
大三Java后端暑期实习面经总结
Java资料站
共 30533字,需浏览 62分钟
· 2021-05-28
点击上方蓝色字体,选择“标星公众号”
优质文章,第一时间送达
作者 | Baret-H
来源 | urlify.cn/6RVNRr
1. JDK、JRE、JVM的区别和联系
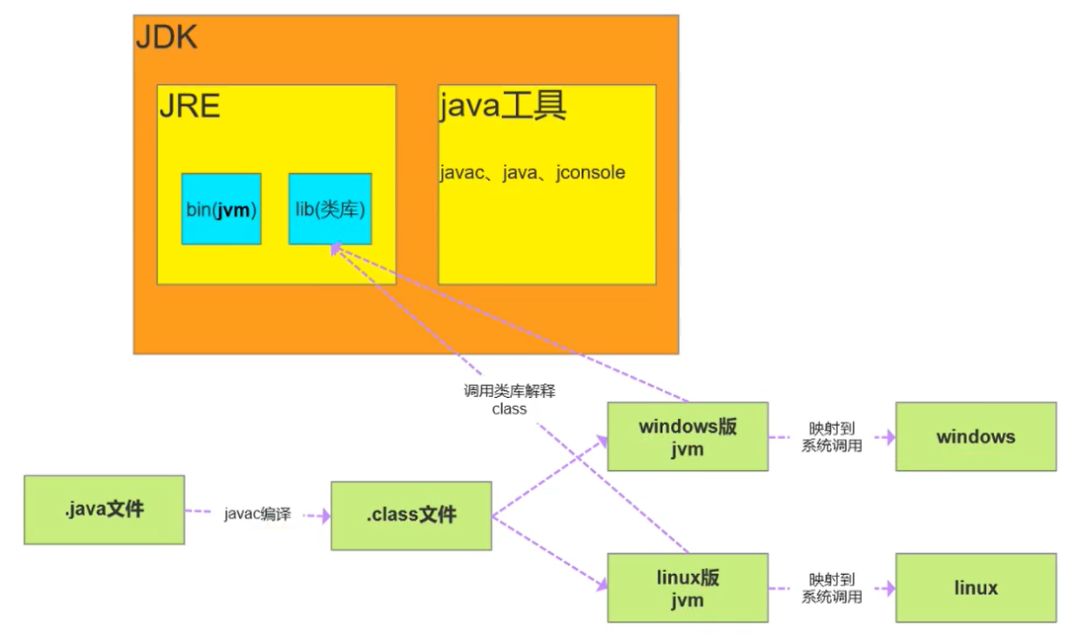
2. 采用字节码的好处
Java源代码-->编译器-->jvm可执行的java字节码-->jvm中解释器-->机器可执行的二进制机器码-->程序运行
3. 接口和抽象类的区别
4. 面向对象的四大特性
5. 面向对象和面向过程
6. 静态绑定&动态绑定
# 关于final,static,private和构造方法是前期绑定的理解:
对于private的方法,首先一点它不能被继承,既然不能被继承那么就没办法通过它子类的对象来调用,而只能通过这个类自身的对象来调用。因此就可以说private方法和定义这个方法的类绑定在了一起。
