 Java技术迷
Java技术迷





来源 | Java技术迷(ID:JavaFans1024)
安装ElasticSearch
首先来到官网下载ElasticSearch:https://www.elastic.co/cn/elasticsearch/
 '
点击按钮进行下载:
'
点击按钮进行下载:
我们以Windows版本为例,下载完成后解压出来,然后执行bin目录下的 elasticsearch.bat 文件:

等待启动完成后,访问http://localhost:9200/:
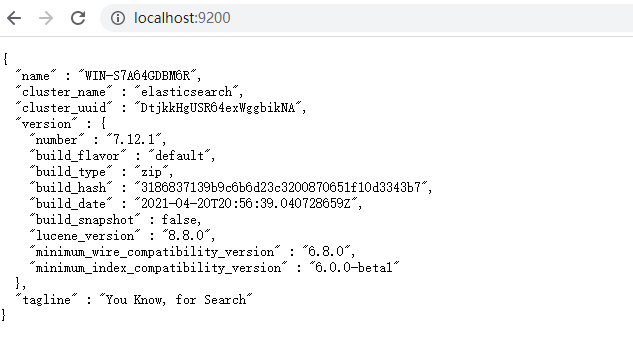
看到此界面则说明ElasticSearch启动成功了。
相关概念
在正式学习ElasticSearch之前,我们先来了解一下ElasticSearch。
Elasticsearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。
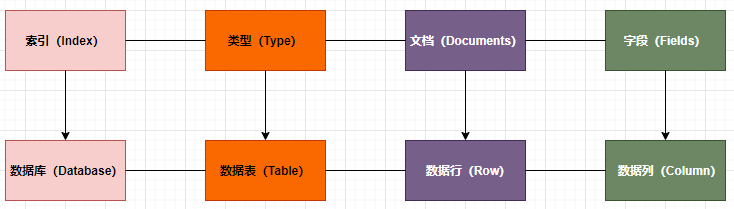
在ElasticSearch中有四个相关的概念:
索引 类型 文档 字段
我们可以将其类比到关系型数据库中,索引就是一个数据库,类型就是一张数据表,而文档就是数据表中的一行,字段就是数据表中的一列,如下图:
ElasticSearch通常用于网站的全文检索,这意味着ElasticSearch将承担着整个系统最大搜索量的搜索业务,想象一下在淘宝搜索入口上搜索一个手机,系统背后需要经历多么大的数据量查询。然而在如此大数据量的情况下,ElasticSearch仍然能够非常出色的完成任务,它是如何做到的呢?
我们先来看一张关系型数据库中的数据表:
+----+------------+
| id | name |
+----+------------+
| 1 | zhang san |
| 2 | zhang san2 |
| 3 | zhang san3 |
| 4 | li si |
+----+------------+
假设这张数据表的数据量非常庞大,若是想进行模糊查询,查询姓 zhang 的用户信息,那么它的效率一定是很低的,因为它需要从第一条数据开始遍历到最后一条数据。来看看ElasticSearch是如何做的,它采用的是一种叫 倒排索引 的方式,即:在插入数据的时候就建立了一张关键字与id的对应表:
+---------+-------+
| keyword | id |
+----+------------+
| zhang | 1,2,3 |
| san | 1,2,3 |
| li | 4 |
| si | 4 |
+---------+-------+
它会将名字中的关键字提取出来,并记录当前id拥有哪些关键字,将其存放起来,此时我们查询姓 zhang 的用户信息时,我们将直接得到姓 zhang 的用户id为 1、2、3 ,然后通过id找到用户信息即可,查询效率大幅提升了。
需要注意的是,从ElasticSearch7.X版本开始,Type的概念已经被移除了。
索引
接下来我们就来看看ElasticSearch中索引的具体操作,因为它是基于RESTful web接口的,所以我们使用Postman进行测试。
创建索引
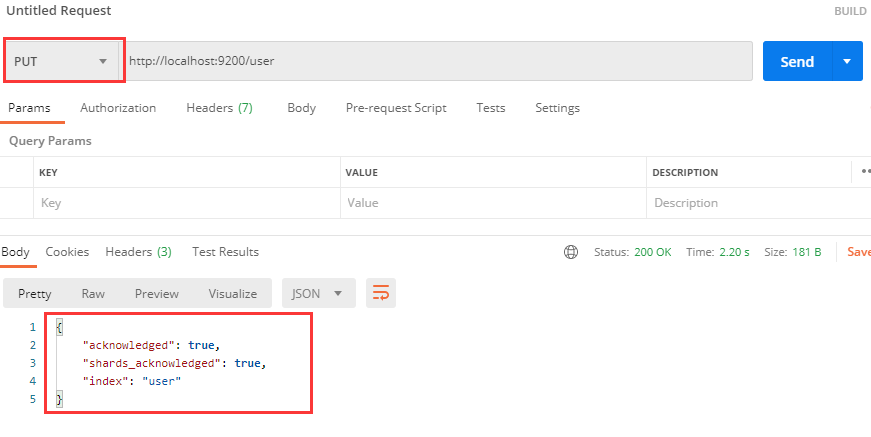
访问路径为 http://localhost:9200/user,请求方式一定要选择PUT,了解RESTful接口的同学都知道,接口的请求方式决定了这次请求的行为,当出现底部的响应内容时,说明索引创建成功了。
查询索引
查询索引非常简单,我们只需要修改刚才的请求方式为GET即可:
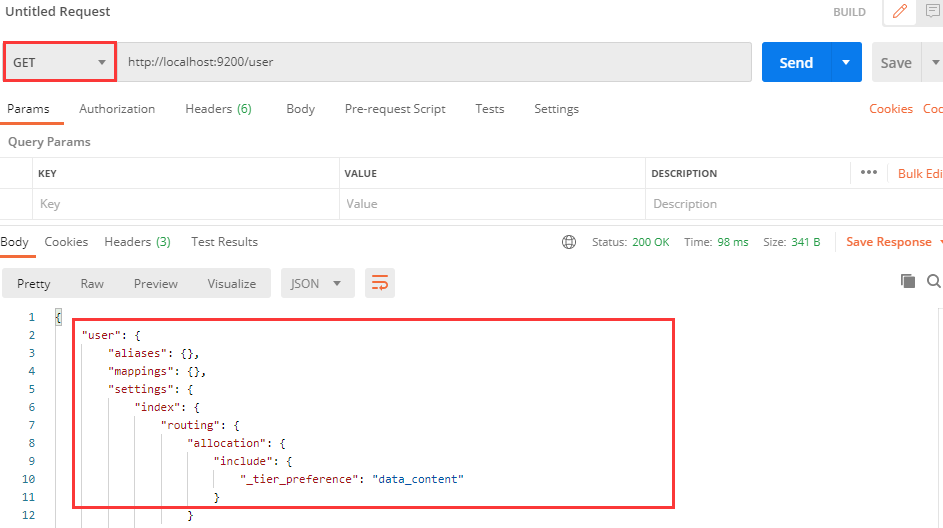
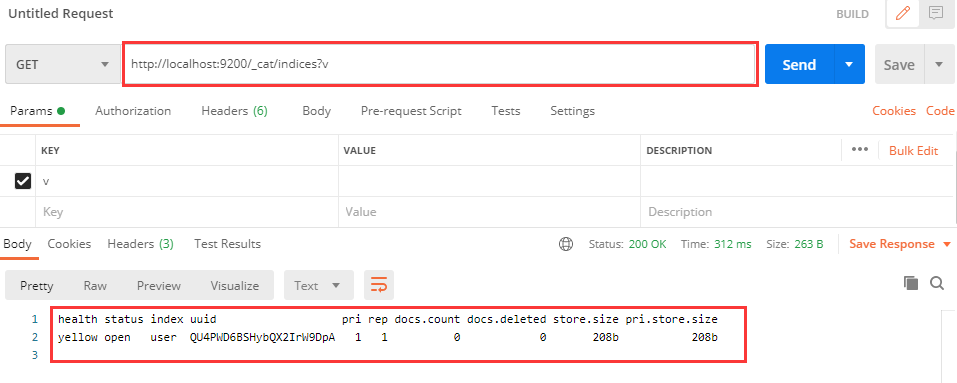
响应的内容是刚刚创建的索引信息,若是想查询ElasticSearch中的所有索引,则访问 _cat :
删除索引
相信你已经知道该如何删除索引了吧,没错,只需要将请求方式修改为DELETE即可:

文档
我们再来看看文档的相关操作,文档对应关系型数据库中的数据行。
创建文档
创建文档的方式也非常简单:

