 极市平台
极市平台





极市导读
本文为详细解读Vision Transformer的第十一篇,本文介绍了两个视觉Transformer在图像质量评价 (Image Quality Assessment) 中应用的工作:IQT、TRIP。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
本文目录
1.IQT:基于 Transformer 的感知图像质量评价
(来自LG,NTIRE 2021冠军方案)
1.1 IQT原理分析2.Transformer+图像质量评价:TRIP
(来自NORCE Norwegian Research Centre,深圳大学)
2.1 TRIP原理分析
Transformer 是 Google 的团队在 2017 年提出的一种 NLP 经典模型,现在比较火热的 Bert 也是基于 Transformer。Transformer 模型使用了 Self-Attention 机制,不采用 RNN 的顺序结构,使得模型可以并行化训练,而且能够拥有全局信息。
本文介绍的两个工作是视觉Transformer在图像质量评价 (Image Quality Assessment) 中的应用。TRIP这个论文是第一个把Transformer用在IQA上的工作,而IQT这个论文是NTIRE 2021比赛 (对应CVPR Workshop 2021) IQA赛道的第1名,使用的也是视觉Transformer模型,它的思路值得拿出来单独讨论。
IQT:基于 Transformer 的感知图像质量评价 (CVPRW 2021)
论文名称:Perceptual Image Quality Assessment with Transformers
论文地址:
https://arxiv.org/pdf/2104.14730.pdf
1.1 IQT原理分析:
对于图像处理领域来讲,一个首要的目标是去提升处理后的图像的质量,而这个质量应该更符合人类的感知,即:如何去评判一个算法所得到的图像是好是坏?这不应该单单是靠着某个指标来决定的,而是应该依赖于人类的观感。 简而言之,这个图像处理算法 A 所得到的结果图片,只有人类看上去感觉更"好看",我们才说 A 是一个好算法。
那接下来得问题是:不能总是靠人来帮助我们构建好的算法,因为人力资源是很昂贵的,因此我们就需要 图像质量评价 (IQA)算法。
我们希望:一个好的图像质量评价 (IQA) 算法,它可以像人一样给出这个结果图是好是坏。 对于一张结果图来说,人感觉它又美又好看,我们的IQA算法就应该给它高分;人感觉它又丑又难看,我们的IQA算法就应该给它低分。这两段话概括得专业一点就是:
One of the goals of the image processing is to improve the quality of the content to an acceptable level for the human viewers.
举个例子,我们常用GAN网络来做一些Image Restoration的任务,那么GAN模型的一个优势是它得到的这些图片尽管一些常用的指标 (PSNR, SSIM) 上不占优势,但是却更"好看",或者说更符合人的主观感受。但是GAN模型生成的图片也会产生一些不现实的伪影 (unrealistic artifacts)。但总而言之,它得到的这些图片给人的感受是更"好看"的。这就说明了一个问题,即:一些经典而常用的指标 (如 PSNR, SSIM 等) 其实是不足以准确评价一幅图片的好坏的。