final方法虽然可以被继承,但不能被重写(覆盖),虽然子类对象可以调用,但是调用的都是父类中所定义的那个final方法,(由此我们可以知道将方法声明为final类型,一是为了防止方法被覆盖,二是为了有效地关闭java中的动态绑定)。
构造方法也是不能被继承的(网上也有说子类无条件地继承父类的无参数构造函数作为自己的构造函数,不过个人认为这个说法不太恰当,因为我们知道子类是通过super()来调用父类的无参构造方法,来完成对父类的初始化, 而我们使用从父类继承过来的方法是不用这样做的,因此不应该说子类继承了父类的构造方法),因此编译时也可以知道这个构造方法到底是属于哪个类。
对于static方法,具体的原理我也说不太清。不过根据网上的资料和我自己做的实验可以得出结论:static方法可以被子类继承,但是不能被子类重写(覆盖),但是可以被子类隐藏。(这里意思是说如果父类里有一个static方法,它的子类里如果没有对应的方法,那么当子类对象调用这个方法时就会使用父类中的方法。而如果子类中定义了相同的方法,则会调用子类的中定义的方法。唯一的不同就是,当子类对象上转型为父类对象时,不论子类中有没有定义这个静态方法,该对象都会使用父类中的静态方法。因此这里说静态方法可以被隐藏而不能被覆盖。这与子类隐藏父类中的成员变量是一样的。隐藏和覆盖的区别在于,子类对象转换成父类对象后,能够访问父类被隐藏的变量和方法,而不能访问父类被覆盖的方法)
由上面我们可以得出结论,如果一个方法不可被继承或者继承后不可被覆盖,那么这个方法就采用的静态绑定。
7. 重载和重写
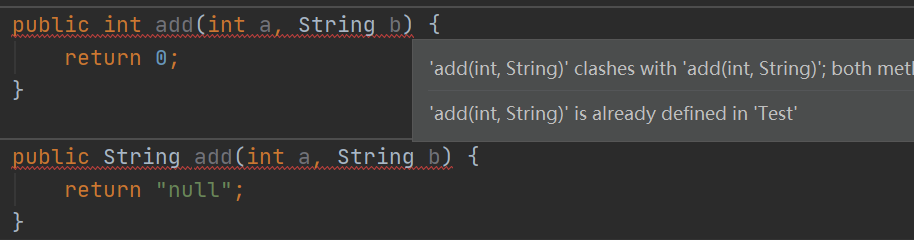
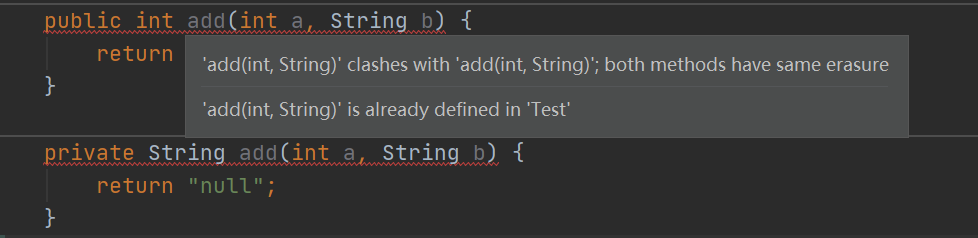
8. Java异常体系
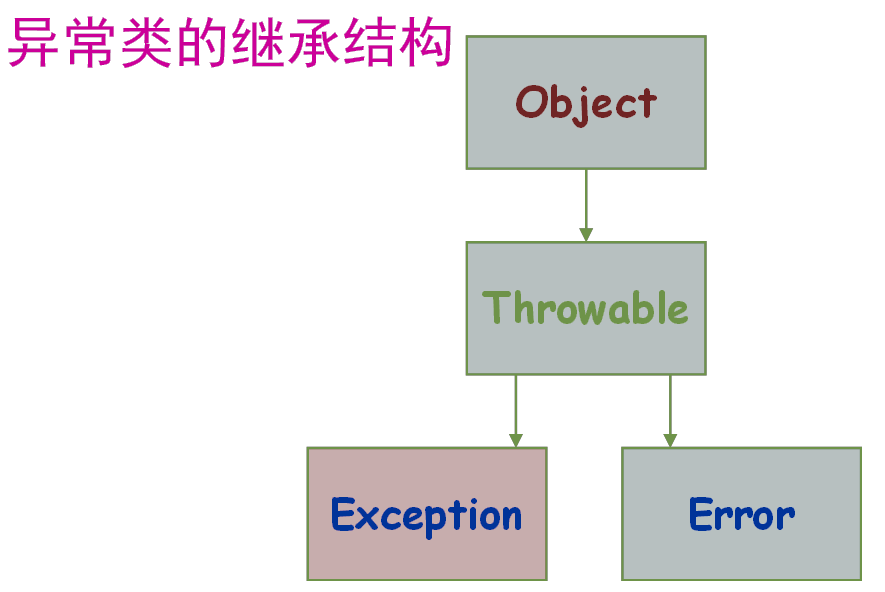
//除0错误:ArithmeticException
//错误的强制类型转换错误:ClassCastException
//数组索引越界:ArrayIndexOutOfBoundsException
//使用了空对象:NullPointerExceptionCheckedException常常发生在程序编译过程中,会导致程序编译不通过
9. final关键字


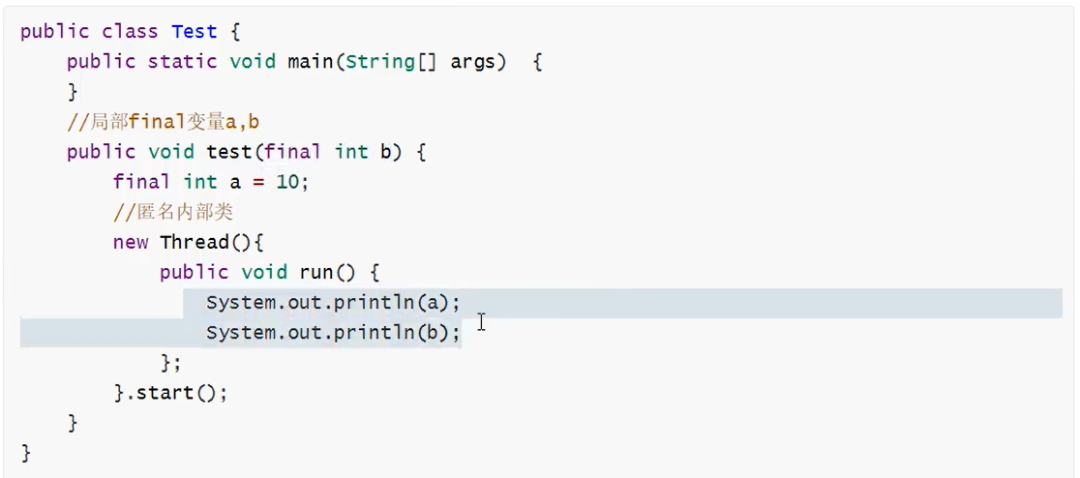
