
遮挡人脸问题 | 详细解读Attention-Based方法解决遮挡人脸识别问题(附论文下载)


1简介
在非约束性环境(如大量人群)中捕获的人脸照片,仍然对当前的人脸识别方法构成挑战,因为人脸经常被前景中的物体或人遮挡。然而,很少有研究涉及到识别部分面孔的任务。

本文提出了一种新的遮挡人脸识别方法,能够识别不同遮挡区域的人脸。通过将一个ResNet中间特征映射的attentional pooling与一个单独的聚合模块相结合来实现这一点。为了保证attention map的多样性,并处理被遮挡的部分,作者进一步对遮挡Face的常见损失函数进行了调整。实验表明,在多个benchmark下本文方法的性能优于所有baseline。
本文工作贡献可以概括为以下几点:
以ResNet为例,利用attentional pooling和聚合网络提出了一种新的扩展,并使用2种适用于部分FR的常见损失函数进行训练;
在多个局部FR的详尽分析中表明,本文的改进大大提高了识别性能。
2方法
2.1 Network Architecture
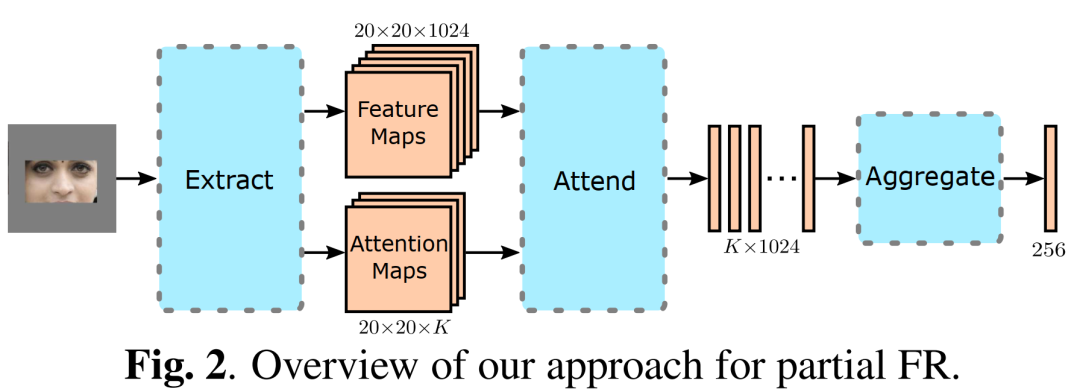
下图描述了partial FR方法,分为3个模块:Extract、Attend和Aggregate。
Extract模块从输入图像中提取特征图和attention maps ,其中K表示attention maps的个数。
在Attend模块中,使用重新校准的attention maps将特征图合并为K个中间特征向量。
Aggregate模块将这些中间特征向量映射到联合特征空间中,得到最终特征向量$f\in R^{256}。
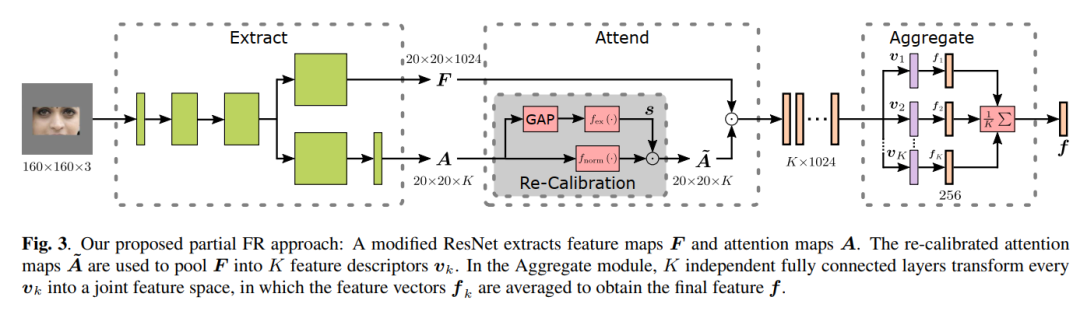
1 Extract
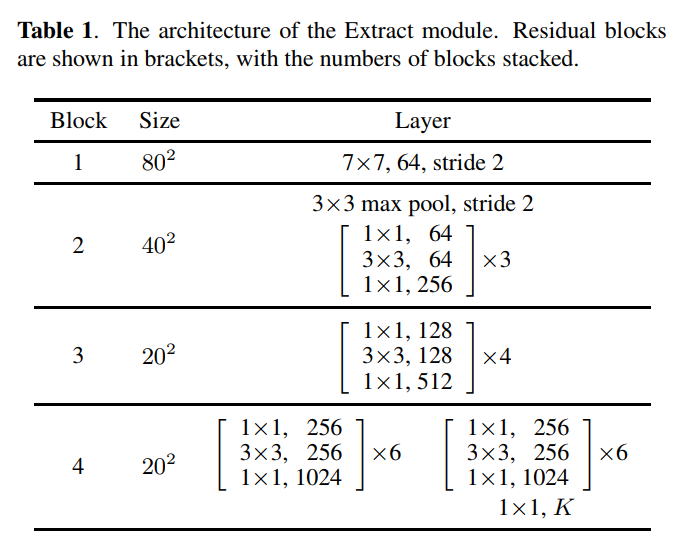
受Comparator networks启发,作者使用了一个删减的ResNet-50架构,它在第4个block之后结束。因此,只进行了3次空间降采样,得到了大小为20×20的特征图,其中区域仍然具有很好的可区分性。与Comparator networks不同的是,在第3个block之后分离ResNet,以允许2个分支专注于各自的任务。而在第4个block之后直接得到F,然后再加上一个1×1的卷积以及ReLU激活函数获取a。具体架构总结如表1所示。
生成的attention maps应满足以下2个关键属性:
attention maps应是互斥的,即不同的attention maps聚焦于人脸图像的不同区域; attention maps的激活与区域的可见性相关。
值得注意的是,implicitly-defined attention maps激活并不一定遵循人类定义的面部标志(如眼睛或鼻子)的直觉。
2 Attend
和Comparator networks一样,attention maps A需要重新校准。Xie等人提出了基于集的FR归一化A的attentional pooling方法,对集合内的所有图像分别进行归一化,从而确保从A中激活程度最大的图像中提取出各自的信息。
本文作者只考虑一个单一的图像,并期望不同的attention maps是相关的,因为这些主要取决于脸部的区域,即,如果眼睛被遮挡,相应的attention maps应该包含低激活值。因此,建议使用无参数的重新标定:
首先,用sigmoid函数对A进行normalize。这样,每个attention maps的每个像素分别归一化为(0,1);此外,先使用Global Average Pooling (GAP),然后使用,计算一个向量$s\in R^K}表示每个attention maps的重要性:
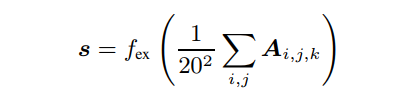
索引表示第个attention maps的第行和第列的像素。通过引入GAP获得了所有attention maps的全局信息,并利用softmax函数将其转化为指示各attention maps重要性的概率分布。接下来,将第个自归一化的attention maps 与其相应的重要性相乘,得到最终的重新校准的attention maps 。
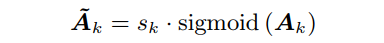
因此,在重新校准中将每个attention maps中的局部信息与跨attention maps的全局信息结合在一起。
重新校准后,应用attentional pooling,得到K个特征描述子:
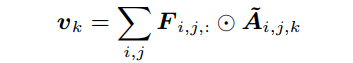
这样,第个特征描述符中就包含了对应attention maps 激活时的信息。
3 Aggregate
用Aggregate模块来总结partial FR模型。由于所有的特征描述符依赖于它们对应的attention maps 聚焦于内的不同区域,所以不可能进行直接聚合。因此,将每个分别映射到一个联合特征空间,每个使用一个单独的全连接层。
注意,由于每个都在不同的特征空间中,所以权重不是共享的。由于同样对身份信息进行编码,所以通过计算平均值得到最终的特征向量:
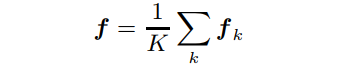
2.2 Loss Functions
为了训练模型,作者使用3个损失的加权和,其描述如下:
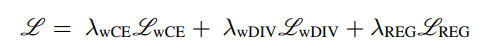
用、和表示超参数来平衡损失,为所有可训练权重的范数。
1 Weighted Cross-Entropy
为了处理一些代表被遮挡区域的向量,从而降低相关性,作者提出了一种加权的softmax CrossEntropy(CE)。对于CE损失添加一个全连接层到每个特征向量匹配训练数据集中类的数量。通过这种方法得到了K CE损失。为了得到最终加权CE损失,对每个及其重要性进行了scale:
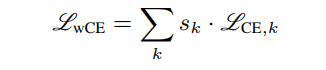
通过这种方式,该网络学习强调代表可见人脸区域的attention maps,同时减轻代表遮挡区域的attention maps的影响。需要注意的是,由于最后一个全连接层的权值是共享的,所以每个的转换是相等的,因此,要保证它们同样编码身份信息,即位于相同的特征空间。此外,由于训练数据集中有大量的类,作为瓶颈层提高了网络的泛化能力。
2 Weighted Diversity Regularizer
多样性正则化的目的是确保attention maps的多样性,因为如果不进行正则化,网络容易倾向于只使用一个attention maps或生成K个相同的attention maps。因此作者使用多样性正则化算法来惩罚不同attention maps之间的相互重叠。首先,使用softmax函数将每个attention maps 自归一化为概率分布:
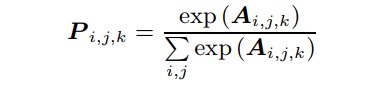
接下来,计算所有的像素级最大值,并得到所有像素的和。对于互不重叠的attention maps,这个和接近于1,可以计算加权多样性损失如下:
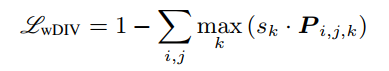
3实验