所以本文给出的模型 IQT 就是一个基于CNN和Transformer的,能够评判GAN生成的图像是好是坏的IQA模型,它的特点是:
为数不多的基于Transformer的IQA模型。 侧重于Perceptual Image Quality Assessment,即:模型的输出结果更接近人类的感知结果。 获得了NTIRE 2021 IQA赛道的1st Place。
1.1.1 常见的IQA算法
讲到这里我们先简单地认识一下 IQA 任务和它的一些指标。常见的IQA算法可以分为3种:
全参考IQA:Full-Reference IQA
输入有2张图: 一张是要评价的图,它可能是某个图像复原GAN模型生成的图片等等,我们叫它失真图;另一张是真值,它是这张图片对应的Ground Truth,比如在图像复原任务中就是对应的清晰的图片,我们叫它参考图。在FR问题中,除了给出失真图像,还给出了无失真的参考图像,难度较低,核心是对比两幅图像的信息量或特征相似度,是研究比较成熟的方向。
半参考IQA:Reduced-Reference IQA
输入有1张图: 就是要评价的图,它可能是某个图像复原GAN模型生成的图片等等,我们叫它失真图。 在RR问题中给出了失真图像,没有参考图像,但是给了参考图像的部分信息。比如只有原始图像的部分信息或从参考图像中提取的部分特征,此类方法介于FR-IQA和NR-IQA之间,且任何FR-IQA和NR-IQA方法经过适当加工都可以转换成RR-IQA方法。进一步,NR-IQA类算法还可以细分成两类,一类研究特定类型的图像质量,比如估计模糊、块效应、噪声的严重程度,另一类估计非特定类型的图像质量,也就是一个通用的失真评估。一般在实际应用中无法提供参考图像,所以NR-IQA最有实用价值,也有着广泛的应用,使用起来也非常方便,同时,由于图像内容的千变万化并且无参考,也使得NR-IQA成为较难的研究对象。
无参考IQA:No-Reference IQA
输入有1张图: 就是要评价的图,它可能是某个图像复原GAN模型生成的图片等等,我们叫它失真图。 在NR问题中仅给出了失真图像。NR是最难的图像质量评价方法,是近些年的研究热点,也是IQA中最有挑战的问题。
1.1.2 常见的IQA数据集
具有广泛认可的IQA数据集有:LIVE,TID2008,TID2013,CSIQ,IVC 和 Toyama。给定这些数据集,然后就可以计算人类平均主观评分和客观IQA模型预测值之间的差异和相关性, 更高的相关性表明更好的模型性能。
1.1.3 常见的IQA指标
衡量图像质量评估结果的指标有很多,每种指标都有自己的特点,通常比较模型客观值与观测的主观值之间的差异和相关性。常见的2种评估指标是Spearman秩相关系数 (Spearman's Rank Order Correlation Coefficient, SROCC) 和线性相关系数 (Linear Correlation Coefficient, LCC) 。LCC也叫Pearson相关系数 (PLCC) ,描述了主、客观评估之间的线性相关性,定义如下:
其中 表示失真图像数, 、 分别表示第 幅图像真实值和测试分数, 、 分别表示真实平均值和预测平均值。
PLCC衡量的其实是 和 这两个向量之间的相似性。这两个向量越相似则PLCC的值越接近1,代表人类平均主观评分和客观IQA模型预测值之间的相关性越高,即我们的IQA模型越好。
SROCC衡量算法预测的单调性,计算公式为:
其中 、 分别表示 、 在真实值和预测值序列中的排序位置。
