 大邓和他的Python
大邓和他的Python




系列视频|Python网络爬虫与文本数据分析 语法最简单的微博通用爬虫weibo_crawler
今天我们介绍一个简单爬虫程序,关于斗图的!!

只想说,从此以后,斗图就不用怕谁了!!
来,开干!

那我们就按照顺序来吧,先导入需要用到的库:
import requests
import re
import os
等等,你这个导入库没在正文目录下面啊!
没事,接下来我们开始表演就行!

一. 找到页面url规律
这里我们要爬取的网站是斗图啦:https://www.doutula.com/。
打开网站 我们先F12打开开发者模式 在右侧搜索框输入关键词 点击搜索 在搜索结果页面下滑,找到 查看更多 点击查看更多(这个时候请注意浏览器地址栏url变化) 于是,你发现了它的规律
# 页面变化项是 keyword 和 page,分别对应的搜索关键词和搜索结果页码
url = f'https://www.doutula.com/search?type=photo&more=1&keyword={keyword}&page={page}'

是不是很开心?!
开心你就蹦一蹦~~

二. 请求搜索结果数据
我们还是直接用requests库进行数据请求即可,这里需要注意的是 需要加上带浏览器的请求头,否则会收到404的错误码!
由于这里我用到re正则表达式进行数据解析,所以,可以先将请求的文本数据中非字符部分去掉,具体看下面代码就好啦。
headers = {
"Accept-Encoding": "Gzip", # 使用gzip压缩传输数据让访问更快
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:83.0) Gecko/20100101 Firefox/83.0",
}
# 搜索页面数据
def get_text(keyword,page):
url = f'https://www.doutula.com/search?type=photo&more=1&keyword={keyword}&page={page}'
# 请求数据
resp = requests.get(url,headers=headers)
# 去掉非字符
text = re.sub('\s','',resp.text)
return text
是不是觉得很简单,很不错!!

三. 解析并下载表情包
我们直接在页面开发者模式下,element元素找到某个表情包,然后在右侧可以看到该表情包所在节点区域,找啊找啊,就找到了表情包的图片地址。
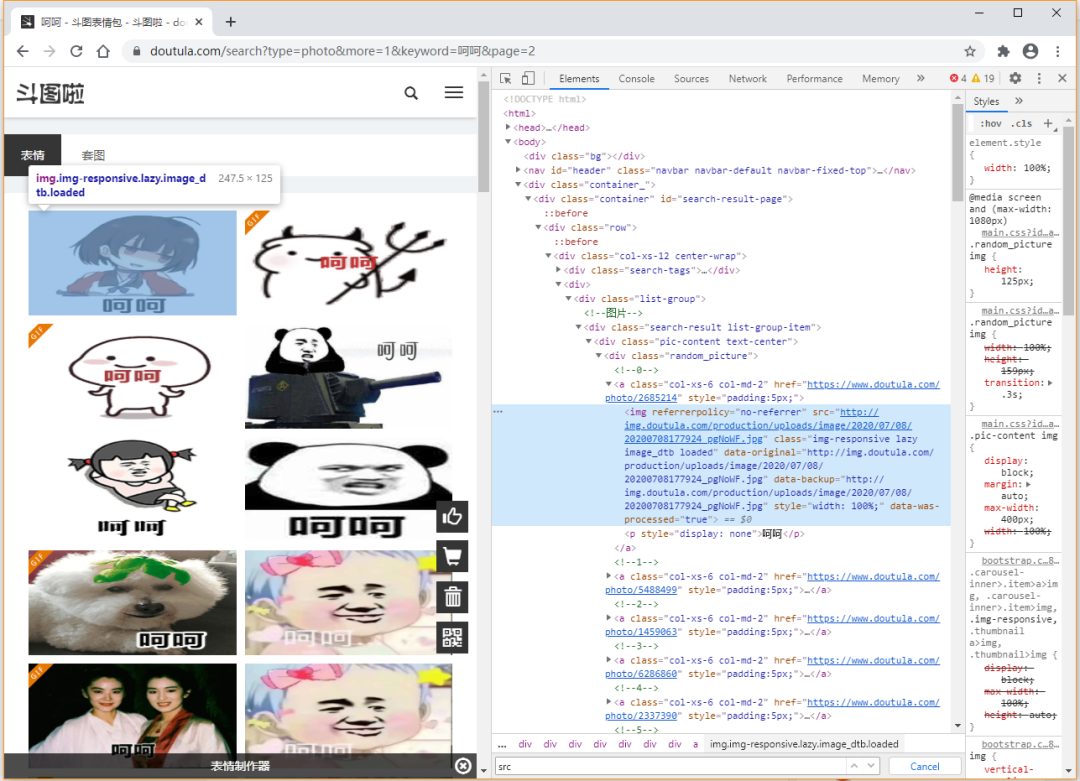
找到了表情包图片地址后,我们直接用正则表达式解析出他们进行处理就好啦。
为了处理的准确性,这里可以先正则解析出页面中全部表情所在区域,然后再在这个区域里解析每个表情包的图片地址,接着遍历全部的表情包地址进行图片下载。
需要注意的是,我这边想将不同关键词搜索结果下的表情包存在不同关键词文件夹里,所以用到了os.mkdir创建关键词文件夹的方式,当然在创建前也需要现判断是否已经存在os.path.exists。