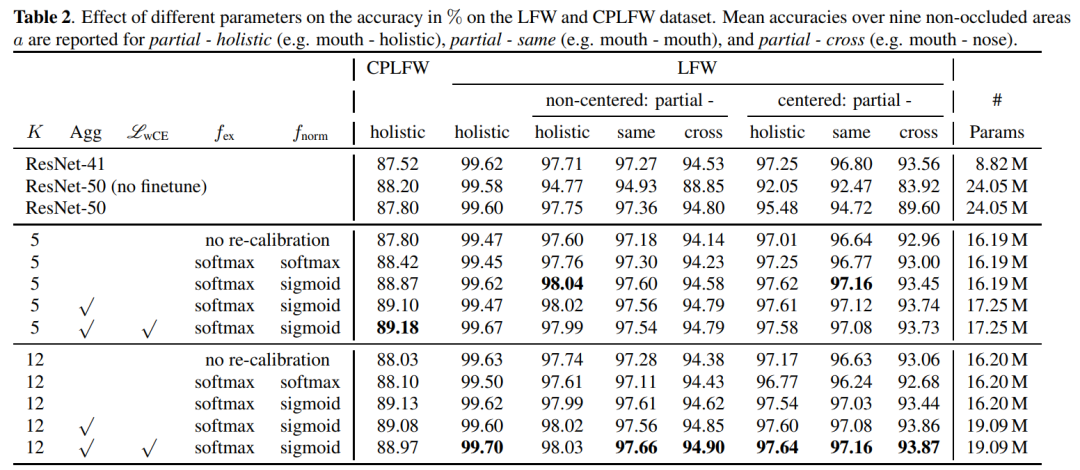
表2描述了LFW数据集上不同benchmark protocols的聚合精度。当考虑一个ResNet-50(没有微调),它在训练期间从未暴露于部分脸,可以观察到标准FR模型非常容易受到partial faces的影响。通过对partial faces进行微调,该模型在partial protocols上表现得更好。ResNet-50在非non-centered protocols上的性能优于ResNet-41,但在centered protocols上的性能较差。作者认为这是由于ResNet-50包含更多可训练参数。因此,由于中心不是数据扩充的一部分,它更容易对训练过程中呈现的空间信息进行过拟合。
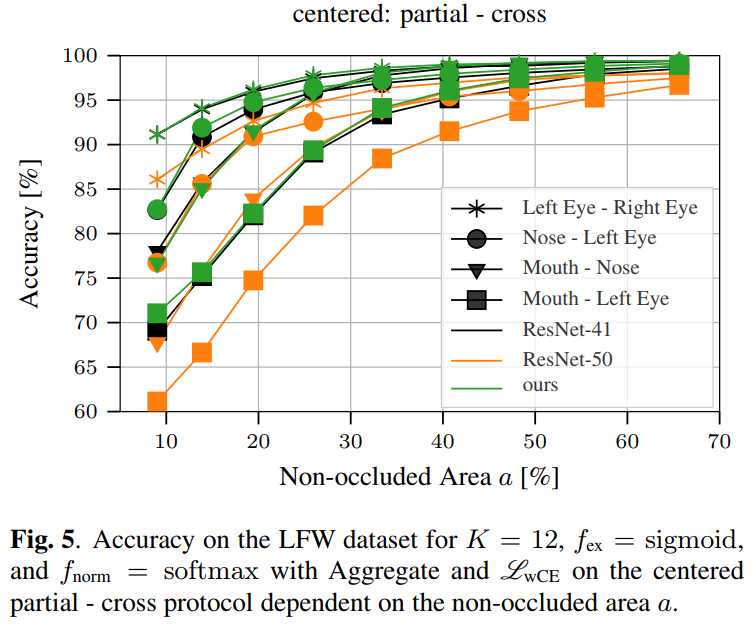
在图中,中心部分面非遮挡区域a的影响:partial - cross protocol。虽然识别左眼-右眼的准确性只受到a的轻微影响,但验证左眼-嘴是否属于同一身份被认为是最具挑战性的。总的来说可以得出结论,本文模型比所有centered: partial-cross的baseline更稳健。
4参考
[1].ATTENTION-BASED PARTIAL FACE RECOGNITION
[2].https://github.com/stefhoer/PartialLFW
5推荐阅读

效率新秀 | 详细解读:如何让EfficientNet更加高效、速度更快

Tansformer | 详细解读:如何在CNN模型中插入Transformer后速度不变精度剧增?

最强Transformer | 太顶流!Scaling ViT将ImageNet Top-1 Acc刷到90.45%啦!!!
本文论文原文获取方式,扫描下方二维码
回复【PFR】即可获取论文
长按扫描下方二维码添加小助手。
可以一起讨论遇到的问题
声明:转载请说明出处
扫描下方二维码关注【集智书童】公众号,获取更多实践项目源码和论文解读,非常期待你我的相遇,让我们以梦为马,砥砺前行!
