
Kubernetes容量规划 | 如何调整集群的资源占用
共 4866字,需浏览 10分钟
· 2021-06-08
Kubernetes 容量规划是基础架构工程师必须面对的主要挑战之一,因为了解 Kubernetes 的资源要求和限制并非易事。
您可能预留了更多的资源,以确保容器不会用完内存或受到 CPU 限制。如果您处于这种情况,那么即使不使用这些资源,也要向云厂商付费,这也将使调度变得更加困难。这就是为什么 Kubernetes 容量规划始终是集群的稳定性和可靠性与正确使用资源之间的平衡。
在本文中,您将学习如何识别未使用的资源以及如何合理分配群集的容量。
不要成为贪婪的开发者
在某些情况下,容器需要的资源超出了限制。如果只是一个容器,它可能不会对您的账户产生重大影响。但是,如果所有容器中都发生这种情况,则在大型群集中将产生几笔额外费用。
更不用说 Pod 占用资源太大,这可能需要你会花费更多的精力来发现占用资源过多的问题。毕竟,对于 Kubernetes 来说,占用资源过多的 Pod 调度起来相对困难。
介绍两个开源工具来帮助您进行 Kubernetes 的容量规划:
kube-state-metrics:一个附加代理,用于生成和公开集群级别的指标。 CAdvisor:容器的资源使用分析器。
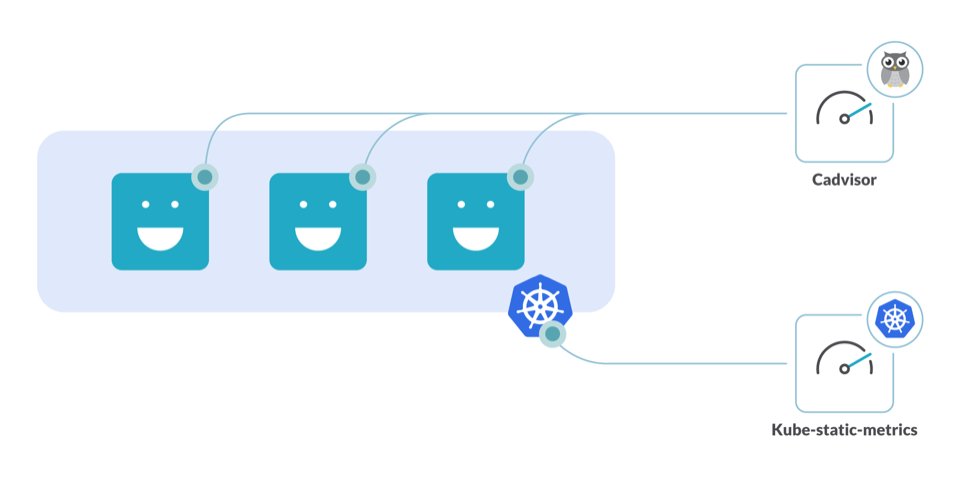
通过在群集中运行这些工具,您将能够避免资源利用不足并调整群集资源占用的大小。
如何检测未充分利用的资源
CPU
CPU 资源占用是最难调整的阈值之一,如果调整的太小可能限制服务的计算能力,如果调整的太大又会造成该节点多数计算资源处于空闲状态。
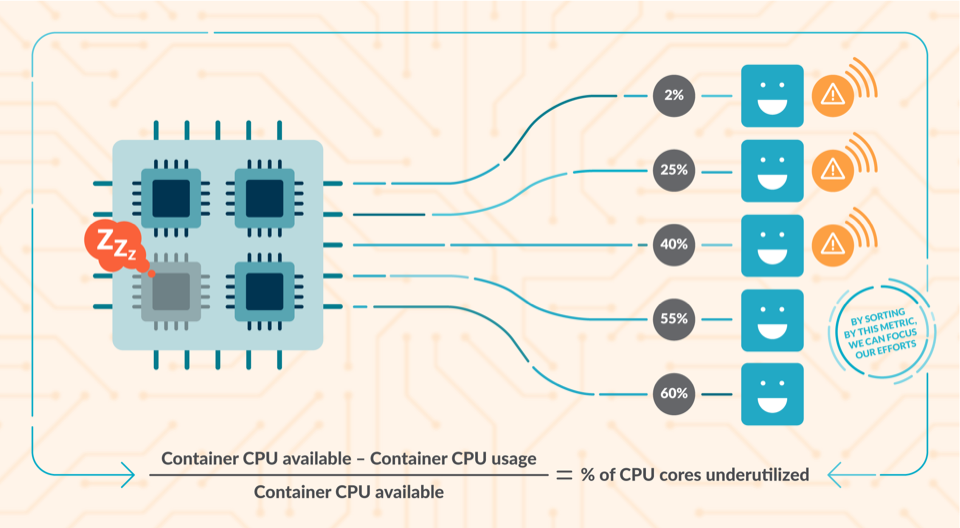
检测空闲 CPU 资源