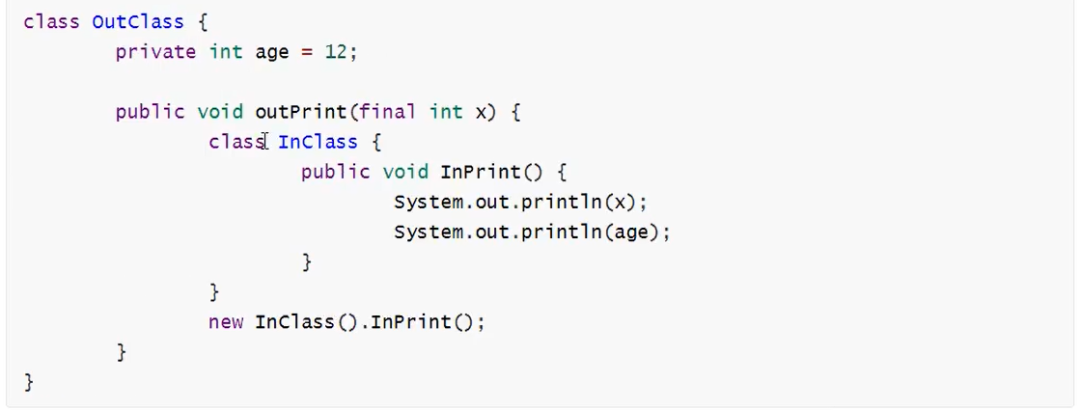
10. String、StringBuilder、StringBuffer
11. 单例模式
12. 工厂模式和建造者模式的区别
13. 深拷贝和浅拷贝
14. 泛型知识
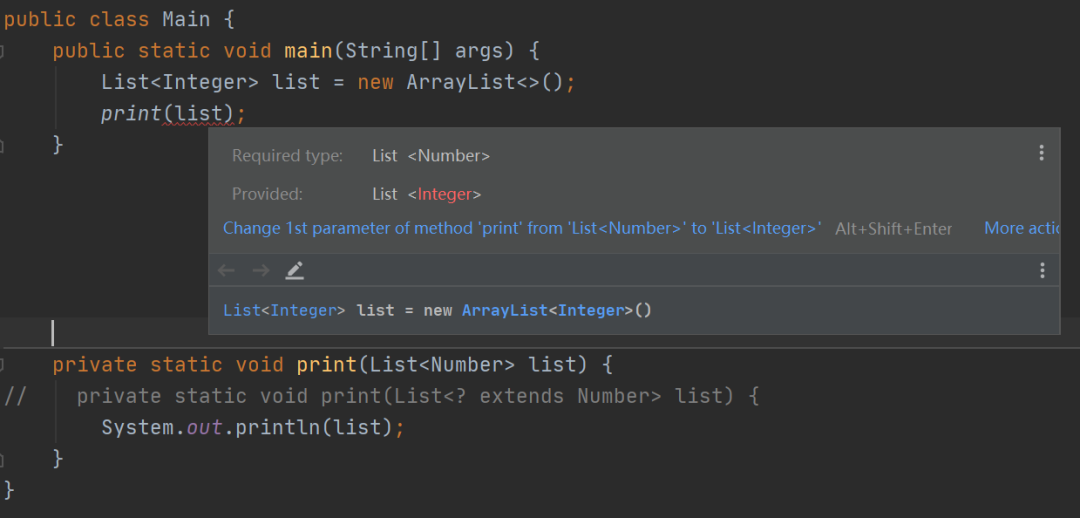
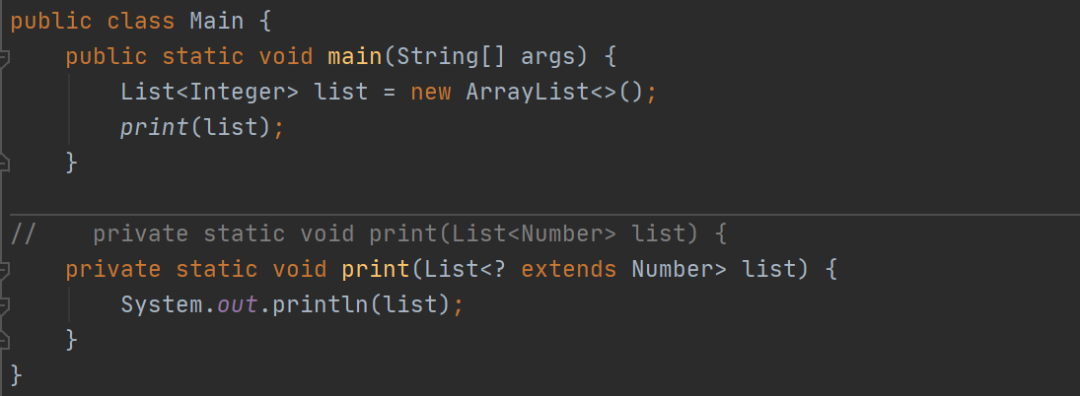
public class PECS {
ArrayList<? extends Fruit> exdentFurit;
ArrayList<? super Fruit> superFurit;
Apple apple = new Apple();
private void test() {
Fruit a1 = exdentFurit.get(0);
Fruit a2 = superFurit.get(0); //Err1
exdentFurit.add(apple); //Err2
superFurit.add(apple);
