
【秋招求职之路】腾讯-QQ音乐一面复盘总结
往期精彩文章推荐
腾讯 QQ音乐 面经
一面
自我介绍
了解ajax跨域嘛?
什么是跨域
回顾一下 URI 的组成:

浏览器遵循「同源政策」(scheme(协议)、host(主机) 和 port(端口) 都相同则为同源)。非同源站点有这样一些限制:
不能读取和修改对方的 DOM 不读访问对方的 Cookie、IndexDB 和 LocalStorage 限制 XMLHttpRequest 请求。(后面的话题着重围绕这个)
当浏览器向目标 URI 发 Ajax 请求时,只要当前 URL 和目标 URL 不同源,则产生跨域,被称为 跨域请求。
跨域请求的响应一般会被浏览器所拦截,注意,是被「浏览器」拦截,响应其实是成功到达客户端了。那这个拦截是如何发生呢?
首先要知道的是,浏览器是多进程的,以 Chrome 为例,进程组成如下:

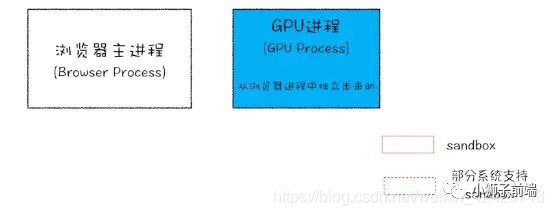
「WebKit 渲染引擎」 和 「V8 引擎」都在渲染进程当中。
当 xhr.send 被调用,即 Ajax 请求准备发送的时候,其实还只是在「渲染进程」的处理。为了防止黑客通过脚本触碰到系统资源,浏览器将每一个渲染进程装进了沙箱,并且为了防止 CPU 芯片一直存在的Spectre 和 Meltdown漏洞,采取了站点隔离的手段,给每一个不同的站点(一级域名不同)分配了沙箱,互不干扰。具体见YouTube上Chromium安全团队的演讲视频。
在沙箱当中的渲染进程是没有办法发送网络请求的,那怎么办?只能通过网络进程来发送。那这样就涉及到「进程间通信」(IPC,Inter Process Communication)了。
总的来说就是利用
Unix Domain Socket套接字,配合事件驱动的高性能网络并发库libevent完成进程的 IPC 过程。
好,现在数据传递给了「浏览器主进程」,主进程接收到后,才真正地发出相应的网络请求。在服务端处理完数据后,将响应返回,主进程检查到跨域,且没有cors(后面会详细说)响应头,将响应体全部丢掉,并不会发送给渲染进程。这就达到了拦截数据的目的。
cors跨域怎么做?
CORS 其实是 W3C 的一个标准,全称是 跨域资源共享 。它需要浏览器和服务器的共同支持,具体来说,非 IE 和 IE10 以上支持CORS,服务器需要附加特定的响应头,后面具体拆解。不过在弄清楚 CORS 的原理之前,我们需要清楚两个概念: 「简单请求」和「非简单请求」。
浏览器根据请求方法和请求头的特定字段,将请求做了一下分类,具体来说规则是这样,凡是满足下面条件的属于「简单请求」:
请求方法为 GET、POST 或者 HEAD 请求头的取值范围: Accept、Accept-Language、Content-Language、Content-Type(只限于三个值 application/x-www-form-urlencoded、multipart/form-data、text/plain)
浏览器画了这样一个圈,在这个圈里面的就是「简单请求」, 圈外面的就是「非简单请求」,然后针对这两种不同的请求进行不同的处理。
简单请求
请求发出去之前,浏览器做了什么?
它会自动在请求头当中,添加一个Origin字段,用来说明请求来自哪个源。服务器拿到请求之后,在回应时对应地添加Access-Control-Allow-Origin字段,如果Origin不在这个字段的范围中,那么浏览器就会将响应拦截。
因此,Access-Control-Allow-Origin字段是服务器用来决定浏览器是否拦截这个响应,这是必需的字段。与此同时,其它一些可选的功能性的字段,用来描述如果不会拦截,这些字段将会发挥各自的作用。
「Access-Control-Allow-Credentials」。这个字段是一个布尔值,表示是否允许发送 Cookie,对于跨域请求,浏览器对这个字段「默认值」设为 false,而如果需要拿到浏览器的 Cookie,需要添加这个响应头并设为true, 并且在前端也需要设置withCredentials属性:
let xhr = new XMLHttpRequest();
xhr.withCredentials = true;
「Access-Control-Expose-Headers」。这个字段是给 XMLHttpRequest 对象赋能,让它不仅可以拿到基本的 6 个响应头字段(包括Cache-Control、Content-Language、Content-Type、Expires、Last-Modified 和 Pragma), 还能拿到这个字段声明的响应头字段。比如这样设置:
Access-Control-Expose-Headers: aaa
那么在前端可以通过 XMLHttpRequest.getResponseHeader('aaa')拿到 aaa 这个字段的值。
非简单请求
非简单请求相对而言会有些不同,体现在两个方面: 「预检请求」和「响应字段」。
我们以 PUT 方法为例。
var url = 'http://xxx.com';
var xhr = new XMLHttpRequest();
xhr.open('PUT', url, true);
xhr.setRequestHeader('X-Custom-Header', 'xxx');
xhr.send();
当这段代码执行后,首先会发送「预检请求」。这个预检请求的请求行和请求体是下面这个格式:
OPTIONS / HTTP/1.1
Origin: 当前地址
Host: xxx.com
Access-Control-Request-Method: PUT
Access-Control-Request-Headers: X-Custom-Header
