
一篇必读的Kafka文章
浪尖聊大数据
共 4281字,需浏览 9分钟
· 2021-06-15

https://kafka.apache.org/intro
应用场景
异步解构:在上下游没有强依赖的业务关系或针对单次请求不需要立刻处理的业务; 系统缓冲:有利于解决服务系统的吞吐量不一致的情况,尤其对处理速度较慢的服务来说起到缓冲作用; 消峰作用:对于短时间偶现的极端流量,对后端的服务可以启动保护作用; 数据流处理:集成 spark 做实事数据流处理。
Kafka 拓扑图(多副本机制)
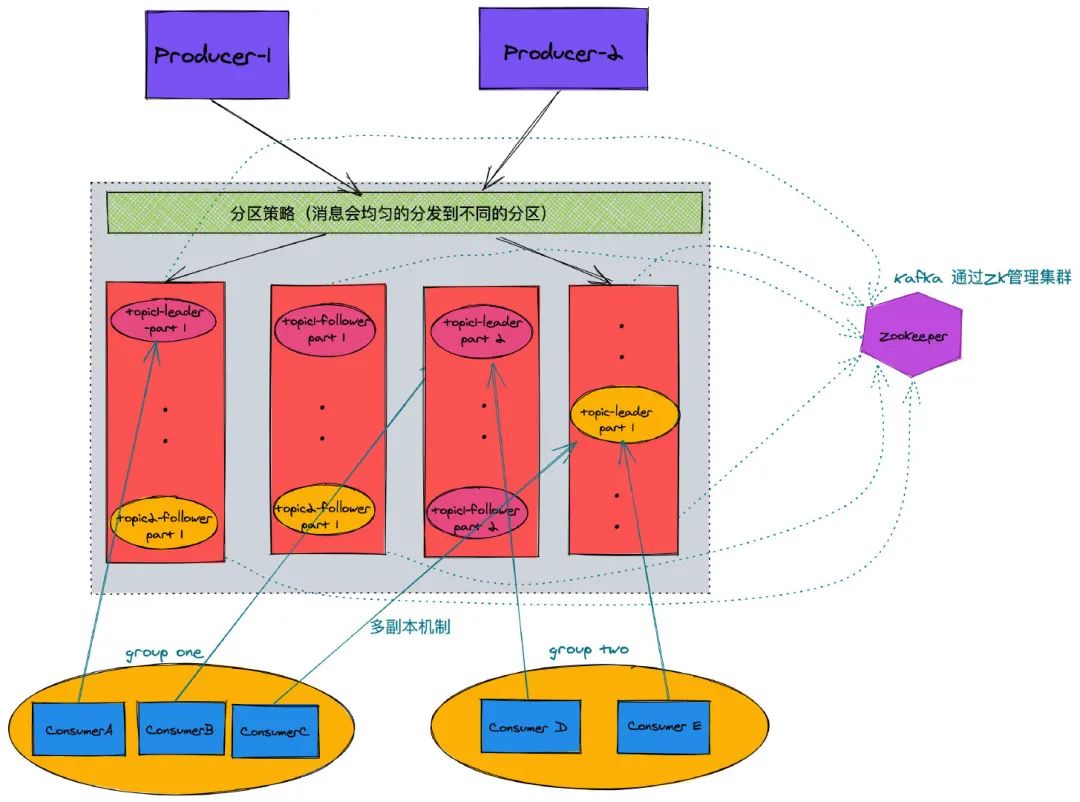
Kafka 核心组件
broker
