
【深入探究Node】(2)“模块机制” 有十三问
我尝试用一种自问自答的方式记下笔记,就像面试一样,我自个儿觉得有意思极了,希望你也喜欢
第一问:CommonJS规范是干嘛的
CommonJS规范为JavaScript制定了一个美好的愿景——希望JavaScript能够在任何地方运行。
CommonJS规范的提出,主要是为了弥补当前JavaScript没有标准的缺陷,以达到像Python、Ruby和Java具备开发大型应用的基础能力,而不是停留在小脚本程序的阶段
第二问:那你知道CommonJs模块包含什么吗?
CommonJS对模块的定义十分简单,主要分为模块引用、模块定义和模块标识3个部分。
1.模块引用
模块引用的示例代码如下:
var math = require('math');
在CommonJS规范中,存在require()方法,这个方法接受模块标识,以此引入一个模块的API到当前上下文中。
2.模块定义
在模块中,上下文提供require()方法来引入外部模块。对应引入的功能,上下文提供了exports对象用于导出当前模块的方法或者变量,并且它是唯一导出的出口。在模块中,还存在一个module对象,它代表模块自身,而exports是module的属性。在Node中,一个文件就是一个模块,将方法挂载在exports对象上作为属性即可定义导出的方式:
// math.js
exports.add = function () {
var sum = 0,
i = 0,
args = arguments,
l = args.length;
while (i < l) {
sum += args[i++];
}
return sum;
};
在另一个文件中,我们通过require()方法引入模块后,就能调用定义的属性或方法了:
// program.js
var math = require('math');
exports.increment = function (val) {
return math.add(val, 1);
};
模块的定义十分简单,接口也十分简洁。它的意义在于将类聚的方法和变量等限定在私有的作用域中,同时支持引入和导出功能以顺畅地连接上下游依赖。如图所示,每个模块具有独立的空间,它们互不干扰,在引用时也显得干净利落。
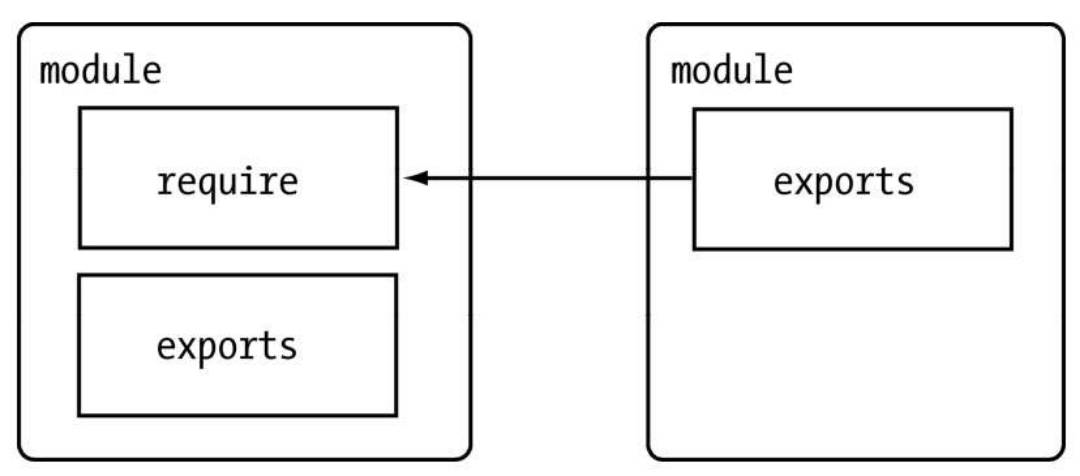
CommonJS构建的这套模块导出和引入机制使得用户完全不必考虑变量污染,命名空间等方案与之相比相形见绌。
3.模块标识
模块标识其实就是传递给require()方法的参数,它必须是符合小驼峰命名的字符串,或者以.、..开头的相对路径,或者绝对路径。它可以没有文件名后缀.js。
第三问:上面提到了模块引用,你可以谈谈模块引用的过程吗?
在Node中引入模块,需要经历如下3个步骤。
(1) 路径分析 (2) 文件定位 (3) 编译执行
第四问:Node中所有模块的引用都要经历这些?
非也!
