 Crossin的编程教室
Crossin的编程教室





https://temai.taobao.com/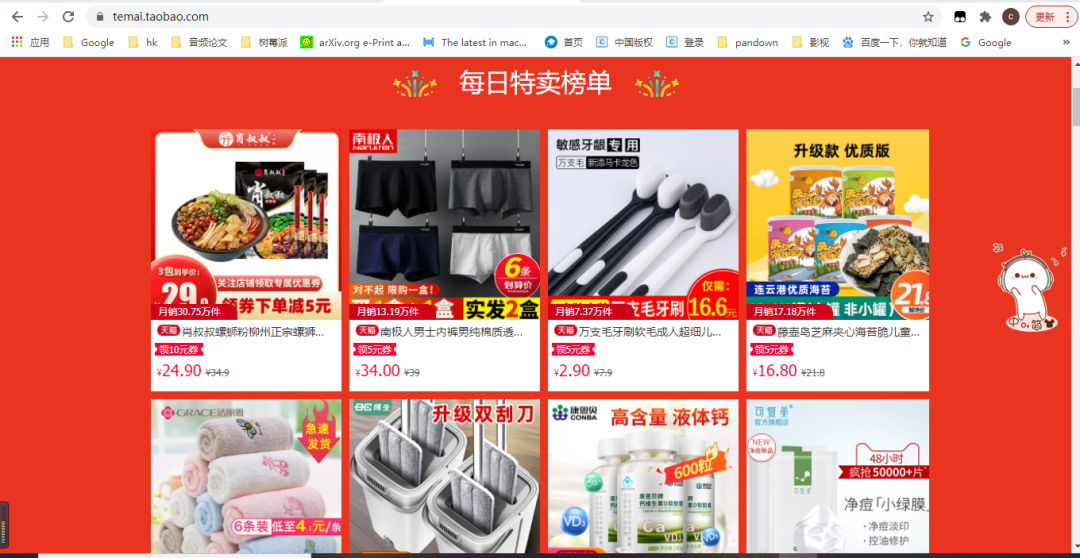
法一(失败):
起初我采用获取网页URL地址的方式去获取数据,发现数据是异步加载,无法直接从请求URL地址获取,所以这条路行不通!
法二(成功):
既然是异步加载数据,因此我们需要通过抓包的方式去查看异步数据包!
这一步我们可以借助 Chrome 的开发者工具来实现,参考之前的文章:
数据包链接
https://h5api.m.taobao.com/h5/mtop.alimama.union.xt.en.api.entry/1.0/?jsv=2.5.1&appKey=12574478&t=1612339221271&sign=8e979106ca943a3865fca277d548b607&api=mtop.alimama.union.xt.en.api.entry&v=1.0&AntiCreep=true&type=jsonp&dataType=jsonp&callback=mtopjsonp1&data=%7B%22pNum%22%3A0%2C%22pSize%22%3A%2288%22