
效率新秀 | 详细解读:如何让EfficientNet更加高效、速度更快
共 5403字,需浏览 11分钟
· 2021-06-16


1简介
近年来,许多研究致力于提高图像分类训练和推理的效率。这种研究通常集中于提高理论效率,通常以每个FLOP的ImageNet验证精度来衡量。然而,事实证明,这些理论上的改进在实践中很难实现,特别是在高性能训练加速器上。
在这项工作中,作者关注的是在一个新的加速器类Graphcore IPU上提高最先进的EfficientNet模型的实际效率。本文主要通过以下方式扩展这类模型:
将Depthwise CNN推广为Group CNN; 添加proxy-normalized激活,以使batch normalization性能与batch-independent statistics相匹配; 通过降低训练分辨率和低成本的微调来减少计算量。
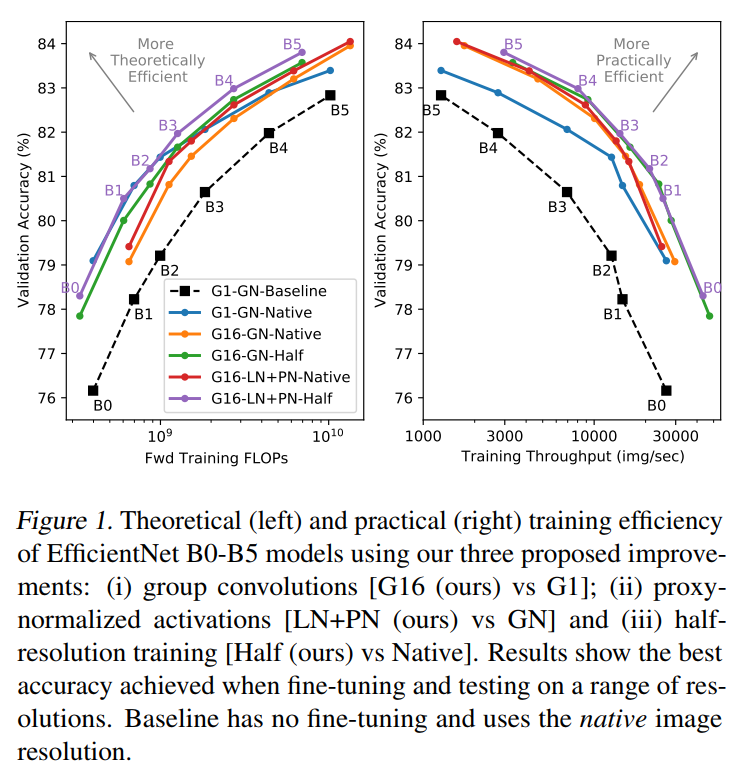
作者发现这3种方法都提高了训练和推理的实际效率。
2研究背景
2.1 Efficient CNNs分析
在CNN的发展过程中,实际训练效率的提高是创新的重要力量。比如说,AlexNet的成功很大一部分因素便得益于GPU加速,ResNet的成功不仅可以归因于其良好的性能,而且其在GPU上的高吞吐量也相对比较高。
最近,在理论效率方面也取得了重大改进。最引人注目的创新是在空间操作中引入Group卷积和Depthwise卷积。ResNet-50单独引入Group卷积可以提高理论效率。类似地,通过将Group规模减少到1,即利用Depthwise卷积,相对于原始的CNN模型也实现了理论效率的提高。特别是,该方法为实现基于“mobile”级别的落地应用提供了可能。
通过使用NAS直接减少FLOPs进一步提高了这些理论上的效率增益。这带来了整个模型尺度范围内的效率提高,从mobile-sized的模型如MobileNetV3和MNasNet 到大型模型如NASNet和AmoebaNet。
值得注意的是,在ImageNet模型的最高精度前100名的所有NAS模型都使用了某种形式的Group卷积或Depthwise卷积,进一步突出了这些操作相对于CNN操作的优势,在高效的MNasNet基础上,EfficientNet进一步改进了训练方法并扩展到更大的模型,以在FLOP范围内实现SOTA性能。
虽然低功耗cpu的高效模型通常能实现实际改进,但这些模型通常难以将理论收益转化为高性能硬件上更高的训练吞吐量。例如,虽然EfficientNets在理论训练效率方面远远优于ResNets,但当考虑到GPU上的实际训练效率时经常被发现表现不佳。最近的一些工作也已经开始使用NAS来优化GPU的实际效率。
2.2 硬件角度考虑与分析
在研究模型的实际效率时,了解它所运行的硬件的特征是很重要的。关于这个问题的讨论通常主要集中在峰值计算速率上,以每秒浮点运算(FLOPS)衡量,这是计算操作的理论最大速率。虽然峰值率是需要考虑的一个重要因素,但了解实现峰值率所需的假设也同样重要,例如,计算的结构和数据的可用性。
计算结构很重要,因为现代硬件通常使用向量指令,允许用一条指令计算给定长度的点积。然而,如果计算的体系结构不能使这些向量指令被填满,那么FLOPs就可能被浪费掉。此外,如果数据不能立即在计算引擎上获得,那么将需要循环来移动它。这种操作将高度依赖于内存的带宽或者位宽。