预检请求的方法是 OPTIONS,同时会加上Origin源地址和Host目标地址,这很简单。同时也会加上两个关键的字段:
Access-Control-Request-Method, 列出 CORS 请求用到哪个HTTP方法 Access-Control-Request-Headers,指定 CORS 请求将要加上什么请求头
这是预检请求。接下来是「响应字段」,响应字段也分为两部分,一部分是对于「预检请求」的响应,一部分是对于 「CORS 请求」的响应。
「预检请求的响应」。如下面的格式:
HTTP/1.1 200 OK
Access-Control-Allow-Origin: *
Access-Control-Allow-Methods: GET, POST, PUT
Access-Control-Allow-Headers: X-Custom-Header
Access-Control-Allow-Credentials: true
Access-Control-Max-Age: 1728000
Content-Type: text/html; charset=utf-8
Content-Encoding: gzip
Content-Length: 0
其中有这样几个关键的「响应头字段」:
Access-Control-Allow-Origin: 表示可以允许请求的源,可以填具体的源名,也可以填*表示允许任意源请求。 Access-Control-Allow-Methods: 表示允许的请求方法列表。 Access-Control-Allow-Credentials: 简单请求中已经介绍。 Access-Control-Allow-Headers: 表示允许发送的请求头字段 Access-Control-Max-Age: 预检请求的有效期,在此期间,不用发出另外一条预检请求。
在预检请求的响应返回后,如果请求不满足响应头的条件,则触发XMLHttpRequest的onerror方法,当然后面真正的「CORS」请求也不会发出去了。
「CORS 请求的响应」。绕了这么一大转,到了真正的 CORS 请求就容易多了,现在它和「简单请求」的情况是一样的。浏览器自动加上Origin字段,服务端响应头返回「Access-Control-Allow-Origin」。可以参考以上简单请求部分的内容。
说说jsonp原理
虽然XMLHttpRequest对象遵循同源政策,但是script标签不一样,它可以通过 src 填上目标地址从而发出 GET 请求,实现跨域请求并拿到响应。这也就是 JSONP 的原理,接下来我们就来封装一个 JSONP:
/* 自定义封装jsonp */
let jsonp = ({ url, params, callbackName }) => {
let generateUrl = () => {
let dataStr = ''
for (let key in params) {
dataStr += `${key}=${params[key]}`
}
dataStr += `callback=${callbackName}`
return `${url}?${dataStr}`
}
return new Promise((resolve, reject) => {
// 创建 script 元素并加入到当前文档中
let scriptEle = document.createElemet('script')
script.src = generateUrl
document.body.appendChild(scriptEle)
try {
resolve(data)
} catch (e) {
reject(e)
} finally {
// script 执行完了,成为无用元素,需要清除
document.body.removeChild(scriptEle)
}
})
}
当然在服务端也会有响应的操作, 以 「express」 为例:
/* 服务端相关操作,以express为例 */
let express = require('express')
let app = express()
const port = '3000'
app.get('/',function(req,res){
let {a,b,callback} = req.query
console.log(a)
console.log(b)
// 注意,返回给script标签,浏览器直接把这部分字符串执行
res.send(`${callback}('数据包')`)
})
app;listen(port)
前端这样简单地调用一下就好了:
/* 前端调用 */
jsonp({
url: 'http://localhost:3000',
params: {
a: 1,
b: 2
}
}).then(data=>{
console.log(data) //该数据包
})
和CORS相比,JSONP 最大的优势在于兼容性好,IE 低版本不能使用 CORS 但可以使用 JSONP,缺点也很明显,请求方法单一,只支持 GET 请求。
拓展:Nginx
Nginx 是一种高性能的 反向代理 服务器,可以用来轻松解决跨域问题。
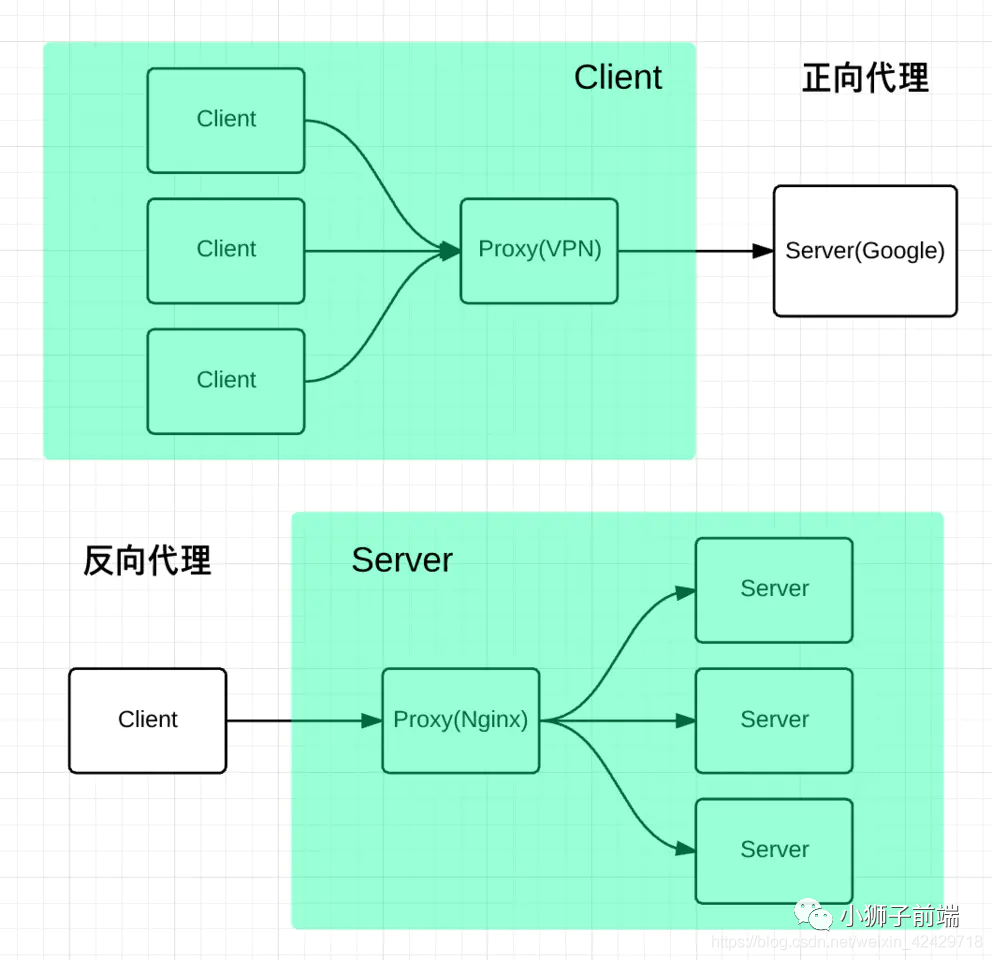
正向代理帮助客户端「访问」客户端自己访问不到的服务器,然后将结果返回给客户端。
反向代理拿到客户端的请求,将请求转发给其他的服务器,主要的场景是维持服务器集群的「负载均衡」,换句话说,反向代理帮「其它的服务器」拿到请求,然后「选择一个合适」的服务器,将请求转交给它。
因此,两者的区别就很明显了,正向代理服务器是帮「客户端」做事情,而反向代理服务器是帮其它的「服务器」做事情。
好了,那 Nginx 是如何来解决跨域的呢?