在Node中,模块分为两类:一类是Node提供的模块,称为核心模块;另一类是用户编写的模块,称为文件模块。
❑ 核心模块部分在Node源代码的编译过程中,编译进了二进制执行文件。在Node进程启动时,部分核心模块就被直接加载进内存中,所以这部分核心模块引入时,文件定位和编译执行这两个步骤可以省略掉,并且在路径分析中优先判断,所以它的加载速度是最快的。
❑ 文件模块则是在运行时动态加载,需要完整的路径分析、文件定位、编译执行过程,速度比核心模块慢。
第五问:我觉得还不够全面,特别重要的一点就是模块二次引用的时候,你没讲。
确实,模块二次引用跟第一次是不一样的。
与前端浏览器会缓存静态脚本文件以提高性能一样,Node对引入过的模块都会进行缓存,以减少二次引入时的开销。不同的地方在于,浏览器仅仅缓存文件,而Node缓存的是与前端浏览器会缓存静态脚本文件以提高性能一样,Node对引入过的模块都会进行缓存,以减少二次引入时的开销。不同的地方在于,浏览器仅仅缓存文件,而Node缓存的是编译和执行之后的对象。
不论是核心模块还是文件模块,require()方法对相同模块的二次加载都一律采用缓存优先的方式,这是第一优先级的。不同之处在于核心模块的缓存检查先于文件模块的缓存检查。。
不论是核心模块还是文件模块,require()方法对相同模块的二次加载都一律采用缓存优先的方式,这是第一优先级的。不同之处在于核心模块的缓存检查先于文件模块的缓存检查。
第六问:你能谈谈 模块引用中的路径分析吗?
可以,路径分析其实就是 模块标志符分析
模块标识符在Node中主要分为以下几类。
❑ 核心模块,如http、fs、path等。 ❑ .或..开始的相对路径文件模块。 ❑ 以/开始的绝对路径文件模块。 ❑ 非路径形式的文件模块,如自定义的connect模块。
而这几种标志符的分析都是不同的。
●核心模块
核心模块的优先级仅次于缓存加载,它在Node的源代码编译过程中已经编译为二进制代码,其加载过程最快。
如果试图加载一个与核心模块标识符相同的自定义模块,那是不会成功的。如果自己编写了一个http用户模块,想要加载成功,必须选择一个不同的标识符或者换用路径的方式。
●路径形式的文件模块
以.、..和/开始的标识符,这里都被当做文件模块来处理。在分析文件模块时,require()方法会将路径转为真实路径,并以真实路径作为索引,将编译执行后的结果存放到缓存中,以使二次加载时更快。
由于文件模块给Node指明了确切的文件位置,所以在查找过程中可以节约大量时间,其加载速度慢于核心模块。
●自定义模块
自定义模块指的是非核心模块,也不是路径形式的标识符。它是一种特殊的文件模块,可能是一个文件或者包的形式(通常我们npm install 的包就是属于自定义模块,它是被放在node_modules包里的)。这类模块的查找是最费时的,也是所有方式中最慢的一种。
第七问:为什么说自定义模块的查找是最慢的?
模块路径是Node在定位文件模块的具体文件时制定的查找策略,具体表现为一个路径组成的数组。关于这个路径的生成规则,我们可以手动尝试一番。
(1) 创建module_path.js文件,其内容为 console.log(module.paths);。(2) 将其放到任意一个目录中然后执行node module_path.js。
在Linux下,你可能得到的是这样一个数组输出:
[ '/home/jackson/research/node_modules',
'/home/jackson/node_modules',
'/home/node_modules',
'/node_modules' ]
而在Windows下,也许是这样:
[ 'c:\\nodejs\\node_modules', 'c:\\node_modules' ]
可以看出,模块路径的生成规则如下所示。
❑ 当前文件目录下的node_modules目录。 ❑ 父目录下的node_modules目录。 ❑ 父目录的父目录下的node_modules目录。 ❑ 沿路径向上逐级递归,直到根目录下的node_modules目录。
它的生成方式与JavaScript的原型链或作用域链的查找方式十分类似。在加载的过程中,Node会逐个尝试模块路径中的路径,直到找到目标文件为止。可以看出,当前文件的路径越深,模块查找耗时会越多,这是自定义模块的加载速度是最慢的原因。
第八问:假如我使用require("myfile")引用文件模块,那这个模块分析过程是怎样的。
我觉得需要分两种情况讨论,一种是 当查到的myfile是文件时就需要按照文件扩展名分析,一种是查不到是文件,而是目录或者包时,就需要继续按照 目录分析
●文件扩展名分析