topic
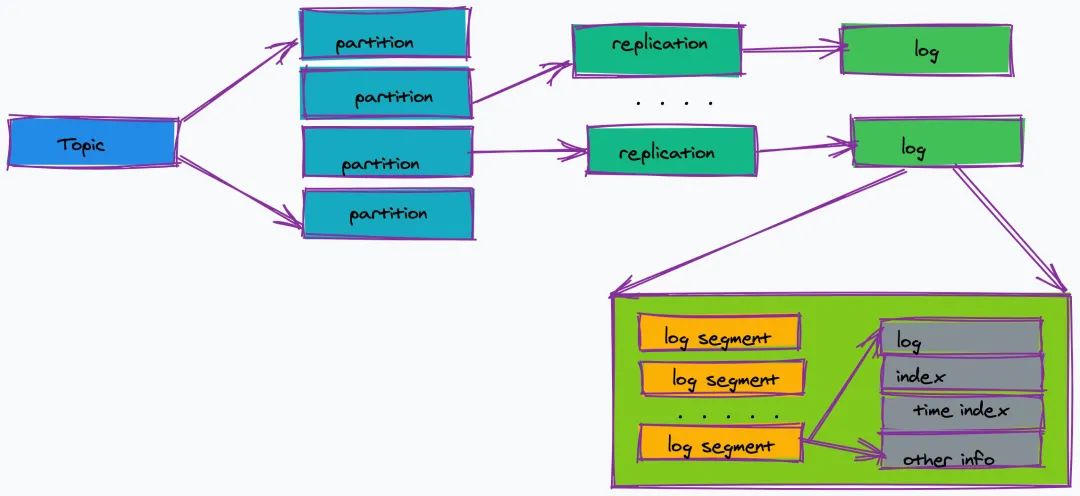
partition
topic 的分区,一个 topic 可以包含多个 partition,topic 消息保存在各个 partition 上;由于一个 topic 能被分到多个分区上,给 kafka 提供给了并行的处理能力,这也正是 kafka 高吞吐的原因之一。 partition 物理上由多个 segment 文件组成,每个 segment 大小相等,顺序读写(这也是 kafka 比较快的原因之一,不需要随机写)。每个 Segment 数据文件以该段中最小的 offset ,文件扩展名为.log。