 浪尖聊大数据
浪尖聊大数据




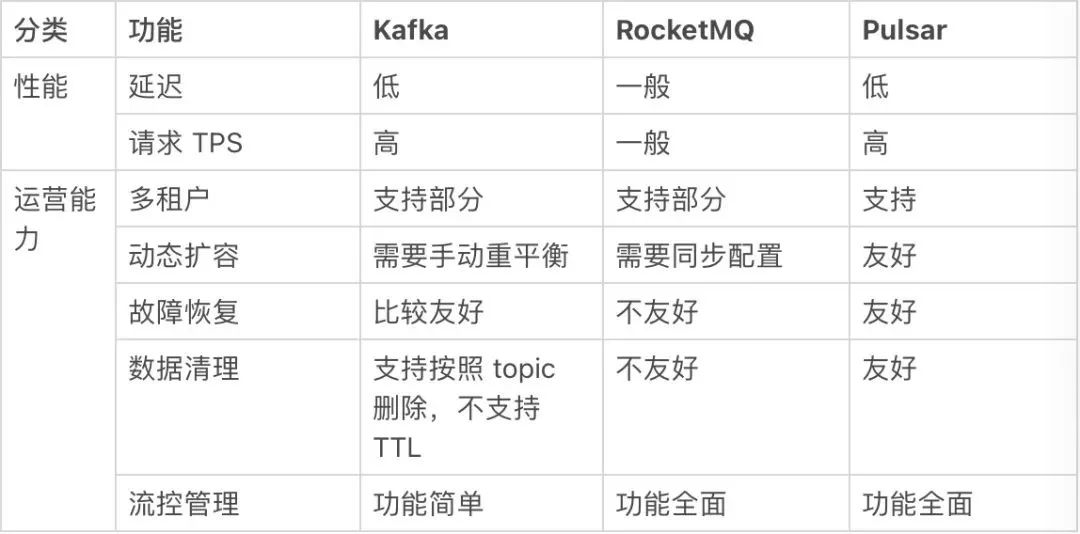
功能需求

为什么选择 Apache Pulsar
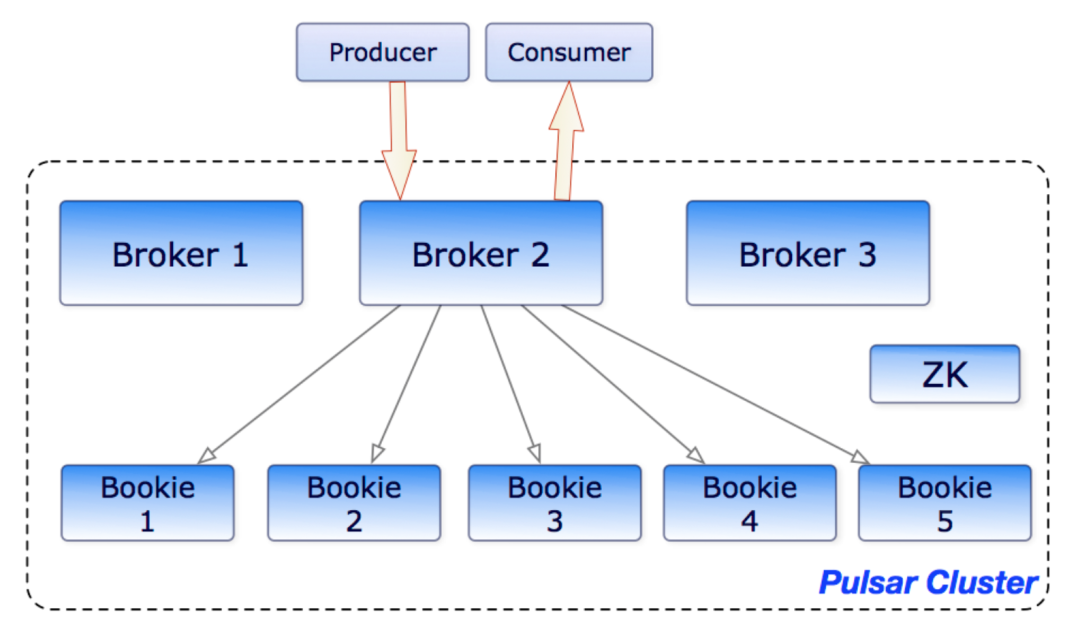
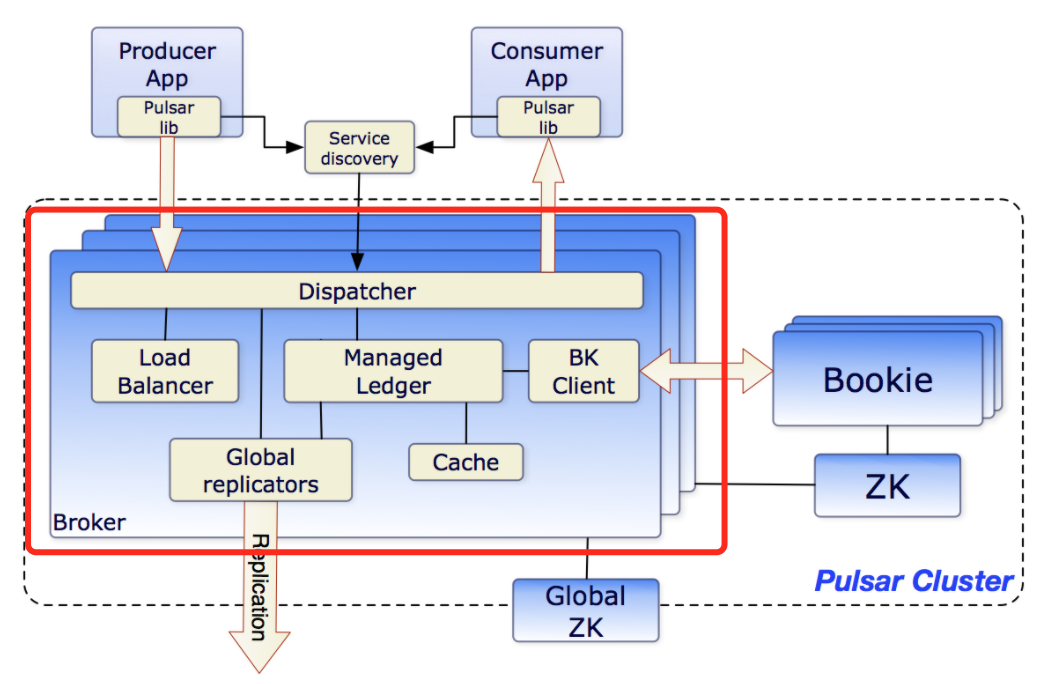
Dispatcher:调度分发模块,承担协议转换、序列化反序列化等。 Load balancer:负载均衡模块,对访问流量进行控制管理。 Global replicator:跨集群复制模块,承担异步的跨集群消息同步功能。 Service discovery:服务发现模块,为每个 topic 选择无状态的主节点。
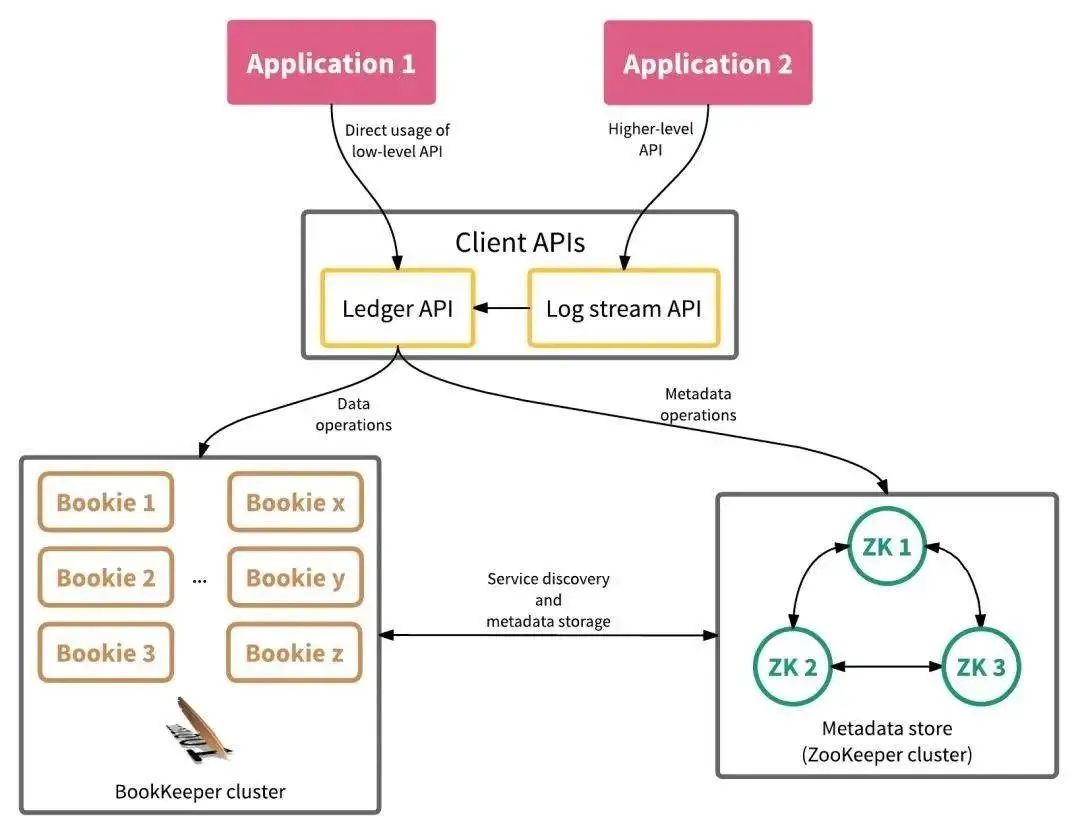