利用给出的container_cpu_usage_seconds_total、kube_pod_container_resource_requests参数,可以检测到 CPU 核心利用情况。
sum((rate(container_cpu_usage_seconds_total{container!="POD",container!=""}[30m]) - on (namespace,pod,container) group_left avg by (namespace,pod,container)(kube_pod_container_resource_requests{resource="cpu"})) * -1 >0)
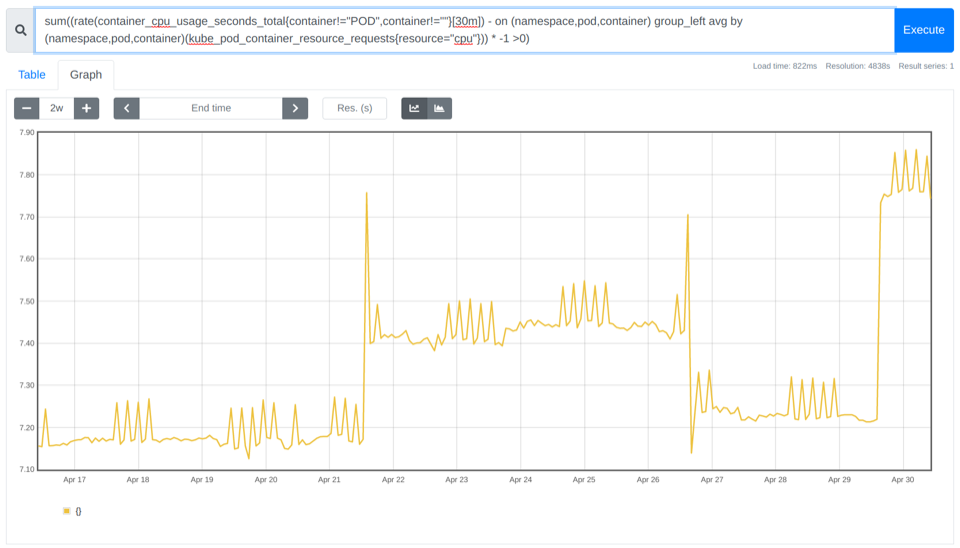 在上面的示例中,您可以看到在~7.10 和~7.85 之间没有使用内核。
在上面的示例中,您可以看到在~7.10 和~7.85 之间没有使用内核。
如何识别那些命名空间浪费了更多的 CPU 内核
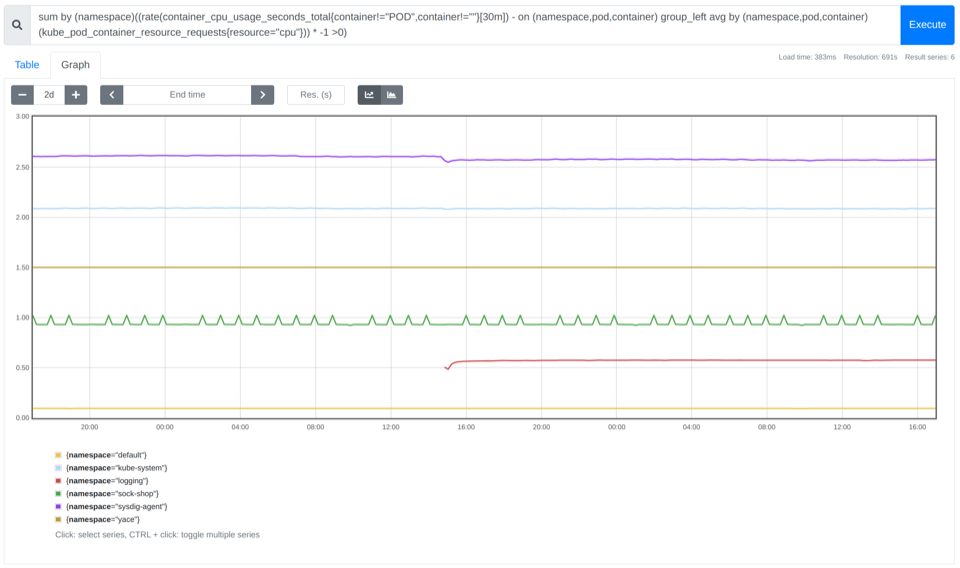
通过使用 PromQL 按名称空间汇总过去的查询,您可以获得更细粒度的使用情况。通过这些信息,使您能够向超大命名空间而且不充分利用资源的部门算账。
sum by (namespace)((rate(container_cpu_usage_seconds_total{container!="POD",container!=""}[30m]) - on (namespace,pod,container) group_left avg by (namespace,pod,container)(kube_pod_container_resource_requests{resource="cpu"})) * -1 >0)