%2C%22floorId%22%3A%2223919%22%2C%22spm%22%3A%22a2e1u.13363363.35064267%22%2C%22app_pvid%22%3A%22201_11.186.139.24_4385651_1612339221783%22%2C%22ctm%22%3A%22spm-url%3A%3Bpage_url%3Ahttps%253A%252F%252Ftemai.taobao.com%252F%22%7D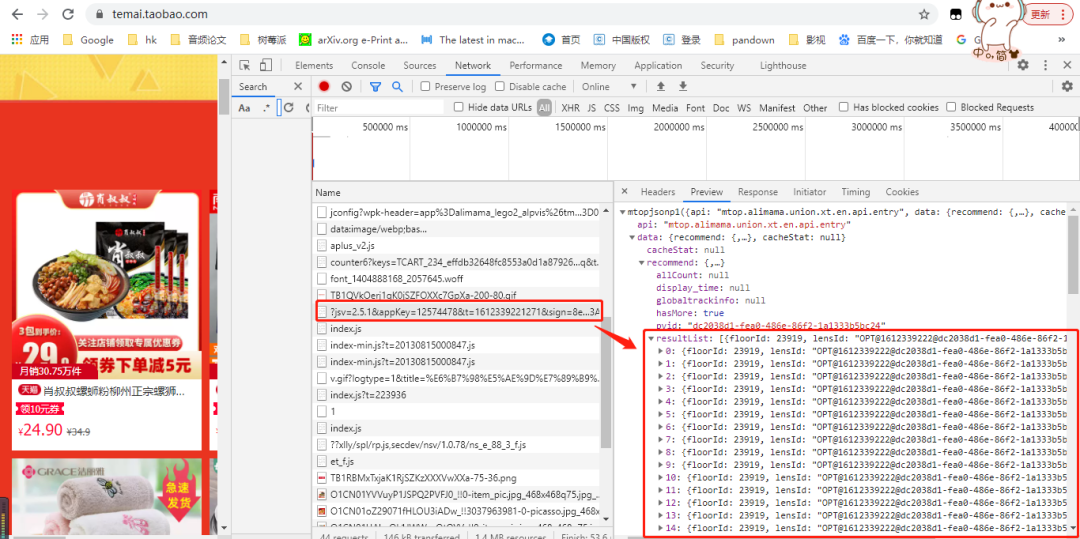
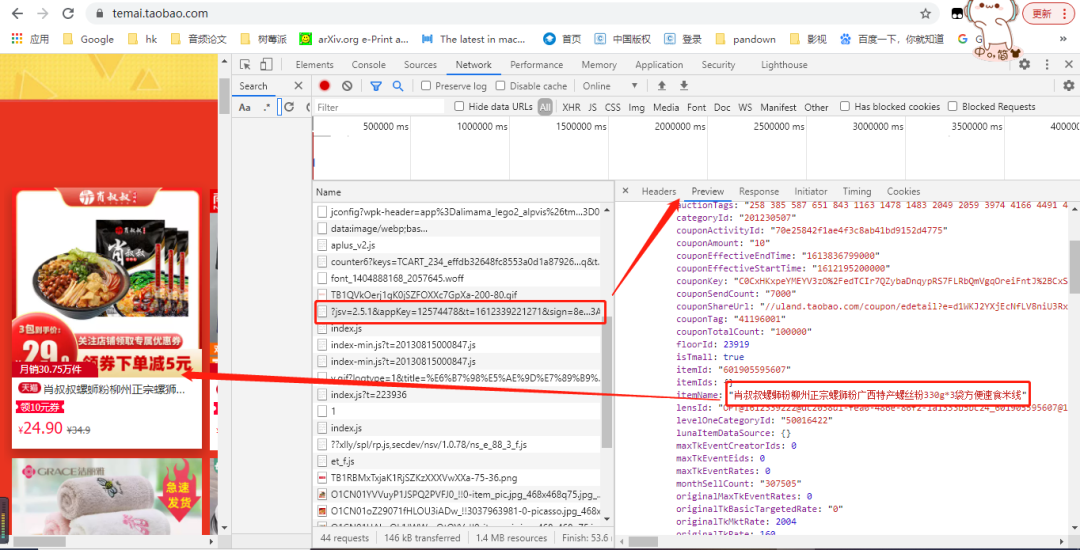
从上图可以看出,数据包中的数据与目标内容一致,因此通过python访问这个数据包即可获取数据!
这里使用了 requests 库,用来做网络请求很方便。参考文章:
问题1:权限问题
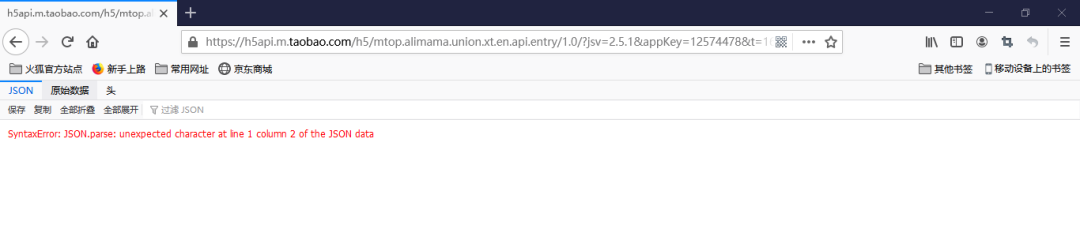
如果直接放到浏览器访问,会发现无法返回json数据,根据多年的经验来看,这个url链接的访问有权限问题!(同理在程序代码里面直接request时会出错)
解决方法
在请求附上请求头headers,即可解决这个问题!
