
结合源码彻底讲解Aggregate vs treeAggregate
Aggregate
本文主要是讲解两个常见的聚合操作:aggregate vs treeAggregate
首先讲解aggregate,该函数的方法具体名称如下:
def aggregate[U: ClassTag](zeroValue: U)(seqOp: (U, T) => U, combOp: (U, U) => U): U = withScope {// Clone the zero value since we will also be serializing it as part of tasksvar jobResult = Utils.clone(zeroValue, sc.env.serializer.newInstance())val cleanSeqOp = sc.clean(seqOp)val cleanCombOp = sc.clean(combOp)val aggregatePartition = (it: Iterator[T]) => it.aggregate(zeroValue)(cleanSeqOp, cleanCombOp)val mergeResult = (index: Int, taskResult: U) => jobResult = combOp(jobResult, taskResult)sc.runJob(this, aggregatePartition, mergeResult)jobResult}
参数定义:
首先可以看到,有个U类型的参数叫做zeroValue,然后有两个方法参数,第一个是seqOp: (U, T) => U将U和T类型的数据转化为T类型的数据,第二个函数combOp: (U, U) => U将两个U类型的数据转化为U类型,返回的是一个U类型的数据。
参数作用:
zeroValue是给定的初始值,该值将会在seqOp和combOp两个函数中都使用。
seqOp在Executor端对每个分区进行操作,会用到初始值zeroValue。
combOp在driver端执行,也会用到初始值。
源码简介:
片段一:
val aggregatePartition = (it: Iterator[T]) => it.aggregate(zeroValue)(cleanSeqOp, cleanCombOp)这个源码就是针对每个RDD分区,进行执行的时候的函数,因为实际上每个分区最终都是一个迭代器,然后执行迭代器的aggregate,参数也是我们给定的参数。Iterator 的aggregate方法实际上三个参数是没有用到的,也即CombOp没有用到。
片段二:
val mergeResult = (index: Int, taskResult: U) => jobResult = combOp(jobResult, taskResult)该段代码是在Driver端执行combOp操作。
具体的执行逻辑不是本文要讲解的主要内容,后面有机会浪尖会逐步给大家分析。
由上面我们可以总结,aggregate执行结构图,如下:

这种聚合操作是有缺陷的,就是所有SeqOp操作对分区的执行结果都只能全部返回给Driver端,然后在对返回的结果和初始值执行CombOp操作,这样数据量大的时候很容易导致Driver端内存溢出,所以,就出现了优化函数treeAggregate。
treeAggregate
treeAggregate函数的具体内容如下:
def treeAggregate[U: ClassTag](zeroValue: U)(seqOp: (U, T) => U,combOp: (U, U) => U,depth: Int = 2): U = withScope {require(depth >= 1, s"Depth must be greater than or equal to 1 but got $depth.")if (partitions.length == 0) {Utils.clone(zeroValue, context.env.closureSerializer.newInstance())} else {val cleanSeqOp = context.clean(seqOp)val cleanCombOp = context.clean(combOp)val aggregatePartition =(it: Iterator[T]) => it.aggregate(zeroValue)(cleanSeqOp, cleanCombOp)var partiallyAggregated = mapPartitions(it => Iterator(aggregatePartition(it)))var numPartitions = partiallyAggregated.partitions.lengthval scale = math.max(math.ceil(math.pow(numPartitions, 1.0 / depth)).toInt, 2)// If creating an extra level doesn't help reduce// the wall-clock time, we stop tree aggregation.