require()在分析标识符的过程中,会出现标识符中不包含文件扩展名的情况。CommonJS模块规范也允许在标识符中不包含文件扩展名,这种情况下,Node会按.js、.json、.node的次序补足扩展名,依次尝试。
在尝试的过程中,需要调用fs模块同步阻塞式地判断文件是否存在。因为Node是单线程的,所以这里是一个会引起性能问题的地方。小诀窍是:如果是.node和.json文件,在传递给require()的标识符中带上扩展名,会加快一点速度。另一个诀窍是:同步配合缓存,可以大幅度缓解Node单线程中阻塞式调用的缺陷。
●目录分析和包
在分析标识符的过程中,require()通过分析文件扩展名之后,可能没有查找到对应文件,但却得到一个目录,这在引入自定义模块和逐个模块路径进行查找时经常会出现,此时Node会将目录当做一个包来处理。
在这个过程中,Node对CommonJS包规范进行了一定程度的支持。首先,Node在当前目录下查找package.json(CommonJS包规范定义的包描述文件),通过JSON.parse()解析出包描述对象,从中取出main属性指定的文件名进行定位。如果文件名缺少扩展名,将会进入扩展名分析的步骤。
而如果main属性指定的文件名错误,或者压根没有package.json文件,Node会将index当做默认文件名,然后依次查找index.js、index.json、index.node。
如果在目录分析的过程中没有定位成功任何文件,则自定义模块进入下一个模块路径进行查找。如果模块路径数组都被遍历完毕,依然没有查找到目标文件,则会抛出查找失败的异常。
第九问:上面提到模块的引入的最后步骤模块编译了,其实文件定位之后是加载文件,然后编译,你能谈谈不同文件是怎么加载的吗
在Node中,每个文件模块都是一个Module对象,,它的定义如下:
function Module(id, parent) {
this.id = id;
this.exports = {};
this.parent = parent;
if (parent && parent.children) {
parent.children.push(this);
}
this.filename = null;
this.loaded = false;
this.children = [];
}
编译和执行是引入文件模块的最后一个阶段。定位到具体的文件后,Node会新建一个模块对象,然后根据路径载入并编译。对于不同的文件扩展名,其载入方法也有所不同,具体如下所示。
❑ .js文件。通过fs模块同步读取文件后编译执行。 ❑ .node文件。这是用 C/C++编写的扩展文件,通过dlopen()方法加载最后编译生成的文件。❑ .json文件。通过fs模块同步读取文件后,用 JSON.parse()解析返回结果。❑ 其余扩展名文件。它们都被当做.js文件载入。
每一个编译成功的模块都会将其文件路径作为索引缓存在Module._cache对象上,以提高二次引入的性能。
根据不同的文件扩展名,Node会调用不同的读取方式,如.json文件的调用如下:
// Native extension for .json
Module._extensions['.json'] = function(module, filename) {
var content = NativeModule.require('fs').readFileSync(filename, 'utf8');
try {
module.exports = JSON.parse(stripBOM(content));
} catch (err) {
err.message = filename + ': ' + err.message;
throw err;
}
};
其中,Module._extensions会被赋值给require()的extensions属性,所以通过在代码中访问require.extensions可以知道系统中已有的扩展加载方式。编写如下代码测试一下:
console.log(require.extensions);
得到的执行结果如下:
{ '.js': [Function], '.json': [Function], '.node': [Function] }
如果想对自定义的扩展名进行特殊的加载,可以通过类似require.extensions['.ext']的方式实现。
在确定文件的扩展名之后,Node将调用具体的编译方式来将文件执行后返回给调用者。
第十问:前面谈到分别有.js ,.node, .json的文件模块。我比较感兴趣的是.js,即JavaScript模块的编译,你能谈谈吗?