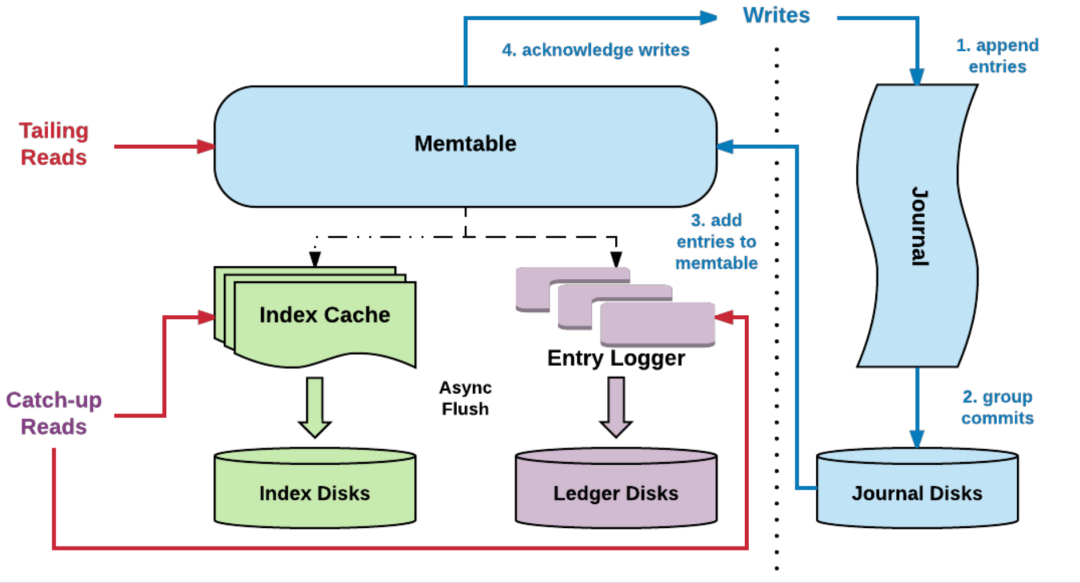
IO 隔离:写入、追尾读和追赶读隔离。 利用网络流入带宽和磁盘顺序写入的特性实现高吞吐写:传统磁盘在顺序写入时,带宽很高,零散读写导致磁盘带宽降低,采取顺序写入方式可以提升性能。 利用网络流出带宽和多个磁盘共同提供的 IOPS 处理能力实现高吞吐读:收到数据后,写到性能较好的 SSD 盘里,进行一级缓存,然后再使用异步线程,将数据写入到传统的 HDD 硬盘中,降低存储成本。 利用各级缓存机制实现低延迟投递:生产者发送消息时,将消息写入 broker 缓存中;实时消费时(追尾读),首先从 broker 缓存中读取数据,避免从持久层 bookie 中读取,从而降低投递延迟。读取历史消息(追赶读)场景中,bookie 会将磁盘消息读入 bookie 读缓存中,从而避免每次都读取磁盘数据,降低读取延时。