这个指标我们可以这样来理解:假设现在有 张图片,IQA算法为它们打分,排名分别是 。而与此同时人类也为它们来打分,排名分别是 。
假设现在如果这个IQA算法很完美,则IQA算法的排名应该是与真人的排名一致,即有:
此时带入公式计算得SROCC=1。
假设现在如果这个IQA算法很差劲,则IQA算法的排名应该是与真人的排名刚好完全相反,即人类认为好的图片,IQA算法认为很差,即有:
此时带入公式计算得SROCC=-1。
你可能有疑问了这个-1是咋算出来的,接下来我推导一波,会的童鞋请自觉跳过。
推导:
此时的
初中时候学过公式:
所以有:
将25.3代入25.4有:
再代入 有:
所以 。
除此之外,还有Kendall秩相关系数(Kendall Rank Order Correlation Coefficient, KROCC),均方根误差(Root Mean Square Error, RMSE)等评估指标。KROCC的性质和SROCC一样,也衡量了算法预测的单调性。RMSE计算MOS与算法预测值之间的绝对误差,衡量算法预测的准确性。
1.1.4 IQT具体方法
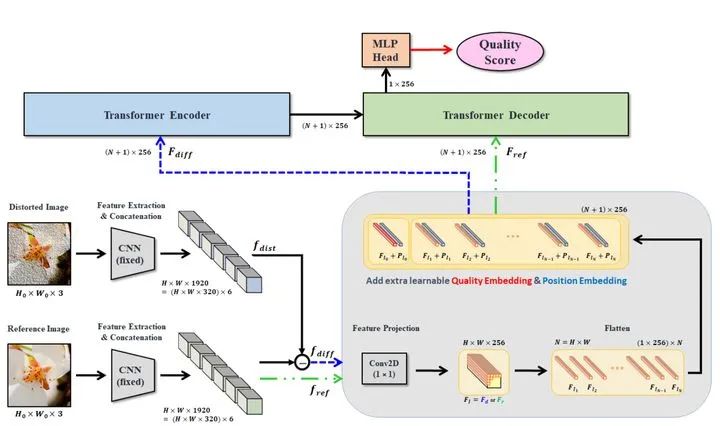
IQT的做法如上图1所示,主要由3部分构成:1个特征提取的backbone,1个Transformer的Encoder-Decoder,和一个预测头 Prediction head。
1 特征提取的backbone
特征提取的backbone使用了CNN,作者首先把失真图 (Distorted Image) 和参考图 (Reference Image) 都通过了CNN的backbone提取它们的特征,得到一个固定长度的特征向量。具体使用的backbone是Inception-Resnet-V2,权重是继承ImageNet的Pretrained weights并固定。使用的特征来自:mixed_5b,block35_2,block35_4,block35_6,block35_8,block35_10。这些特征都有相同的shape: ,把它们在channel的维度上concatenate在一起得到最后的提取特征: 。
把失真图得到的特征向量取名为 ,参考图得到的特征向量取名为 。接下来要输入给Transformer的是两个特征,其一是参考图的特征向量 ,其二是二者的差值 。
2 Transformer的Encoder
根据上面的描述,Transformer的Encoder输入的是 这个 的张量。
把它们提供1×1卷积,将channel变成Transformer的Embedding dimension ,再把它使用Flatten操作展平得到 的张量。同时,模仿ViT使用class token的做法,作者在这里也加了一个quality token,与输入张量concat在一起。这样输入张量的维度就变成了 。
对于位置编码而言,IQT没有使用ViT中的正弦位置编码,而使用了可学习的位置编码,其维度为: 。
所以Encoder的流程写成公式就是:
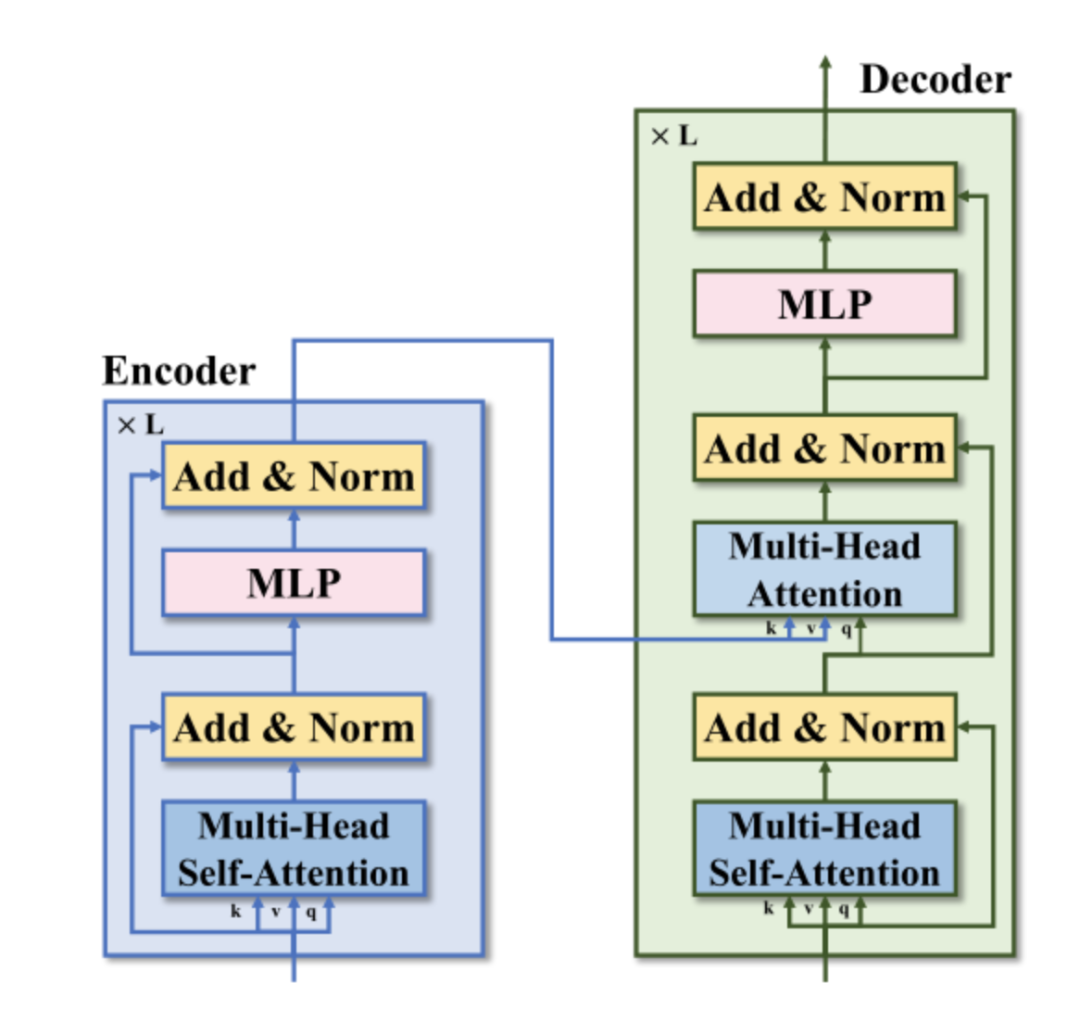
注意这里Layer Normalization的位置是在Add以后的,而不是先做LN,如下图2所示。再通过MHSA或者FFN。Encoder输出张量的维度是 。
3 Transformer的Decoder