比如说现在客户端的域名为 client.com,服务器的域名为 server.com,客户端向服务器发送 Ajax 请求,当然会跨域了,那这个时候让 Nginx 登场了,通过下面这个配置:
server {
listen 80;
server_name client.com;
location /api {
proxy_pass server.com;
}
}
Nginx 相当于起了一个跳板机,这个跳板机的域名也是 client.com,让客户端首先访问 client.com/api,这当然没有跨域,然后 Nginx 服务器作为反向代理,将请求转发给 server.com,当响应返回时又将响应给到客户端,这就完成整个跨域请求的过程。
还有一些不太常用的方式,了解即可,比如postMessage,当然WebSocket也是一种方式,但是已经不属于 HTTP 的范畴。
如果是用node来做跨域的话,你会怎么做?
(1) 浏览器会自动进行 CORS 通信,实现 CORS 通信的关键是后端。只要后端实现了 CORS,就实现了跨域。(2) 服务端设置 Access-Control-Allow-Origin 就可以开启 CORS。该属性表示哪些域名可以访 问资源,如果设置通配符(*)则表示所有网站都可以访问资源。(3)设置 CORS 和前端没什么关系,但是通过这种方式解决跨域问题的话,会在发送请求时出现两种情况,分 别为简单请求和复杂请求。(上文已经提到)
先以 express 为例
//allow custom header and CORS
app.all('*',function (req, res, next) {
res.header('Access-Control-Allow-Origin', '*');
res.header('Access-Control-Allow-Headers', 'Content-Type, Content-Length, Authorization, Accept, X-Requested-With , yourHeaderFeild');
res.header('Access-Control-Allow-Methods', 'PUT, POST, GET, DELETE, OPTIONS');
if (req.method == 'OPTIONS') {
res.send(200); /让options请求快速返回/
}
else {
next();
}
});
介绍一个 cors 模块,引入就可以解决了。代码如下:
/* express引入cors模块 */
let express = require('express')
let cors = require('cors')
let app = express()
app.use(cors())
app.get('/products/:id', function (req, res, next) {
res.json({ msg: 'This is CORS-enabled for all origins!' })
})
app.listen(80, function () {
console.log('CORS-enabled web server listening on port 80')
})
然后,我们再以 koa 为例
「服务端: 3001端口」
var Koa = require('koa');
var Router = require('koa-router');
const bodyParser = require('koa-bodyparser')
var app = new Koa();
var router = new Router();
app.use(bodyParser()); // 解析body数据
router.options('/test',async (ctx, next) => {
ctx.set("Access-Control-Allow-Origin", "*");
ctx.set("Access-Control-Allow-Headers", "Content-Type");
ctx.set("Access-Control-Allow-Methods","PUT,POST,GET,DELETE,OPTIONS");
ctx.set('Access-Control-Allow-Credentials', true);
ctx.set("Content-Type", "application/json;charset=utf-8");
ctx.status = 204;
});
router.post('/test',async (ctx, next) => {
// ctx.router available
ctx.set("Access-Control-Allow-Origin", "*");
ctx.set("Access-Control-Allow-Headers", "Content-Type");
ctx.set("Access-Control-Allow-Methods","PUT,POST,GET,DELETE,OPTIONS");
ctx.set('Access-Control-Allow-Credentials', true);
ctx.set("Content-Type", "application/json;charset=utf-8");
ctx.body = {
status: 'success',
result: ctx.request.body
};
});
app
.use(router.routes())
.use(router.allowedMethods());
app.listen(3001);
「客户端:」
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>测试</title>
</head>
<body>
<script>
fetch('http://localhost:3001/test', {
method: 'POST',
headers: {
'Content-Type': 'application/json;charset=utf-8'
},
body: JSON.stringify({
data: 'Test'
})
}).then(data => {
console.log(data);
})
</script>
</body>
</html>
koa 也有个 cors 模块.代码如下:
/* koa引入cors模块 */
var koa = require('koa')
var route = require('koa-route')
var cors = require('koa-cors')
var app = koa()
app.use(cors())
app.use(
route.get('/', function () {
this.body = { msg: 'Hello World!' }
})
)
app.listen(3000)
怎样给一个新增的dom节点绑定事件?(询问事件代理的作用)
事件委托(事件代理)的作用?