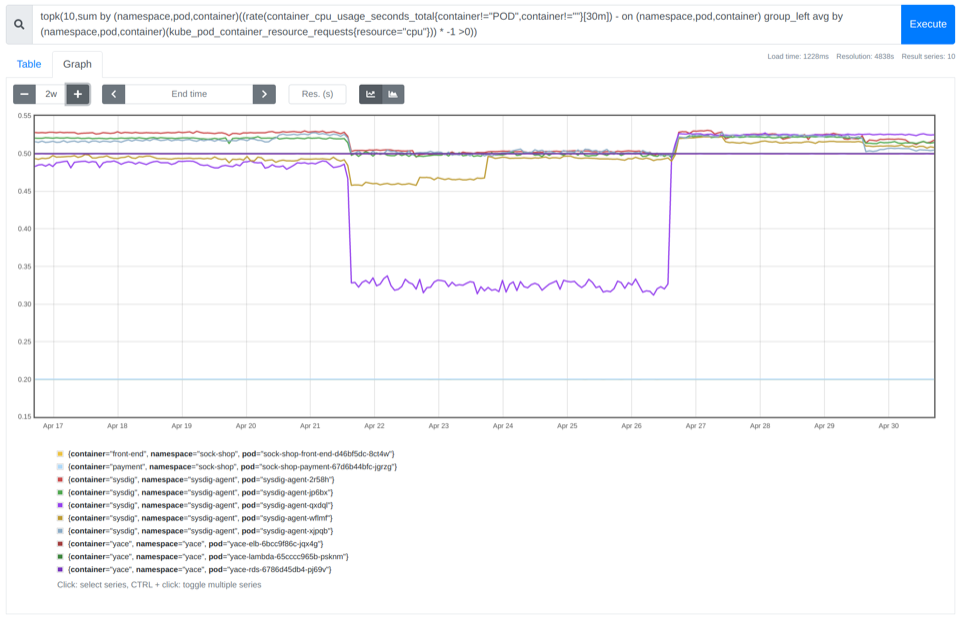
查找 CPU 占用前 10 的容器
正如我们在 PromQL 入门指南中介绍的那样,您可以使用该 topk 函数轻松获取 PromQL 查询的最佳结果。像这样:
topk(10,sum by (namespace,pod,container)((rate(container_cpu_usage_seconds_total{container!="POD",container!=""}[30m]) - on (namespace,pod,container) group_left avg by (namespace,pod,container)(kube_pod_container_resource_requests{resource="cpu"})) * -1 >0))
内存
正确进行内存规划至关重要。如果您内存使用率过高,则该节点将在内存不足时开始逐出 Pod。但是内存也是有限的,因此设置越好,每个节点可以容纳的 Pod 就越多。
检测未使用的内存
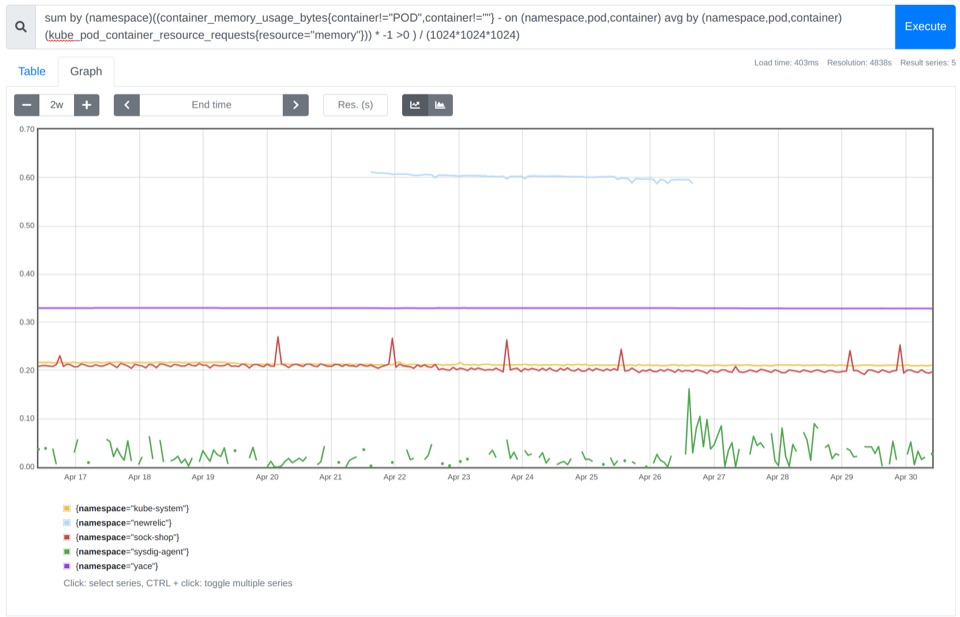
您可以使用container_memory_usage_bytes、kube_pod_container_resource_requests查看您浪费了多少内存。
sum((container_memory_usage_bytes{container!="POD",container!=""} - on (namespace,pod,container) avg by (namespace,pod,container)(kube_pod_container_resource_requests{resource="memory"})) * -1 >0 ) / (1024*1024*1024)