// Don't trigger TreeAggregation when it doesn't save wall-clock timewhile (numPartitions > scale + math.ceil(numPartitions.toDouble / scale)) {numPartitions /= scaleval curNumPartitions = numPartitionspartiallyAggregated = partiallyAggregated.mapPartitionsWithIndex {(i, iter) => iter.map((i % curNumPartitions, _))}.reduceByKey(new HashPartitioner(curNumPartitions), cleanCombOp).values}partiallyAggregated.reduce(cleanCombOp)}}
参数定义:
首先可以看到,有个U类型的参数叫做zeroValue,然后有两个方法参数,第一个是seqOp: (U, T) => U将U和T类型的数据转化为T类型的数据,第二个函数combOp: (U, U) => U将两个U类型的数据转化为U类型,返回的是一个U类型的数据。
参数作用:
zeroValue是给定的初始值,该值将会在seqOp和combOp两个函数中都使用。
seqOp在Executor端对每个分区进行操作,会用到初始值zeroValue。
combOp在Executor端和driver端都会执行,不会用到初始值。
源码简介:
片段一:
val aggregatePartition =(it: Iterator[T]) => it.aggregate(zeroValue)(cleanSeqOp, cleanCombOp)var partiallyAggregated = mapPartitions(it => Iterator(aggregatePartition(it)))
在Executor端执行的第一层任务,主要操作是对源数据和初始值zeroValue执行seqOp操作。
片段二:
var numPartitions = partiallyAggregated.partitions.lengthval scale = math.max(math.ceil(math.pow(numPartitions, 1.0 / depth)).toInt, 2)while (numPartitions > scale + math.ceil(numPartitions.toDouble / scale)) {numPartitions /= scaleval curNumPartitions = numPartitionspartiallyAggregated = partiallyAggregated.mapPartitionsWithIndex {(i, iter) => iter.map((i % curNumPartitions, _))}.reduceByKey(new HashPartitioner(curNumPartitions), cleanCombOp).values}
在执行完成第一层任务之后,执行combOp操作,主要是逐渐降低分区数,来逐层进行combOp操作,该操作是在Executor端执行,并且该操作并未用到初始值。
片段三:
partiallyAggregated.reduce(cleanCombOp)在Executor端初步聚合后,对结果数据使用combOp操作再次执行reduce操作。
由上面我们可以总结,aggregate执行结构图,如下:
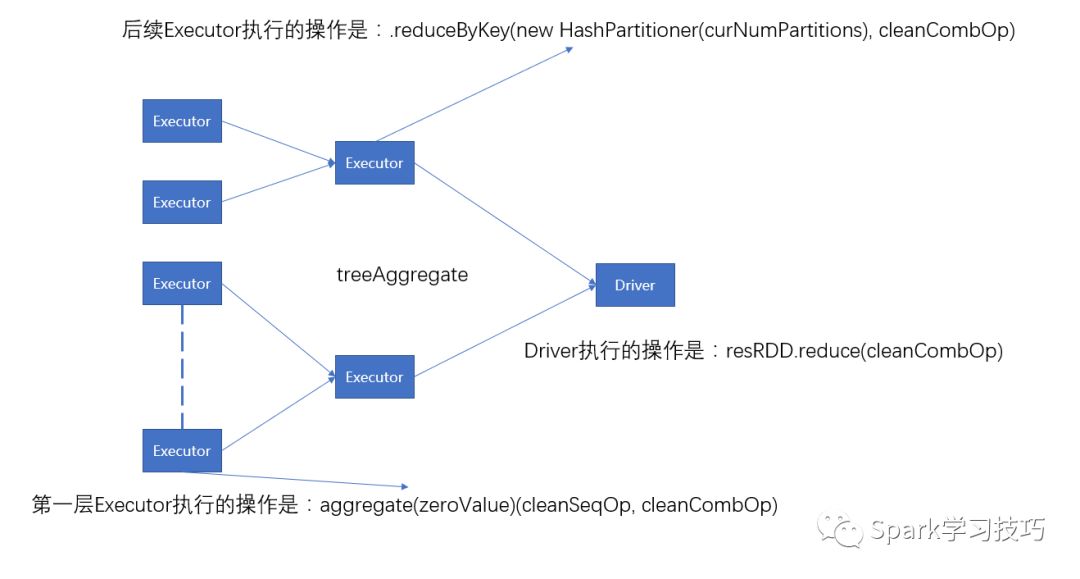
aggregate VS treeAggregate
1, aggregate和treeAggregate的作用一样,最终的结果区别是treeAggregate执行combOp并没有用到初始值zeroValue。
2,treeAggregate比aggregate多执行了n次任务,n可计算。
3,treeAggregate降低了aggregate在driver端内存溢出的风险。
可以举个例子:
def seq(a:Int,b:Int):Int={println("seq:"+a+":"+b)a+b}def comb(a:Int,b:Int):Int={println("comb:"+a+":"+b)a+b}val res = sc.parallelize(List(1,2,4,5,8,9,7,2),3)res.aggregate(1)(seq,comb)res.treeAggregate(1)(seq,comb)
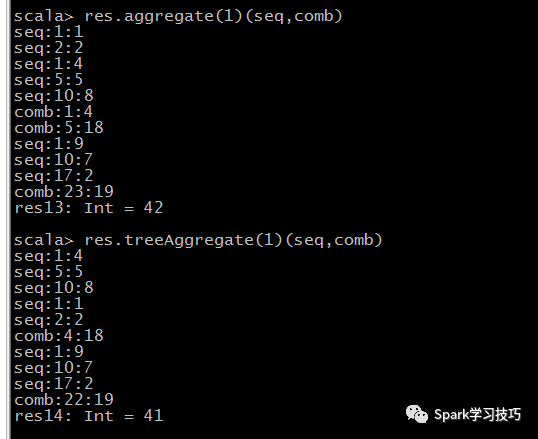
aggregate结果应该是:1+2+4+5+8+9+7+2+3*1 +1=42
treeAggregate结果应该是:1+2+4+5+8+9+7+2+3*1=41
推荐阅读: