
5 分钟理解百度 ERNIE 核心思想
❝本文主要帮助读者超短时间内理解 ERNIE 核心思想,适合正在准备面试百度的同学 (如果需要内推可以找我)。如果想要细致了解 ERNIE 的各个细节,建议读原论文:ERNIE1.0 和 ERNIE2.0
❞
本文假设读者对 Transformer 以及 BERT 有一定的了解。
ERNIE 1.0
「ERNIE1.0 主要是改进了 BERT 的 MLM 任务。」 我们看图说话,
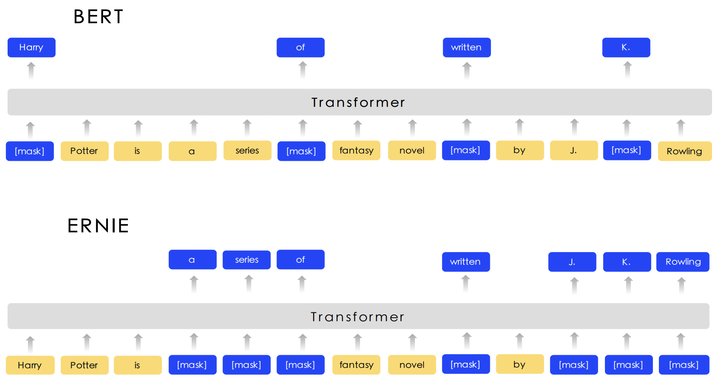
从图中,我们很容易发现 ERNIE1.0 对于 BERT 的改进是在 MLM 任务。在论文,作者阐述了三种不同的 mask 技巧:
基础 mask:任意 mask 一个单词 (BERT 所采用的 mask 类型) 短语 mask:不是将单词看成一个整体,而是将短语看成一个整体;(比如上图中,mask 了 a series of 而不仅仅是 of) 实体 mask:mask 一个实体名。(比如上图中,mask 的是 J.K.Rowling,而不是 K.)
好了,这样子最初版的 ERNIE 就讲完了。下面我们开始讲 ERNIE2.0.
ERNIE 2.0
「ERNIE2.0 主要是在 ERNIE1.0 的基础上,使用了新的多任务训练的框架。」 BERT 的预训练中,采用了 MLM 和 NSP 两种任务,目的是为了让模型能够学出更好的词表示向量,以及句子之间的关系。对于这样的多任务训练,ERNIE2.0 系统化的提出了 3 大类任务,并让 ERNIE 基于这三大类任务进行学习。我们先看图:
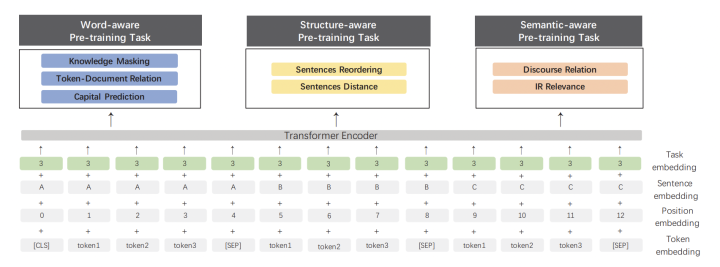
我们首先介绍这三大类任务,然后再介绍任务训练的方式。
预训练的三大任务
单词层面预训练任务: 知识 mask:ERNIE1.0 介绍的 mask; 单词 - 文章关系:预测一个单词是否会出现在一篇文章中,可以让模型抓住文章主旨; 首字母大写预测:一般实体的首字母得大写,所以这个任务有助于 NER 任务 结构层面预训练任务: 文章句子排序:将一组乱序的句子,重新排序成一个段落; 句子距离预测:3 分类任务,“0” 表示是一个文章中紧挨着的句子,“1” 表示是一个文章中的句子,但不是紧挨着的,“2” 表示不是一个文章中的句子 语义层面预训练任务: 语义关系:预测两个句子之间的语义关系或者修辞关系 信息检索相关性:预测 query 和 title 是否相关的 3 分类任务。“0” 表示强相关,“1” 表示若相关,“2” 表示完全不相关。
训练方式
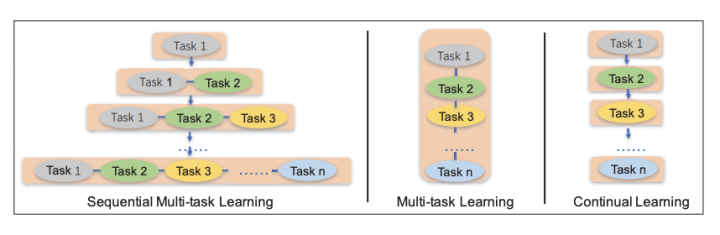
ERNIE2.0 采用的是序列多任务学习 (Sequential Multi-task Learning)。这样学习是为了让模型巩固之前的任务所学到的知识。
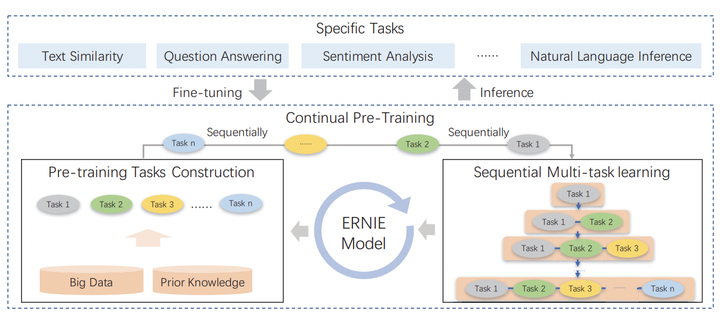
最终,ERNIE2.0 预训练的整体框架为:
评论