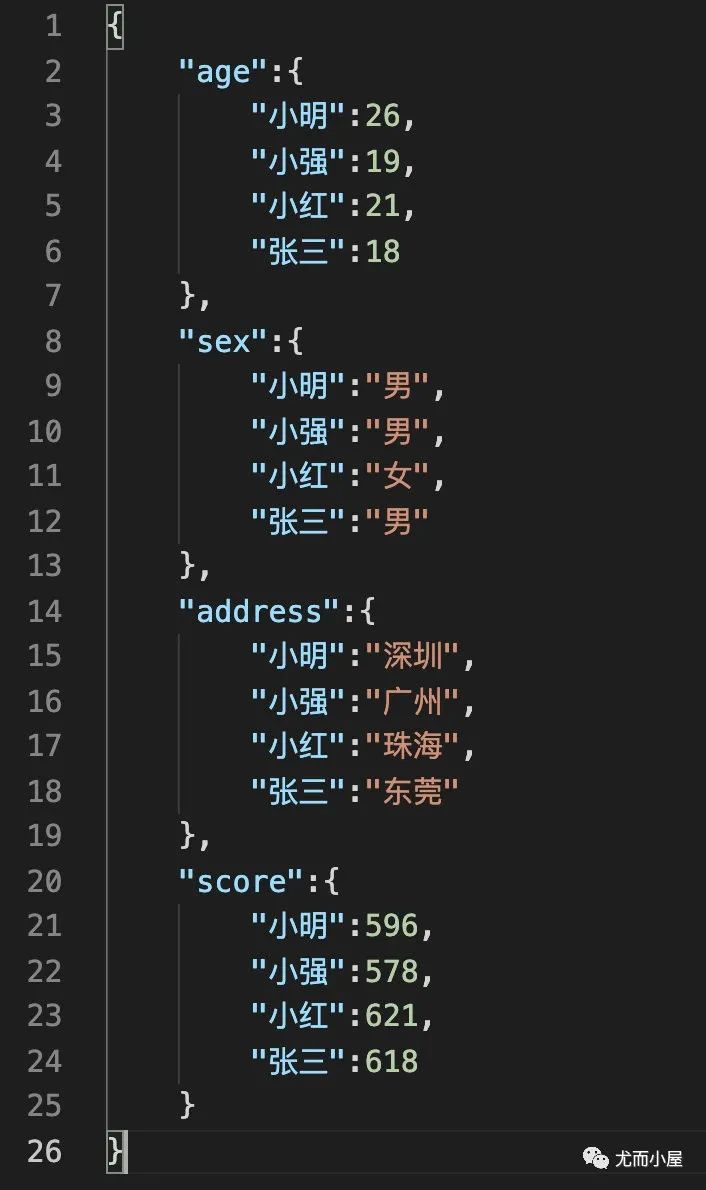
通过 pandas 读取进来:
df4 = pd.read_json("information.json")
df4

4、读取 TXT 文件
本地当前目录有一个 TXT 文件,如下图:

df5 = pd.read_table("text.txt")
df5

上图中如果不指定任何参数:pandas 会将第一行数据作为列字段(不是我们想要的结果),指定参数修改后的代码:
df7 = pd.read_table(
"text.txt", # 文件路径
names=["姓名","年龄","性别","省份"], # 指定列属性
sep=" " # 指定分隔符:空格
)
df7

另外的一种解决方法就是:直接修改 txt 文件,在最上面加上我们想要的列字段属性:这样最上面的一行数据便会当做列字段
姓名 年龄 性别 出生地
小明 20 男 深圳
小红 19 女 广州
小孙 28 女 北京
小周 25 男 上海
小张 22 女 杭州
读取数据库文件创建
1、先安装 pymysql
本文中介绍的是通过 pymysql 库来操作数据库,然后将数据通过 pandas 读取进来,首先要先安装下 pymysql库(假装你会了):
pip install pymysql
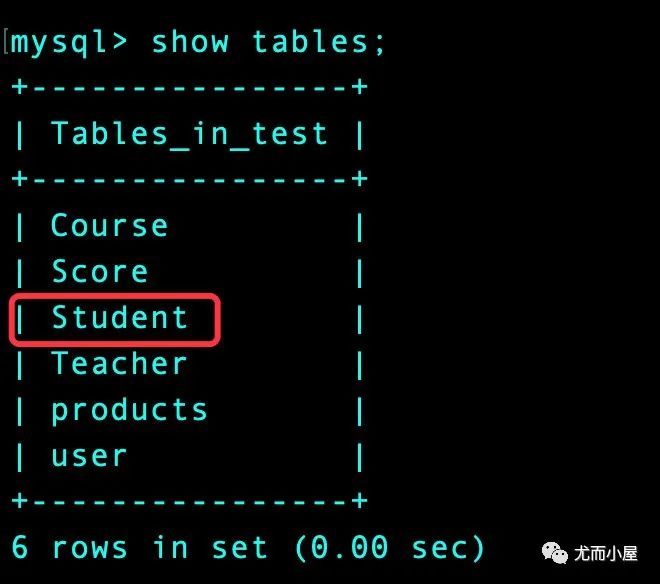
首先看下本地数据库中一个表中的数据:读取 Student 表中的全部数据
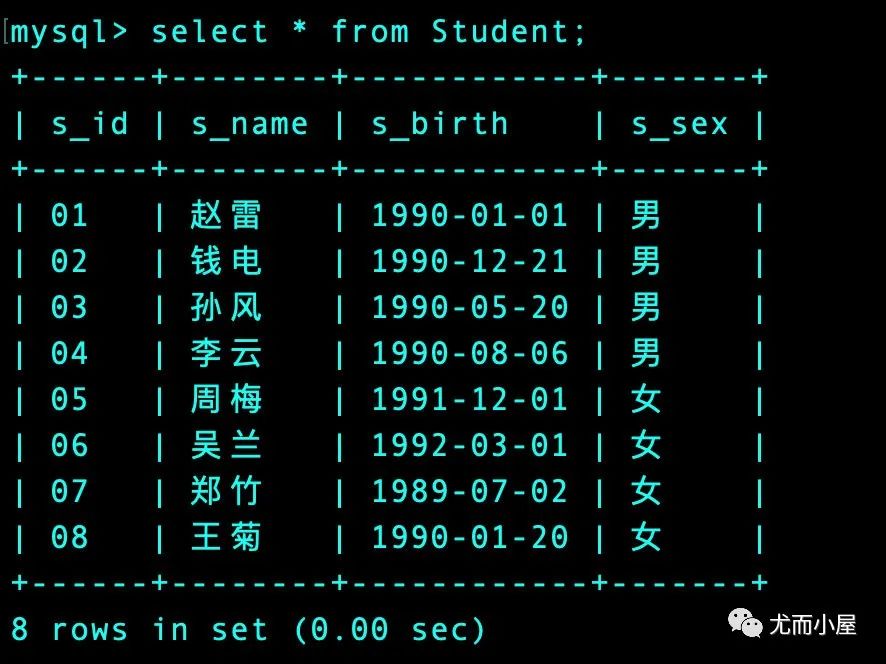
数据真实样子如下图:
2、建立连接
connection = pymysql.connect(