首先在访问路径上添加 /_doc ,其次修改请求方式为POST,最后不要忘记添加请求体参数,它将作为我们的文档数据。需要注意的是,创建索引使用的是PUT请求,而创建文档使用的是POST请求,千万不能搞混了,实在记不清的话,你可以这样理解,当我们在创建文档时,响应内容中有一项 _id 参数,而每次请求这个 _id 都是会变化的,这就说明该接口是不符合幂等性的。
幂等性就是指用户对于同一操作发起的一次请求或者多次请求的结果是一致的,不会因为多次点击而产生了副作用。
而PUT方式要求接口必须符合幂等性,所以我们在创建文档时就不能选择使用PUT方式,这样记忆是不是会更好呢。
在创建文档时我们可以通过url指定文档的id:

因为此时的id是由你自己指定的,所以每次发送请求得到的响应结果其实是一样的,符合幂等性,因此,这种指定id创建文档的方式也可以使用PUT请求:
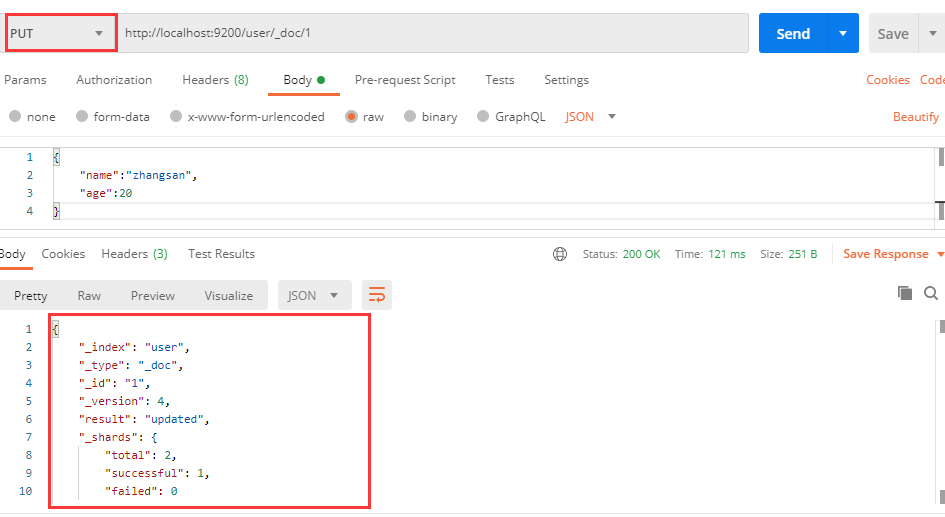
查询文档
通过GET请求方式即可查询文档:
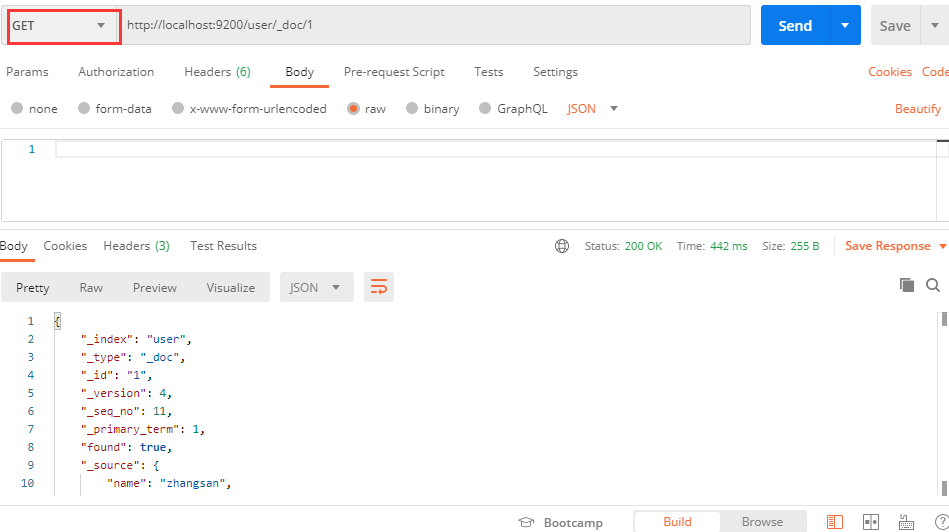
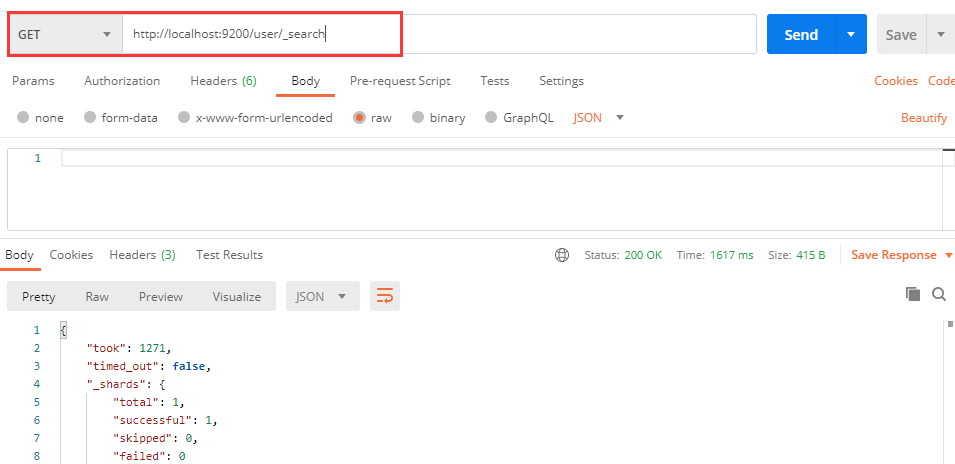
使用 _search 即可查询所有ElasticSearch中的所有文档数据:
更新文档
更新文档分为两种方式:
全量更新 局部更新
其中全量更新指的是将文档中的数据全部进行更新,由于是全部更新,每次请求响应的内容是一致的,符合幂等性,所以可以使用PUT请求(当然了,POST请求一定也是可以的):

而对于局部更新,因为每次更新的内容可能不同,导致响应的结果也不同,它就不符合接口的幂等性,所以它只能使用POST请求进行更新:
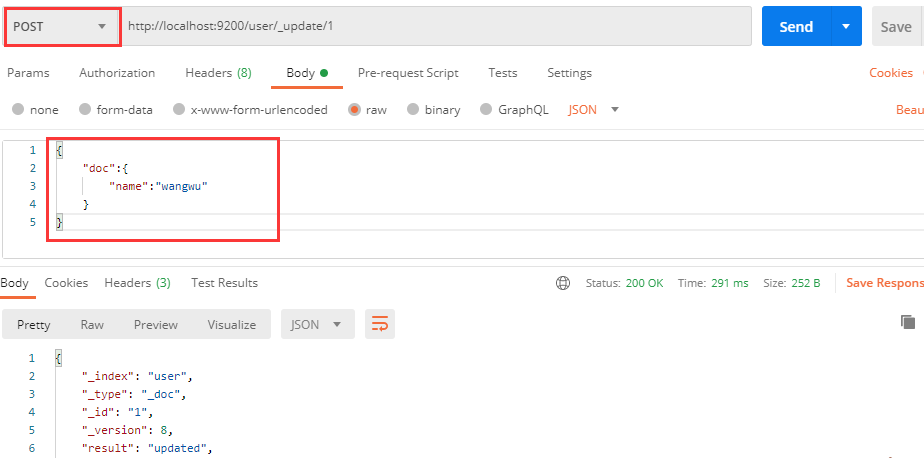
此时我们的url需要进行修改,使用 _update 来指定此次操作为更新操作(对应的还有 _create 操作,只不过它与 _doc 功能相同,都是创建索引),而且请求体参数也发生了变化,需要更新的属性值需要写在 doc 属性中。
删除文档
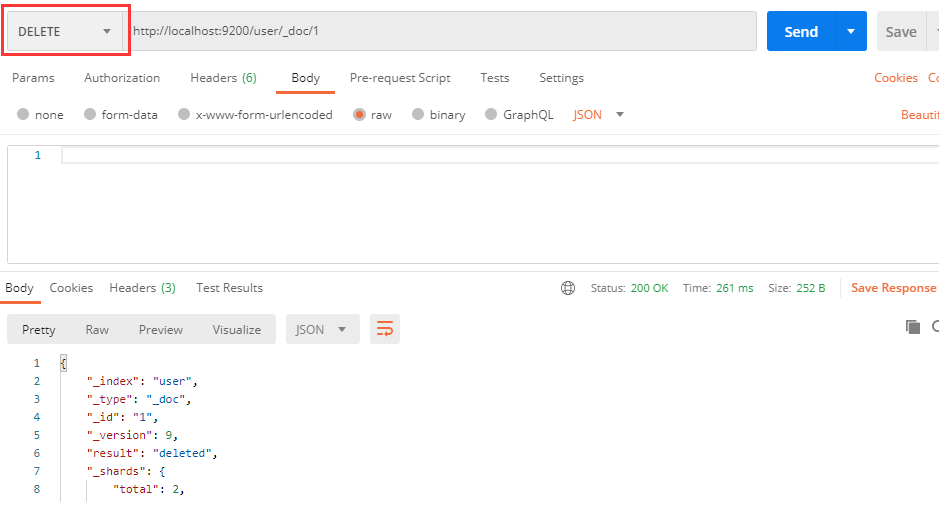
只需将请求方式设置为DELETE即可完成对文档的删除:
高级查询
作为全文检索工具,ElasticSearch在查询方面具有无与伦比的效率,为此,我们再来看看ElasticSearch中关于查询的一些高级内容。
条件查询
要想实现条件查询,我们就需要将查询条件拼接到url中:

我们知道, _search 可以查询ElasticSearch中的所有文档数据,通过 q 参数即可传入查询条件。
使用url传递参数有诸多弊端,编写麻烦而且容易出现乱码问题,所以我们可以将查询条件作为请求体参数进行传递:
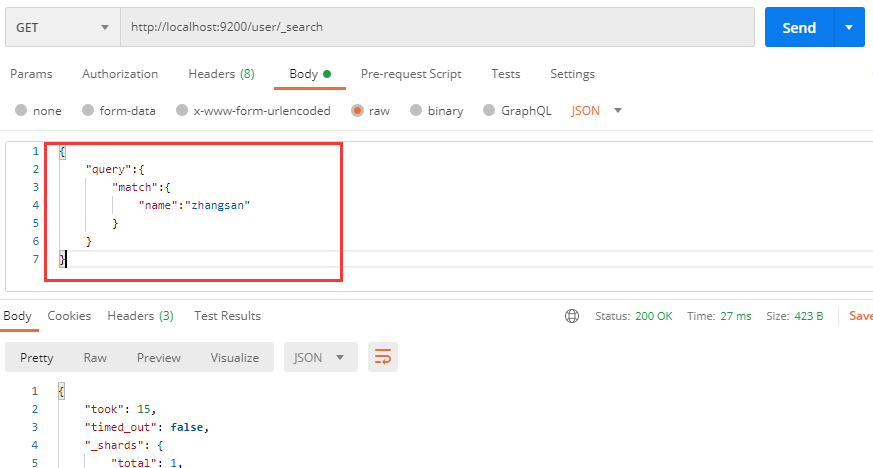
请求体参数中, query 表示这是一个查询条件, match 指定的是查询模式,为匹配查询,匹配内容为 name 等于 zhangsan 。
ElasticSearch当然也支持分页查询:

其中 from 用于指定页码, size 指定每页记录数,这里则表示按每页两条记录数进行分页,并返回第一页的文档数据。请求参数中指定 _source 能够指定响应内容中文档的数据,比如:
{
"query":{
"match":{
"name":"zhangsan"
}
},
"from":0,
"size":2,
"_source":["name"]
}
它表示在分页查询的基础上只显示 name 属性值。若是想实现查询时排序,则只需在请求体参数中添加一个 sort 属性:
{
"query":{
"match":{
"name":"zhangsan"
}
},
"from":0,
"size":2,
"_source":["name"],
"sort":{
"age":{
"order":"asc"
}
}
}
它表示按照年龄进行升序。
多条件查询
若是想实现多条件查询,则需要进一步封装请求体参数,比如查询 name 为 zhangsan 且 age 等于 20 的用户信息:
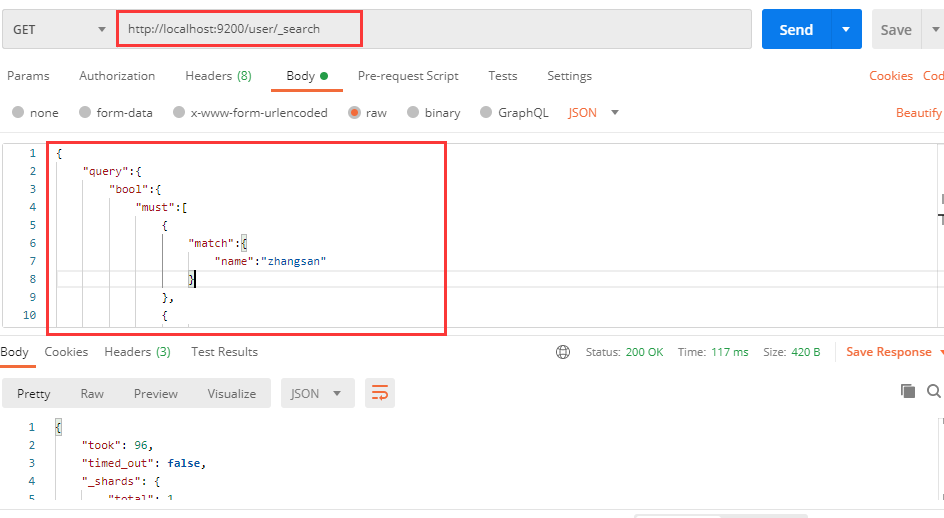
请求体参数为:
{
"query":{
"bool":{
"must":[
{
"match":{
"name":"zhangsan"
