
图神经网络入门必读: 一文带你梳理GCN, GraphSAGE, GAT, GAE, Pooling, DiffPool
笔者注:行文如有错误或者表述不当之处,还望批评指正!
一、为什么需要图神经网络?
图的大小是任意的,图的拓扑结构复杂,没有像图像一样的空间局部性 图没有固定的节点顺序,或者说没有一个参考节点 图经常是动态图,而且包含多模态的特征
二. 图神经网络是什么样子的?
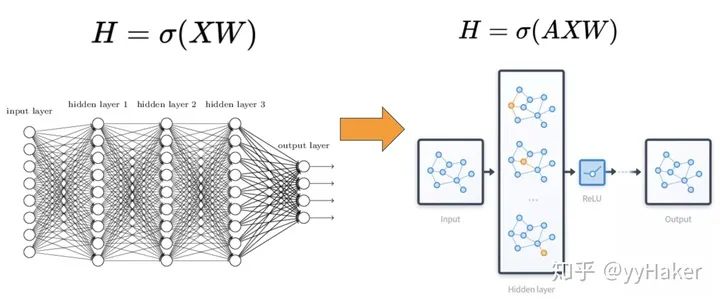
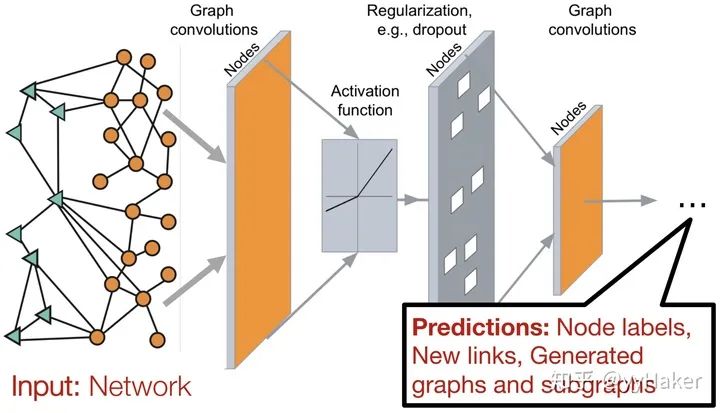
三、图神经网络的几个经典模型与发展
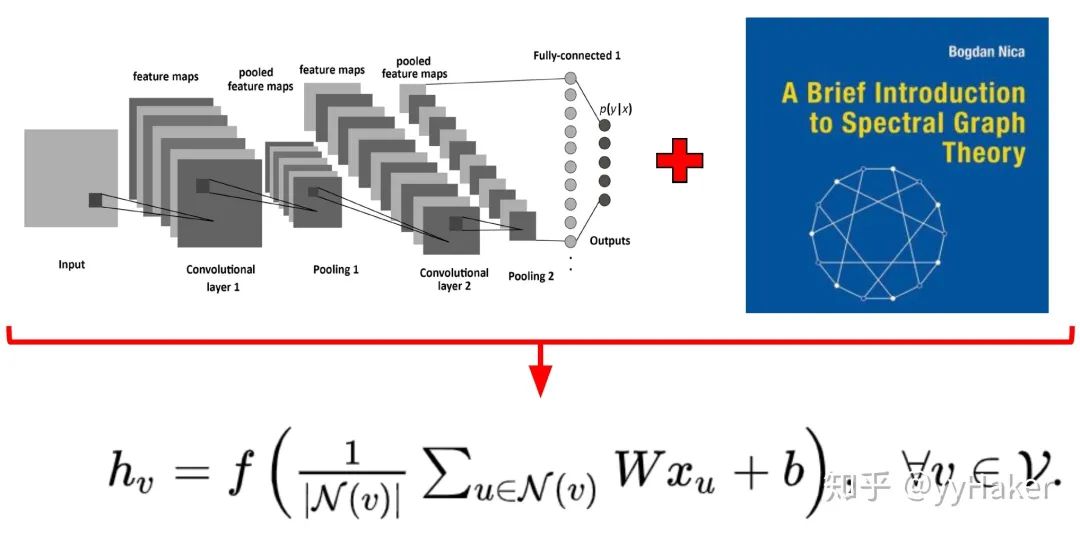
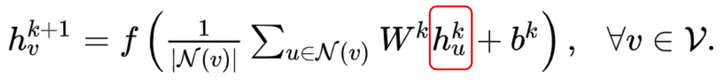
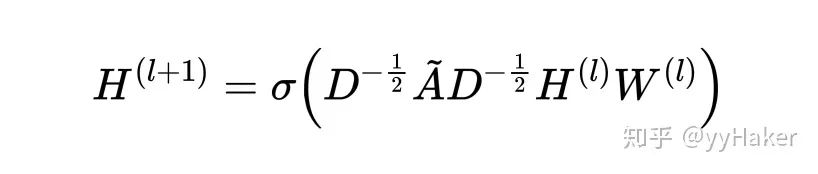
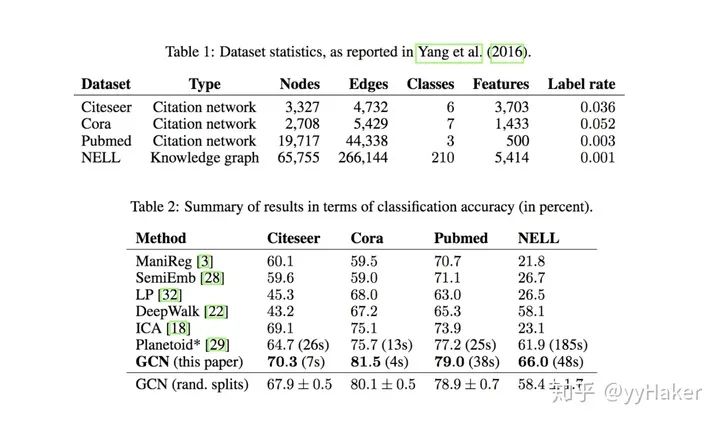
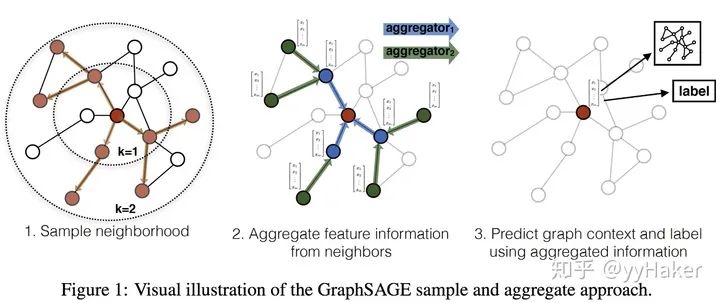

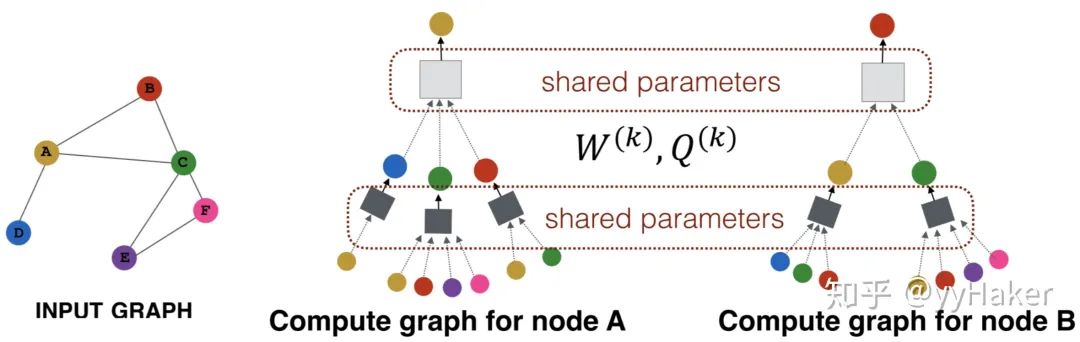


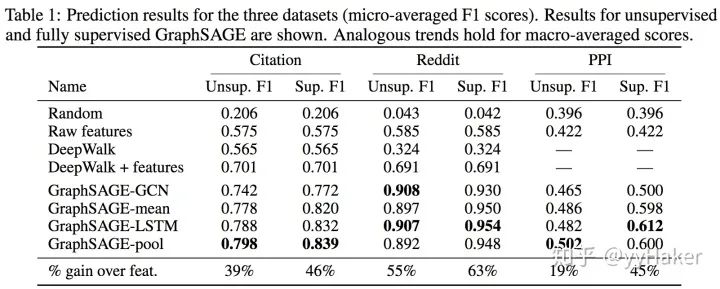
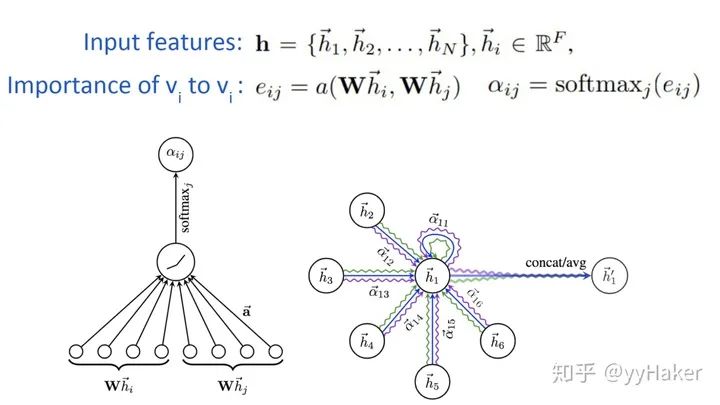
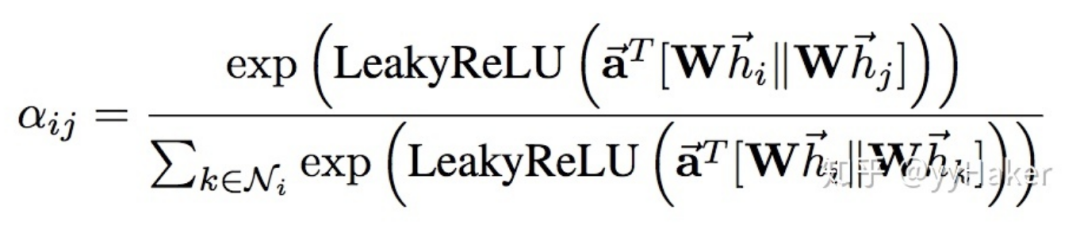
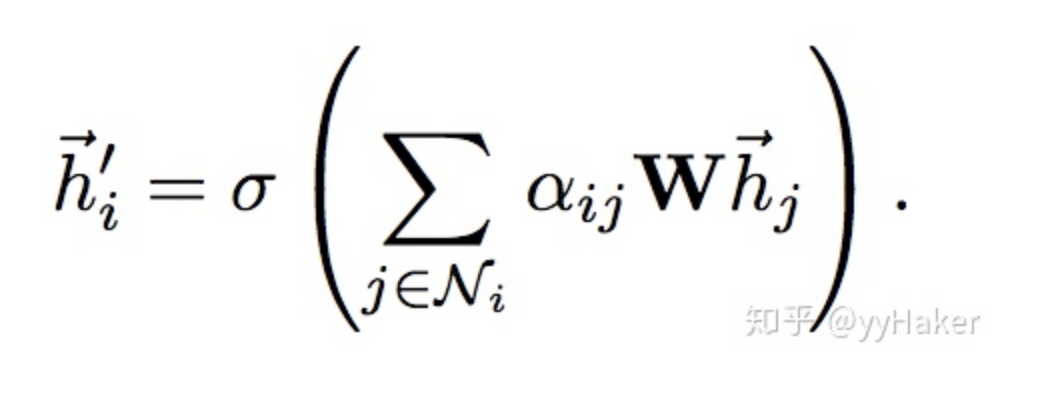
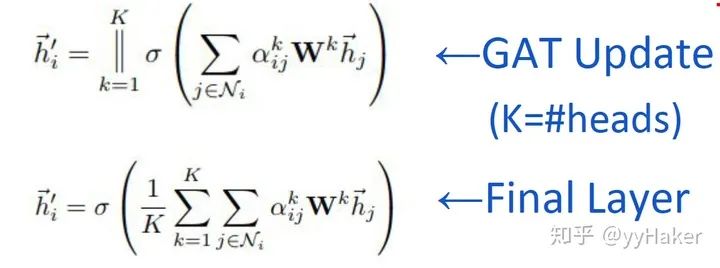
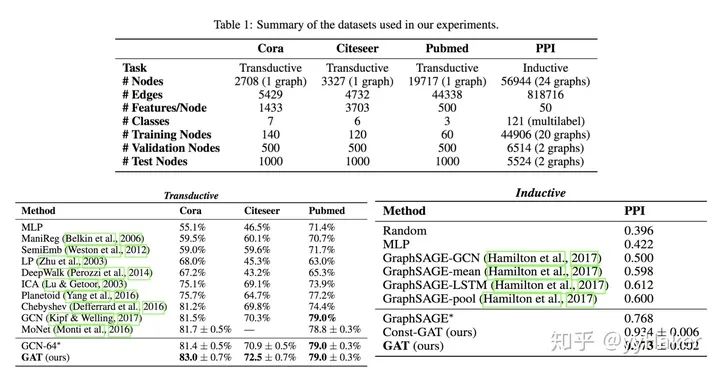
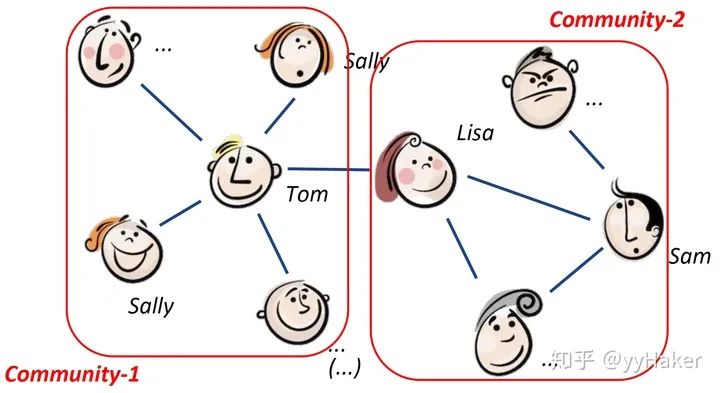
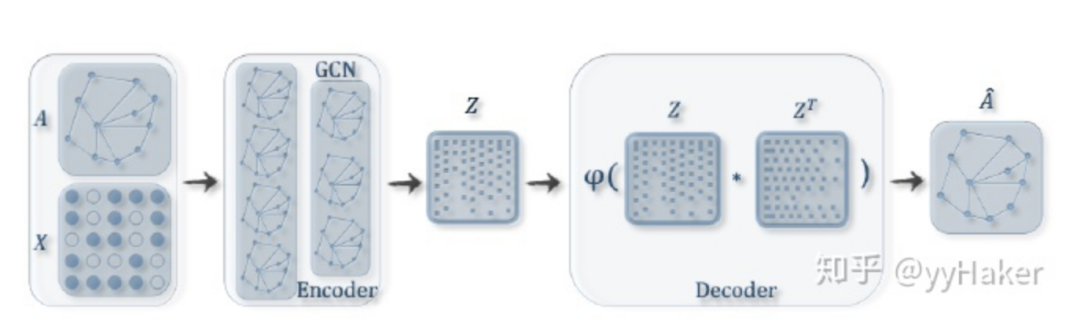
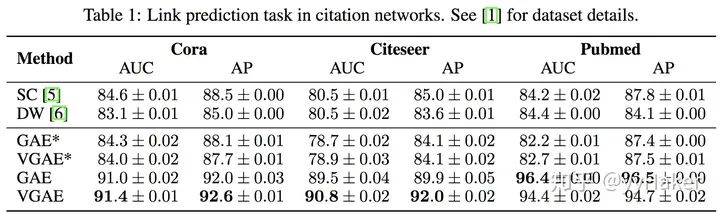
Graph Auto-Encoder(GAE)[10]

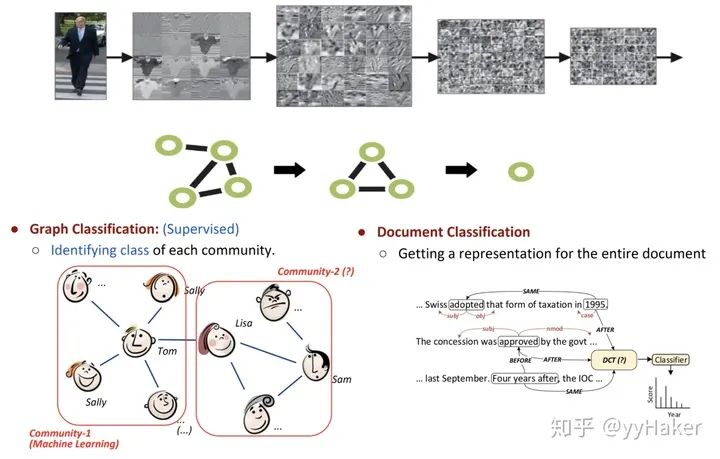
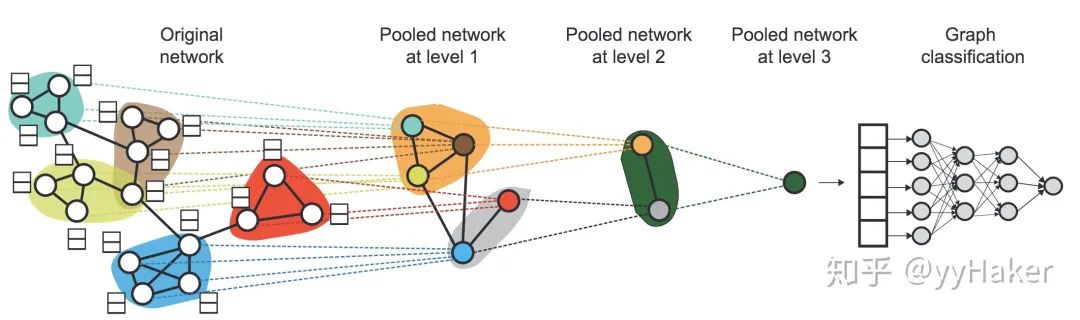
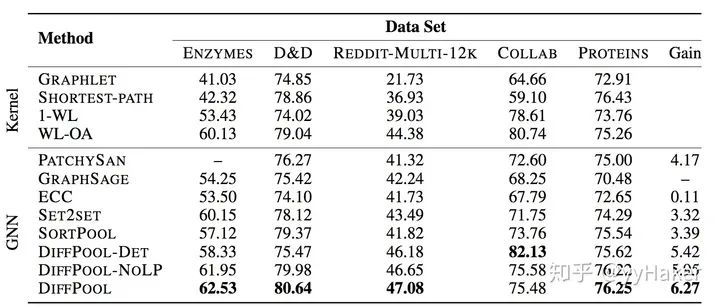
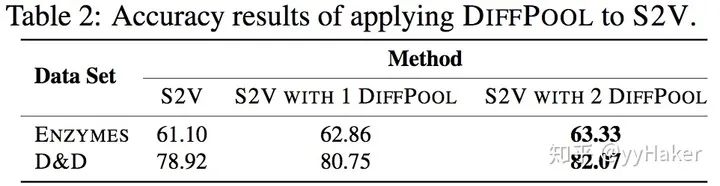
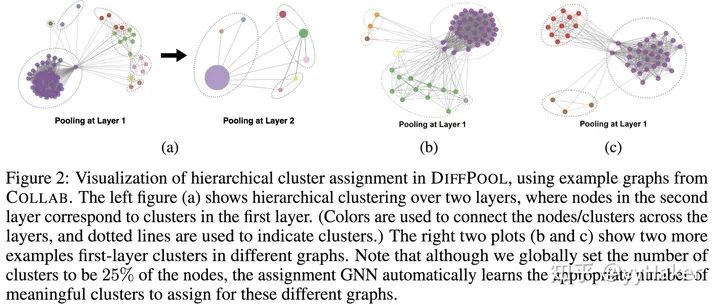
分配矩阵的学习
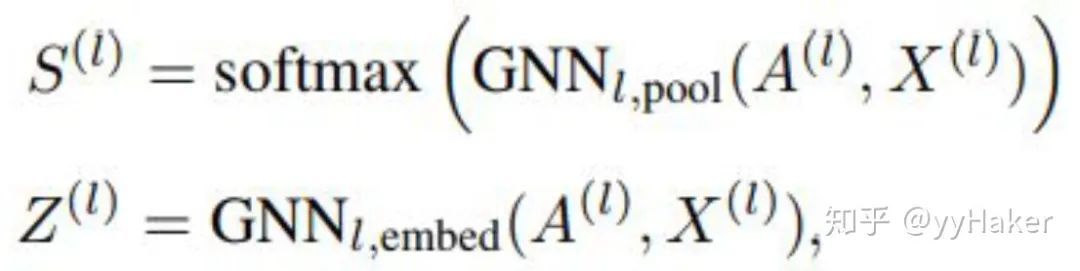
池化分配矩阵
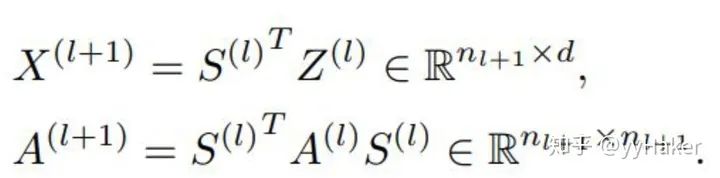
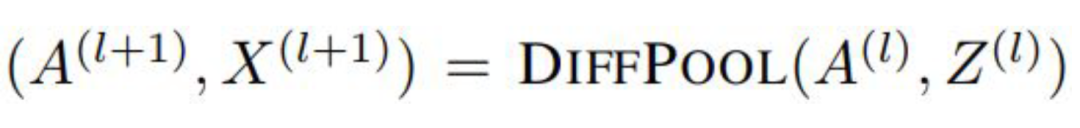
参考
 End
End
声明:部分内容来源于网络,仅供读者学术交流之目的,文章版权归原作者所有。如有不妥,请联系删除。
评论