当查找 offset 的 Message 的时候,通过二分查找快找到 Message 所处于的 Segment 中。
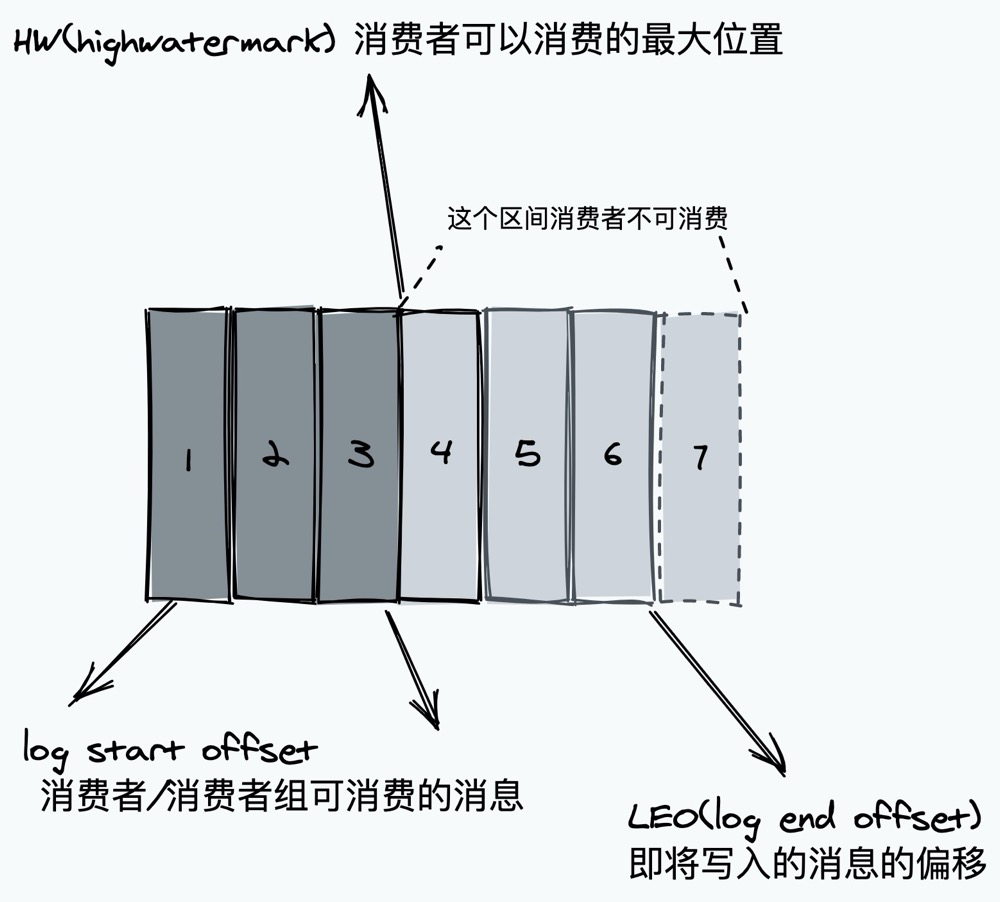
offset
消息在日志中的位置,可以理解是消息在 partition 上的偏移量,也是代表该消息的唯一序号。 同时也是主从之间的需要同步的信息。
Producer
Consumer
Consumer Group
Zookeeper
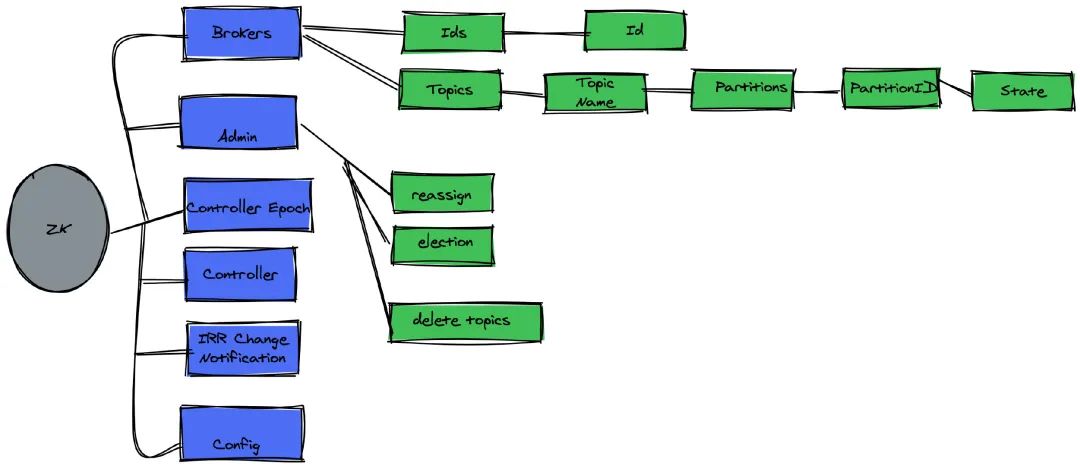
服务治理
数据同步
ISR
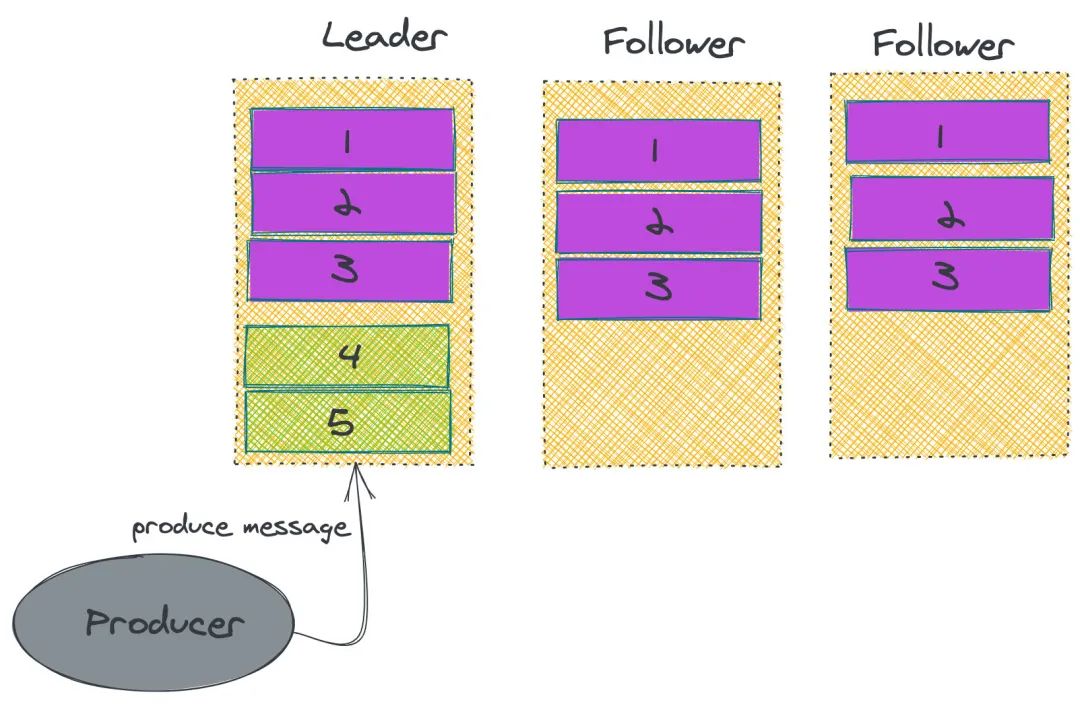