}
},
{
"match":{
"age":"20"
}
}
]
}
}
}
其中 query 表示查询,不必多说, bool 表示查询条件,之后就是 must 了,它表示must中的内容一定要成立,must中可以填写多个查询条件,match 表示匹配,匹配内容为 name 等于 zhangsan , age 等于 20 。
若是想实现查询 name 为 zhangsan 或者 lisi 的用户,则需要将 must 替换为 should :
{
"query":{
"bool":{
"should":[
{
"match":{
"name":"zhangsan"
}
},
{
"match":{
"name":"lisi"
}
}
]
}
}
}
若是想查询年龄在20~30之间的用户信息,则我们需要借助 filter 属性:
{
"query":{
"bool":{
"filter":{
"range":{
"age":{
"gt":20,
"lt":30
}
}
}
}
}
}
全文检索
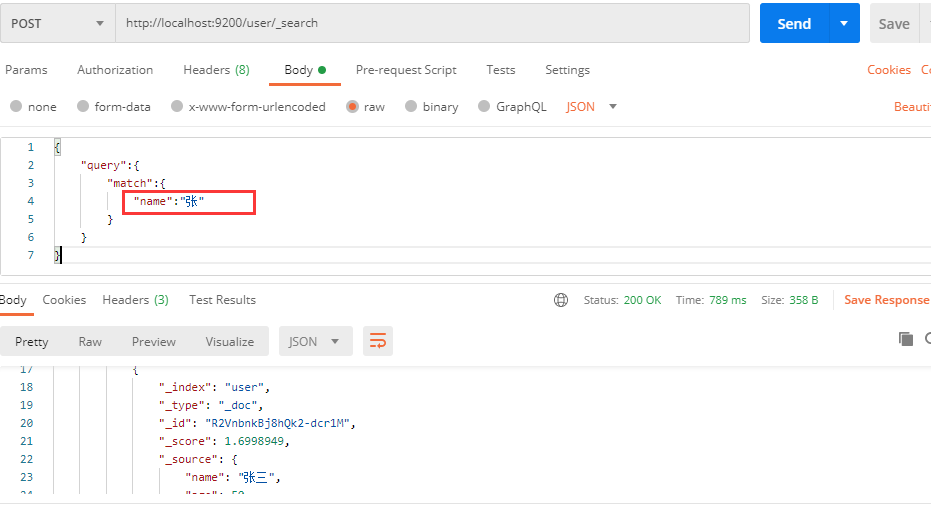
当我们在检索某个关键字的时候,ElasticSearch仍然能够准备查询到相关信息,这是因为ElasticSearch会将文字分词并与文档id作对应形成倒排索引,相关内容我们在前面就已经接触到了,这就是ElasticSearch的全文检索功能。当我们的姓名是两个汉字时:
{
"query":{
"match":{
"name":"张李"
}
}
}
ElasticSearch仍然会将其分为 张 和 李 两个字,并分别做匹配,若是我们就想查询名字叫 张李 的用户,那么就不能使用 match 匹配了,而是使用 match_phrase :
{
"query":{
"match_phrase":{
"name":"张李"
}
}
}
它表示的是完全匹配,即:匹配的内容必须和属性值完全一致。我们还可以让匹配的内容高亮显示:
{
"query":{
"match_phrase":{
"name":"张三"
}
},
"highlight":{
"fields":{
"name":{}
}
}
}
使用 highlight 指定需要高亮显示的属性。
聚合查询
若是想对查询的数据进行分组管理,在ElasticSearch中称为聚合操作,比如:
{
"aggs":{
"age_group":{
"terms":{
"field":"age"
}
}
}
}
aggs 表示这是一次聚合操作, age_group 是统计结果的名称,可以随意指定, terms 表示以哪个属性进行分组。分组后的结果:
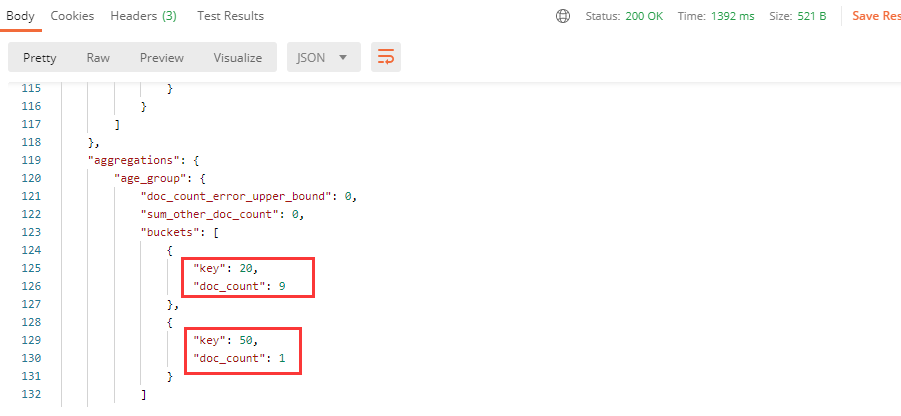
它将显示出每个年龄的用户数量。
求每个用户的年龄平均值:
{
"aggs":{
"age_avg":{
"avg":{
"field":"age"
}
}
}
}
结果:
....
"aggregations": {
"age_avg": {
"value": 23.0
}
}
....
Java项目中如何操作ElasticSearch
下面我们来看看在Java项目中该如何使用ElasticSearch以及相关操作。首先创建一个普通的Maven项目,并引入依赖:
<dependencies>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.8.0</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.8.0</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>2.8.2</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.8.2</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.9.9</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
</dependencies>
在正式操作之前,我们先在Linux环境安装一下ElasticSearch,这里推荐使用Docker进行环境搭建,首先拉取ElasticSearch的镜像:
docker pull elasticsearch:7.4.2
然后创建两个文件夹
mkdir -p /mydata/elasticsearch/config
mkdir -p /mydata/elasticsearch/data
它们将分别用于存放ElasticSearch的配置文件和数据文件,然后修改一下文件夹权限:
chmod 777 /mydata/elasticsearch/data/
这样就可以启动ElasticSearch了:
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \
-e ES_JAVA_OPTS="-Xms64m -Xmx128m" \
-v /mydata/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /mydata/elasticsearch/data:/usr/share/elasticsearch/data \
-v /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins \
-d elasticsearch:7.4.2
启动完成后,同样测试一下:
接下来我们就可以在Java程序中尝试创建一下索引:
public class ESClient {
private RestHighLevelClient esClient;
@Before
public void createClient() {
// 创建es客户端
esClient = new RestHighLevelClient(
RestClient.builder(new HttpHost("192.168.56.10", 9200, "http"))
);
}
@After
public void closeClient() throws IOException {
// 关闭客户端
esClient.close();
}
@Test
public void testIndex() throws IOException {
// 创建索引
CreateIndexRequest request = new CreateIndexRequest("emp");
CreateIndexResponse response = esClient.indices().create(request, RequestOptions.DEFAULT);
boolean result = response.isAcknowledged();
if (result) {
System.out.println("索引创建成功...");
} else {
System.out.println("索引创建失败...");
}
}
}
首先需要创建ElasticSearch客户端,指定ip、端口和http协议,然后就可以创建索引了,通过CreateIndexRequest即可创建一个索引。其它的索引操作也都是类似的:
@Test
public void testIndex() throws IOException {
// 查询索引
GetIndexRequest request = new GetIndexRequest("emp");
GetIndexResponse response = esClient.indices().get(request, RequestOptions.DEFAULT);
System.out.println(response.getAliases());
System.out.println(response.getSettings());
System.out.println(response.getMappings());
}
通过GetIndexRequest即可查询索引,在response中可以获取别名、设置及其映射等信息,运行结果:
{emp=[]}
{emp={"index.creation_date":"1621085161553","index.number_of_replicas":"1","index.number_of_shards":"1","index.provided_name":"emp","index.uuid":"kOqizSD5R9Kq4W-5mKinfw","index.version.created":"7040299"}}