支持为同一个DOM元素注册多个同类型事件 可将事件分成事件捕获和事件冒泡机制
「注册多个事件」
用以往注册事件的方法,如果存在多个事件,后注册的事件会覆盖先注册的事件
//index.html
<div id="div1"></div>
window.onload = function(){
let div1 = document.getElementById('div1');
div1.onclick = function(){
console.log('打印第一次')
}
div1.onclick = function(){
console.log('打印第二次')
}
}
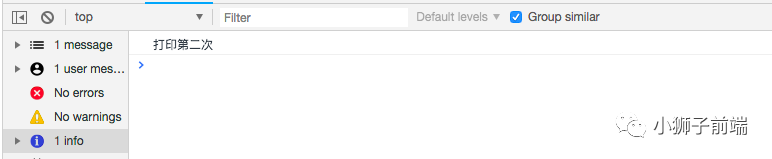
可以看到第二个点击注册事件覆盖了第一个注册事件,只执行了console.log('打印第二次');
用 addEventListener(type,listener,useCapture)实现
type: 必须,String类型,事件类型 listener: 必须,函数体或者JS方法 useCapture: 可选,boolean类型。指定事件是否发生在捕获阶段。「默认」为false,事件发生在「冒泡」阶段
<div id="div1"></div>
window.onload = function(){
let div1 = document.getElementById('div1');
div1.addEventListener('click',function(){
console.log('打印第一次')
})
div1.addEventListener('click',function(){
console.log('打印第二次')
})
}
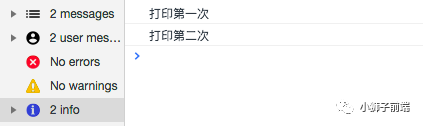
可以看到两个注册事件都成功触发了。useCapture是事件委托的关键,我们后面详解
「事件捕获和事件冒泡机制」
事件捕获
当一个事件触发后,从Window对象触发,不断「经过下级节点,直到目标节点」。在事件到达目标节点之前的过程就是捕获阶段。所有经过的节点,都会触发对应的事件
事件冒泡
当事件到达目标节点后,会「沿着捕获阶段的路线原路返回」。同样,所有经过的节点,都会触发对应的事件
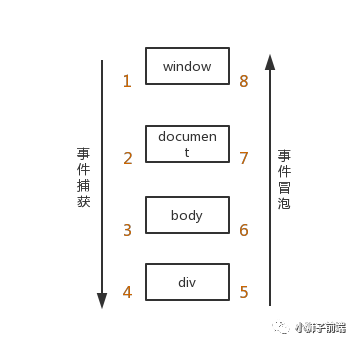 通过例子理解两个事件机制:
例子:假设有body和body节点下的div1均有绑定了一个注册事件.
效果:
通过例子理解两个事件机制:
例子:假设有body和body节点下的div1均有绑定了一个注册事件.
效果:
当为事件捕获(useCapture:true)时,先执行body的事件,再执行div的事件 当为事件冒泡(useCapture:false)时,先执行div的事件,再执行body的事件
//当useCapture为默认false时,为事件冒泡
<body>
<div id="div1"></div>
</body>
window.onload = function(){
let body = document.querySelector('body');
let div1 = document.getElementById('div1');
body.addEventListener('click',function(){
console.log('打印body')
})
div1.addEventListener('click',function(){
console.log('打印div1')
})
}
//结果:打印div1 打印body
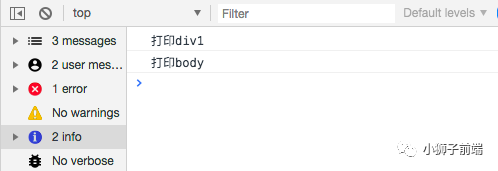
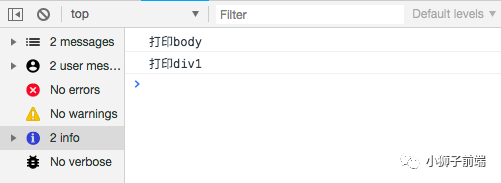
//当useCapture为true时,为事件捕获
<body>
<div id="div1"></div>
</body>
window.onload = function(){
let body = document.querySelector('body');
let div1 = document.getElementById('div1');
body.addEventListener('click',function(){
console.log('打印body')
},true)
div1.addEventListener('click',function(){
console.log('打印div1')
})
}
//结果:打印body 打印div1
事件委托和新增节点绑定事件的关系?
事件委托的优点:
「提高性能」: 每一个函数都会占用内存空间,只需添加一个事件处理程序代理所有事件,所占用的内存空间更少。 「动态监听」: 使用事件委托可以「自动绑定动态添加的元素」,即新增的节点不需要主动添加也可以一样具有和其他元素一样的事件。
例子解析:
<script>
window.onload = function(){
let div = document.getElementById('div');
div.addEventListener('click',function(e){
console.log(e.target)
})
let div3 = document.createElement('div');
div3.setAttribute('class','div3')
div3.innerHTML = 'div3';
div.appendChild(div3)
}
</script>
<body>
<div id="div">
<div class="div1">div1</div>
<div class="div2">div2</div>
</div>
</body>
虽然没有给div1和div2添加点击事件,但是无论是点击div1还是div2,都会打印当前节点。因为其父级绑定了点击事件,点击div1后冒泡上去的时候,执行父级的事件。
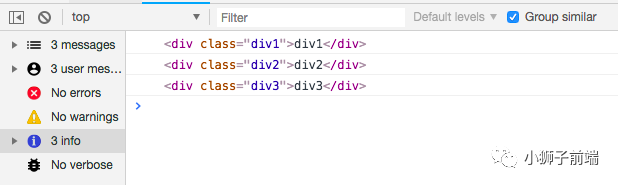
这样无论后代新增了多少个节点,一样具有这个点击事件的功能。
了解浏览器缓存吗?(强缓存、协商缓存)你怎样更新强缓存呢?