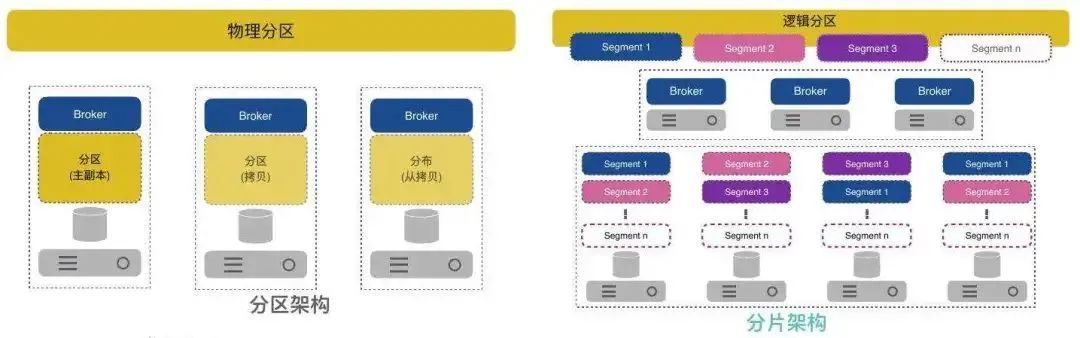
对比总结

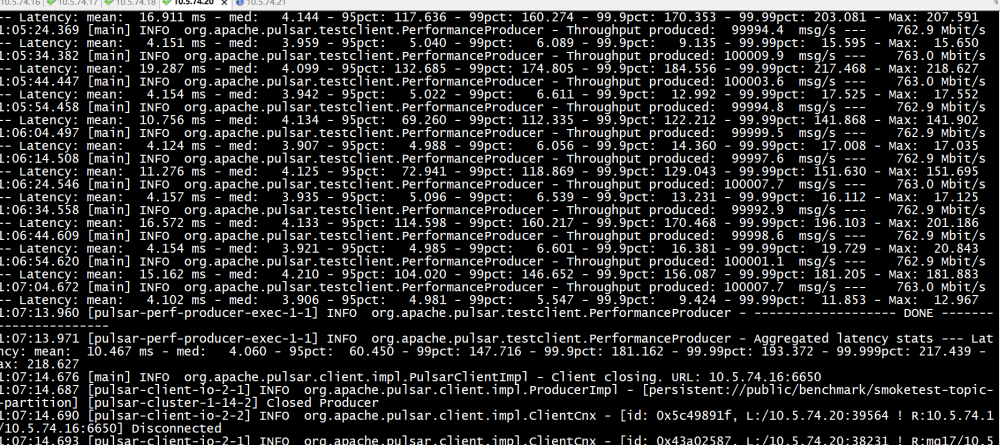
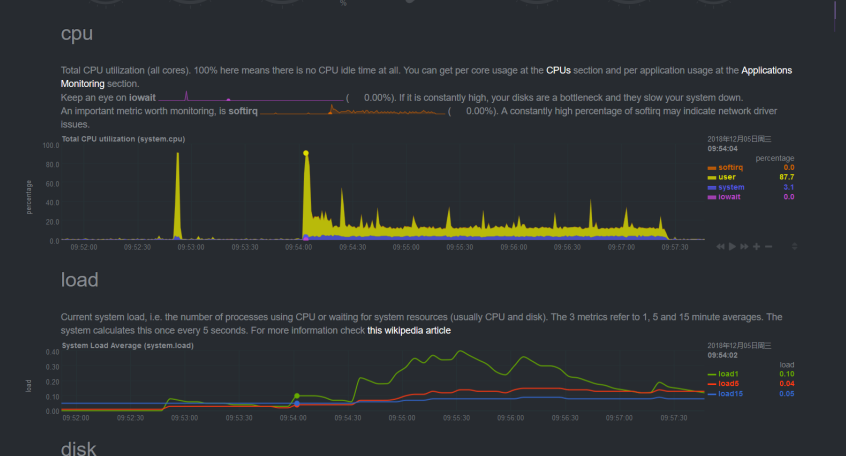
部署方式:混合部署优于分开部署。broker 和 bookie 可以部署在同一个节点上,也可以分开部署。节点数量较多时,分开部署较好;节点数量较少或对性能要求较高时,将二者部署在同一个节点上较好,可以节省网络带宽,降低延迟。 负载大小:随着测试负载的增大,tps 降低,吞吐量稳定。 刷盘方式:异步刷盘优于同步刷盘。 压缩算法:压缩算法推荐使用 LZ4 方式。我们分别测试了 Pulsar 自带的几种压缩方式,使用 LZ4 压缩算法时,CPU 使用率最低。使用压缩算法可以降低网络带宽使用率,压缩比率为 82%。 