 数据派THU
数据派THU





作者:Jason Brownlee 翻译:wwl
校对:车前子
本文约4000字,建议阅读3分钟 本文介绍了haberman乳腺癌生存二分类数据集,进行神经网络模型拟合。包含数据准备、MLP模型学习机制、模型稳健性评估。
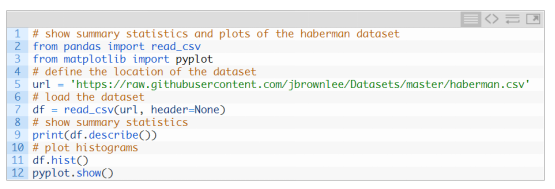
如何加载和汇总癌症生存数据集,根据结果来进行数据准备和模型配置。
如何探索MLP模型拟合数据的学习机制。
如何得到稳健的模型,调优并做预测。

Haberman 乳腺癌生存数据集
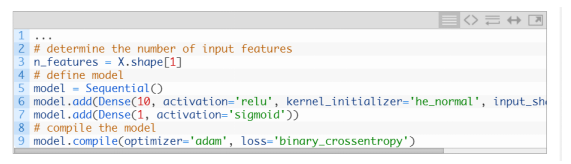
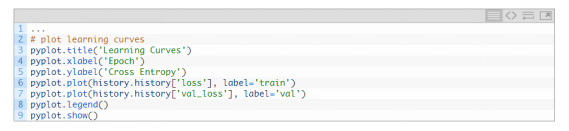
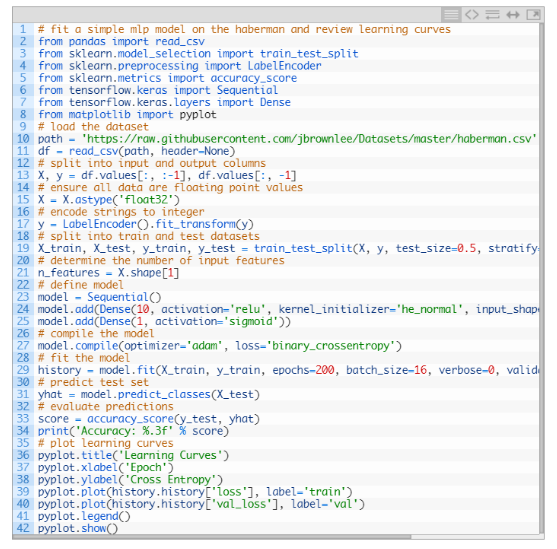
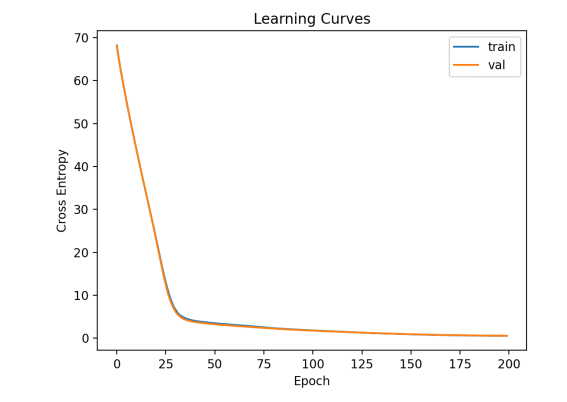
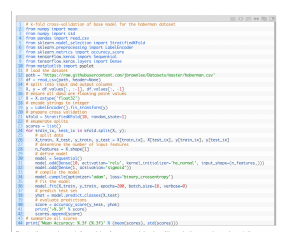
神经网络学习机制
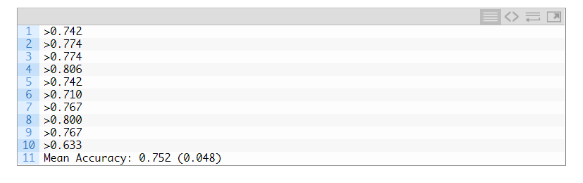
模型鲁棒性评估
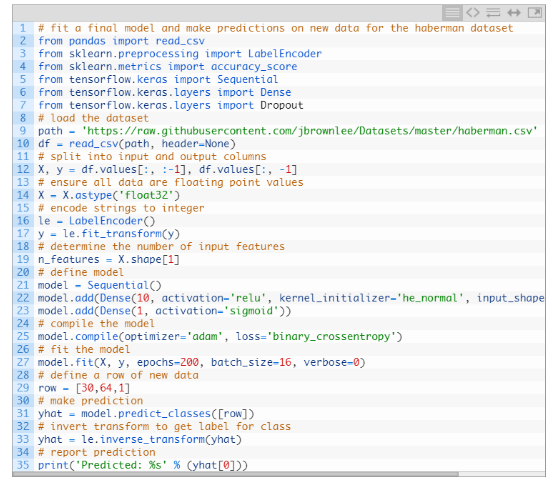
最终的模型及预测
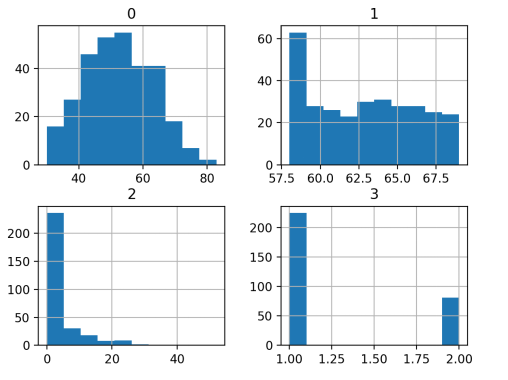
病人在手术期间的年龄;
手术的两位数年份;
检测到的腋窝淋巴结阳性数,这是衡量癌症是否已扩散的一种手段。