对内存带宽的依赖依赖于模型,可以通过计算与数据传输的比率来表征,即算术arithmetic intensity——在这种情况下,低arithmetic intensity强度的操作更依赖于内存带宽。对于一个简单的Group卷积,arithmetic intensity强度随着Group大小、Kernel大小、field大小和Batch大小单调地增加。值得注意的是,这意味着Group卷积和Depthwise卷积在Group较小时的效率更可能受到可用内存带宽的限制。
在这项工作中,作者使用了一种新的硬件加速器Graphcore IPU。这种加速器与通常用于神经网络训练的GPU有很大的区别。IPU计算在芯片上分布在1472个核心中,尽管它的指令仍然是向量化的,但要充分利用计算引擎,只需要16项的点积即可。这有助于减少对计算结构的依赖。此外,IPU拥有超过900MB的高带宽片上内存,远远超过其他硬件。这大大降低了低arithmetic intensity强度操作的代价。
为了最大化IPU上的性能,保持尽可能多的工作内存(例如芯片上的激活状态)变得非常重要。这自然促进了更小批次的使用、内存节约优化和分布式处理的创新形式。同时,它确实需要重新考虑使用BN,因为在视觉模型中,最常见的归一化方法它很依赖于大的Batchsize。
3本文方法
3.1 改用Group卷积
NAS方法倾向于将它们的spatial卷积分组,通常分组大小为G=1(Depthwise卷积)。而Depthwise卷积具有很低的FLOP和参数,使用G>1作为一个更大的Group将更有效地利用现代硬件加速器:
(i) 增加arithmetic intensity强度; (ii) 增加点积的长度(用于卷积),允许使用更大的向量指令。
作者的目的是研究在EfficientNet模型中增加spatial卷积的Group大小所涉及的权衡问题。单单增加G就会增加参数量和FLOPs。因此,为了保持相似的模型复杂度,作者相应地降低了扩展比(扩展比定义为输入到first pointwise CNN和spatial CNN之间的通道比)。这类似于ResNeXt的Flop等效扩展。
因此,对于相同的FLOP具有更大G的网络将更窄,更窄的网络模型将通过减少存储激活状态的大小和使用更大的BatchSize而获得计算优势。请注意,虽然这种补偿的目的是保持总FLOPs和参数量,但为简单起见,作者只在全局级别更改扩展比率。因此,并不需要保持与深度完全相同的参数和FLOPs分布。
与EfficientNet一样,其他NAS派生的架构通常只使用depthwise卷积,这表明depthwise卷积在验证准确性方面是最优的。在ResNeXts中,在保持总FLOPs的同时增加G会导致验证准确性下降。这也表明与类似G>1的网络对比G=1的vanilla EfficientNet将实现更高的准确度。然而,作者希望改进的网络提供更好的性能和训练时间之间的权衡。因此对EfficientNet B0和B2的Group规模在G=1和G=64之间进行了测试。
3.2 Batch-Independent Normalization
BN的问题在哪?