1.强缓存
强缓存是指直接通过本地缓存获取资源,不用经过服务器
常用字段:
expires 值为一个绝对时间的 GMT 格式的时间字符串,如果发送请求的时间在 expires 之前,那么本地缓存有效,否则就会发送请求到服务器来获取资源。
缺点:无法保证客户端按照标准时间设定
Cache-Control(常用值如下):
max-age:允许的最大缓存秒数 no-store:不允许使用缓存,「每次都要向服务器获取」no-cache:不允许使用本地缓存,「每次都要向服务器进行协商缓存」public:允许被「所有」中间代理和终端浏览器缓存 private:只允许被终端浏览器缓存 Cache-Control 比 expires 优先级高
2.协商缓存
协商缓存是指客户端「向服务端确认资源是否用」
常用字段:
Last-Modified / If-Modified-Since:
值是 GMT 格式的时间字符串,具体流程如下:
浏览器第一次请求资源,服务端返回 Last-Modified,表示资源在服务端的最后修改时间。浏览器第二次请求的时候会在请求头上携带If-Modified-Since,值为上次返回的 Last-Modified服务端收到请求后,比较保存的 Last-Modified 和 请求报文中的 If-Modified-Since,如果一致就返回 304 状态码,不一致就返回新资源,同时更新 Last-Modified 值
ETag / If-None-Match
值是服务器生成的资源标识符,当资源修改后这个值会被改变,
具体流程与 Last-Modified、If-Modified-Since 相似,但与 Last-Modified 不一样的是,当服务器返回304的响应时,由于 ETag 重新生成过,response header中还会把这个 ETag 返回,即使这个 ETag 跟之前的没有变化。
既生 Last-Modified 何生 Etag
一些文件也许会周期性的更改,但是他的内容并不改变(仅仅改变的修改时间),这个时候我们并不希望客户端认为这个文件被修改了,我们就可以使用
Etag来做某些文件修改非常频繁,比如在「秒以下的时间内」进行修改,(比方说1s内修改了N次),
If-Modified-Since能检查到的粒度是s级的,这种修改无法判断
最佳实践
缓存的意义就在于
减少请求,更多地使用本地的资源,给用户更好的体验的同时,也减轻服务器压力。所以,最佳实践,就应该是尽可能命中强缓存,同时,能在更新版本的时候让客户端的缓存失效。
在更新版本之后,如何让用户第一时间使用最新的资源文件呢?机智的前端们想出了一个方法,在更新版本的时候,顺便「把静态资源的路径」改了,这样,就相当于第一次访问这些资源,就不会存在缓存的问题了。
 伟大的「webpack」可以让我们在打包的时候,在文件的命名上带上
伟大的「webpack」可以让我们在打包的时候,在文件的命名上带上 hash 值
entry:{
main: path.join(__dirname,'./main.js'),
vendor: ['react', 'antd']
},
output:{
path:path.join(__dirname,'./dist'),
publicPath: '/dist/',
filname: 'bundle.[chunkhash].js'
}
综上所述,我们可以得出一个较为合理的缓存方案:
HTML:使用协商缓存。 CSS&JS&图片:使用强缓存,文件命名带上hash值。
哈希值计算方式
webpack给我们提供了三种哈希值计算方式,分别是 hash 、chunkhash 和 contenthash。那么这三者有什么区别呢?