从以下链接,可以对这个数据集有更多了解:
Haberman Survival Dataset (haberman.csv)(https://github.com/jbrownlee/Datasets/blob/master/haberman.csv)
Haberman Survival Dataset Details (haberman.names)(https://github.com/jbrownlee/Datasets/blob/master/haberman.names)
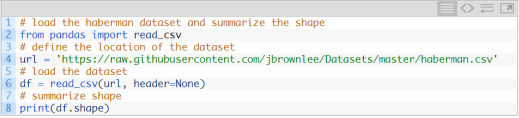
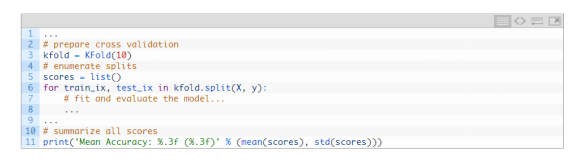
可以直接从URL中加载数据集,保存为pandas DataFrame,如下:




ReLu函数
https://machinelearningmastery.com/rectified-linear-activation-function-for-deep-learning-neural-networks/
权重初始化函数
https://machinelearningmastery.com/weight-initialization-for-deep-learning-neural-networks/
二分类交叉熵损失函数
https://machinelearningmastery.com/how-to-choose-loss-functions-when-training-deep-learning-neural-networks/



https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.StratifiedKFold.html






How to Develop a Probabilistic Model of Breast Cancer Patient Survival
How to Develop a Neural Net for Predicting Disturbances in the Ionosphere
Best Results for Standard Machine Learning Datasets
TensorFlow 2 Tutorial: Get Started in Deep Learning With tf.keras
A Gentle Introduction to k-fold Cross-Validation
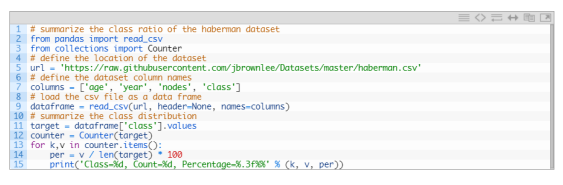
如何加载和汇总癌症生存数据集,并使用结果来建议要使用的数据准备和模型配置。
如何在数据集上探索简单MLP模型的学习动态。
如何开发模型性能的稳健估计,调整模型性能并对新数据进行预测。
译者简介
翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。

点击“阅读原文”拥抱组织