host="IP地址",
port=端口号,
user="用户名",
password="密码",
charset="字符集",
db="库名"
)
cur = connection.cursor() # 建立游标
# 待执行的SQL语句
sql = """
select * from Student
"""
# 执行SQL
cur.execute(sql)
3、返回执行的结果
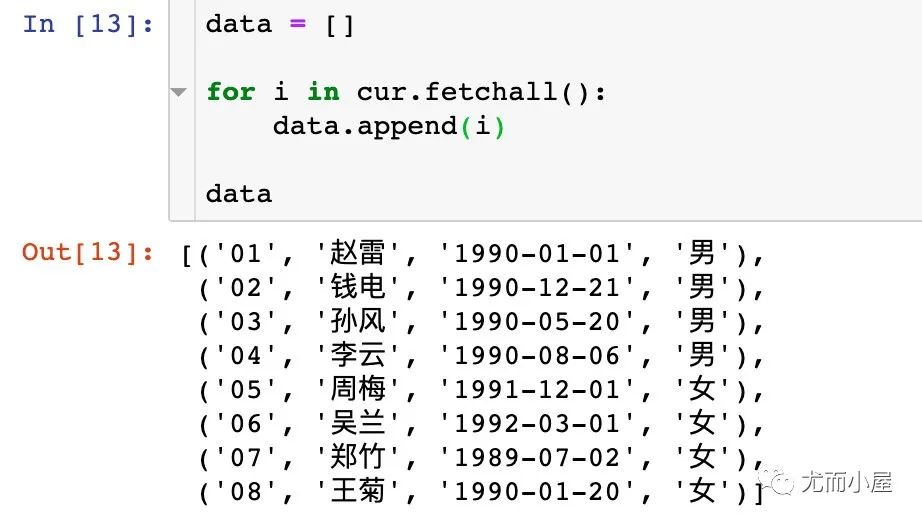
data = []
for i in cur.fetchall():
data.append(i) # 将每条结果追加到列表中
data
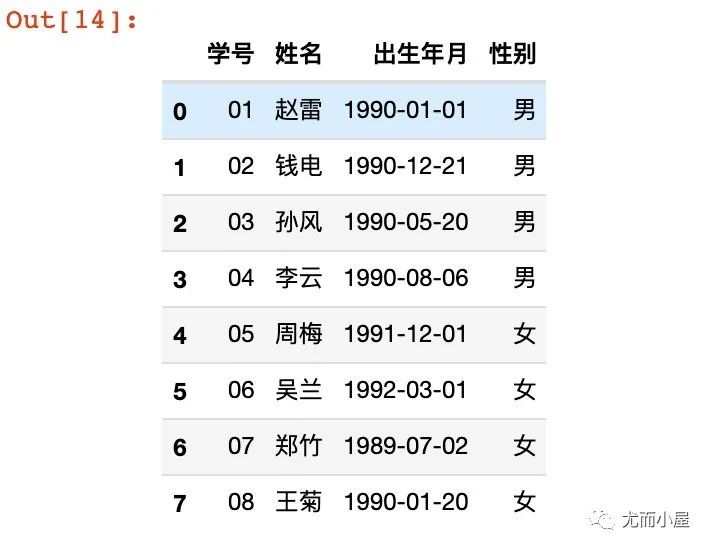
4、创建成 DataFrame 数据
df8 = pd.DataFrame(data,columns=["学号","姓名","出生年月","性别"]) # 指定每个列属性名称
df8
使用 python 字典创建
1、包含列表的字典创建
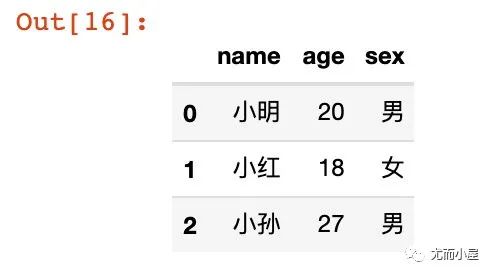
# 1、包含列表的字典
dic1 = {"name":["小明","小红","小孙"],
"age":[20,18,27],
"sex":["男","女","男"]
}
dic1

df9 = pd.DataFrame(dic1,index=[0,1,2])
df9
2、字典中嵌套字典进行创建
# 嵌套字典的字典
dic2 = {'数量':{'苹果':3,'梨':2,'草莓':5},
'价格':{'苹果':10,'梨':9,'草莓':8},
