
2021 最新视频防抖论文+开源代码汇总
点击上方“AI算法与图像处理”,选择加"星标"或“置顶”
重磅干货,第一时间送达
大家好,今天给大家分享,今年三篇关于视频防抖的文章,这三篇文章分布采用了不同的方法来解决视频抖动的问题。
1、基于深度的三维视频稳定学习方法Deep3D稳定器
2、融合运动传感器数据和光流,实现在线视频稳定
3、融合视频中多个相邻帧的信息,来呈现无需裁剪的完整稳定视频
3D Video Stabilization with Depth Estimation by CNN-based Optimization (CVPR 2021)
论文:https://drive.google.com/file/d/1vTalKtMz2VEowUg0Cb7nW3pzQhUWDCLA/view?usp=sharing
项目:https://yaochih.github.io/deep3d-stabilizer.io/
视频效果
摘要:
基于CNN优化的深度估计三维视频稳定我们提出了一种新的基于深度的三维视频稳定学习方法Deep3D稳定器。我们的方法不需要预训练数据,而是直接通过三维重建来稳定输入视频。校正阶段结合三维场景深度和摄像机运动,平滑摄像机轨迹,合成稳定的视频。与大多数基于学习的方法不同,我们的平滑算法允许用户有效地操纵视频的稳定性。
主要贡献包括:
我们介绍了第一种基于3D的深层CNN视频稳定方法,无需训练数据。
我们的方法可以利用3D运动模型更恰当地处理视差效应。
我们的稳定解决方案允许用户实时操纵视频的稳定性(34.5 fps)。
框架图:
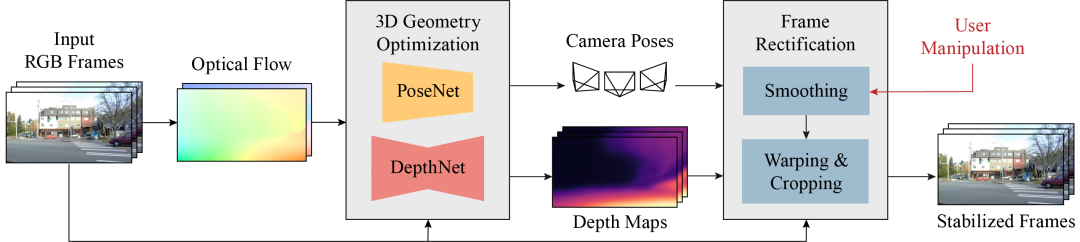
推荐方法的pipeline:pipeline由两个阶段组成。首先,三维几何优化阶段通过测试时训练,分别用PoseNet和DepthNet估计输入RGB序列的三维摄像机轨迹和稠密场景深度。优化阶段以输入序列和相应的光流作为学习3D场景的引导信号。其次,视频帧校正阶段以估计的摄像机轨迹和场景深度作为输入,在平滑后的轨迹上进行视点合成。平滑过程使用户可以通过操纵平滑滤波器的参数来获得不同程度的稳定度,然后对得到的视频进行包装和裁剪,得到稳定的视频。
Deep Online Fused Video Stabilization
论文:https://arxiv.org/pdf/2102.01279.pdf
项目:https://zhmeishi.github.io/dvs/
摘要:
提出了一种利用传感器数据(陀螺仪)和图像内容(光流)通过无监督学习来稳定视频的深度神经网络(DNN)。该网络将光流与真实/虚拟摄像机姿态历史融合成关节运动表示。接下来,LSTM块推断出新的虚拟相机姿势,并使用该虚拟姿势生成一个扭曲网格,以稳定帧。提出了一种新的相对运动表示方法和多阶段的训练过程来优化模型。据我们所知,这是第一个DNN解决方案,采用传感器数据和图像稳定。我们通过烧蚀研究验证了所提出的框架,并通过定量评估和用户研究证明了所提出的方法优于现有的替代解决方案。
本文的贡献如下:
第一个基于DNN的框架,融合运动传感器数据和光流,实现在线视频稳定。
具有多阶段训练和相对运动表示的无监督学习过程。
基准数据集,包含陀螺仪和OIS传感器数据的视频,涵盖各种场景。数据集和代码都将公开发布。
框架图:
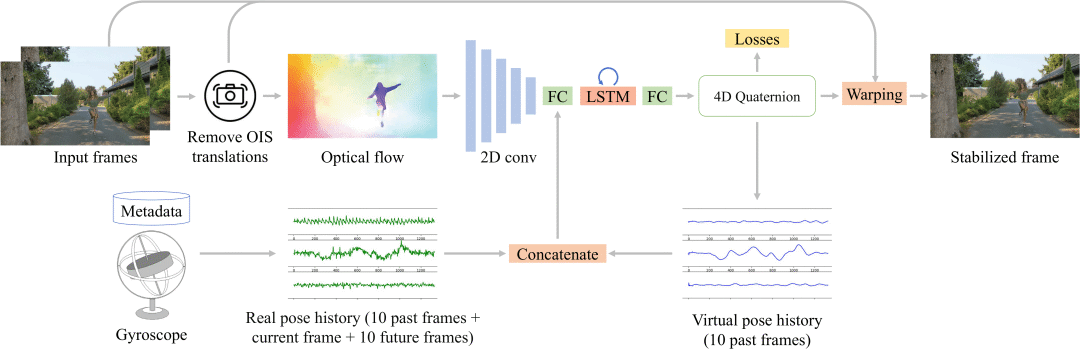
deep-FVS概述。在给定输入视频的情况下,我们首先去除了OIS转换,提取原始光流。我们还从陀螺仪获得真实的相机姿态,并将其转换为相对四元数。一个二维卷积编码器将光流嵌入到一个潜在的表示,然后将其与真实和虚拟摄像机的姿态连接起来。该关节运动表示被馈送到LSTM单元和FC层,以预测新的虚拟相机姿态为四元数。最后,基于OIS和虚拟摄像机姿态对输入帧进行扭曲,生成稳定帧
Hybrid Neural Fusion for Full-frame Video Stabilization
论文:https://arxiv.org/pdf/2102.06205.pdf
项目:https://github.com/alex04072000/FuSta
之前分享过,感兴趣的可以点击下面的链接查看
AI防抖,稳如老狗?台湾大学和谷歌提出NeRViS:无需裁剪的全帧视频稳定算法