在上面的示例中,您可以看到可以为该集群节省 0.8gb 的成本。
如何识别哪些命名空间浪费了更多的内存
就像我们使用 CPU 一样,我们可以按命名空间进行聚合。
sum by (namespace)((container_memory_usage_bytes{container!="POD",container!=""} - on (namespace,pod,container) avg by (namespace,pod,container)(kube_pod_container_resource_requests{resource="memory"})) * -1 >0 ) / (1024*1024*1024)
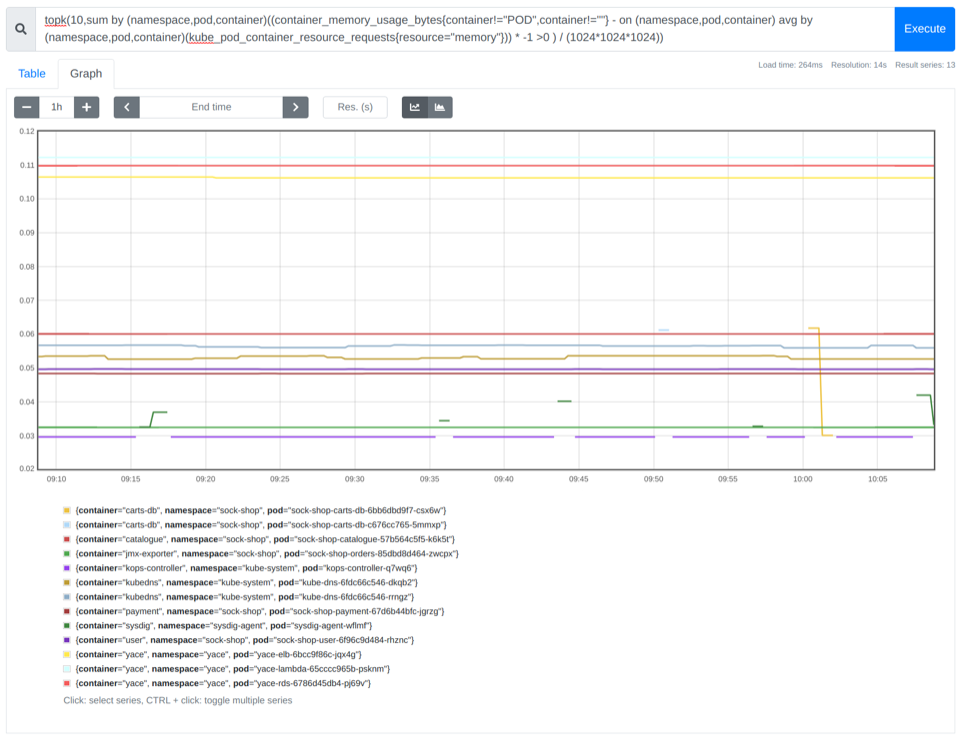
查找内存过大的前 10 个容器
同样,使用该 topk 函数,我们可以确定在每个命名空间内浪费更多内存的前 10 个容器。
topk(10,sum by (namespace,pod,container)((container_memory_usage_bytes{container!="POD",container!=""} - on (namespace,pod,container) avg by (namespace,pod,container)(kube_pod_container_resource_requests{resource="memory"})) * -1 >0 ) / (1024*1024*1024))
如何对容器的资源利用进行优化