'产地':{'苹果':'陕西','梨':'山东','草莓':'广东'}
}
dic2
# 结果
{'数量': {'苹果': 3, '梨': 2, '草莓': 5},
'价格': {'苹果': 10, '梨': 9, '草莓': 8},
'产地': {'苹果': '陕西', '梨': '山东', '草莓': '广东'}}
创建结果为:

python 列表创建
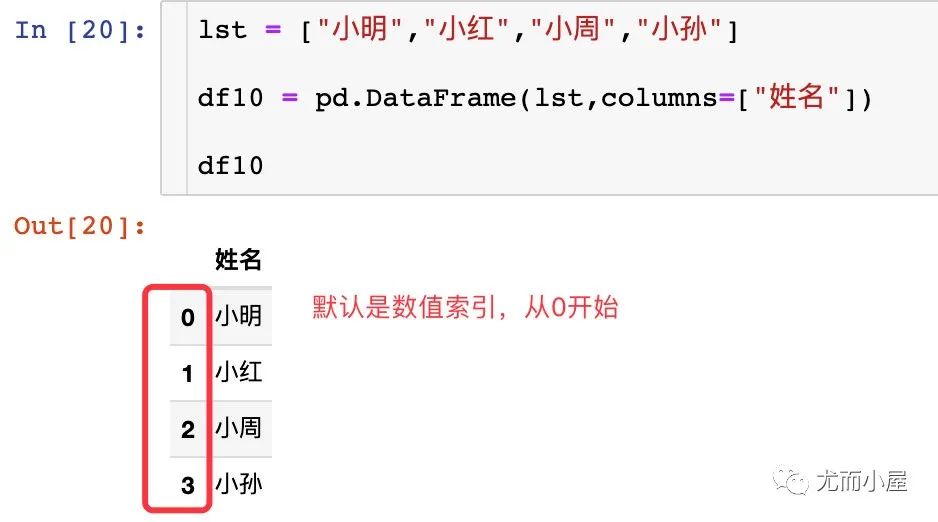
1、使用默认的行索引
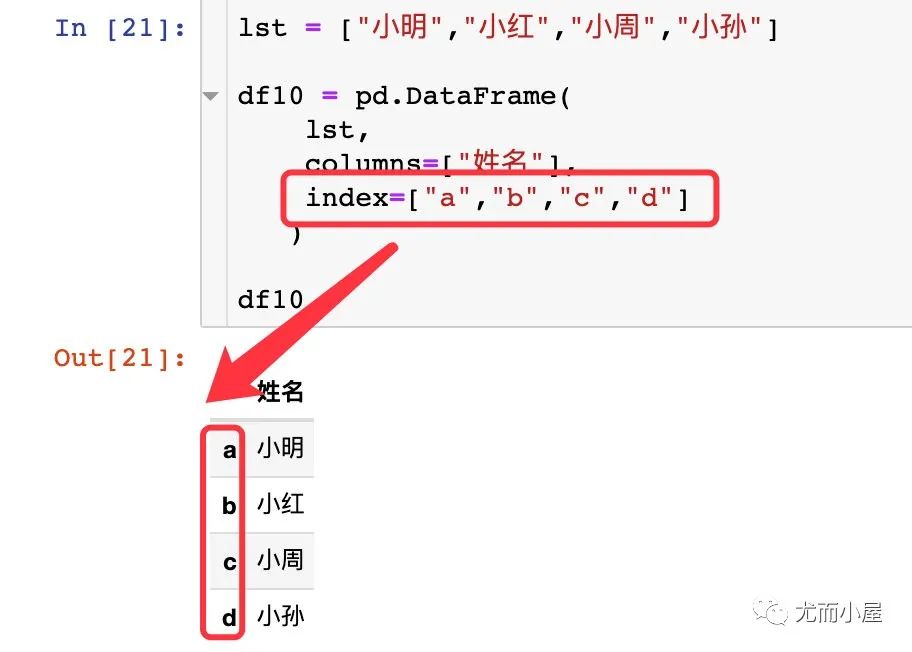
lst = ["小明","小红","小周","小孙"]
df10 = pd.DataFrame(lst,columns=["姓名"])
df10
可以对索引进行修改:
lst = ["小明","小红","小周","小孙"]
df10 = pd.DataFrame(
lst,
columns=["姓名"],
index=["a","b","c","d"] # 修改索引
)
df10
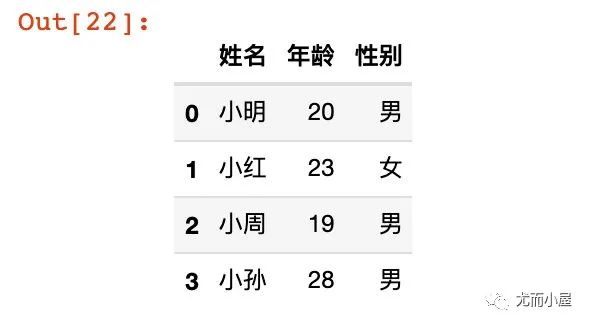
3、列表中嵌套列表
# 嵌套列表形式
lst = [["小明","20","男"],
["小红","23","女"],
["小周","19","男"],
["小孙","28","男"]
]
df11 = pd.DataFrame(lst,columns=["姓名","年龄","性别"])
df11
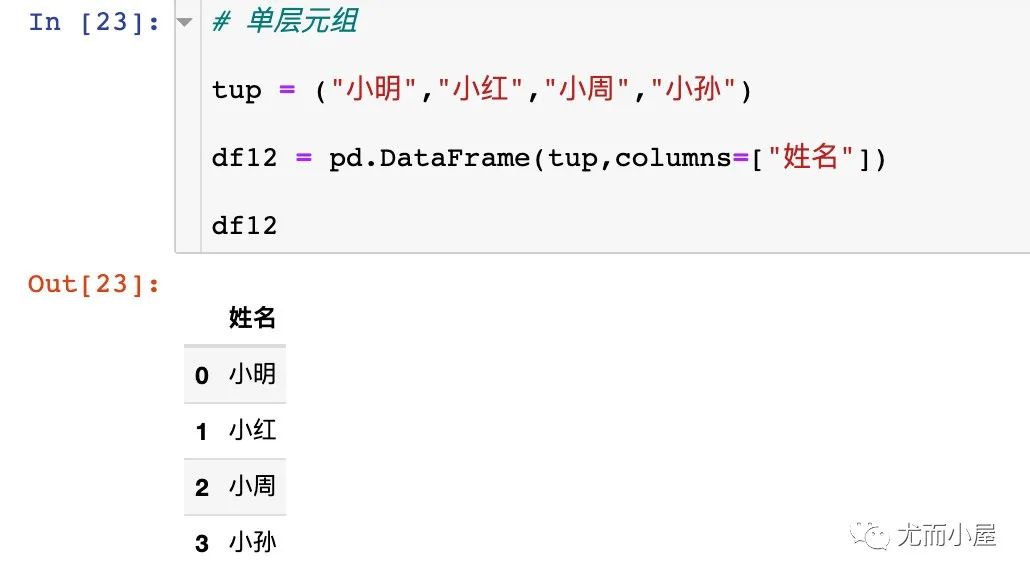
python 元组创建
元组创建的方式和列表比较类似:可以是单层元组,也可以进行嵌套。
1、单层元组创建