{emp=org.elasticsearch.cluster.metadata.MappingMetadata@d42716bd}
最后是删除索引:
@Test
public void testIndex() throws IOException {
// 删除索引
DeleteIndexRequest request = new DeleteIndexRequest("emp");
AcknowledgedResponse response = esClient.indices().delete(request, RequestOptions.DEFAULT);
boolean result = response.isAcknowledged();
if (result) {
System.out.println("索引删除成功");
}else {
System.out.println("索引删除失败");
}
}
接着是Java项目中对于文档的操作,文档需要传入的是json数据,所以我们先创建一个Bean:
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Employee {
private String name;
private Integer age;
private String sex;
private Double salary;
}
创建文档过程如下:
@Test
public void testDoc() throws IOException {
// 创建文档
IndexRequest request = new IndexRequest();
// 指定索引
request.index("emp");
// 指定文档id
request.id("1");
Employee employee = new Employee("张三", 30, "男", 6000.0);
// 将对象转为json数据
Gson gson = new Gson();
String empJson = gson.toJson(employee);
// 传入json数据
request.source(empJson, XContentType.JSON);
IndexResponse response = esClient.index(request, RequestOptions.DEFAULT);
System.out.println(response.getResult());
}
若是想要更新文档,则只需使用UpdateRequest即可:
@Test
public void testDoc() throws IOException {
// 更新文档
UpdateRequest request = new UpdateRequest();
// 指定索引
request.index("emp");
// 指定文档id
request.id("1");
// 更新
request.doc(XContentType.JSON,"salary",5000.0);
UpdateResponse response = esClient.update(request, RequestOptions.DEFAULT);
System.out.println(response.getResult());
}
接下来的查询文档和删除文档操作,相信不用往下看,大家也应该会了,这里就直接贴代码了:
@Test
public void testDoc() throws IOException {
// 查询文档
GetRequest request = new GetRequest();
// 指定索引
request.index("emp");
// 指定id
request.id("1");
GetResponse response = esClient.get(request, RequestOptions.DEFAULT);
System.out.println(response.getSourceAsString());
}
@Test