}
}
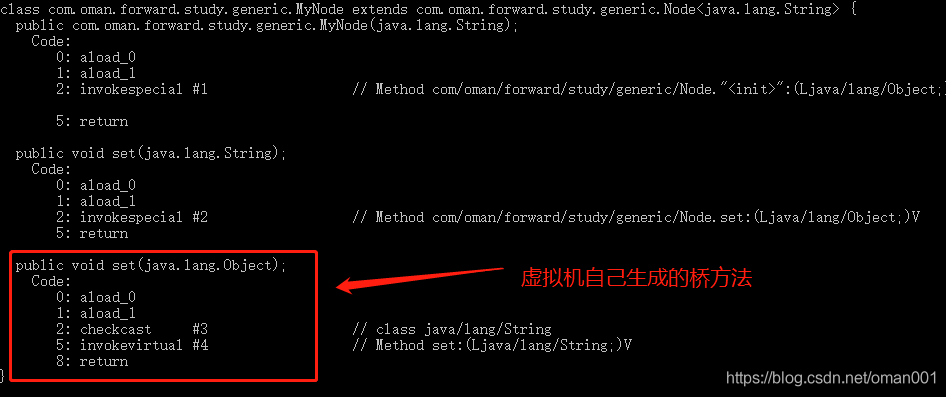
15. Java泛型的原理?什么是泛型擦除机制?
16. Java编译器具体是如何擦除泛型的
17. Array数组中可以用泛型吗?
18. PESC原则&限定通配符和非限定通配符
19. Java中List<?>和List<Object>的区别
20. for循环和forEach效率问题
package for循环效率问题;
import java.util.ArrayList;
public class Test {
public static void main(String[] args) {
ArrayList<Integer> arrayList = new ArrayList<>();
for (int i = 0; i < 10000000; i++) {
arrayList.add(i);
}
int x = 0;
//for循环遍历
long forStart = System.currentTimeMillis();
for (int i = 0; i < arrayList.size(); i++) {
x = arrayList.get(i);
}
long forEnd = System.currentTimeMillis();
System.out.println("for循环耗时" + (forEnd - forStart) + "ms");
//for-each遍历
long forEachStart = System.currentTimeMillis();
for (int i : arrayList) {
x = i;
}
long forEachEnd = System.currentTimeMillis();
System.out.println("foreach耗时" + (forEachEnd - forEachStart) + "ms");
}
}

package for循环效率问题;
import java.util.ArrayList;
import java.util.Iterator;
public class Test {
public Test() {
}
public static void main(String[] args) {
ArrayList<Integer> arrayList = new ArrayList();
int x;
for(x = 0; x < 10000000; ++x) {
arrayList.add(x);
}
int x = false;
long forStart = System.currentTimeMillis();
for(int i = 0; i < arrayList.size(); ++i) {
x = (Integer)arrayList.get(i);
}
long forEnd = System.currentTimeMillis();
System.out.println("for循环耗时" + (forEnd - forStart) + "ms");
long forEachStart = System.currentTimeMillis();
int i;
for(Iterator var9 = arrayList.iterator();
var9.hasNext();
i = (Integer)var9.next()) {
}
long forEachEnd = System.currentTimeMillis();
System.out.println("foreach耗时" + (forEachEnd - forEachStart) + "ms");
}
}
package for循环效率问题;
import java.util.LinkedList;
public class Test2 {
public static void main(String[] args) {
LinkedList<Integer> linkedList = new LinkedList<>();
for (int i = 0; i < 10000; i++) {
linkedList.add(i);
}
int x = 0;
//for循环遍历
long forStart = System.currentTimeMillis();
for (int i = 0; i < linkedList.size(); i++) {
x = linkedList.get(i);
}
long forEnd = System.currentTimeMillis();
System.out.println("for循环耗时" + (forEnd - forStart) + "ms");
//for-each遍历
long forEachStart = System.currentTimeMillis();
for (int i : linkedList) {
x = i;
}
long forEachEnd = System.currentTimeMillis();
System.out.println("foreach耗时" + (forEachEnd - forEachStart) + "ms");
}
}

Source code recreated from a .class file by IntelliJ IDEA// (powered by Fernflower decompiler)//
package for循环效率问题;
import java.util.Iterator;
import java.util.LinkedList;
public class Test2 {
public Test2() {
}
public static void main(String[] args) {
LinkedList<Integer> linkedList = new LinkedList();
int x;
for (x = 0; x < 10000; ++x) {
linkedList.add(x);
}
int x = false;
long forStart = System.currentTimeMillis();
for (int i = 0; i < linkedList.size(); ++i) {
x = (Integer) linkedList.get(i);
}
long forEnd = System.currentTimeMillis();
System.out.println("for循环耗时" + (forEnd - forStart) + "ms");
long forEachStart = System.currentTimeMillis();
int i;
for (Iterator var9 = linkedList.iterator(); var9.hasNext(); i = (Integer) var9.next()) {
}
long forEachEnd = System.currentTimeMillis();
System.out.println("foreach耗时" + (forEachEnd - forEachStart) + "ms");
}
}
# 单链表b[3]
- 用for循环,从a[0]开始读元素、然后通过a[0]的next读到a[1]元素、通过a[0]的next的next读到a[2]元素,以此类推,性能影响较大,慎用!