hash:跟整个项目的构建相关,构建生成的文件hash值都是一样的,只要项目里有文件更改,整个项目构建的hash值都会更改。 chunkhash:根据不同的入口文件(Entry)进行依赖文件解析、构建对应的chunk,生成对应的hash值。 contenthash:由文件内容产生的hash值,内容不同产生的contenthash值也不一样。
显然,我们是不会使用第一种的。改了一个文件,打包之后,其他文件的hash都变了,缓存自然都失效了。这不是我们想要的。
那chunkhash 和 contenthash 的主要应用场景是什么呢?在实际在项目中,我们一般会把项目中的css都抽离出对应的「css文件」来加以引用。如果我们使用chunkhash,当我们改了css代码之后,会发现css文件hash值改变的同时,js文件的hash值也会改变。这时候,contenthash就派上用场了。
补充:后端需要怎么设置
上文主要说的是前端如何进行打包,那后端怎么做呢?我们知道,浏览器是根据响应头的相关字段来决定缓存的方案的。所以,后端的关键就在于,根据不同的请求返回对应的缓存字段。以nodejs为例,如果「需要浏览器强缓存」,我们可以这样设置:
res.setHeader('Cache-Control', 'public, max-age=xxx');
如果需要协商缓存,则可以这样设置:
res.setHeader('Cache-Control', 'public, max-age=0');
res.setHeader('Last-Modified', xxx);
res.setHeader('ETag', xxx);
在做前端缓存时,我们尽可能设置长时间的强缓存,通过文件名加hash的方式来做版本更新。在代码分包的时候,应该将一些不常变的公共库独立打包出来,使其能够更持久的缓存。
HTTP缓存
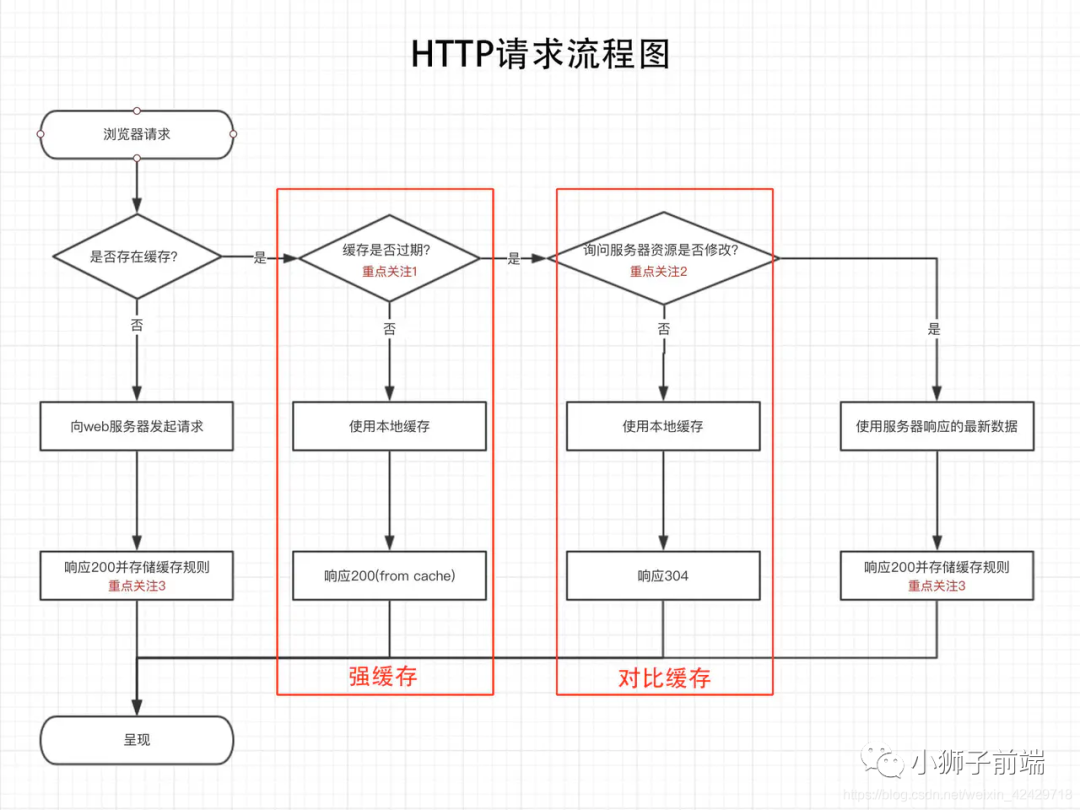
缓存配置
方案如下:
方案1:cache-control: no-store:不缓存,每次访问都从服务下载所有资源。 方案2:cache-control: no-cache或cache-control: max-age=0:对比缓存,缓存当前资源,但每次访问都需要跟服务器对比,检查资源是否被修改。(等同于expires = 过去的时间或无效时间,缓存但立即过期) 方案3:cache-control: max-age=seconds //seconds > 0:强缓存,缓存当前资源,在一定时期内,再次请求资源直接读取本地缓存。
注:强缓存下资源也并非不可更新,例如chrome的
ctrl + f5等同于直接触发方案1,f5或者webview的刷新键会直接触发方案2,但都是基于客户端操作,不建议纳入实际项目考虑。
实际项目中,方案1的应用基本上看不到,对比方案2和方案3,方案1没有任何优势。在方案2和方案3的选择中,我们会对资源作区分。
对于
img,css,js,fonts等非html资源,我们可以直接考虑方案3,并且max-age配置的时间可以尽可能久,类似于缓存规则案例中,cache-control: max-age=31535000配置365天的缓存,需要注意的是,这样配置并不代表这些资源就一定一年不变,其根本原因在于目前前端构建工具在静态资源中都会加入戳的概念(例如,webpack中的[hash],gulp中的gulp-rev),「每次修改均会改变文件名或增加query参数,本质上改变了请求的地址」,也就不存在缓存更新的问题。对于
html资源,我们建议根据项目的更新频度来确定采用哪套方案。html作为前端资源的入口文件,一旦被强缓存,那么相关的js,css,img等均无法更新。对于「高频维护的业务类」项目,建议采用方案2,或是方案3但max-age设置一个较小值,例如3600,一小时过期。对于一些活动项目,上线后「不会进行较大改动,建议采用方案3」,不过max-age也不要设置过大,否则一旦出现bug或是未知问题,用户无法及时更新。