直接看代码吧!!

# 表情包下载
def down_meme(keyword):
# 由于表情较多,这里只取10页(也有接近700左右)
pages = 10
num = 0
for page in range(1,pages+1):
text = get_text(keyword,page)
# 表情包区域
search_result = re.findall(r'divclass="search-resultlist-group-item"(.*?)class="text-center"',text)[0]
# 表情包下载地址
meme_urls = re.findall(r'"data-original="(.*?)"',search_result)
# 下载每页的表情包
for meme_url in meme_urls:
num += 1
# 表情包文件名
meme_name = re.findall(r'http://img.doutula.com/.*/(.*)',meme_url)[0]
meme_img = requests.get(meme_url)
# 表情包内容 bytes 格式
meme = meme_img.content
# 写入本地(判断关键字文件夹是不是存在,不存在则创建一个)
if not os.path.exists(f'./{keyword}'):
os.mkdir(f'./{keyword}')
with open(f'./{keyword}/{meme_name}','wb') as f:
f.write(meme)
print(f'{num} 个 {keyword} 表情包已经下载...')
是不是很简单,很牛逼??

四.代码跑起来,表情包斗起来!
最后,我们就可以进行表情包的自定义下载啦!
记得加上以下代码:
if __name__ == "__main__":
# keyword = '呵呵'
keyword = input('请输入你想查询的表情包:')
down_meme(keyword)
代码运行起来,666表情包刷起来!!!
