
Optuna:席卷Kaggle的调参神器,NN和树模型通吃!
共 4046字,需浏览 9分钟
· 2021-06-13

极市导读
Kaggle的竞赛首选调参工具包,解决了大多数超参寻优算法的目前存在的主要问题。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
简介
目前非常多的超参寻优算法都不可避免的有下面的一个或者多个问题:
需要人为的定义搜索空间; 没有剪枝操作,导致搜索耗时巨大; 无法通过小的设置变化使其适用于大的和小的数据集;
本文介绍的一种超参寻优策略则同时解决了上面三个问题,与此同时,该方法在目前kaggle的数据竞赛中也都是首选的调参工具包,其优势究竟有多大,我们看一下其与目前最为流行的一些工具包的对比。
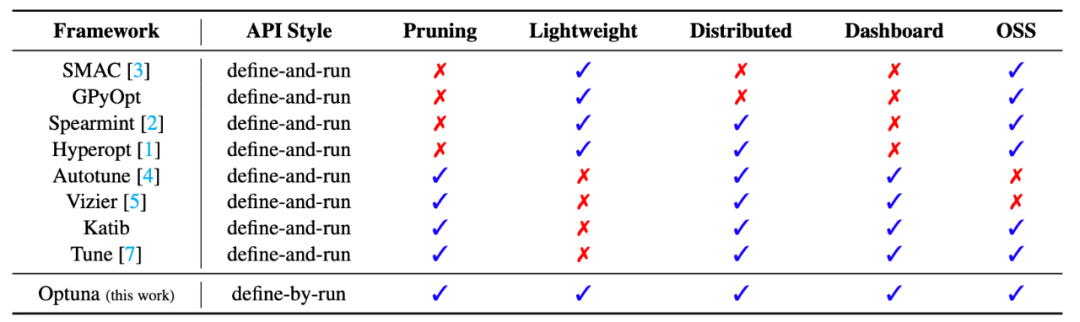
Optuna
01 Define-By-Run的API
Optuna将超参数优化描述为一个最小化/最大化目标函数的过程,该目标函数以一组超参数作为输入并返回其(验证)分数。该函数不依赖于外部定义的静态变量,动态构造神经网络结构的搜索空间(层数和隐单元数)。Optuna是以每一个优化过程为研究对象,以每一个评价目标函数为试验对象。Optuna中的目标函数接收的不是超参数值,而是与单个试验相关联的活动试验对象。
模块化编程:Optuna的代码是模块化的,用户可以轻松地用其他条件变量和其他参数集的方法扩充代码,并从更多样化的模型池中进行选择。 Optuna可以较为容易地进行部署;
02 高效的采样和剪枝策略
关系采样,Optuna可以识别关于共现的实验结果,通过这种方式,框架可以在经过一定数量的独立采样后识别出潜在的共现关系,并使用推断出的共现关系进行用户选择的关系采样算法。 高效的剪枝算法,Optuna会定期监测中间目标值并终止不符合预定条件的试验。它还采用异步Successive Halving算法,所以我们可以在此进行并行计算,而相互不会有太多影响。
03 可扩展的同时易于设置
Optuna是一个可扩展的系统,它可以处理各种各样的任务,包括:
从需要大量工作人员的繁重实验到通过Jupyter Notebook等交互界面进行的试验级、轻量级计算; 当用户需要进行分布式计算时,Optuna的用户可以部署关系数据库作为后端。Optuna的用户也可以使用SQLite数据库。 Optuna的新设计大大减少了部署存储所需的工作量,新的设计可以很容易地集成到Kubernetes这样的容器编排系统中。
代码
1. 数据集生成
# !pip install optuna
import optuna
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import KFold , cross_val_score
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import lightgbm as lgb
import numpy as np
from optuna.samplers import TPESampler
from sklearn.metrics import accuracy_score
iris = load_iris()
X = iris.data
y = iris.target
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size = 0.3,random_state = 14)
2. Optuna+LightGBM
sampler = TPESampler(seed=10) # for reproducibility
def objective(trial):
dtrain = lgb.Dataset(X_train, label=y_train)
param = {
'objective': 'multiclass',
'metric': 'multi_logloss',
'verbosity': -1,
'boosting_type': 'gbdt',
'num_class':3,
'lambda_l1': trial.suggest_loguniform('lambda_l1', 1e-8, 10.0),
'lambda_l2': trial.suggest_loguniform('lambda_l2', 1e-8, 10.0),
'num_leaves': trial.suggest_int('num_leaves', 2, 512),
'learning_rate': trial.suggest_loguniform('learning_rate', 1e-8, 1.0),
'n_estimators': trial.suggest_int('n_estimators', 700, 3000),
'feature_fraction': trial.suggest_uniform('feature_fraction', 0.4, 1.0),
'bagging_fraction': trial.suggest_uniform('bagging_fraction', 0.4, 1.0),
'bagging_freq': trial.suggest_int('bagging_freq', 1, 7),
'min_child_samples': trial.suggest_int('min_child_samples', 5, 100),
}
gbm = lgb.train(param, dtrain)
return accuracy_score(y_test, np.argmax(gbm.predict(X_test),axis=1))
study = optuna.create_study(direction='maximize', sampler=sampler)
study.optimize(objective, n_trials=100)
输出模型的最好结参数
# 输出模型的最好结参数
study.best_params
{'lambda_l1': 0.0234448167468032,
'lambda_l2': 7.075730911992614e-07,
'num_leaves': 173,
'learning_rate': 4.887601625186522e-05,
'n_estimators': 1824,
'feature_fraction': 0.9712805361251421,
'bagging_fraction': 0.8498709168727996,
'bagging_freq': 2,
'min_child_samples': 17}
适用问题
Optuna方法目前适用于所有模型的参数的调节,传统的模型亦或者是神经网络模型。目前最新的kaggle竞赛中,该方法可以非常快速的寻找到最优的参数,是目前必须一试的算法。
参考
1.https://github.com/optuna/optuna
2.Optuna: A Next-generation Hyperparameter Optimization Framework
3.Smart Hyperparameter Tuning With Optuna
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“79”获取CVPR 2021:TransT 直播链接~

# CV技术社群邀请函 #
备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