# 单层元组
tup = ("小明","小红","小周","小孙")
df12 = pd.DataFrame(tup,columns=["姓名"])
df12
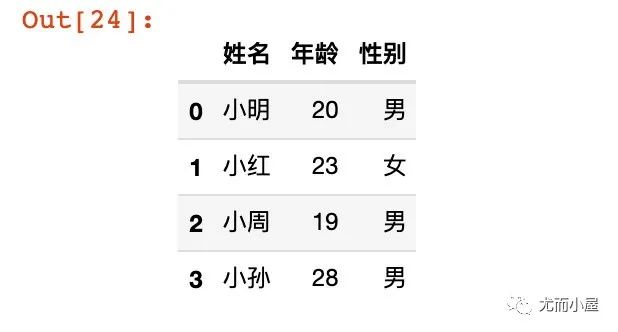
2、元组的嵌套
# 嵌套元组
tup = (("小明","20","男"),
("小红","23","女"),
("小周","19","男"),
("小孙","28","男")
)
df13 = pd.DataFrame(tup,columns=["姓名","年龄","性别"])
df13
使用 Series 创建
DataFrame 是将数个 Series 按列合并而成的二维数据结构,每一列单独取出来是一个 Series ,所以我们可以直接通过Series数据进行创建。
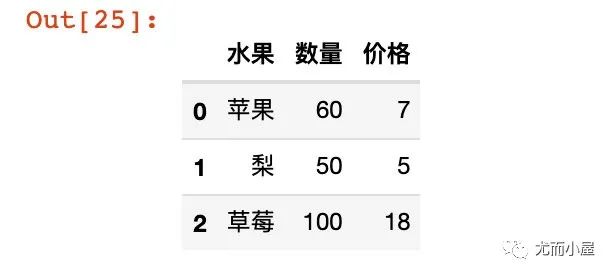
series = {'水果':Series(['苹果','梨','草莓']),
'数量':Series([60,50,100]),
'价格':Series([7,5,18])
}
df15 = pd.DataFrame(series)
df15
numpy 数组创建
1、使用 numpy 中的函数进行创建
# 1、使用numpy生成的数组
data1 = {
"one":np.arange(4,10), # 产生6个数据
"two":range(100,106),
"three":range(20,26)
}
df16 = pd.DataFrame(
data1,
index=['A','B','C','D','E','F'] # 索引长度和数据长度相同
)