与ViT不同的是作者还是用了Decoder的结构。Transformer的Decoder输入的是 这个 的张量。也是通过相同的Conv 1×1和Flatten操作变成了 的张量。同时,和Encoder里面的做法保持一致,作者在这里也加了一个quality token,与输入张量concat在一起。这样输入张量的维度就变成了 。同时,根据Decoder的性质,Encoder的输出张量 也会输入给Decoder的Multi-head Self-attention中的Key和Value。Decoder的流程写成公式就是:
注意这里Layer Normalization的位置是在Add以后的,而不是先做LN,再通过MHSA或者FFN。Decoder输出张量的维度是 。
4 预测头Prediction Head
最后一步是把Transformer Decoder的输出取出quality token对应的那一个patch的张量,其维度是 ,通过MLP层得到一个标量 (channel=1,代表这张失真图片的得分),这就是一个标准的回归问题。
Experiments:
数据集: LIVE Image Quality Assessment Database (LIVE),Categorical Subjective Image Quality (CSIQ),TID2013,KADID-10k,PIPAL
值得一提的是最后这个PIPAL数据集就是NTIRE 2021比赛中主办方给出的数据集,其中包含许多GAN生成的失真图像,其label就是人类给出的打分。现有的度量方法很难准确预测感知质量,下图3是这些数据集的特点:

超参数设置:
Transformer超参数:
| 参数 | 值 |
|---|---|
| Encoder层数 | 2 |
| Decoder层数 | 2 |
| head | 4 |
| Embedding dimension | 256 |
| MHSA中的MLP Expansion ratio | 4 |
| 预测头中的MLP Expansion ratio | 2 |
| 输入图片大小 | 256×256×3 |
| Patch数量N | 891 |
这里Patch设置的比较大,是因为作者将图片进行裁切 (crop),裁成了256×256×3的patch,patch之间是有重叠的。测试时随机选取M个patch得到的结果求加权和作为该图片的得分。
网络训练超参数:
| 参数 | 值 |
|---|---|
| 优化器 | Adam |
| 初始学习率 | 2×e-4 |
| 学习率衰减策略 | cosine learning rate decay |
| batch size | 16 |
| 损失函数 | MSE |
作者在KADID-10k数据集上训练模型并在LIVE,CSIQ,TID2013上进行测试,结果如下图4所示。
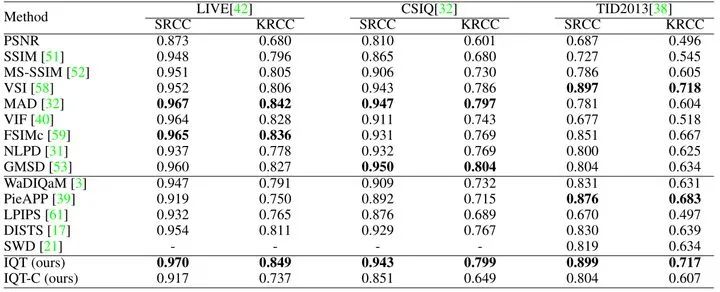
IQT的SROCC和KRCC指标的值是最有优势的。对于LIVE和TID2013数据集,作者提出的IQT在SROCC方面表现最佳。此外,在所有的测试中,IQT在SROCC和KRCC中都排名前三。
如下图5所示是一组图像,来自PIPAL validation dataset。其中最左侧的是真值,其它的是各种的失真图像。下面的一堆数字是使用各种IQA算法得到的结果,分别有:PSNR, SSIM, MS-SSIM, LPIPS, 和本文提出的 IQT。MOS代表平均主观得分(Mean opinion score, MOS) ,可以认为是人类的主观感受来打分,失真图从左至右MOS值越来越低,代表我们人类认为从左到右的图越来越丑。那么哪一个IQA算法更好,它的输出也应该是从左到右越来越差的。