我们都知道BN通常应用于没有归一化的pre-activations X进而产生归一化pre-activations Y,然后再进行仿射变换和非线性,最终产生post-activations Z。形式上,每个通道c:
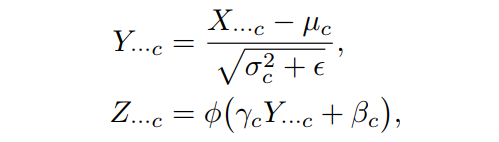
式中BN的归一化确保了Y被规范化,这意味着每个通道c的均值和单位方差都为零,因此BN对于将模型扩展到大型和深度模型是成为了可能:
通过确保非线性在每个通道中“sees”接近归一化的数据分布,可以有效地形成非线性的分布。因此,额外的层可以增加表达能力,网络可以有效地利用其整个深度。这与会“see”一个“collapsed”的数据分布的情况相反,这样它会在一阶上很好地近似于一个关于这个分布的线性函数;
通过保证不同通道的方差接近相等,网络可以有效地利用其整个带宽。这与一种情况相反,在这种情况下,一个单一的通道会任意支配其他渠通道,从而成为唯一的通道被后续层“seen”。
尽管这一基本原则取得了实际的成功应用,但BN对小batchsize数据的依赖有时会产生问题。最值得注意的是,当batchsize较小或数据集较大时,来自小batchsize统计数据中噪声的正则化可能会过大或不必要,从而导致性能下降。
突破点在哪?
为了解决这些问题,研究者们也提出了各种Batch-Independent相关的归一化技术:层归一化(LN)、组归一化(GN)、实例归一化(IN)、权重归一化(WN)、权重标准化(WS)、在线归一化(ON)、滤波器响应归一化(FRN)、EvoNorm等。虽然这些技术在其他环境中很有用,但在本工作中,没有一种技术能够缩小与大 Batch BN的性能差距,重点关注在ImageNet上使用RMSProp训练的EfficientNets。