分区数量:如果单 topic 未达到单节点物理资源上限,建议使用单分区;由于 Pulsar 存储未与分区耦合,可以根据业务发展情况,随时调整分区数量。 主题数量:压测过程中,增加 topic 数量,性能不受影响。 资源约束:如果网络带宽为千兆,网络会成为性能瓶颈,网络 IO 可以达到 880 MB/s;在网络带宽为万兆时,磁盘会成为瓶颈,磁盘 IO 使用率为 85% 左右。 内存与线程:如果使用物理主机,需注意内存与线程数目的比例。默认配置参数为 IO 线程数等于 CPU 核数的 2 倍。这种情况下,实体机核数为 48 核,如果内存设置得较小,比较容易出现 OOM 的问题。
所有测试场景中,没有出现消息丢失与消息乱序; 开启消息去重的场景中,没有出现消息重复。
Pulsar 在基础消息平台的实践
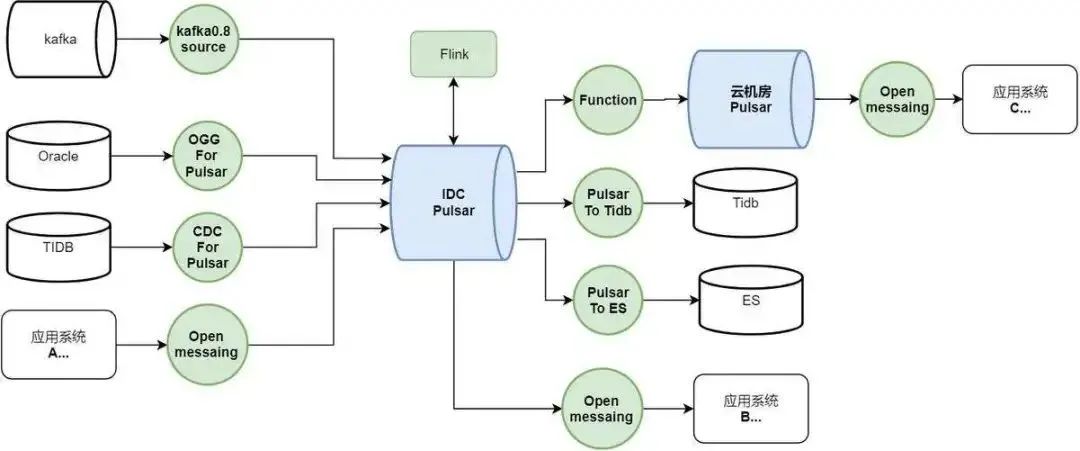
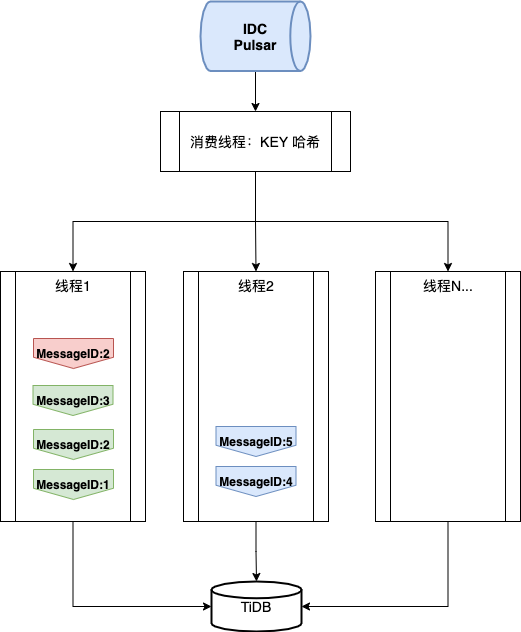
场景 1:流式队列

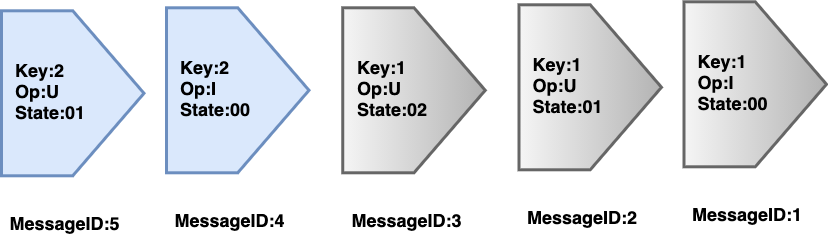
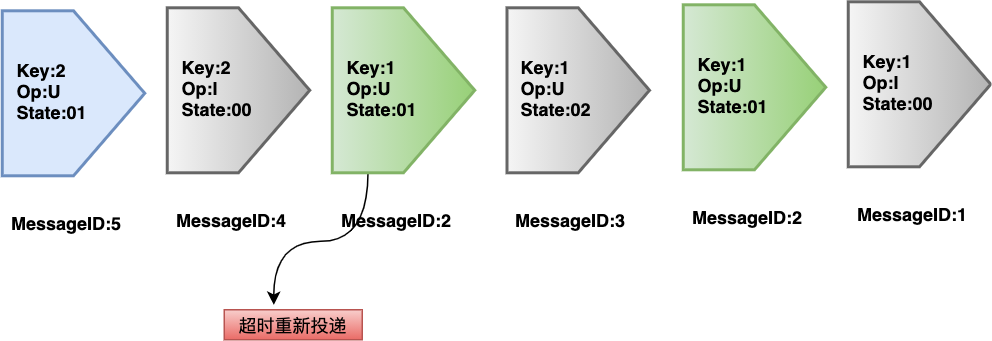
使用灾备订阅方式,消费 Pulsar 消息。 根据消息的 key 进行哈希运算,将相同的 key 散列到同一持久化线程中。 启用 Pulsar 的消息去重功能,避免消息重复投递。假设 MessageID2 重复投递,那么数据一致性将被破坏。
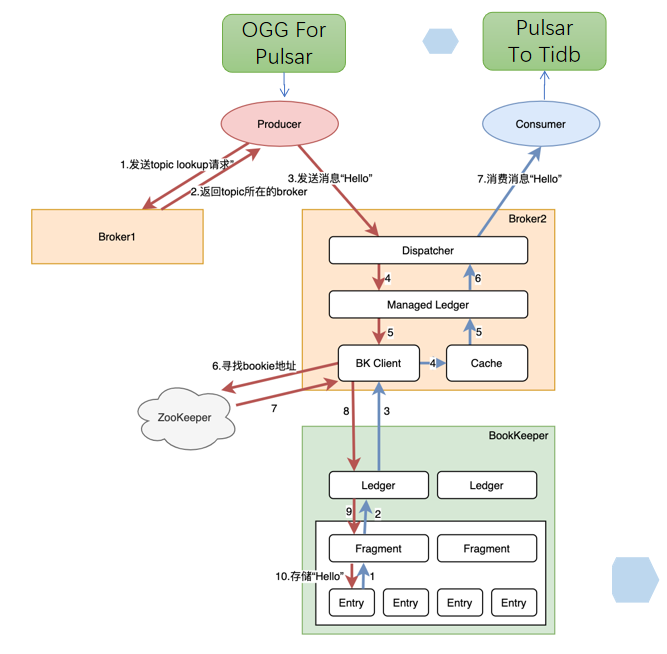
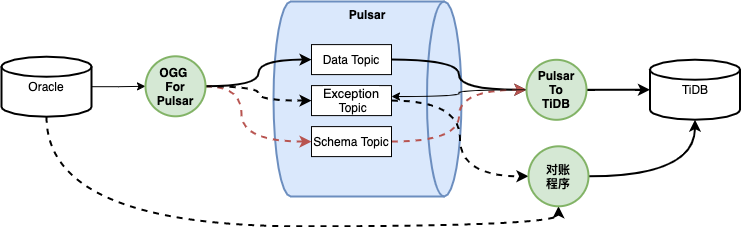