除了以上考虑,有时候其他因素也会影响缓存的配置,例如
QQ红包除夕活动,高并发大流量很容易给服务器带来极大挑战,这时我们作为前端开发,就可以采用方案3来避免用户多次进入带来的流量压力。
对于http缓存的配置,我们始终要做到两点,一是清楚明白http缓存的原理与规则,二是明确
缓存的配置不是一次性的,根据不同的情况配置不同的规则,才能够更好的发挥http缓存的价值。
cdn缓存
cdn缓存是一种服务端缓存,CDN服务商将源站的资源缓存到遍布全国的高性能加速节点上,当用户访问相应的业务资源时,用户会被调度至最接近的节点最近的节点ip返回给用户,在web性能优化中,它主要起到了,缓解源站压力,优化不同用户的访问速度与体验的作用。
缓存规则
与http缓存规则不同的是,这个规则并不是规范性的,而是由cdn服务商来制定,我们以腾讯云举例,打开cdn加速服务配置,面板如下。
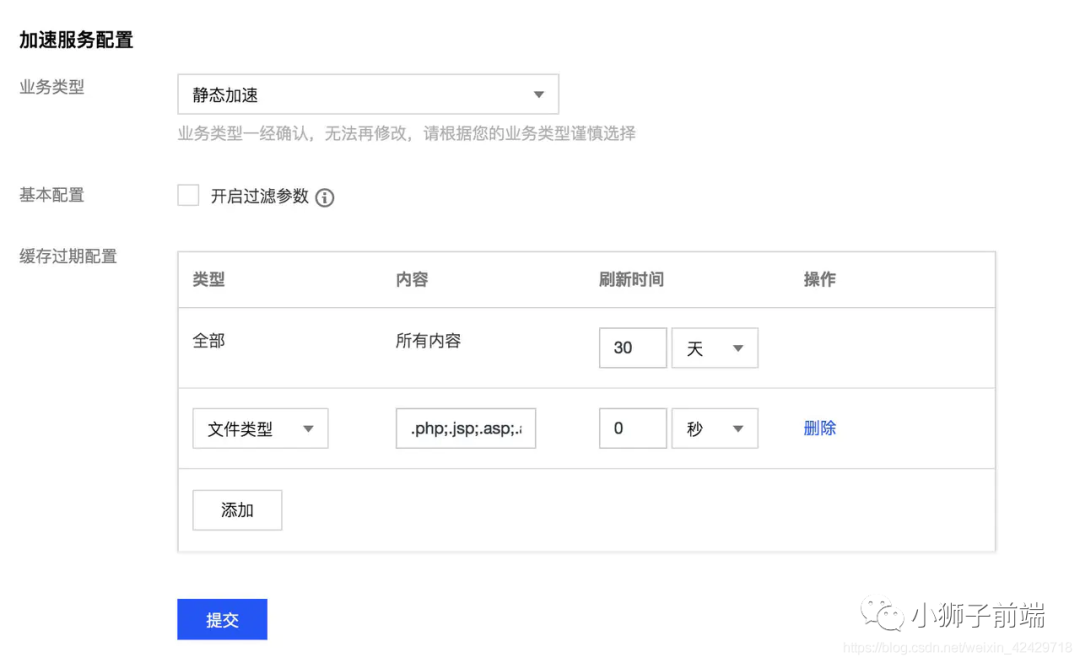 可以看到,提供给我们的配置项只有文件类型(或文件目录)和刷新时间,意义也很简单,针对不同文件类型,在cdn节点上缓存对应的时间。
可以看到,提供给我们的配置项只有文件类型(或文件目录)和刷新时间,意义也很简单,针对不同文件类型,在cdn节点上缓存对应的时间。
cdn运作流程
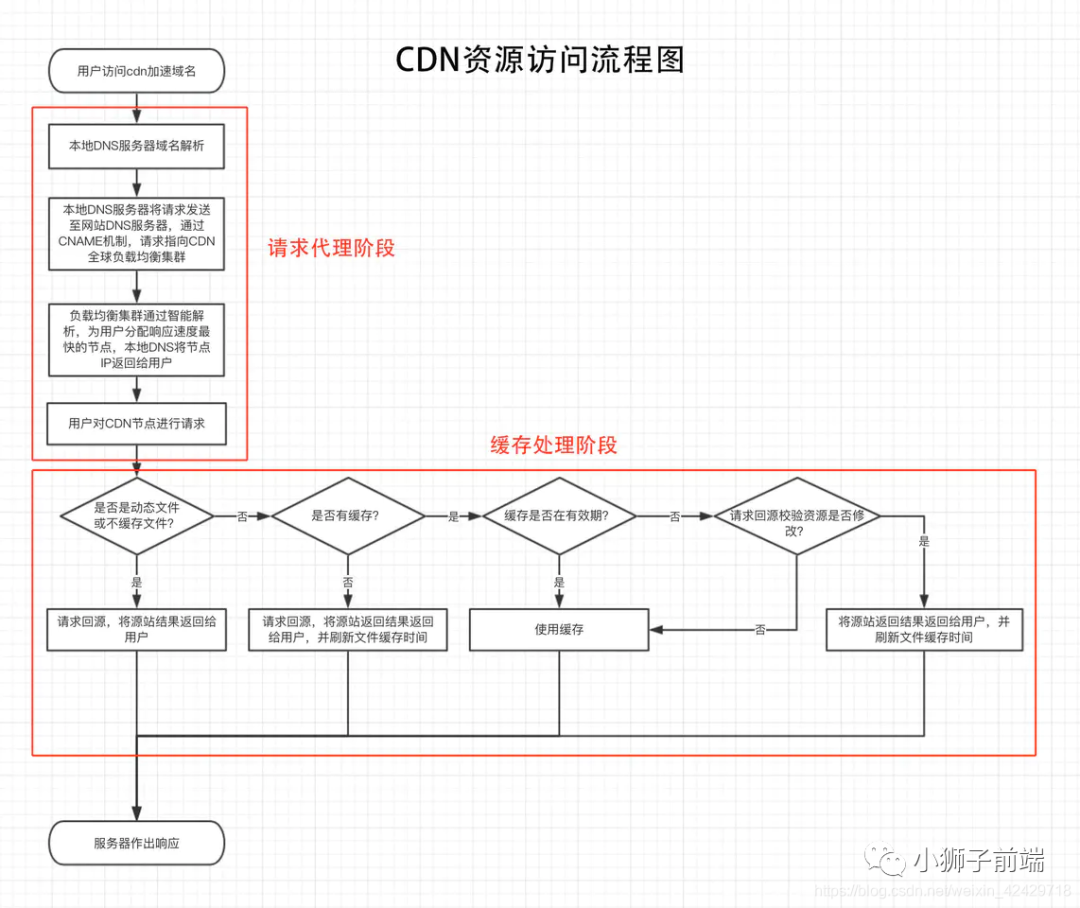 由图我们可以看出,cdn缓存的配置主要作用在缓存处理阶段,虽然配置项只有文件类型和缓存时间,但流程却并不简单,我们先来明确一个概念——「回源」,回源的意思就是「返回源站,何为源站,就是我们自己的服务器」,很多人误解接入cdn就是把资源放在了cdn上,其实不然,如图中所示,接入cdn后,我们的服务器就是源站,源站一般情况下只会在cdn节点没有资源或cdn资源失效时接收到cdn节点的请求,其他时间,源站并不会接收请求(当然,如果我们知道源站的地址,我们可以直接访问源站)。明确了回源的概念后,cdn的流程就显得不那么复杂了,简单的理解就是, 「没有资源就去源站读取,有资源就直接发送给用户。」 与http缓存不同的是,cdn中没有no-cache(max-age=0)的情况,当我们设置缓存时间为0的时候,该类型文件就被认定为不缓存文件,就是所有请求直接转发源站,「只有当缓存时间大于0且缓存过期的时候,才会与源站对比缓存是否被修改。」
由图我们可以看出,cdn缓存的配置主要作用在缓存处理阶段,虽然配置项只有文件类型和缓存时间,但流程却并不简单,我们先来明确一个概念——「回源」,回源的意思就是「返回源站,何为源站,就是我们自己的服务器」,很多人误解接入cdn就是把资源放在了cdn上,其实不然,如图中所示,接入cdn后,我们的服务器就是源站,源站一般情况下只会在cdn节点没有资源或cdn资源失效时接收到cdn节点的请求,其他时间,源站并不会接收请求(当然,如果我们知道源站的地址,我们可以直接访问源站)。明确了回源的概念后,cdn的流程就显得不那么复杂了,简单的理解就是, 「没有资源就去源站读取,有资源就直接发送给用户。」 与http缓存不同的是,cdn中没有no-cache(max-age=0)的情况,当我们设置缓存时间为0的时候,该类型文件就被认定为不缓存文件,就是所有请求直接转发源站,「只有当缓存时间大于0且缓存过期的时候,才会与源站对比缓存是否被修改。」
缓存配置
各个cdn服务商并不完全一致,以腾讯云为例,在缓存配置的文档中特别有以下说明。
 这会对我们有什么影响呢?
这会对我们有什么影响呢?