结果发现, IQT预测的质量分数非常类似于MOS,表示在主观质量评价这一块,IQT方法是最好的。
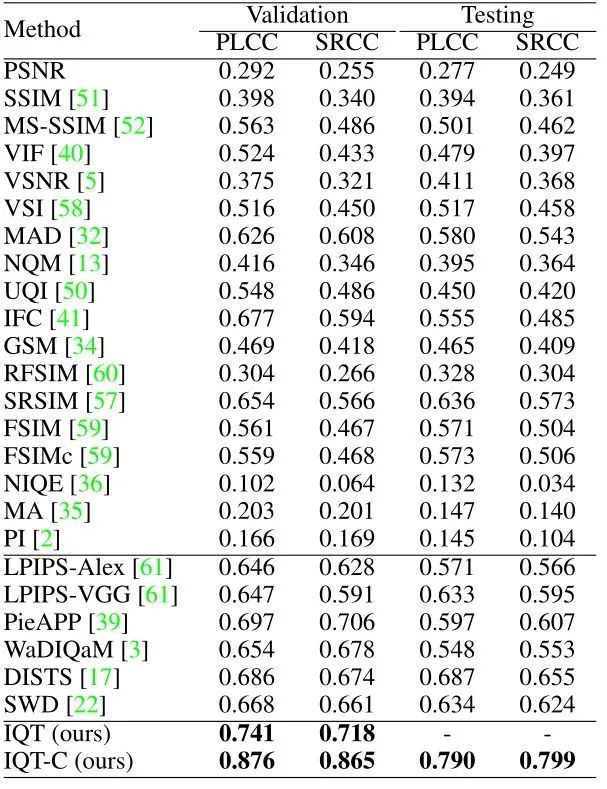
IQT模型在PIPAL上进行测试,再次强调IQT模型是在KADID-10k数据集上训练的,测试结果如下图6所示。结果表明,IQT方法在验证集和测试集的性能都是最优的。
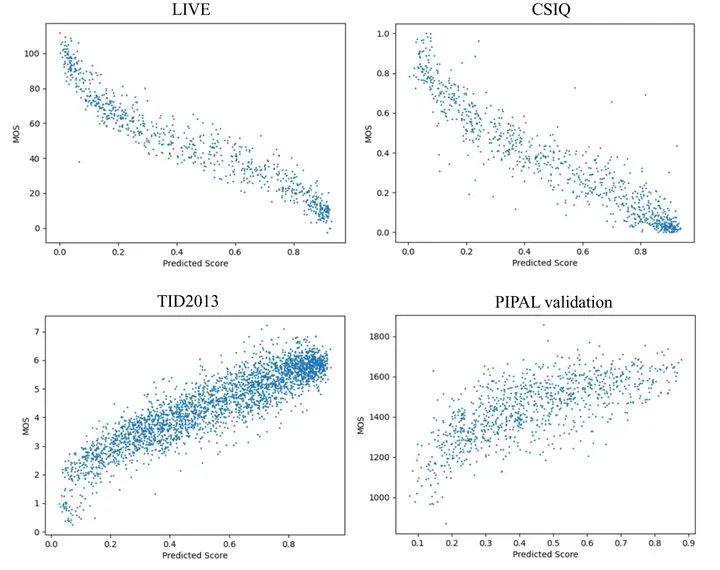
下图7所示是几个数据集上IQT预测得分和ground-truth MOS对应的散点图,我们可以看到在不同的数据集上IQT方法的预测结果和真值MOS相比都展现出了很强的相关关系,证明IQT是一种很不错的方法。
下图8为图5显示了IQT模型的attention map。可视化的方法是把不同层的attention map取平均,得到大小是 的attention map。再把第一行,即quality token对应的 个归一化权值resize成image的大小,作为输入图像的mask,与输入图像叠加在一起得到的结果。它指的是模型在预测感知质量时更关注的区域。结果显示,失真类型不同,注意力所在的区域也不同;而且,人类评价一个图片质量好坏时,看到整个图像很重要,然后也会集中在局部区域。而这个具体集中的位置可以由attention机制学习到。

IQT这个模型获得了NTIRE 2021 Perceptual IQA Challenge的冠军。对于这个比赛来讲,作者在NTIRE 2021 challenge提供的训练集上进行训练,采用了相同的模型结构以及训练和测试策略,超参数的设置如下:
Transformer超参数:
| 参数 | 值 |
|---|---|
| Encoder层数 | 1 |
| Decoder层数 | 1 |
| head | 4 |
| Embedding dimension | 128 |
| MHSA中的MLP Expansion ratio | 4 |
| 预测头中的MLP Expansion ratio | 1 |
| 输入图片大小 | 192×192×3 |
| Patch数量N | 441 |
作者将图片进行裁切 (crop),裁成了192×192×3的patch,patch之间是有重叠的。测试时随机选取M个patch得到的结果求加权和作为该图片的得分。
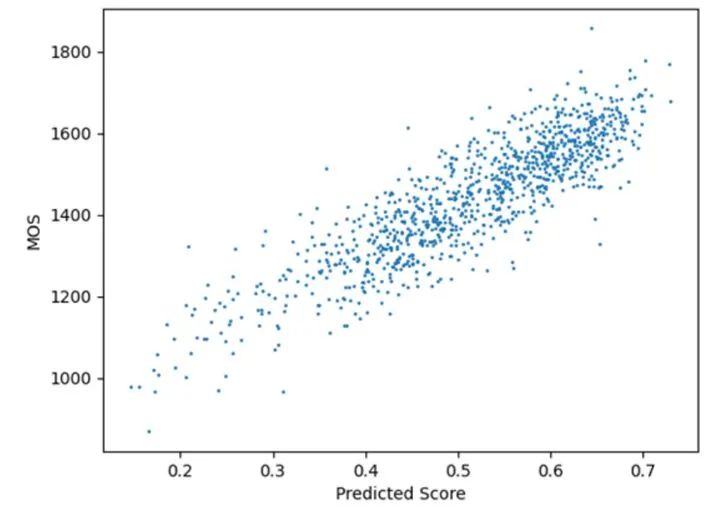
在PIPAL验证集上的散点图如下图9所示,可以发现模型的输出和真值MOS也具有极强的相关性。
NTIRE 2021 Perceptual IQA Challenge的冠军这个模型命名为IQT-C。但是,IQT-C是专门针对这个比赛而训练的,其在其他数据集LIVE,CSIQ,TID2013上的表现不如IQT (使用 KADID-10k数据集训练)。
小结:
本文给出2个模型:IQT和IQT-C,分别是在KADID-10k和PIPAL数据集上训练得到的,其中IQT-C是专门针对NTIRE 2021 challenge而训练的,二者结构相同但超参数设置上有差别。它们都是基于CNN和Transformer的,能够评判GAN生成的图像是好是坏的IQA模型,它的特点是一个为数不多的基于Transformer的IQA模型。而且侧重于Perceptual Image Quality Assessment,即:模型的输出结果更接近人类的感知结果。
Transformer+图像质量评价:TRIP
论文名称:Transformer for Image Quality Assessment
论文地址:
https://arxiv.org/ftp/arxiv/papers/2101/2101.01097.pdf
1 TRIP原理分析:
TRIP是第1个将Transformer应用于IQA任务的工作,其中的很多思想被后来的IQT得以借鉴。图像质量评估 (Image quality assessment, IQA) 实质上是一种识别任务,即识别图像的质量水平。作者第1个尝试研究如何在IQA任务中应用Transformer。现有的深度学习驱动的IQA模型主要基于CNN架构。一个典型的例子是使用CNN作为特征提取器,并在顶部的MLP来预测图像质量。与其他CV任务 (如目标检测或图像识别) 相比,IQA有一个特殊的特点:分辨率对图像质量有显著影响。 换句话说,图像质量可能会受到调整图像的大小的潜在影响,例如,降采样图像可能会降低其感知质量 (perceptual quality)。尽管图像 resize 的操作在深度学习模型中被广泛用于其他CV任务,但在IQA模型中应该避免。 一般情况下,Transformer可以接受不同长度的输入 (例如,包含不同数量单词的句子)。因此,还可以使Transformer编码器适应不同分辨率的图像,以构建通用的IQA模型。
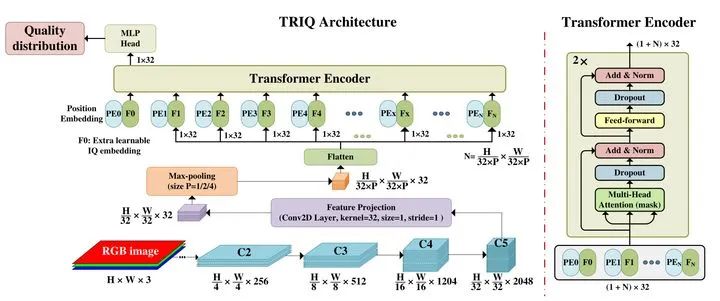
作为第1个将Transformer应用于IQA任务的工作,TRIP的结构简洁明了,如上图10所示。
首先通过ResNet-50作为特征提取器,那么ResNet-50的中间层C2-C5的输出维度大小依次是:
将输出特征C5再经过1×1卷积得到 的特征,式中 为Transformer模型的Embedding dimension。
一个需要注意的问题是:如上文所述,Transformer模型不能像图像分类任务那样对图片进行resize操作,因为resize操作会影响图片的质量。再ViT模型中,图片都是被resize成相同的224×224×3的大小输入给模型,但是TRIP不能进行resize操作,所以在进行位置编码时就必须 定义了具有足够长度的位置编码以覆盖数据集中具有最大分辨率的图片。对于分辨率较小的图片,可以通过截断的方式来控制对应的位置编码长度。
此外,当输入图像具有较大的分辨率时,图像patch的数量 ( ) 也可以很大。这导致了两个潜在问题。首先,在分辨率非常高的图像上运行Transformer编码器需要很大的内存。其次,当patch的数量过多时,我们的Transformer模型捕获不同图片patch之间的长距离依赖 (long-term dependence) 的能力也会下降。所以这里应该做的是减小patch的数量。具体的做法是使用池化层。对于输出特征C5再经过1×1卷积得到 的特征,首先对其进行Max-Pool 处理得到维度为 的特征,然后再进行Flatten操作得到最终的维度为 的特征,将这个特征输入到Transformer的Encoder中。Max-Pool 的参数 的大小是根据输入图像的分辨率自适应地确定的。
根据上面的描述,Transformer的Encoder输入的是这个 的张量。
同时,模仿ViT使用class token的做法,作者在这里也加了一个Image quality token,与输入张量concat在一起。这样输入张量的维度就变成了 。
对于位置编码而言,IQT没有使用ViT中的正弦位置编码,而使用了可学习的位置编码,其维度为: 。
所以Encoder的流程写成公式就是:
注意这里Layer Normalization的位置是在Add以后的,而不是先做LN。再通过MHSA或者FFN。Encoder输出张量的维度是 。