该方法的核心思想,是融合视频中多个相邻帧的信息,来呈现无需裁剪的完整稳定视频。
具体而言,对于输入视频,首先对每一帧图像特征进行编码,并在目标时间戳处将相邻帧翘曲至虚拟相机空间。
这里面主要用到了目标帧到关键帧的翘曲场,以及从关键帧到相邻帧的估计光流两个信息,这样,就可以通过链接流向量,计算目标帧到相邻帧的翘曲场。
然后,融合这些特征。
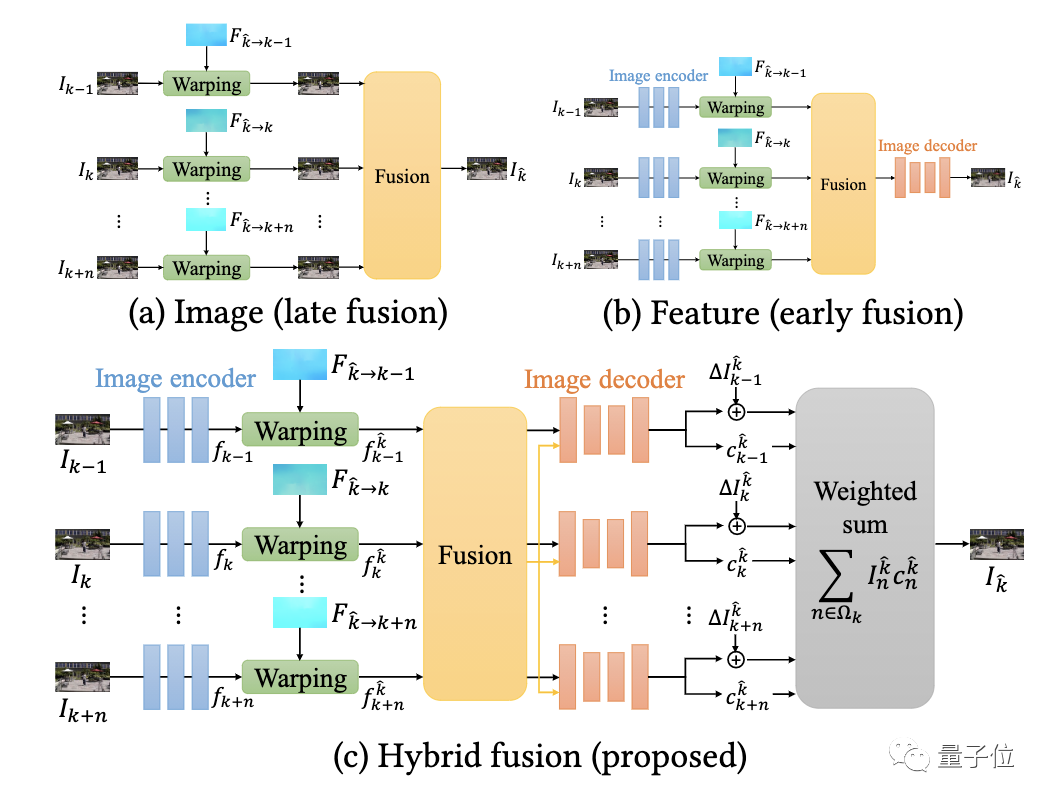
传统的全景图像拼接算法通常是在图像级别进行融合。这样做的缺点在于,如果估计光流不可靠,就会产生伪影。
而将图像编码为CNN特征,再在特征空间中进行融合的方法更具鲁棒性,但又往往会产生过于模糊的图像(如下图b)。
于是,研究人员提出结合两种策略的优点:首先将图像编码为CNN特征,然后从多个帧中融合翘曲特征。
对于每个源帧,研究人员将融合特征图和各个翘曲特征一起,解码成输出帧和相关的置信度图。
最后,通过使用生成图像的加权平均,来产生最终的输出帧。

好的,今天的分享就到这里,如果喜欢记得关注我,给我一个三连,感谢

个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2021 在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文
点亮  ,告诉大家你也在看
,告诉大家你也在看