这也促使作者重新思考如何执行独立于batch的Norm,并在工作中提出Proxy Normalized Activations。在本研究中,作者提出了一个假设,即除了提高对小batch的依赖外,与batch无关的归一化还应保持每个通道中归一化预激活Y的BN原则。
这一假设的第1个理由是BN的归纳偏差。第2个理由是,在更实际的层面上,BN被用于架构搜索,比如产生了EfficientNet模型系列的搜索。因此,坚持相同的标准化原则可以避免重新执行这些搜索。
为了保留BN原则,同时消除对Batchsize的依赖,作者扩展的工作如下:
(i)将Eq.(1)的BN步骤替换为基于LN或GN的Batch无关的标准化步骤;
(ii)将式(2)的激活步骤替换为proxy-normalized activation步骤。
这一步通过将与同化,使归一化,其中是一个高斯proxy变量,具有均值和方差,如果选择LN作为Batch无关的归一化,对于每个batch元素b和通道c,这表示为:
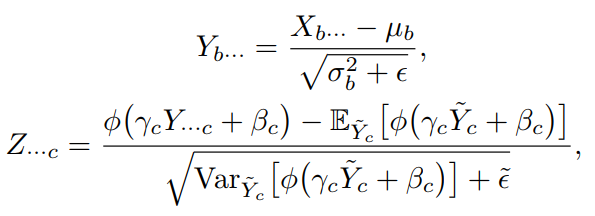
其中,,是X的batch元素b在空间和通道维度上的均值和标准差。
当与LN结合时,这种激活的proxy标准化(PN)迭代确保预激活Y保持接近于标准化(论文中有推导)。
3.3 Image分辨率
引入全局平均池化允许CNN对任意分辨率的输入进行操作。虽然这已经在图像分割等任务中得到了探索,但在图像分类中,其影响仍有待更加深入的挖掘。EfficientNet模型将图像分辨率作为一个可调的超参数,使用更大的图像来训练更大的网络。Hoffer等人同时对多个图像尺寸的网络进行训练发现:
i) 大分辨率可以加速训练以达到目标精度 ii) 大分辨率可以提高相同训练的最终性能。
或许与目标最接近的是,Howard建议从低分辨率图像开始训练,在训练过程中逐步增加图像的大小,以减少总的训练时间。
Touvron等人研究表明,少量的微调可以使网络收敛的更好。微调步骤只需要对网络的最后部分起作用,而且只需要几个epoch就可以提高总体精度。因此,与其他训练相比,微调的计算成本几乎可以忽略不计。
从这一研究中获得了灵感,研究了在低分辨率图像上训练的网络的微调,并从效率的角度将其推广到更大的分辨率。在训练过程中使用较小的图像可以使用更少的内存更快地训练出一个给定的模型,或者在相同的时间内训练一个较大的模型。为了测试这一想法,作者在固有的EfficientNet图像大小以大约为原来像素数的一半进行训练,这里表示为半分辨率。结果与EfficientNet模型的FLOPs大致相当。
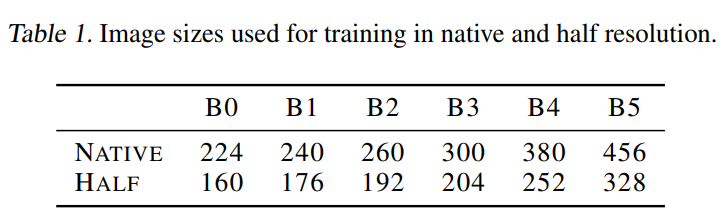
然后,微调和测试的图像尺寸范围高达700x700。在选择用于验证的精确分辨率时,注意到性能可能会受到混叠效应的影响。这种人工干扰是由于非对称下采样层的位置造成的,其中输入的维度是奇数,这取决于输入分辨率在不同的深度上决定的。作者还发现在训练和测试之间保持这些降采样层的位置一致是很重要的。这可以通过选择测试分辨率来实现,使,其中n是模型中的下采样层数(对于EfficientNet, n=5)。
4实验
4.1 Group卷积的影响