最后,Image quality token对应的输出 通过一个MLP head得到一个5维的向量来预测一个分布,这个softmax分布是代表了图片的质量分布:1=bad, 2=poor, 3=fair, 4= good, 5=excellent。损失函数是Cross-Entropy Loss,代表图像质量分布与ground-truth分布之间的距离。举个例子,输出结果为[0.01, 0.08, 0.11, 0.3, 0.5],标签为[0, 0, 0, 0, 1],那么对于这个样本来讲我们只需要计算这两个向量之间的CE-Loss即可。
最后的得分计算为:
Experiments:
数据集制作: 实验涉及到的2个数据集是KonIQ-10k和LIVE-wild。这2个数据集不宜直接混合,因为它们的rating scales不同,意思是相同的图像内容在不同的实验中可能被赋予不同的质量等级。作者进行了一项小规模实验,使用5名参与者比较了20对图像,每一对图像中一张来自KonIQ-10k数据集而另一张来自LIVE-wild数据集,参与者被要求比较它们并判断它们是否代表了相似的质量水平。实验表明,随机选取的20对图像几乎都具有相似的质量水平。因此,在这项工作中,这两个数据库被结合起来。
作者将这2个数据集按照spatial information (SI) 的大小分为了两类:high SI和low SI,每类又进一步按照真值MOS的大小分成5种不同的质量等级的图片。由于KonIQ-10k数据库中的图像数量要比LIVE-wild高得多,所以我们从每个复杂度类别中的每个质量类别中随机选取KonIQ-10k数据库中85%的图像和LIVE-wild数据库中50%的图像作为训练图像,剩下的图像作为测试图像。作者还使用了KonIQ-10k 数据集一般大小的数据,并命名为KonIQ-half-sized 数据集。因此,最后生成了一个由KonIQ-10k,KonIQ-half-sized 和 LIVE-wild 数据库组成的组合数据库,所包含的训练和测试集是从单个数据库的原始分割继承而来的。
超参数设置:
Transformer超参数:
| 参数 | 值 |
|---|---|
| Encoder层数 | 2 |
| Head数 | 8 |
| Embedding dimension | 32 |
| patch size | 32 |
| FFN的Expansion ratio | 2 |
作者还另外尝试了2种模型,即ViT-IQA和R50-ViT-IQA,ViT模型在提出时其实是有两种,一种是把图片直接分patch,而另一种是以ResNet-50作为特征提取器得到相同size的特征。这个R50的意思是ViT的特征提取环节使用ResNet-50进行,而不是直接分patch。ViT-IQA和R50-ViT-IQA 直接继承了ViT 模型的架构和在ImageNet-21k上训练的权重来进行IQA的任务,在MLP head那里换成了TRIP的结构。训练的超参数如下:
训练超参数:
| 参数 | 值 |
|---|---|
| 优化器 | Adam |
| 初始学习率 | 5e-5 |
| warm up | linear |
| weight decay | cosine |
| fine-tune学习率 | 1e-6 |
Evaluation Metrics:
SROCC (如上文介绍) ,PLCC (如上文介绍) ,真值MOS和预测值之间的MSE。