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36','cookie':'cna=QsEFGOdo0BICARsnWHe+63/1; hng=CN%7Czh-CN%7CCNY%7C156; thw=cn; t=effdb32648fc8553a0d1a87926b80343; ctoken=M9E3xvdCNyLPC-Zyg-ZtE-nV; lego2_cna=TE08X4XP4MY5HRU8CUWMXPWD; __wpkreporterwid_=6809b44b-13ba-4faf-b370-b3788df99e39; mt=ci%3D-1_0; _m_h5_tk=843522e3dd448b136527b03c459d75b4_1612344437570; _m_h5_tk_enc=b21044b7bd07665cd105ce83fc4b4339; xlly_s=1; isg=BF1daNoy4eZf_bpk6aW7OIxsbDlXepHMvS62OB8imbTj1n0I58qhnCtEAMpQDamE; tfstk=cfNPBXYKM_CP5qGCBbGeVJ9975URwvV31T3KEJHXW-6LU4fDOH3mpNr8YcCmE; l=eBIj49hqOGMgJjg9BOfanurza77OSIRYYuPzaNbMiOCPOyfB5Hu1W6MaTD86C3GVh6XDR3yMI8QMBeYBqQAonxvOaGUhCOMmn','referer':'https://temai.taobao.com/',}
这里cookie的来源于数据包,从你的网页开发者工具里复制即可。(无需登录,也建议不要登录以免被封号)
问题2:中文乱码
解决方法
如果使用 .text 属性,可以指定编码类型:
r.encoding = 'utf8's = r.text
如果使用的是 content 属性,可以手动解码:
###乱码问题s = r.contents = s.decode('utf8')
请求数据
import requests###请求urlurl="https://h5api.m.taobao.com/h5/mtop.alimama.union.xt.en.api.entry/1.0/?jsv=2.5.1&appKey=12574478&t=1612344646955&sign=9650d7c2752bc40a2bde0b90b44d58d4&api=mtop.alimama.union.xt.en.api.entry&v=1.0&AntiCreep=true&type=jsonp&dataType=jsonp&callback=mtopjsonp2&data=%7B%22pNum%22%3A0%2C%22pSize%22%3A%2288%22%2C%22floorId%22%3A%2223919%22%2C%22spm%22%3A%22a2e1u.13363363.35064267%22%2C%22app_pvid%22%3A%22201_11.186.139.24_4399690_1612344646453%22%2C%22ctm%22%3A%22spm-url%3A%3Bpage_url%3Ahttps%253A%252F%252Ftemai.taobao.com%252F%22%7D"###requests+请求头headersr = requests.get(url, headers=headers)r.encoding = 'utf8's = r.texts = s.replace("mtopjsonp1(","").replace(")","")
提取内容
###转为json格式s = json.loads(s)resultList = s['data']['recommend']['resultList']for i in resultList:###商品名称itemName = i['itemName']print("商品名称="+str(itemName))###月销量monthSellCount = i['monthSellCount']print("月销量"+str(monthSellCount))###价格priceAfterCoupon = i['priceAfterCoupon']print("价格"+str(priceAfterCoupon))###原价promotionPrice = i['promotionPrice']print("原价="+str(promotionPrice))###店铺名称shopTitle = i['shopTitle']print("店铺名称="+str(shopTitle))###优惠劵总数couponTotalCount = i['couponTotalCount']print("优惠劵总数="+str(couponTotalCount))###优惠劵领取数couponSendCount = i['couponSendCount']print("优惠劵领取数="+str(couponSendCount))print("-------------------------")
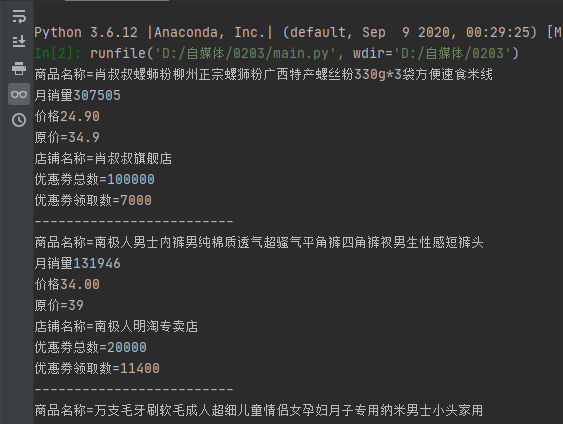
我们提取好了所需字段(商品名称、月销量、价格、原价、店铺名称、优惠劵总数、优惠劵领取数)。
接下来进行可视化分析!