好的。
回到CommonJS模块规范,我们知道每个模块文件中存在着require、exports、module这3个变量,但是它们在模块文件中并没有定义,那么从何而来呢?甚至在Node的API文档中,我们知道每个模块中还有__filename、__dirname这两个变量的存在,它们又是从何而来的呢?如果我们把直接定义模块的过程放诸在浏览器端,会存在污染全局变量的情况。
事实上,在编译的过程中,Node对获取的JavaScript文件内容进行了头尾包装。在头部添加了(function (exports, require, module, __filename, __dirname) {\n,在尾部添加了\n});。一个正常的JavaScript文件会被包装成如下的样子:
(function (exports, require, module, __filename, __dirname) {
var math = require('math');
exports.area = function (radius) {
return Math.PI * radius * radius;
};
});
这样每个模块文件之间都进行了作用域隔离。包装之后的代码会通过vm原生模块的runInThisContext()方法执行(类似eval,只是具有明确上下文,不污染全局),返回一个具体的function对象。最后,将当前模块对象的exports属性、require()方法、module(模块对象自身),以及在文件定位中得到的完整文件路径和文件目录作为参数传递给这个function()执行。
这就是这些变量并没有定义在每个模块文件中却存在的原因。在执行之后,模块的exports属性被返回给了调用方。exports属性上的任何方法和属性都可以被外部调用到,但是模块中的其余变量或属性则不可直接被调用。
至此,require、exports、module的流程已经完整,这就是Node对CommonJS模块规范的实现。
第十一问:好了,顺便也谈谈C/C++模块和JSON文件的编译吧
好的。
C/C++模块的编译
Node调用process.dlopen()方法进行加载和执行。
实际上,.node的模块文件并不需要编译,因为它是编写C/C++模块之后编译生成的,所以这里只有加载和执行的过程。在执行的过程中,模块的exports对象与.node模块产生联系,然后返回给调用者。
C/C++模块给Node使用者带来的优势主要是执行效率方面的,劣势则是C/C++模块的编写门槛比JavaScript高。
JSON文件的编译
.json文件的编译是3种编译方式中最简单的。Node利用fs模块同步读取JSON文件的内容之后,调用JSON.parse()方法得到对象,然后将它赋给模块对象的exports,以供外部调用。
JSON文件在用作项目的配置文件时比较有用。如果你定义了一个JSON文件作为配置,那就不必调用fs模块去异步读取和解析,直接调用require()引入即可。此外,你还可以享受到模块缓存的便利,并且二次引入时也没有性能影响。
第十二问:我们经常在面试中遇到除了CommonJS外,其实还遇到AMD,能否介绍下AMD呢?
JavaScript在Node出现之后,比别的编程语言多了一项优势,那就是一些模块可以在前后端实现共用,这是因为很多API在各个宿主环境下都提供。但是在实际情况中,前后端的环境是略有差别的。
前后端JavaScript分别搁置在HTTP的两端,它们扮演的角色并不同。浏览器端的JavaScript需要经历从同一个服务器端分发到多个客户端执行,而服务器端JavaScript则是相同的代码需要多次执行。前者的瓶颈在于带宽,后者的瓶颈则在于CPU和内存等资源。前者需要通过网络加载代码,后者从磁盘中加载,两者的加载速度不在一个数量级上。
纵观Node的模块引入过程,几乎全都是同步的。尽管与Node强调异步的行为有些相反,但它是合理的。但是如果前端模块也采用同步的方式来引入,那将会在用户体验上造成很大的问题。UI在初始化过程中需要花费很多时间来等待脚本加载完成。鉴于网络的原因,CommonJS为后端JavaScript制定的规范并不完全适合前端的应用场景。经过一段争执之后,AMD规范最终在前端应用场景中胜出。它的全称是Asynchronous Module Definition,即是“异步模块定义”。
AMD规范是CommonJS模块规范的一个延伸,它的模块定义如下:
define(id? , dependencies? , factory);
它的模块id和依赖是可选的,与Node模块相似的地方在于factory的内容就是实际代码的内容。下面的代码定义了一个简单的模块:
define(function() {
var exports = {};
exports.sayHello = function() {
alert('Hello from module: ' + module.id);
};
return exports;
});
不同之处在于AMD模块需要用define来明确定义一个模块,而在Node实现中是隐式包装的,它们的目的是进行作用域隔离,仅在需要的时候被引入,避免掉过去那种通过全局变量或者全局命名空间的方式,以免变量污染和不小心被修改。另一个区别则是内容需要通过返回的方式实现导出。
第十三问:其实除了CommonJS ,AMD外,还有CMD,顺便也介绍下吧
好的。
CMD规范由国内的玉伯提出,与AMD规范的主要区别在于定义模块和依赖引入的部分。AMD需要在声明模块的时候指定所有的依赖,通过形参传递依赖到模块内容中:
define(['dep1', 'dep2'], function (dep1, dep2) {
return function () {};
});
与AMD模块规范相比,CMD模块更接近于Node对CommonJS规范的定义:
define(factory);
在依赖部分,CMD支持动态引入,示例如下:
define(function(require, exports, module) {
// The module code goes here
});
require、exports和module通过形参传递给模块,在需要依赖模块时,随时调用require()引入即可。
最后
公众号里回复关键词加群,加入技术交流群 文章点个在看,支持一下把!点击关注我们