public void testDoc() throws IOException {
// 删除文档
DeleteRequest request = new DeleteRequest();
// 指定索引
request.index("emp");
// 指定id
request.id("1");
DeleteResponse response = esClient.delete(request, RequestOptions.DEFAULT);
System.out.println(response.toString());
}
Java API中也提供了批量创建和删除文档的方法,一起来看看如何操作:
@Test
public void testDoc() throws IOException {
// 批量创建文档
BulkRequest request = new BulkRequest();
// 创建对象
Employee employee = new Employee("张三", 20, "男", 5000.0);
Employee employee2 = new Employee("李四", 30, "男", 6000.0);
Employee employee3 = new Employee("王五", 40, "男", 6000.0);
// 添加到request中
request.add(new IndexRequest().index("emp").id("1").source(new Gson().toJson(employee), XContentType.JSON));
request.add(new IndexRequest().index("emp").id("2").source(new Gson().toJson(employee2), XContentType.JSON));
request.add(new IndexRequest().index("emp").id("3").source(new Gson().toJson(employee3), XContentType.JSON));
// 执行批量创建
BulkResponse response = esClient.bulk(request, RequestOptions.DEFAULT);
System.out.println(Arrays.toString(response.getItems()));
}
@Test
public void testDoc() throws IOException {
// 批量删除文档
BulkRequest request = new BulkRequest();
// 添加到request中
request.add(new DeleteRequest().index("emp").id("1"));
request.add(new DeleteRequest().index("emp").id("2"));
request.add(new DeleteRequest().index("emp").id("3"));
// 执行批量删除
BulkResponse response = esClient.bulk(request, RequestOptions.DEFAULT);
System.out.println(Arrays.toString(response.getItems()));
}
高级查询
最后我们来看看Java API该如何实现ElasticSearch中的高级查询。
@Test
public void testQuery() throws IOException {
// 高级查询
SearchRequest request = new SearchRequest();
// 指定索引
request.indices("emp");
// 指定查询条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder().query(QueryBuilders.matchAllQuery());// 匹配所有
request.source(searchSourceBuilder);