OGG For Pulsar 组件调用 Pulsar 客户端的 producer 接口,投递消息。 Pulsar 客户端根据配置文件中的 broker 地址列表,获取其中一个 broker 的地址,然后发送 topic 归属查询服务,获取服务该 topic 的 broker 地址(下图示例中为 broker2)。 Pulsar 客户端将消息投递给 Broker2。 Broker2 调用 BookKeeper 的客户端做持久化存储,存储策略包括本次存储可选择的 bookie 总数、副本数、成功存储确认回复数。
在 namespace 级别开启去重功能:bin/pulsar-admin namespaces set-deduplication namespace --enable
修复 / 优化 Pulsar 客户端死锁问题。2.7.1 版本已修复,详细信息可参考 PR 9552。
pulsar.producer.batchingEnabled=false
pulsar.producer.blocklfQueueFull=true
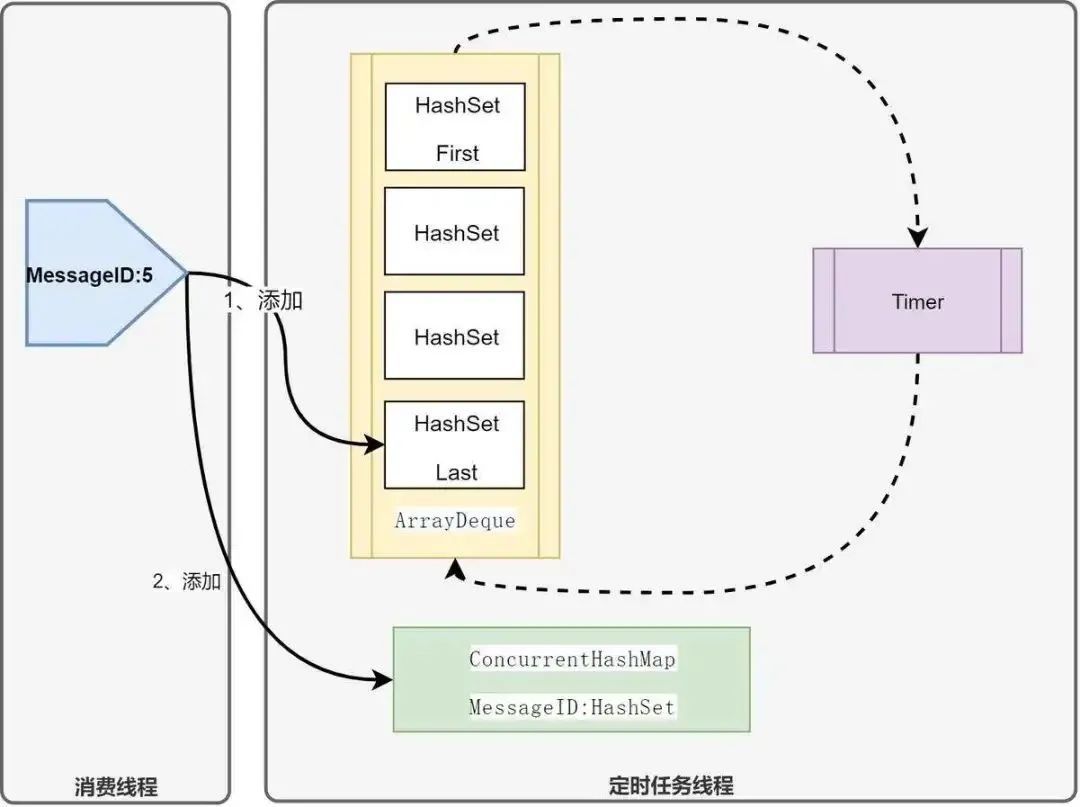
实现拦截器:ConsumerInterceptorlmpl implements ConsumerInterceptor 配置确认超时:pulsarClient.ackTimeout(3000, TimeUnit.MILLISECONDS).ackTimeoutTickTime(500, TimeUnit.MILLISECONDS) 使用累积确认:consumer.acknowledgeCumulative(sendMessageID)
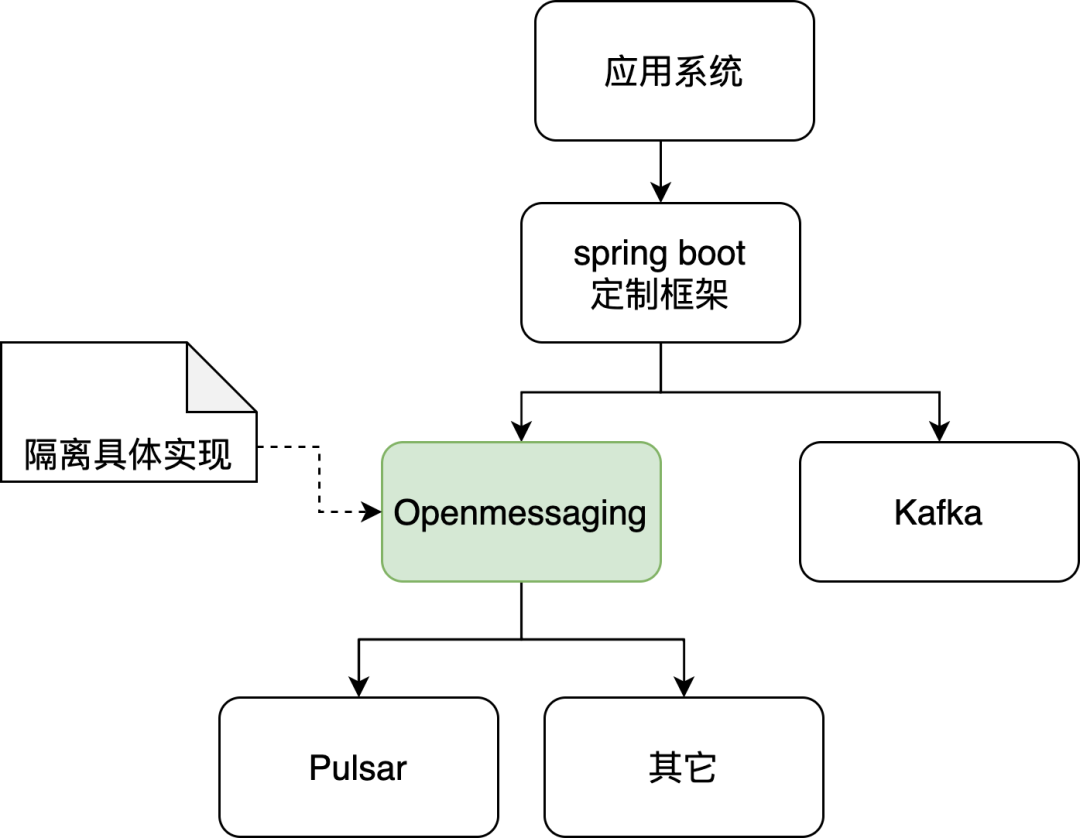