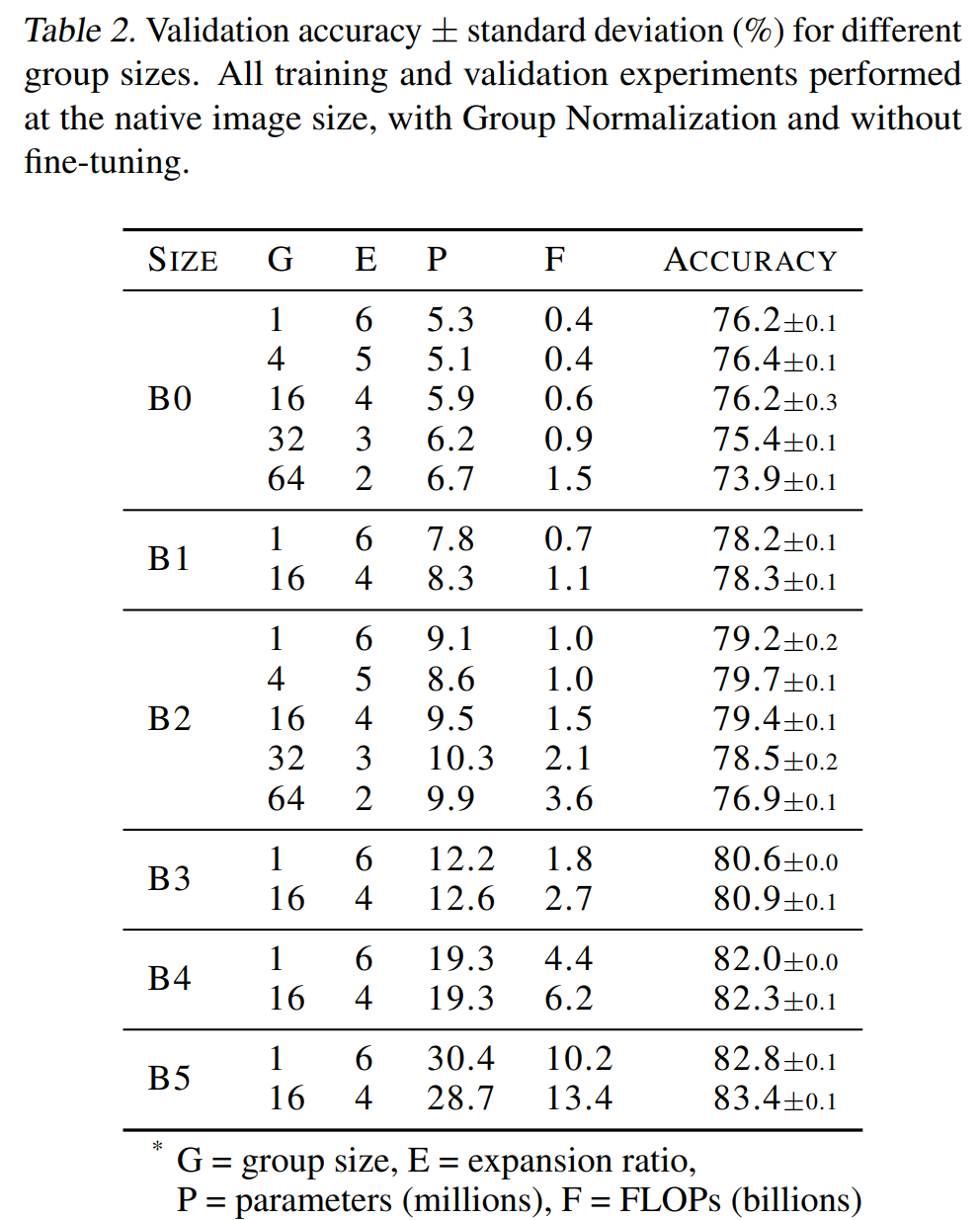
通过上表可以看出虽然组大小为G=4的情况下在这些测试中获得了最好的准确性,但发现组大小为G=16的增加的计算效益在实践中产生了比较好的权衡。
4.2 Proxy-Normalized Activations的影响
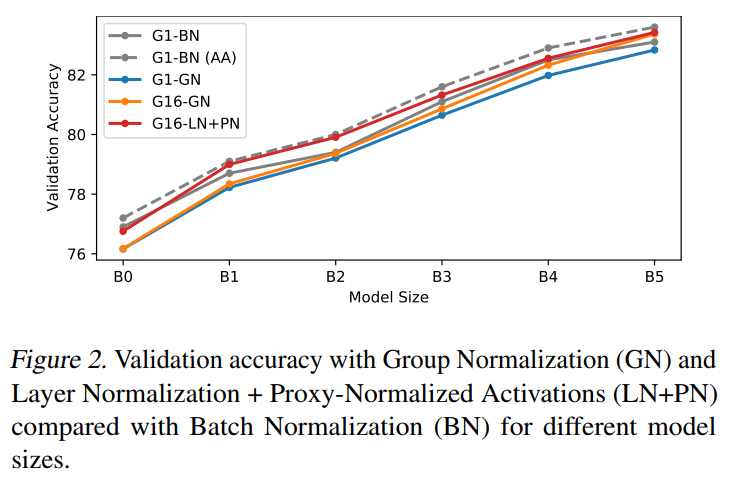
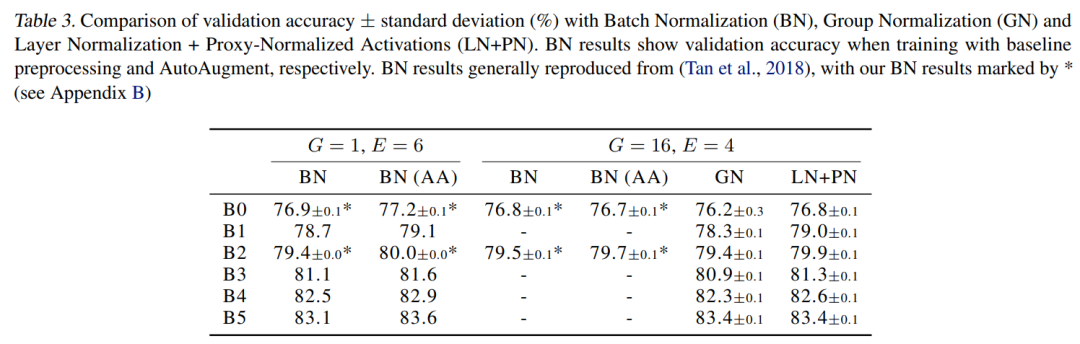
从表中可以看出,对于B0和B2,在G=16上直接比较2种方法时,LN+PN得到的准确率与BN得到的准确率最匹配。
4.3 分辨率的影响

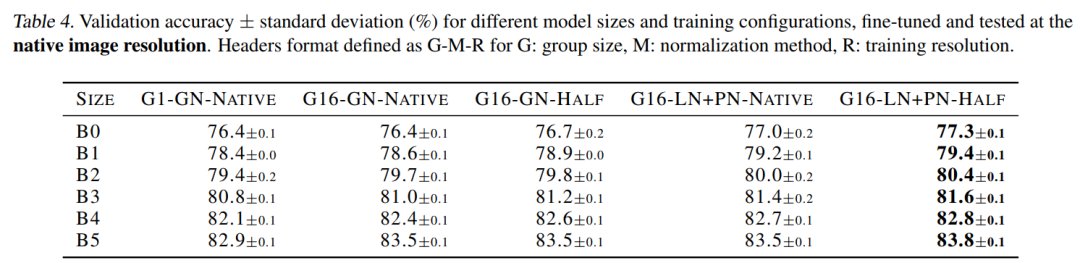
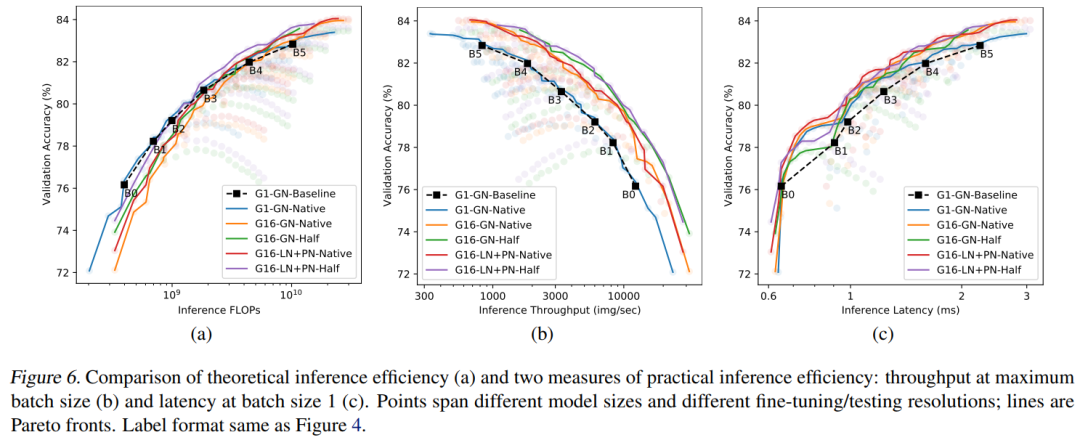
4.4 推理效率
5参考
[1].Making EfficientNet More Efficient
6推荐阅读

最强Transformer | 太顶流!Scaling ViT将ImageNet Top-1 Acc刷到90.45%啦!!!

让检测告别遮挡 | 详细解读NMS-Loss是如何解决目标检测中的遮挡问题?

即插即用 | 卷积与Self-Attention完美融合X-volution插入CV模型将带来全任务的涨点(文末附论文)
本文论文原文获取方式,扫描下方二维码
回复【MEF】即可获取论文
长按扫描下方二维码添加小助手。
可以一起讨论遇到的问题
声明:转载请说明出处
扫描下方二维码关注【集智书童】公众号,获取更多实践项目源码和论文解读,非常期待你我的相遇,让我们以梦为马,砥砺前行!