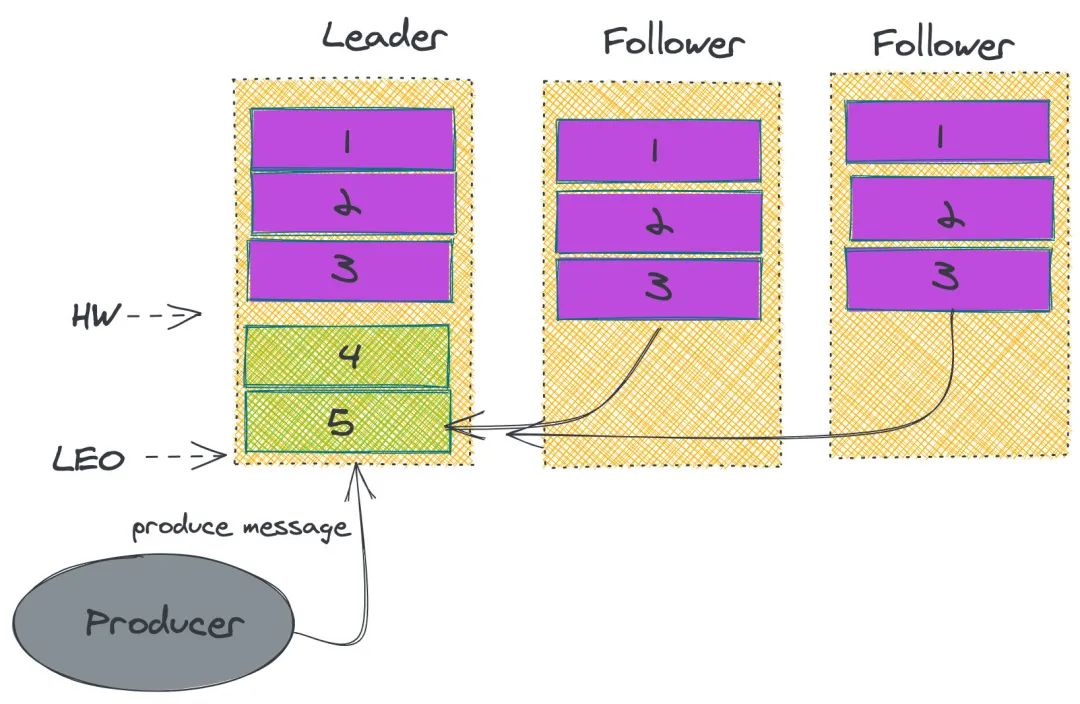
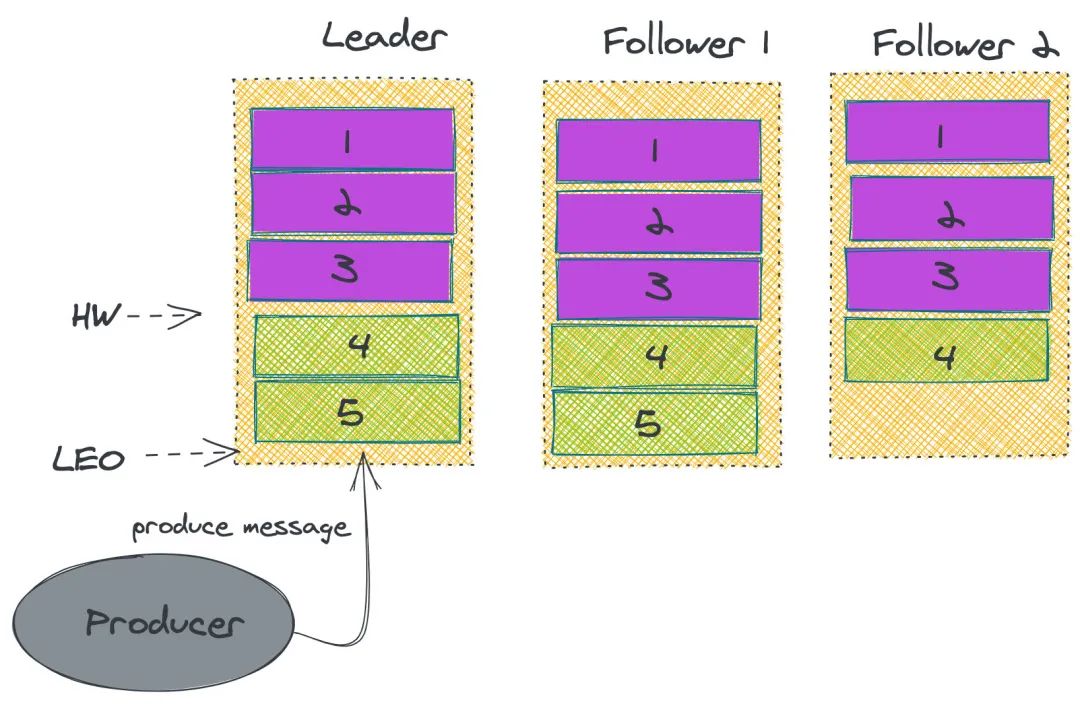
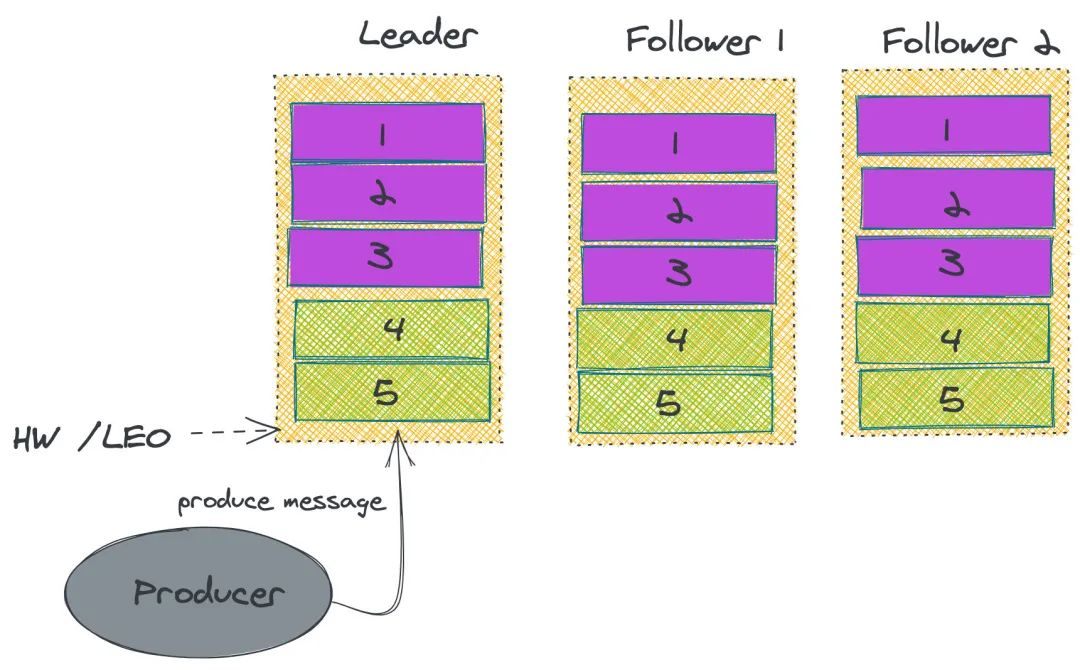
Kafka 故障恢复
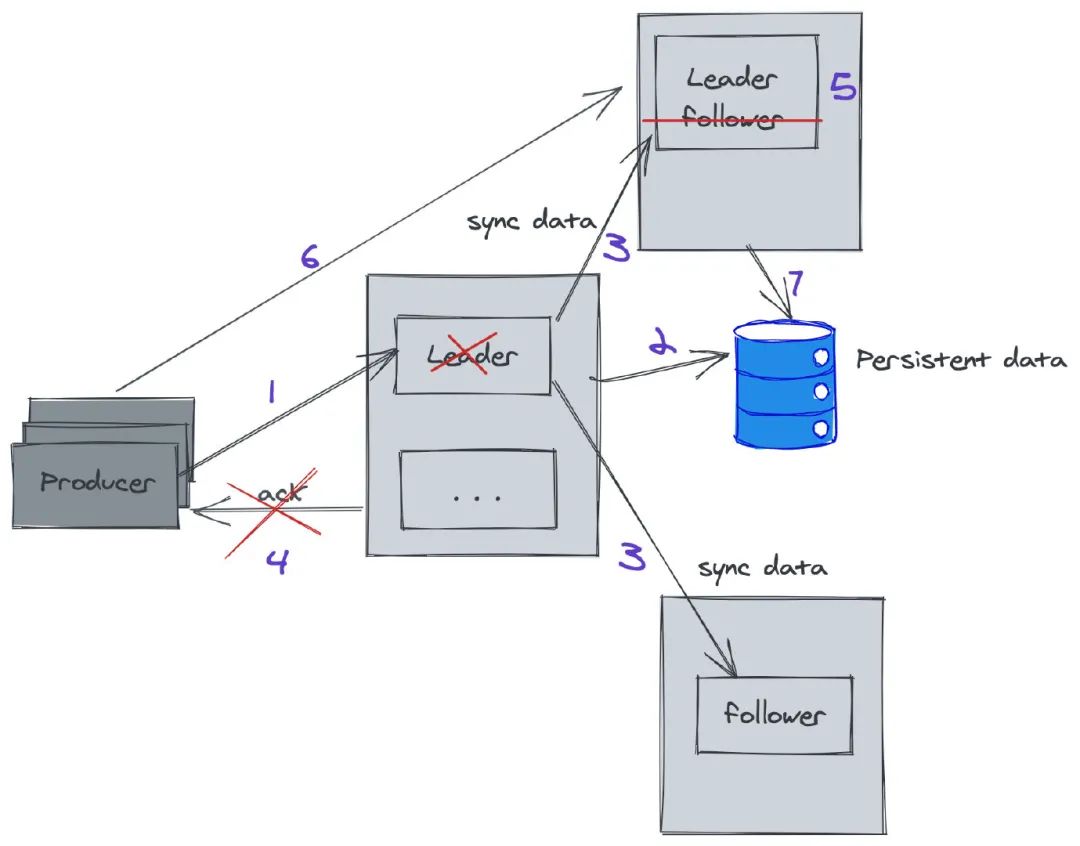
生产者发生消息给 leader,这个时候 leader 完成数据存储,突然发生故障,没有给 producer 返回 ack; 通过 ZK 选举,其中一个 follower 成为 leader,这个时候 producer 重新请求新的 leader,并存储数据。
Kafka 为什么这么快