场景 2:消息队列:OpenMessaging 协议实现(透明层协议)
通过 Pulsar 实现 OpenMessaging 协议。 开发框架(基于 spring boot)调用 OpenMessaging 协议接口,发送和接收消息。
场景 3:流式队列:自定义 Kafka 0.8-Source(Source 开发)

场景 4:流式队列:Function 消息过滤(消息过滤)

场景 5:流式队列:Pulsar Flink Connector 流式计算(流式计算)
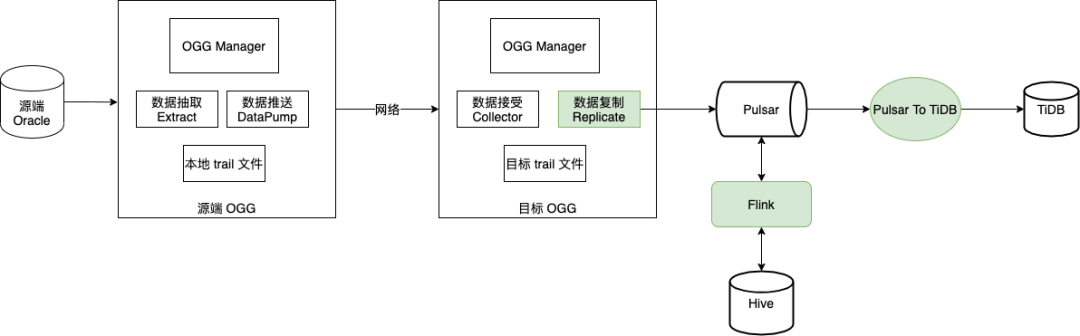
场景 6:流式队列:TiDB CDC 适配(TiDB 适配)

未来规划
陆续下线其它消息系统,最终全部接入到 Pulsar 基础消息平台; 深度使用 Pulsar 的资源隔离和流控机制。