第一个实验是在混合数据集上面进行的,结果如下图11所示。TRIQ的结果超过了ViT-IQA和R50-ViT-IQA这2种模型。尽管ViT在大规模数据集ImageNet-21k预训练的帮助下,在图像识别方面取得了很好的性能,但它在IQA方面还不能击败TRIQ。作者认为主要原因是,在这项工作中,IQA使用的数据集规模相对较小,不能充分利用大规模的预训练的优势。而且, CNN架构的inductive bias的能力比单纯的patch更能恰当地捕捉图像质量特征。由于使用的数据集都是数量较小的,TRIQ中使用的Transformer编码器的浅层架构,而不是R50-ViT-IQA的更深层次架构,所以对于小数据集而言,浅层的Transformer模型足以捕获足够的特征,用于图像质量感知。
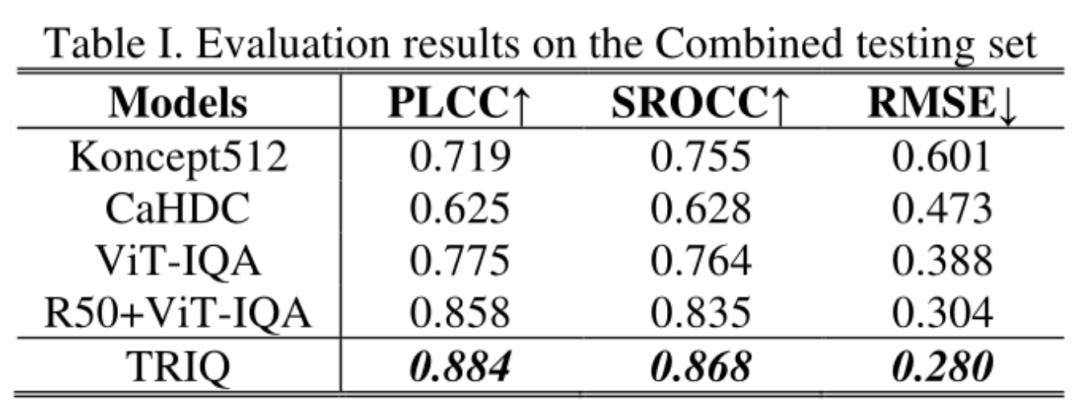
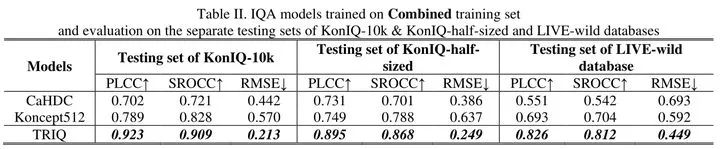
下图12是在混合数据集上训练并分别在各个数据集上测试的结果。与其他的模型相比,TRIQ作为一种通用的IQA模型对各种图像内容和分辨率具有良好的性能。
Attention weights可视化
下图13所示是通过对不同head的Attention weights进行平均,然后将归一化后的权重作为输入图像的mask,将训练过程中学习到的权重可视化。不同head的Attention weights进行平均之后的attention map的大小是 的。可视化的方法是把第一行,即image quality token对应的 个归一化权值resize成image的大小,作为输入图像的mask,与输入图像叠加在一起得到的结果。
右侧这一列是ViT模型的Attention weights可视化结果。与ViT模型相比,IQA中注意力的分布更加广泛,而不是集中在感兴趣的区域。我们假设这是因为投票者 (主观参与者或客观质量模型) 在评估图像质量时,往往需要集中于整个图像区域,以收集更多的信息。

小结:
本文是第1个将Transformer应用于IQA任务的工作。通过CNN作为特征提取器,以及Transformer的建模,得到一张图片的质量分数,为后期的IQT提供了baseline方法。本文的另一大贡献就是完成了一个Transformer+IQA任务的baseline,包括数据集的制作和处理,结果的分析和可视化,对领域有一定的开创意义。
总结:
本文介绍的两个工作是视觉Transformer在图像质量评价 (Image Quality Assessment) 中的应用。TRIP是第1个将Transformer应用于IQA任务的工作,完成了一个可靠的Transformer+IQA任务的baseline,而IQT侧重于Perceptual Image Quality Assessment,即:模型的输出结果更接近人类的感知结果。作为NTIRE 2021冠军方案,它尤其擅长于评价GAN生成的图片的质量,这一点很难得,因为这种图片视觉效果较好,但在一些常见指标 (如PSNR,SSIM) 上表现较差。IQT解决了评价图片的感知质量的问题,对领域有一定的启发意义。
本文亮点总结
为数不多的基于Transformer的IQA模型。 侧重于Perceptual Image Quality Assessment,即:模型的输出结果更接近人类的感知结果。 获得了NTIRE 2021 IQA赛道的1st Place。
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“目标检测”获取目标检测算法综述盘点~


# 极市原创作者激励计划 #