如果我们http缓存设置cache-control: max-age=600,即缓存10分钟,但cdn缓存配置中设置文件缓存时间为1小时,那么就会出现如下情况,文件被访问后第12分钟修改并上传到服务器,用户重新访问资源,响应码会是304,对比缓存未修改,资源依然是旧的,一个小时后再次访问才能更新为最新资源
如果不设置cache-control呢,在http缓存中我们说过,如果不设置cache-control,那么会有默认的缓存时间,但在这里,cdn服务商明确会在没有cache-control字段时主动帮我们添加cache-control: max-age=600。
注:针对问题1,也并非没有办法,当我们必须要在缓存期内修改文件,并且不想影响用户体验,那么我们可以「使用cdn服务商提供的强制更新缓存功能」,主要注意的是,这里的强制更新是更新服务端缓存,「http缓存」依然按照http头部规则进行自己的缓存处理,并「不会受到影响」。
http缓存与cdn缓存的结合
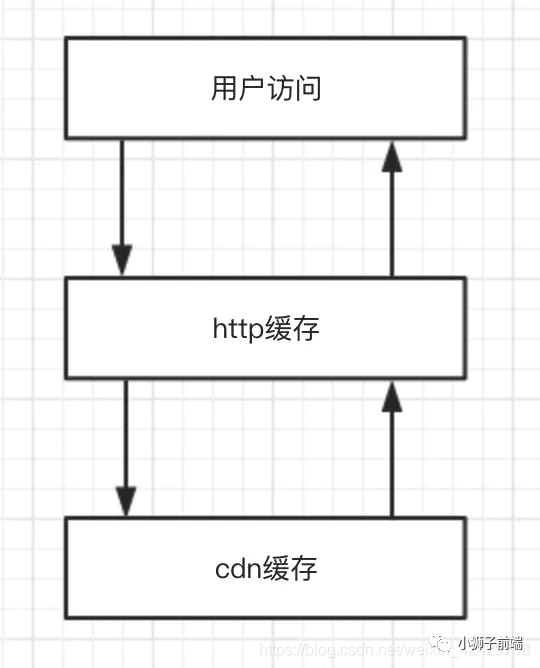 当用户访问我们的业务服务器时,首先进行的就是http缓存处理,如果http缓存通过校验,则直接响应给用户,如果「未通过校验,则继续进行cdn缓存」的处理,cdn缓存处理完成后返回给客户端,由客户端进行http缓存规则存储并响应给用户。
当用户访问我们的业务服务器时,首先进行的就是http缓存处理,如果http缓存通过校验,则直接响应给用户,如果「未通过校验,则继续进行cdn缓存」的处理,cdn缓存处理完成后返回给客户端,由客户端进行http缓存规则存储并响应给用户。
总结
「CDN的原理」
首先,浏览器会先请求CDN域名,CDN域名服务器会给浏览器返回指定域名的CNAME,浏览器在对这些CNAME进行解析,得到CDN缓存服务器的IP地址,浏览器在去请求缓存服务器,CDN缓存服务器根据内部专用的DNS解析得到实际IP,然后缓存服务器会向实际IP地址请求资源,缓存服务器得到资源后进行本地保存和返回给浏览器客户端。
如何检测JS错误,如何保证你的产品质量?(错误监控)(仅仅答了window.onerror)跨域的js运行错误可以捕获吗,错误提示什么,应该怎么处理?
script error 由来
我们的页面往往将静态资源( js、css、image )存放到第三方 CDN,或者依赖于外部的静态资源。当从「第三方加载的 javascript 执行出错」时,由于同源策略,为了保证用户信息不被泄露,不会返回详细的错误信息,取之返回 script error。
webkit 源码:
bool ScriptExecutionContext::sanitizeScriptError(String& errorMessage, int& lineNumber, String& sourceURL) {
KURL targetURL = completeURL(sourceURL);
if (securityOrigin()->canRequest(targetURL)) return false;
// 非同源,将相关的错误信息设置成默认,错误信息置为 Script error,行号置成0
errorMessage = "Script error.";
sourceURL = String();
ineNumber = 0;
return true;
}
bool ScriptExecutionContext::dispatchErrorEvent(const String& errorMessage, int lineNumber, const String& sourceURL) {
EventTarget* target = errorEventTarget();
if (!target) return false;
String message = errorMessage;
int line = lineNumber;
String sourceName = sourceURL;
sanitizeScriptError(message, line, sourceName);
ASSERT(!m_inDispatchErrorEvent);
m_inDispatchErrorEvent = true;
RefPtr<ErrorEvent> errorEvent = ErrorEvent::create(message, sourceName, line);
target->dispatchEvent(errorEvent);
m_inDispatchErrorEvent = false;
return errorEvent->defaultPrevented();
}
常见的解决方案
开启 CORS 跨域资源共享
a) 添加 crossorigin="anonymous" 属性:
<script src="http://domain/path/*.js" crossorigin="anonymous"></script>
当有 crossorigin="anonymous",浏览器以匿名的方式获取目标脚本,请求脚本时不会向服务器发送用户信息( cookie、http 证书等)。
b) 此时静态服务器需要添加跨域协议头:
Access-Control-Allow-Origin: *
完成这两步后 window.onerror 就能够捕获对应跨域脚本发生错误时的详细错误信息了。
try catch
crossorigin="anonymous" 确实可以完美解决 badjs 上报 script error 问题,但是需要服务端进行跨域头支持,而往往在大型企业,域名多的令人发指,导致跨域规则配置非常复杂,所以很难全部都配置上,而且依赖的一些外部资源也不能确保支持,所以我们在
调用外部资源方法以及一些不确认是否配置跨域头的资源方法时采用 try catch 包装,并在 catch 到问题时上报对应的错误。
function invoke(obj, method, args) {
try {
return obj[method].apply(this, args);
} catch (e) {
reportBadjs(e); // report the error
}
}
参考:前端 JavaScript 错误分析实践
结果
一面凉经,继续努力。
小狮子有话说
我是小狮子团队的【一百个Chocolate】,全网同名,周更的前端博主,分享一些前端技术干货与程序员生活日常,欢迎各位小伙伴的持续关注,一起变优秀~
学如逆水行舟,不进则退
点击【在看】可能会有红包福利出现~