df16

2、直接通过 numpy 数组创建
# 2、numpy数组创建
# reshape()函数改变数组的shape值
data2 = np.array(["小明","广州",175,"小红","深圳",165,"小周","北京",170,"小孙","上海",180]).reshape(4,3)
data2

df17 = pd.DataFrame(
data2, # 传入数据
columns=["姓名","出生地","身高"], # 列属性
index=[0,1,2,3] # 行索引
)
df17

3、使用 numpy 中的随机函数
# 3、numpy中的随机函数生成
# 创建姓名、学科、学期、班级4个列表
name_list = ["小明","小红","小孙","小周","小张"]
subject_list = ["语文","数学","英文","生物","物理","地理","化学","体育"]
semester_list = ["上","下"]
class_list = [1,2,3]
# 生成40个分数:在50-100之间
score_list = np.random.randint(50,100,40).tolist() # 50-100之间选择40个数
随机生成的 40 个分数:

通过 numpy 中的 random 模块的 choice 方法进行数据的随机生成:
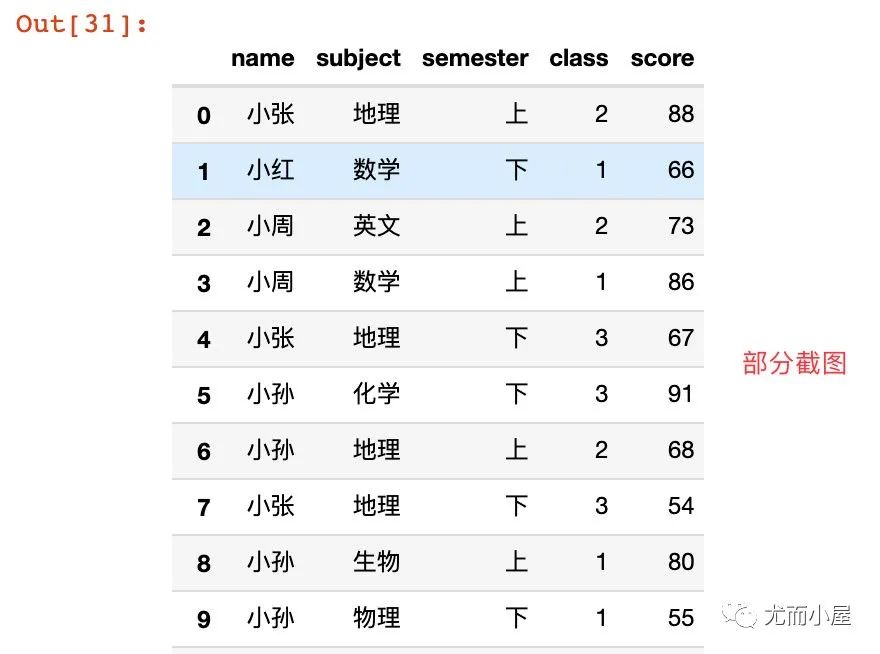
df18 = pd.DataFrame({
"name": np.random.choice(name_list,40,replace=True), # replace=True表示抽取后放回(默认),所以存在相同值