顺序写磁盘
Page Cache

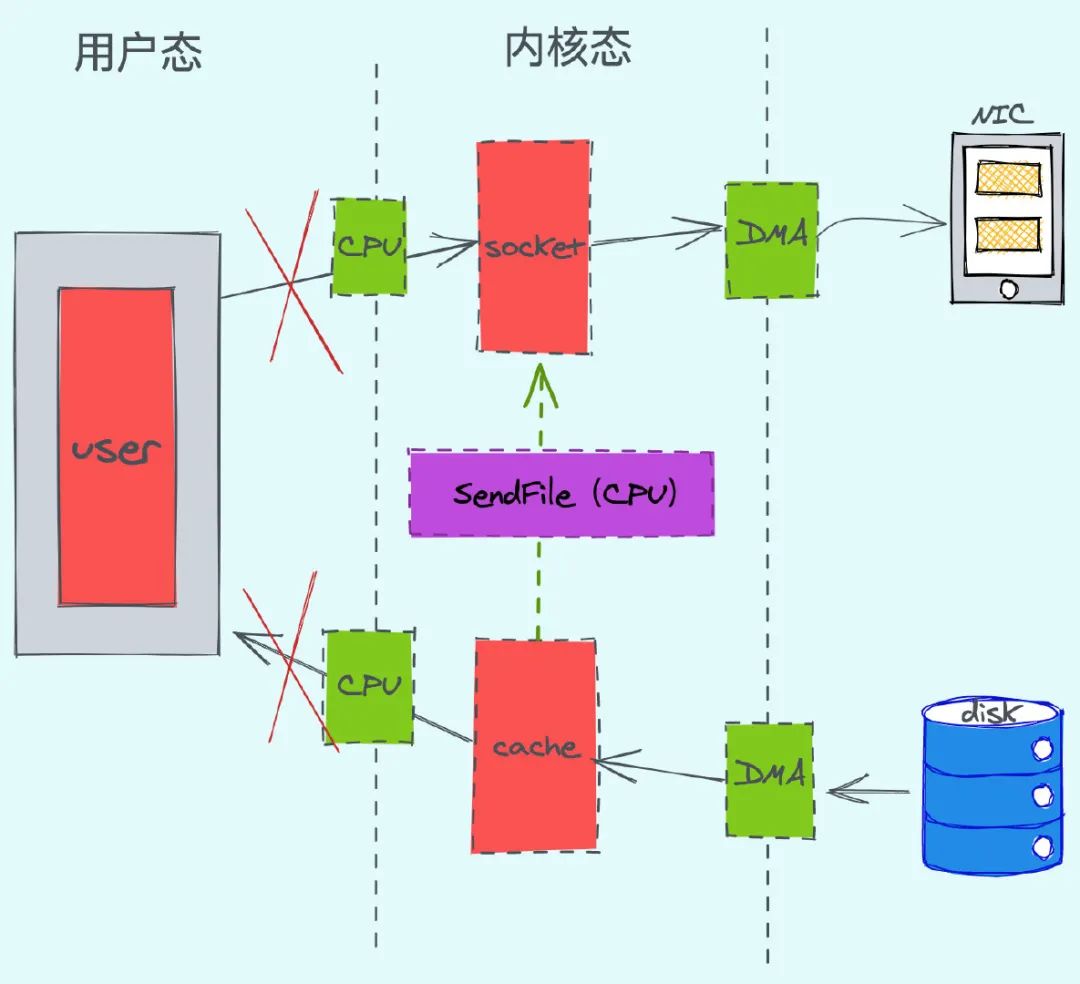
零拷贝
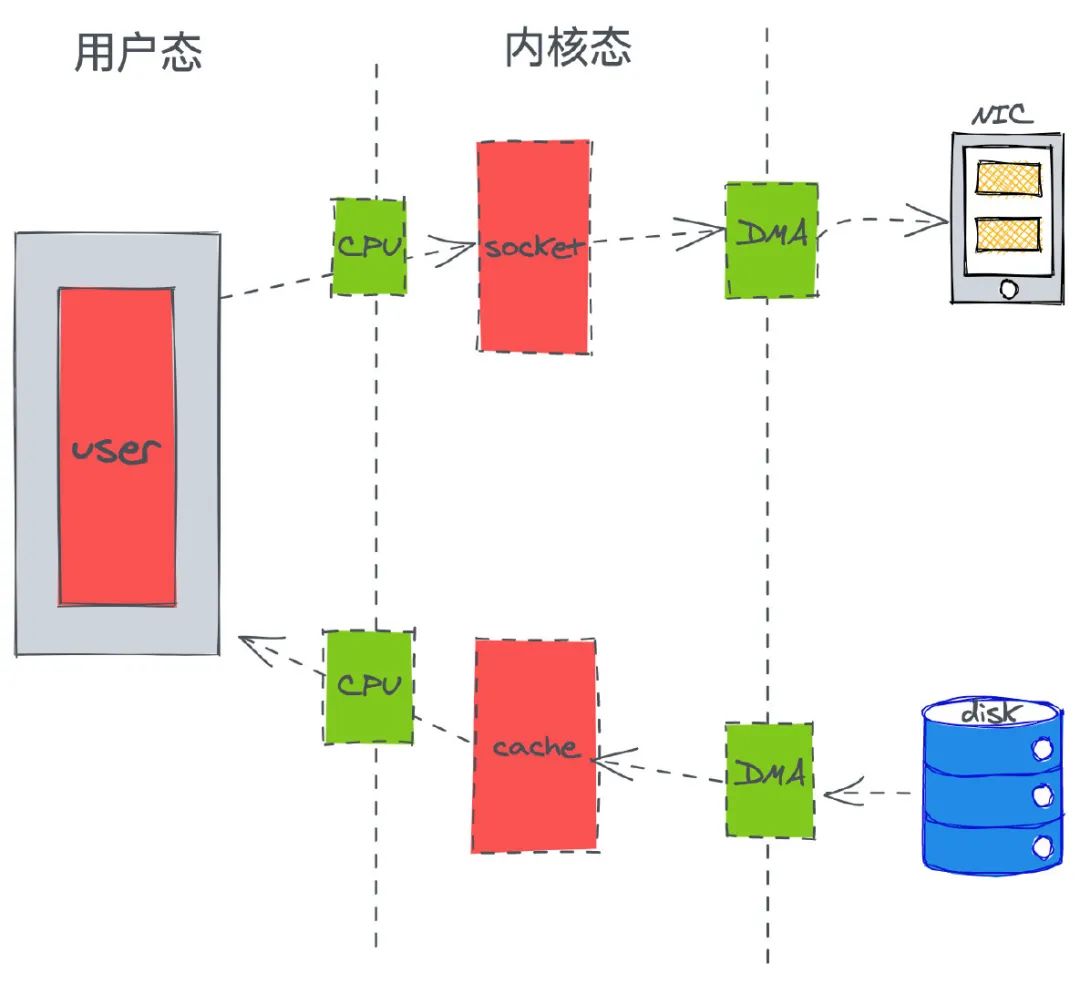
传统的一次应用程请求数据的过程
零拷贝的方式
分区分段
数据压缩
Kafka 安装
安装 JDK
yum -y list Java*
yum install java-1.8.0-openjdk-devel.x86_64
Java -version
安装 Zookeeper
tar -zxvf zookeeper-3.4.9.tar.gz
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