- 用foreach,得到a[0]-a[2]的全部地址放入队列,按顺序取出队里里的地址来访问元素;
16. NIO、BIO、AIO
17. 什么是反射
18. 序列化&反序列化
private static final long serialVersionUID = 1L;
private static final long serialVersionUID = 4603642343377807741L;
19. 动态代理是什么?有哪些应用?
20. 怎么实现动态代理
package demo3;
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Method;
import java.lang.reflect.Proxy;
public class ProxyInvocationHandler implements InvocationHandler {
//定义真实角色
private Rent host;
//真实角色set方法
public void setHost(Rent host) {
this.host = host;
}
/**
生成代理类方法
1. 类加载器,为当前类即可
2. 代理类实现的接口
3. 处理器接口对象
**/
public Object getProxy() {
return Proxy.newProxyInstance(this.getClass().getClassLoader(),
host.getClass().getInterfaces(), this);
}
//处理代理实例,并返回结果
//方法在此调用
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
//调用真实角色方法,相当于调用rent()方法
Object result = method.invoke(host, args);
//附加方法
seeHouse();
contract();
fare();
return result;
}
//看房
public void seeHouse() {
System.out.println("中介带你看房");
}
//签合同
public void contract() {
System.out.println("租赁合同");
}
//收中介费
public void fare() {
System.out.println("收中介费");
}
}
package demo3;
public class Client {
public static void main(String[] args) {
//真实角色:房东
Host host = new Host();
//处理器接口对象
ProxyInvocationHandler handler = new ProxyInvocationHandler();
//设置要代理的真实角色
handler.setHost(host);
//动态生成代理类
Rent proxy = (Rent) handler.getProxy();
//调用方法
proxy.rent();
}
}
21. 如何实现对象克隆?
protected Object clone() throws CloneNotSupportedException {
test_paper paper = (test_paper) super.clone();
paper.date = (Date) date.clone();
return paper;
}import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.util.Date;
@SuppressWarnings("all")
public class Client {
public static void main(String[] args) throws Exception {
Date date = new Date();
String name = "zsr";
test_paper paper1 = new test_paper(name, date);
//通过序列化和反序列化来实现深克隆
ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream obs = new ObjectOutputStream(bos);
obs.writeObject(paper1);
byte a[] = bos.toByteArray();
ObjectInputStream ois = new ObjectInputStream(new ByteArrayInputStream(a));
test_paper paper3 = (test_paper) ois.readObject();//获取到新对象
paper3.getDate().setDate(1000);//改变非基本类型属性
System.out.println(paper1);
System.out.println(paper3);
}
}


评论
小象面经|京东暑期实习风控产品岗面经来啦!
京东一面FIRST ROUND1. 自我介绍。2. 为什么要转专业?3. 转专业的时候是怎么想的?4. 介绍一下自己在律所的主要工作?前面的繁杂性的工作对后面有没有帮助?5. 有没有觉得自己有什么闪闪发光的时刻?6. 在学习...
环游世界的荷兰豆
0