"subject": np.random.choice(subject_list,40),
"semester": np.random.choice(semester_list,40),
"class":np.random.choice(class_list,40),
"score": score_list
})
df18
使用构建器 from_dict
pandas中有一个和字典相关的构建器:DataFrame.from_dict 。
它接收字典组成的字典或数组序列字典,并生成 DataFrame。除了 orient 参数默认为 columns,本构建器的操作与 DataFrame 构建器类似。把 orient 参数设置为 'index', 即可把字典的键作为行标签。
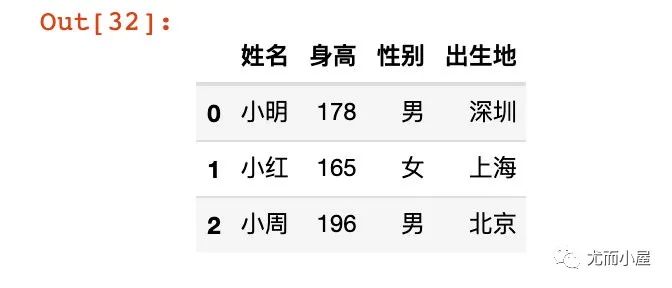
df19 = pd.DataFrame.from_dict(dict([('姓名', ['小明', '小红', '小周']),
('身高', [178, 165, 196]),
('性别',['男','女','男']),
('出生地',['深圳','上海','北京'])
])
)
df19
还可以通过参数指定行索引和列字段名称:
df20 = pd.DataFrame.from_dict(dict([('姓名', ['小明', '小红', '小周']),
('身高', [178, 165, 196]),
('性别',['男','女','男']),
('出生地',['深圳','上海','北京'])
]),
orient='index', # 将字典的键作为行索引