# zookeeper内部的基本单位,单位是毫秒,这个表示一个tickTime为2000毫秒,在zookeeper的其他配置中,都是基于tickTime来做换算的
tickTime=2000
# 集群中的follower服务器(F)与leader服务器(L)之间 初始连接 时能容忍的最多心跳数(tickTime的数量)。
initLimit=10
#syncLimit:集群中的follower服务器(F)与leader服务器(L)之间 请求和应答 之间能容忍的最多心跳数(tickTime的数量)
syncLimit=5
# 数据存放文件夹,zookeeper运行过程中有两个数据需要存储,一个是快照数据(持久化数据)另一个是事务日志
dataDir=/tmp/zookeeper
## 客户端访问端口
clientPort=2181
vim ~/.bash_profile
export ZK=/usr/local/src/apache-zookeeper-3.7.0-bin
export PATH=$PATH:$ZK/bin
export PATH
// 启动
zkServer.sh start

安装 Kafka
tar -xzvf kafka_2.12-2.0.0.tgz
export ZK=/usr/local/src/apache-zookeeper-3.7.0-bin
export PATH=$PATH:$ZK/bin
export KAFKA=/usr/local/src/kafka
export PATH=$PATH:$KAFKA/bin
nohup kafka-server-start.sh 自己的配置文件路径/server.properties &
评论
一篇必看的React文章
本文适合有 React 基础的小伙伴进阶学习作者:广东靓仔一、前言本文基于开源项目:https://github.com/facebook/react进行简单的梳理,希望能够让读者一文搞懂React 机制。1.React中文文档 本文需要对React有所了...
前端大神之路
0