在 Kubernetes 容量规划中,要保留足够的计算资源,您需要分析容器的当前资源使用情况。为此,您可以使用此 PromQL 查询来计算属于同一工作负载的所有容器的平均 CPU 利用率。将工作负载理解为Deployment、StatefulSet、DaemonSet。
avg by (namespace,owner_name,container)((rate(container_cpu_usage_seconds_total{container!="POD",container!=""}[5m])) * on(namespace,pod) group_left(owner_name) avg by (namespace,pod,owner_name)(kube_pod_owner{owner_kind=~"DaemonSet|StatefulSet|Deployment"}))
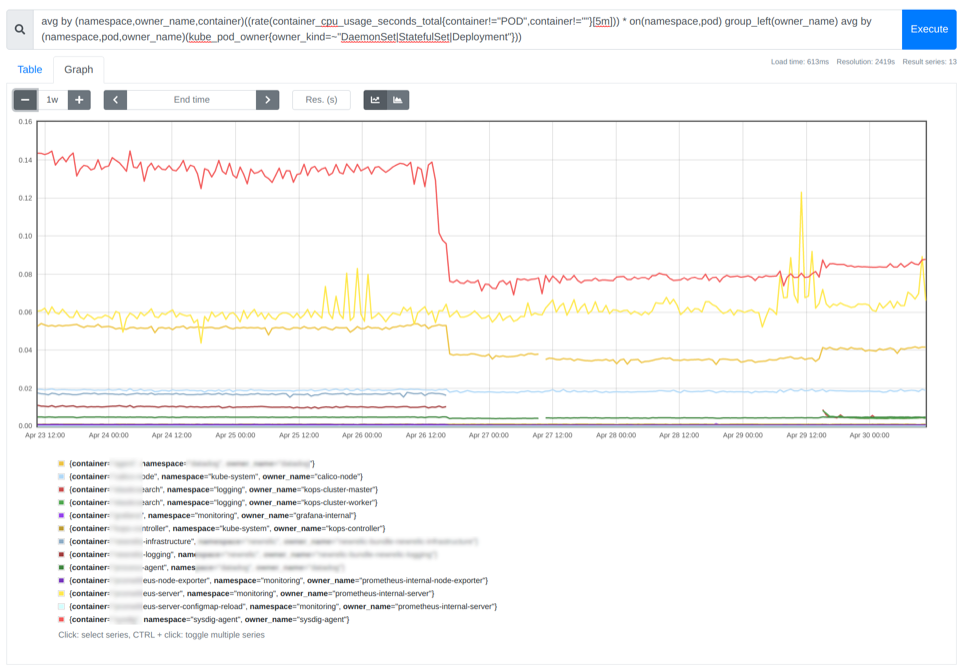
在上图中,您可以看到每个容器的平均 CPU 利用率。根据经验,可以将容器的 Request 设置为 CPU 或内存平均使用率的 85%到 115%之间的值。
如何衡量优化的影响
在执行了一些 Kubernetes 容量规划操作之后,您需要检查更改对基础架构的影响。为此,您可以将未充分利用的 CPU 内核现在与一周前的值进行比较,以评估优化后的影响。
sum((rate(container_cpu_usage_seconds_total{container!="POD",container!=""}[30m]) - on (namespace,pod,container) group_left avg by (namespace,pod,container)(kube_pod_container_resource_requests{resource="cpu"})) * -1 >0) - sum((rate(container_cpu_usage_seconds_total{container!