columns=['one', 'two', 'three'] # 指定列字段名称
)
df20

使用构建器 from_records
pandas中还有另一个支持元组列表或结构数据类型(dtype)的多维数组的构建器:from_records
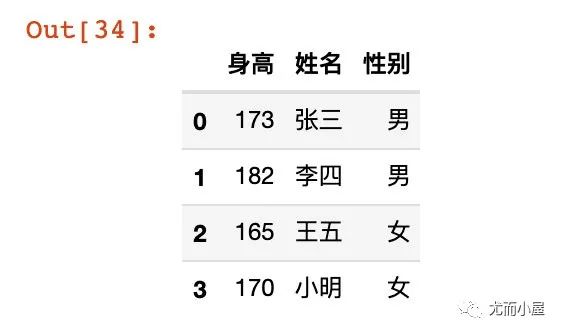
data3 = [{'身高': 173, '姓名': '张三','性别':'男'},
{'身高': 182, '姓名': '李四','性别':'男'},
{'身高': 165, '姓名': '王五','性别':'女'},
{'身高': 170, '姓名': '小明','性别':'女'}]
df21 = pd.DataFrame.from_records(data3)
df21
还可以传入列表中嵌套元组的结构型数据:
data4 = [(173, '小明', '男'),
(182, '小红', '女'),
(161, '小周', '女'),
(170, '小强', '男')
]
df22 = pd.DataFrame.from_records(data4,
columns=['身高', '姓名', '性别']
)
df22

总结
DataFrame 是 pandas 中的二维数据结构,即数据以行和列的表格方式排列,类似于 Excel 、SQL 表,或 Series 对象构成的字典。它在 pandas 中是经常使用,本身就是多个 Series 类型数据的合并。
本文介绍了10 种不同的方式创建 DataFrame,最为常见的是通过读取文件的方式进行创建,然后对数据帧进行处理和分析。希望本文能够对读者朋友掌握数据帧 DataFrame 的创建有所帮助。