###分析1:销量分析def analysis1(indexlist):#商品名称itemNames = []#销量datas = []for j in indexlist:###商品名称itemName = resultList[new_countdict[j][0]]['itemName']print("商品名称=" + str(itemName)[0:10].replace(" ",""))itemNames.append(str(itemName)[0:10].replace(" ",""))###月销量monthSellCount = resultList[new_countdict[j][0]]['monthSellCount']print("月销量" + str(monthSellCount))datas.append(int(monthSellCount))itemNames.reverse()datas.reverse()# 绘图。fig, ax = plt.subplots()b = ax.barh(range(len(itemNames)), datas, color='#6699CC')# 为横向水平的柱图右侧添加数据标签。for rect in b:w = rect.get_width()ax.text(w, rect.get_y() + rect.get_height() / 2, '%d' %int(w), ha='left', va='center')# 设置Y轴纵坐标上的刻度线标签。ax.set_yticks(range(len(itemNames)))ax.set_yticklabels(itemNames)plt.title('淘宝商品热卖月销量', loc='center', fontsize='20',fontweight='bold', color='red')plt.show()
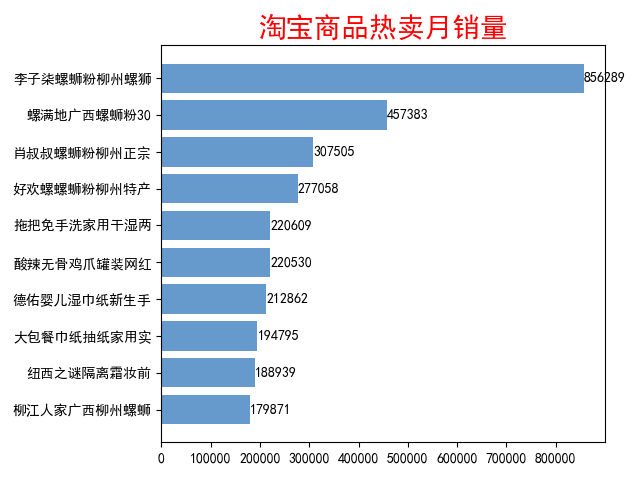
分析
1、淘宝热卖销量第一名:李子柒螺蛳粉柳州螺狮,月销量达到了85万
2、从热卖销量的前10名来看,螺蛳粉比较受欢迎,甚至霸占了前几名
3、从热卖销量的前10名来看,用户在网购方面偏向于购买食物
###分析2:优惠券领取量分析def analysis2(indexlist):# 商品名称itemNames = []# 优惠券总量datas1 = []# 优惠券领取量datas2 = []for i in range(0,len(indexlist)):j = indexlist[i]###商品名称itemName = resultList[new_countdict[j][0]]['itemName']print("商品名称=" + str(itemName)[0:10].replace(" ", ""))itemNames.append(str(i+1)+str(itemName)[1:4].replace(" ", ""))###优惠劵总数couponTotalCount = resultList[new_countdict[j][0]]['couponTotalCount']print("优惠劵总数=" + str(couponTotalCount))datas1.append(int(couponTotalCount))###优惠劵领取数couponSendCount = resultList[new_countdict[j][0]]['couponSendCount']print("优惠劵领取数=" + str(couponSendCount))datas2.append(int(couponSendCount))N = len(datas1)S = datas1C = datas2d = []for i in range(0, len(S)):sum = S[i] + C[i]d.append(sum)ind = np.arange(N) # the x locations for the groupswidth = 0.35 # the width of the bars: can also be len(x) sequencep1 = plt.bar(ind, S, width, color='#d62728') # , yerr=menStd)p2 = plt.bar(ind, C, width, bottom=S) # , yerr=womenStd)plt.ylabel('数量')plt.title('优惠券领取分析')itemNamesplt.xticks(ind, itemNames)plt.legend((p1[0], p2[0]), ('优惠券总量', '优惠券领取数'))plt.show()
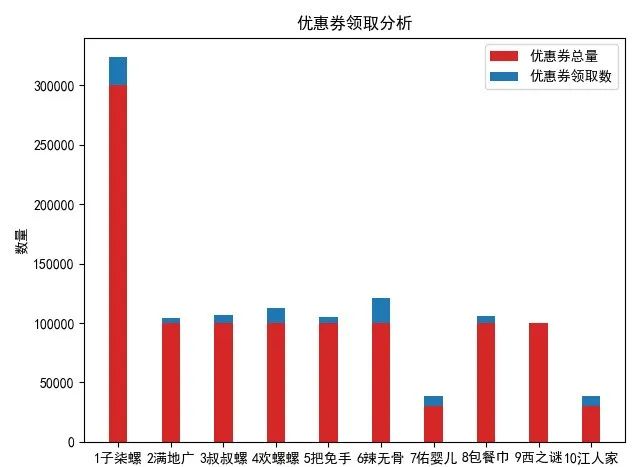
分析
由于商品名称名字太长,所以就截取前几位!同时从1-10是按销量从大到小顺序!
从图表上可以看出,销量第一:李子柒螺蛳粉柳州螺狮的优惠券总量遥遥领先
在上面的分析可知,李子柒螺蛳粉柳州螺狮的销量最大,所以优惠券领取量也随之猛增
值得关注的是第九名:纽西之谜隔离霜妆前乳女打底水润提亮肤色隐形毛孔出水官方正品的优惠券领取量竟然为0,看来客户群是真土豪,都不使用优惠券
###分析3:优惠券金额分析def analysis3(indexlist):# 商品名称itemNames = []# 优惠券金额datas = []for i in range(0,len(indexlist)):j = indexlist[i]###商品名称itemName = resultList[new_countdict[j][0]]['itemName']print("商品名称=" + str(itemName).replace(" ", ""))itemNames.append(str(i+1)+str(itemName)[0:6].replace(" ", ""))###优惠劵金额couponAmount = resultList[new_countdict[j][0]]['couponAmount']print("优惠劵金额=" + str(couponAmount))datas.append(int(couponAmount))x = range(len(itemNames))plt.plot(x, datas, marker='o', mec='r', mfc='w', label=u'优惠金额')plt.legend() # 让图例生效plt.xticks(x, itemNames, rotation=45)plt.margins(0)plt.subplots_adjust(bottom=0.15)plt.xlabel(u"商品名称") # X轴标签plt.ylabel("金额") # Y轴标签plt.title("优惠券金额分析") # 标题plt.show()
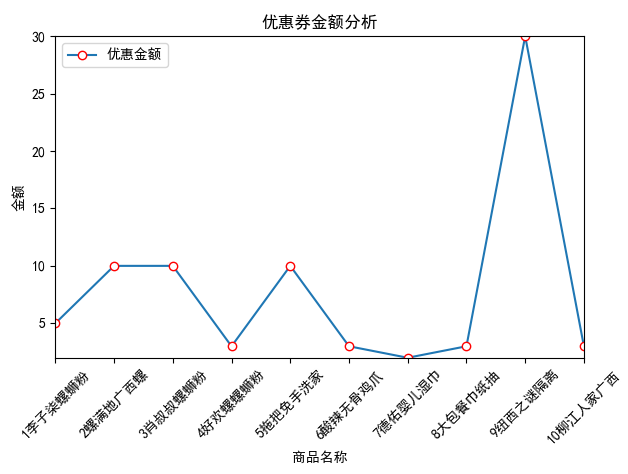
分析
从图表可以看出销量第9名商品的优惠金额最大(30元)
第7名的优惠金额竟然为0,那可以推断出这个商品没有优惠
第1、4、6、8、10,这几个商品的优惠金额<=5元