="POD",container!=""}[30m] offset 1w) - on (namespace,pod,container) group_left avg by (namespace,pod,container)(kube_pod_container_resource_requests{resource="cpu"} offset 1w )) * -1 >0)
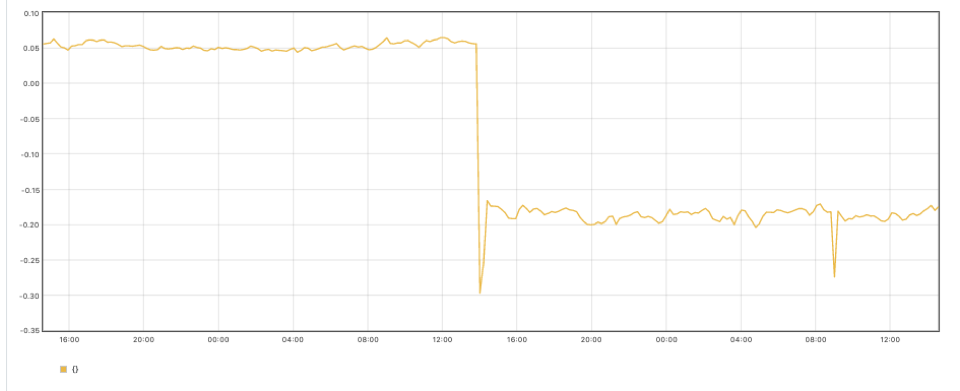
在上图中,您可以看到优化之后,集群中未使用的 CPU 更少了。
总结
现在您知道了贪婪的开发者的后果以及如何检测平台资源的过度分配。此外,您还学习了如何对容器的请求进行容量设置以及如何衡量优化的影响。
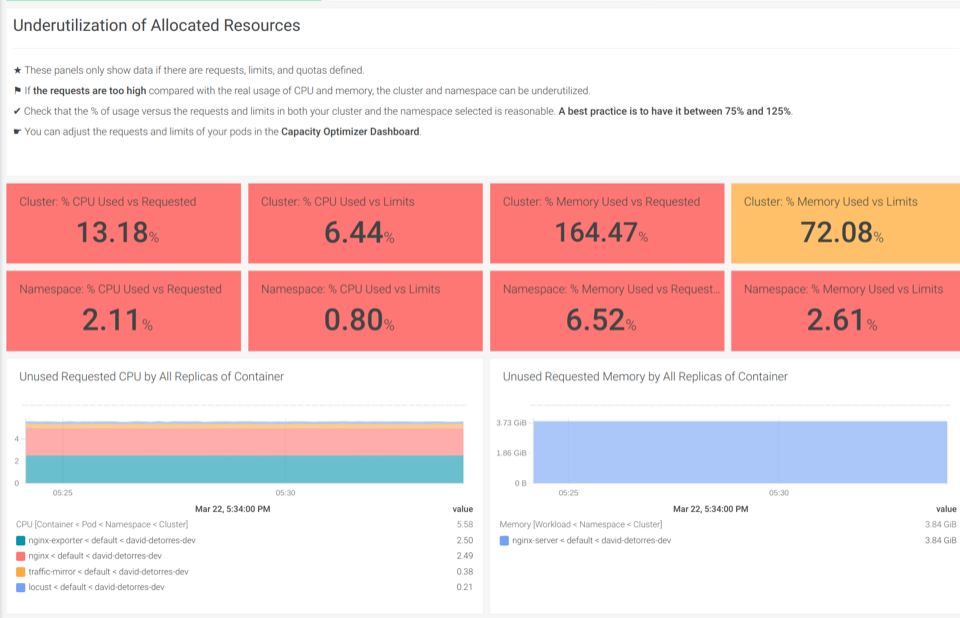
这些技巧应该是构建全面的 Kubernetes 容量规划仪表板的良好起点,并获得包含优化平台资源所需的单一面板。
更多文档请参考 [1][2][3][4]
参考资料
度量工具: https://github.com/kubernetes/kube-state-metrics
[2]度量工具: https://github.com/google/cadvisor
[3]PromQL: https://sysdig.com/blog/getting-started-with-promql-cheatsheet/
[4]内存不足的错误: https://sysdig.com/blog/troubleshoot-kubernetes-oom/
关注「开源Linux」加星标,提升IT技能