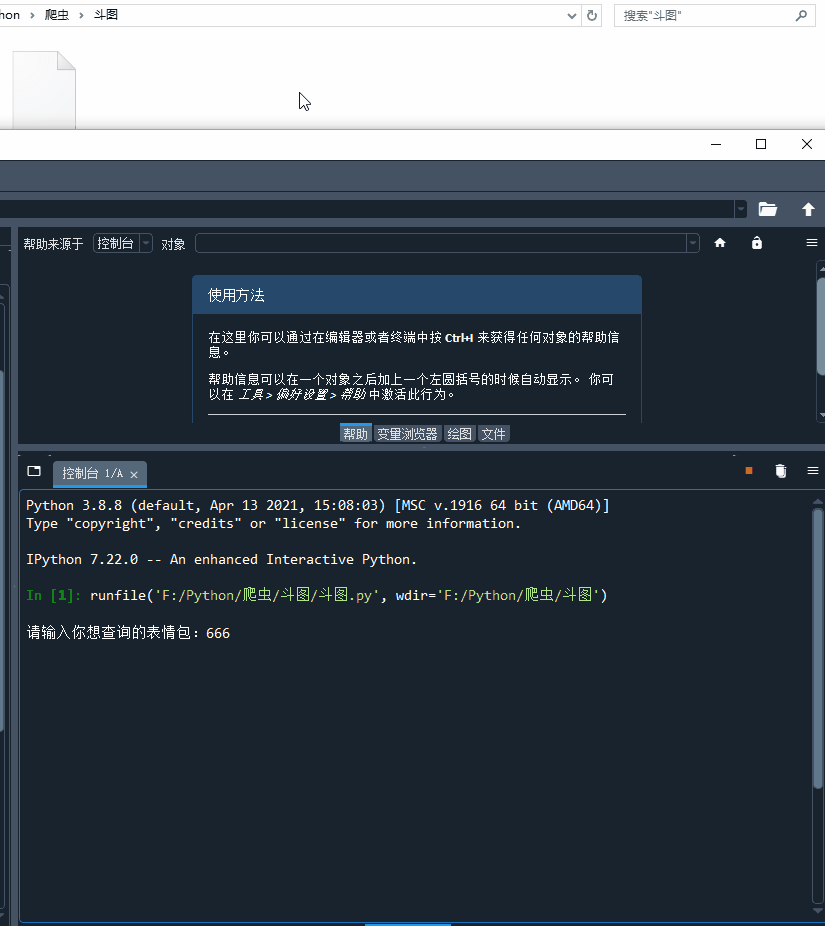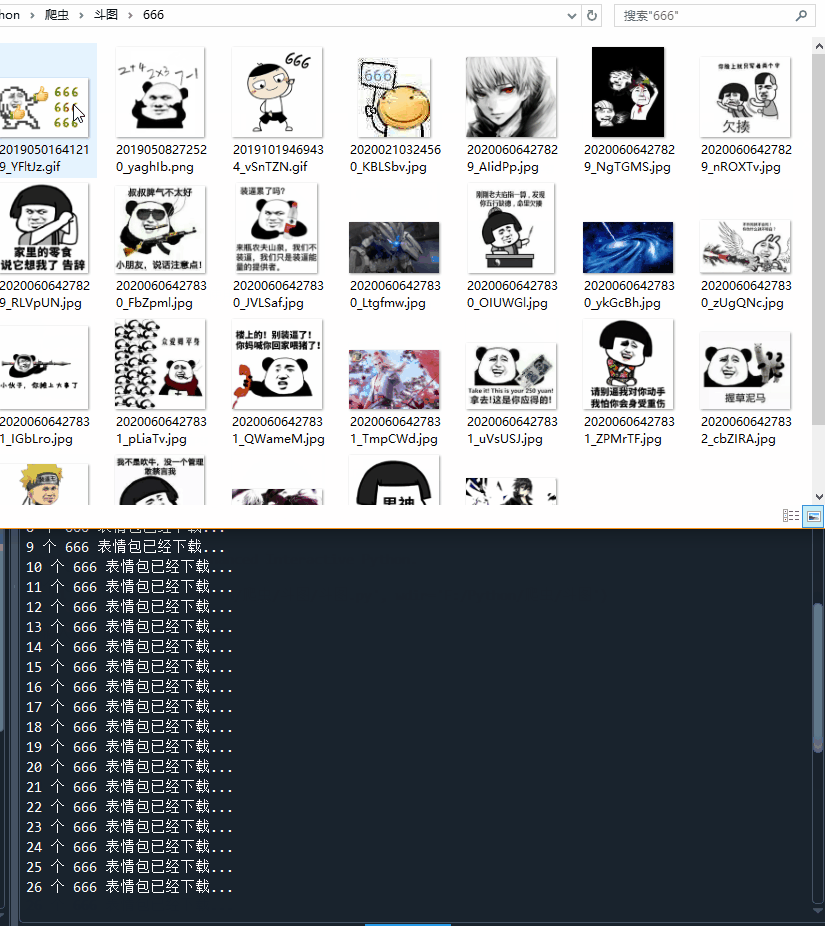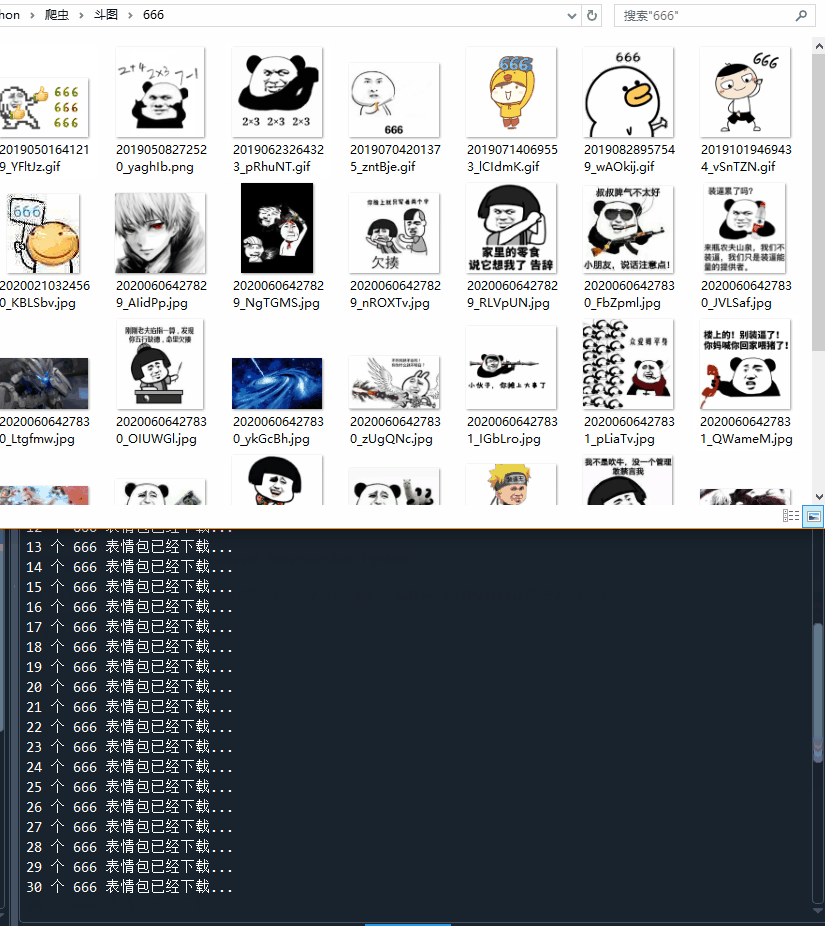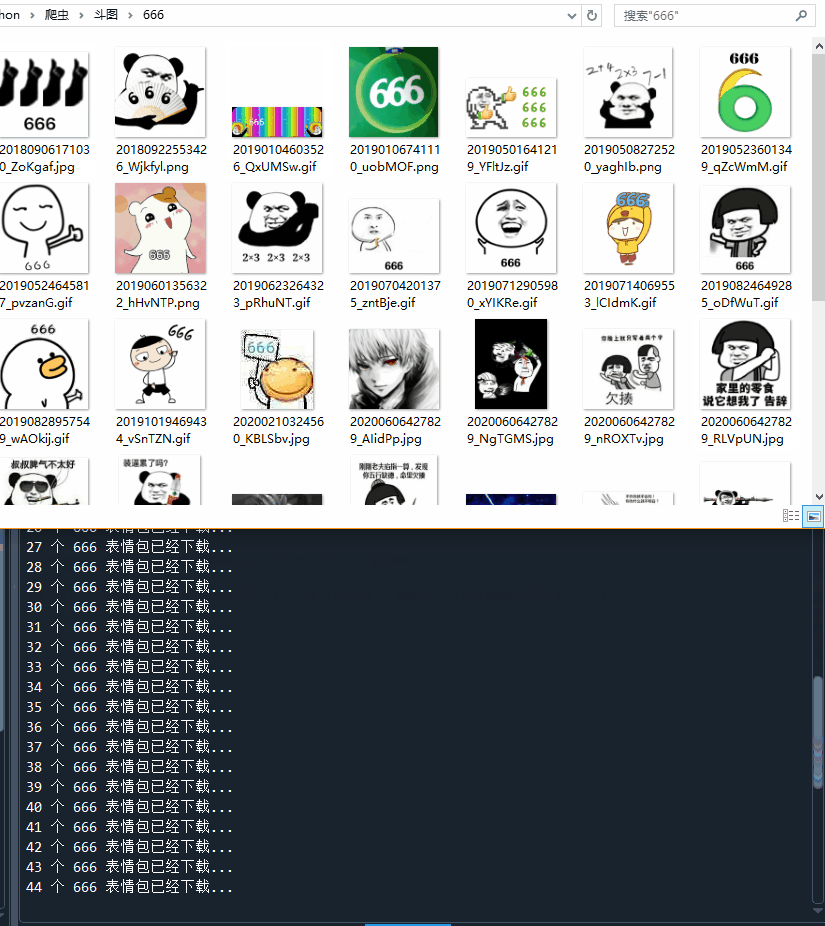
表情包下载
五.斗图吧
如果你在pc端微信,则直接将下载的表情包拖进对话框就行;如果你是手机的话,将文件导入手机,然后以照片形式发送亦可!
请开启你的斗图模式!!
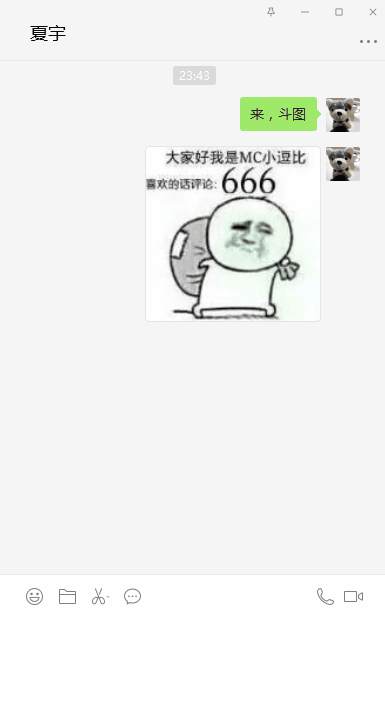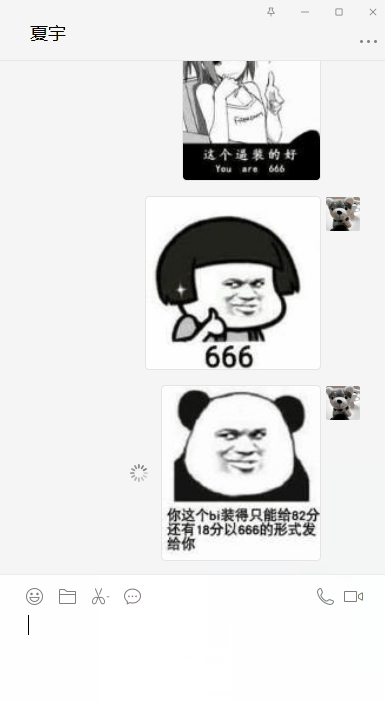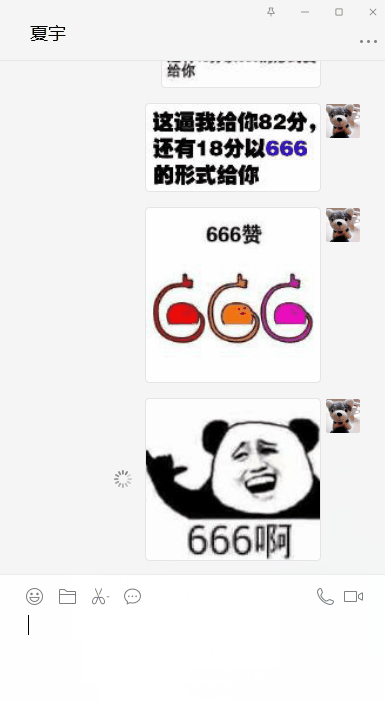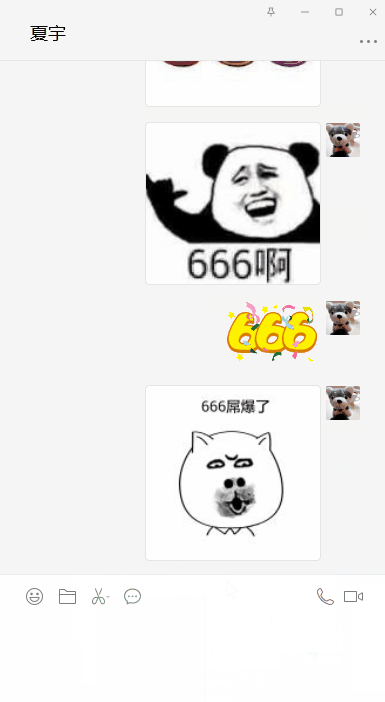
以上就是本次全部内容,简单粗暴有没有!!

还等什么,斗图去吧!

扫码免费领1万代理IP,高并发不限制,稳定速度快,快去薅羊毛吧!
精选文章
系列视频|Python网络爬虫与文本数据分析 语法最简单的微博通用爬虫weibo_crawler hiResearch 定义自己的科研首页 Jaal 库 轻松绘制动态社交网络关系图 来自kaggle最佳数据分析实践 B站视频 | Python自动化办公 SciencePlots | 科研样式绘图库 使用streamlit上线中文文本分析网站 bsite库 | 采集B站视频信息、评论数据 texthero包 | 支持dataframe的文本分析包 爬虫实战 | 采集&可视化知乎问题的回答 reticulate包 | 在Rmarkdown中调用Python代码 plydata库 | 数据操作管道操作符>> plotnine: Python版的ggplot2作图库 读完本文你就了解什么是文本分析 文本分析在经管领域中的应用概述 综述:文本分析在市场营销研究中的应用 plotnine: Python版的ggplot2作图库 Wow~70G上市公司定期报告数据集 漂亮~pandas可以无缝衔接Bokeh YelpDaset: 酒店管理类数据集10+G
“分享”和“在看”是更好的支持