###分析4:商品原价和限价对比分析def analysis4(indexlist):# 商品名称itemNames = []# 原价datas1 = []# 限价datas2 = []for i in range(0,len(indexlist)):j = indexlist[i]###商品名称itemName = resultList[new_countdict[j][0]]['itemName']print("商品名称=" + str(itemName).replace(" ", ""))itemNames.append(str(i+1)+str(itemName)[1:4].replace(" ", ""))###原价promotionPrice = resultList[new_countdict[j][0]]['promotionPrice']print("原价=" + str(promotionPrice))datas1.append(float(promotionPrice))###限价priceAfterCoupon = resultList[new_countdict[j][0]]['priceAfterCoupon']print("价格=" + str(priceAfterCoupon))datas2.append(float(priceAfterCoupon))font_size = 10 # 字体大小fig_size = (8, 6) # 图表大小names = (u'限价', u'原价')data = (datas2,datas1)# 更新字体大小mpl.rcParams['font.size'] = font_size# 更新图表大小mpl.rcParams['figure.figsize'] = fig_size# 设置柱形图宽度bar_width = 0.35index = np.arange(len(data[0]))# 绘制「小明」的成绩rects1 = plt.bar(index, data[0], bar_width, color='#0072BC', label=names[0])# 绘制「小红」的成绩rects2 = plt.bar(index + bar_width, data[1], bar_width, color='#ED1C24', label=names[1])# X轴标题plt.xticks(index + bar_width, itemNames)# Y轴范围plt.ylim(ymax=100, ymin=0)# 图表标题plt.title(u'商品原价和限价对比分析')# 图例显示在图表下方plt.legend(loc='upper center', bbox_to_anchor=(0.5, -0.03), fancybox=True, ncol=5)# 添加数据标签def add_labels(rects):for rect in rects:height = rect.get_height()plt.text(rect.get_x() + rect.get_width() / 2, height, height, ha='center', va='bottom')# 柱形图边缘用白色填充,纯粹为了美观rect.set_edgecolor('white')add_labels(rects1)add_labels(rects2)# 图表输出到本地plt.savefig('4.png')
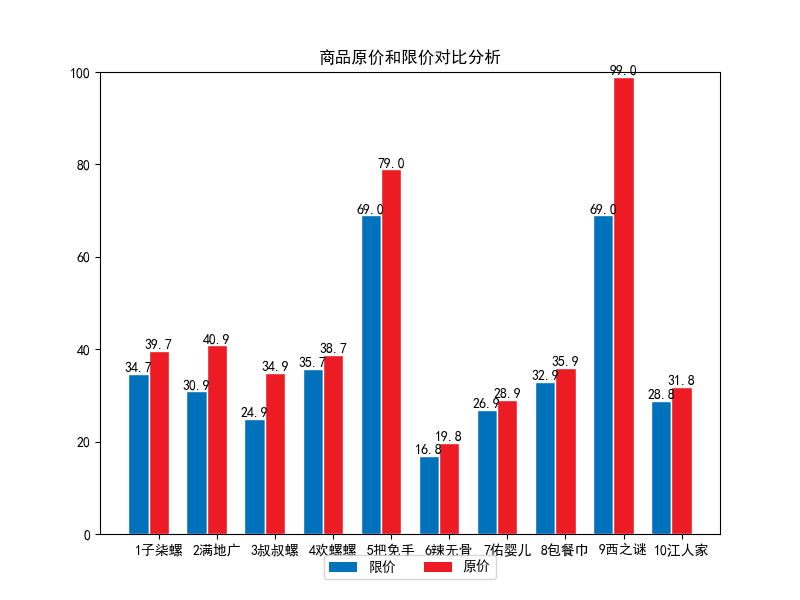
分析
从图中可以看出在这前10大销量商品中,价格最高是第9(纽西之谜隔离霜妆前乳),其次是第5(拖把免手洗家用干湿两用拖布),价格最低的是第6(酸辣无骨鸡爪)
从原价和限价对比来看,差值最大的是第9(纽西之谜隔离霜妆前乳)
详细介绍了数据的爬取过程,可方便新手学习入门学习
通过不同的可视化图表对数据进行展示
对可视化图表进行精简总结归纳,便于理解
代码很详细!
获取代码请在公众号里回复关键字: 淘宝
如果文章对你有帮助,欢迎转发/点赞/收藏~
作者:李运辰
_往期文章推荐_