SearchResponse response = esClient.search(request, RequestOptions.DEFAULT);
SearchHits hits = response.getHits();
System.out.println(hits.getTotalHits()); // 获取结果总记录数
System.out.println(response.getTook()); // 获取查询耗费时间
hits.forEach(System.out::println);
}
QueryBuilders类中提供了一些已经写好的查询条件,比如这里的matchAllQuery,表示匹配所有,即:全量匹配,看看运行结果:
3 hits
1.3s
{
"_index" : "emp",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"name" : "张三",
"age" : 20,
"sex" : "男",
"salary" : 5000.0
}
}
{
"_index" : "emp",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"name" : "李四",
"age" : 30,
"sex" : "男",
"salary" : 6000.0
}
}
{
"_index" : "emp",
"_type" : "_doc",
"_id" : "3",
"_score" : 1.0,
"_source" : {
"name" : "王五",
"age" : 40,
"sex" : "男",
"salary" : 6000.0
}
}
条件查询:
@Test
public void testQuery() throws IOException {
// 高级查询
SearchRequest request = new SearchRequest();
// 指定索引
request.indices("emp");
// 指定查询条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder().query(QueryBuilders.termQuery("age",30));
request.source(searchSourceBuilder);
SearchResponse response = esClient.search(request, RequestOptions.DEFAULT);
SearchHits hits = response.getHits();
hits.forEach(System.out::println);
}
调用QueryBuilders的termQuery方法能够指定具体的查询条件,此时便可以查询出年龄为30岁的用户信息:
{"name":"李四","age":30,"sex":"男","salary":6000.0}
分页查询:
@Test
public void testQuery() throws IOException {
SearchRequest request = new SearchRequest(); // 高级查询
request.indices("emp"); // 指定索引
// 指定查询条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder().query(QueryBuilders.matchAllQuery());// 匹配所有
searchSourceBuilder.from(0); // 指定页码
searchSourceBuilder.size(2); // 指定每页的记录数
request.source(searchSourceBuilder);
SearchResponse response = esClient.search(request, RequestOptions.DEFAULT);
SearchHits hits = response.getHits();
System.out.println(hits.getTotalHits());
hits.forEach(hit -> {
System.out.println(hit.getSourceAsString());
});
}
通过from和size方法即可指定分页参数,此时将会查询到第一页的两条数据:
3 hits
{"name":"张三","age":20,"sex":"男","salary":5000.0}
{"name":"李四","age":30,"sex":"男","salary":6000.0}
组合查询:
@Test
public void testQuery() throws IOException {
SearchRequest request = new SearchRequest(); // 高级查询
request.indices("emp"); // 指定索引
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
BoolQueryBuilder queryBuilder = QueryBuilders.boolQuery();
// 指定查询条件
queryBuilder.must(QueryBuilders.matchQuery("age", 30))
.must(QueryBuilders.matchQuery("sex", "男"));
searchSourceBuilder.query(queryBuilder);
request.source(searchSourceBuilder);
SearchResponse response = esClient.search(request, RequestOptions.DEFAULT);
SearchHits hits = response.getHits();
hits.forEach(hit -> {
System.out.println(hit.getSourceAsString());
});
}
此时将查询出年龄为30岁的男性用户,若是想查询年龄为20或者30的用户,则修改查询条件:
queryBuilder.should(QueryBuilders.matchQuery("age", 20))
.should(QueryBuilders.matchQuery("age", "30"));
范围查询:
@Test
public void testQuery() throws IOException {
SearchRequest request = new SearchRequest(); // 高级查询
request.indices("emp"); // 指定索引
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
RangeQueryBuilder queryBuilder = QueryBuilders.rangeQuery("age");
// 指定查询范围
queryBuilder.gte(20).lte(40);
searchSourceBuilder.query(queryBuilder);
request.source(searchSourceBuilder);
SearchResponse response = esClient.search(request, RequestOptions.DEFAULT);
SearchHits hits = response.getHits();
hits.forEach(hit -> {
System.out.println(hit.getSourceAsString());
});
}
此时将查询年龄在20~30岁之间的用户数据。
好了,以上就是本篇文章的全部内容了。我觉得写的还算通俗易懂,希望对你入门有帮助吧!
本文作者:汪伟俊 为Java技术迷专栏作者 投稿,未经允许请勿转载。

往 期 推 荐 1、Intellij IDEA这样 配置注释模板,让你瞬间高出一个逼格! 2、吊炸天的 Docker 图形化工具 Portainer,必须推荐给你! 3、最牛逼的 Java 日志框架,性能无敌,横扫所有对手! 4、把Redis当作队列来用,真的合适吗? 5、惊呆了,Spring Boot居然这么耗内存!你知道吗? 6、全网最全 Java 日志框架适配方案!还有谁不会? 7、Spring中毒太深,离开Spring我居然连最基本的接口都不会写了


点分享

点收藏

点点赞

点在看

